PyTorch Workflow
1) 데이터 준비 (Get data ready)
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
# transforms: 데이터 전처리 과정을 정의
# - ToTensor(): 이미지를 Tensor(숫자 배열)로 변환, 값은 [0,1]
# - Normalize(): 데이터 분포를 일정하게 맞춤 (평균 0.5, 표준편차 0.5 → [-1, 1] 범위)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# MNIST 데이터셋 로드
# Dataset: 데이터와 라벨(label)을 묶어 관리하는 객체
trainset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
testset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# DataLoader: 데이터를 미니배치 단위(batch_size)로 나눠 모델에 공급
# batch_size: 한 번에 학습하는 데이터의 개수
# shuffle=True: 학습할 때마다 데이터 순서를 섞어서 일반화 성능 향상
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
testloader = torch.utils.data.DataLoader(testset, batch_size=1000, shuffle=False)
print("✅ 데이터 준비 완료 (Tensor 변환 + 미니배치 구성)")2) 모델 정의 (Build the model)
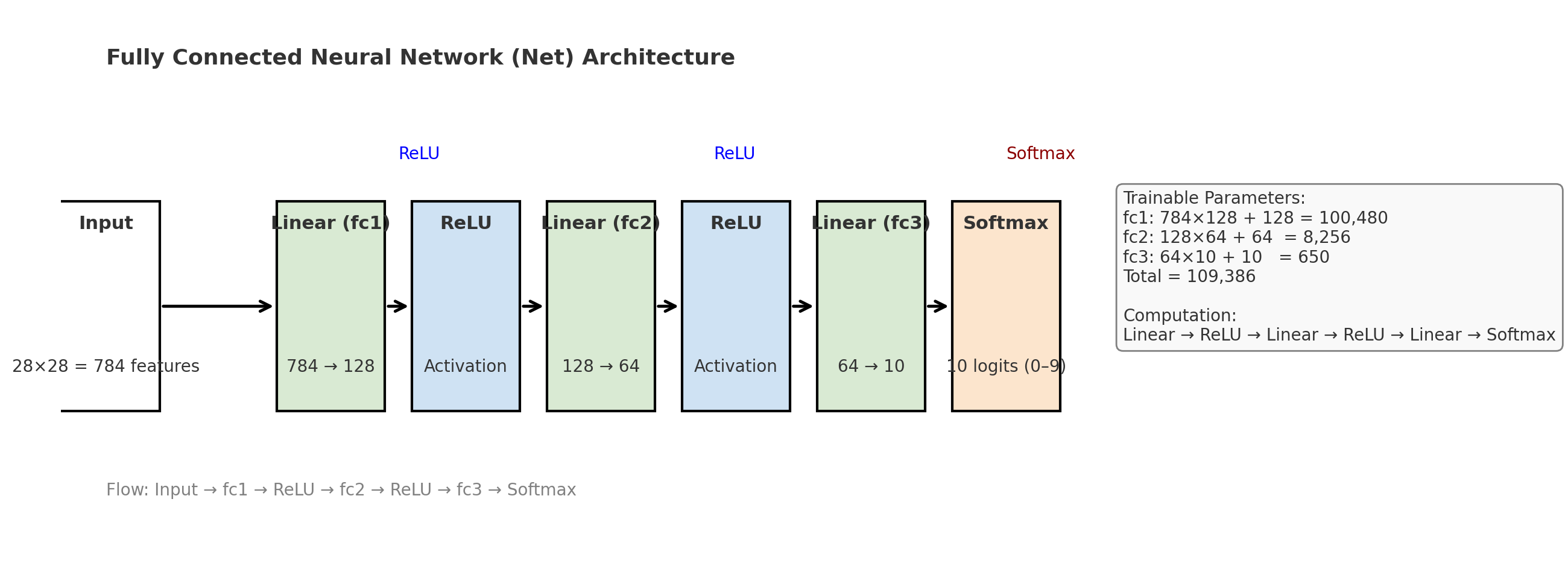
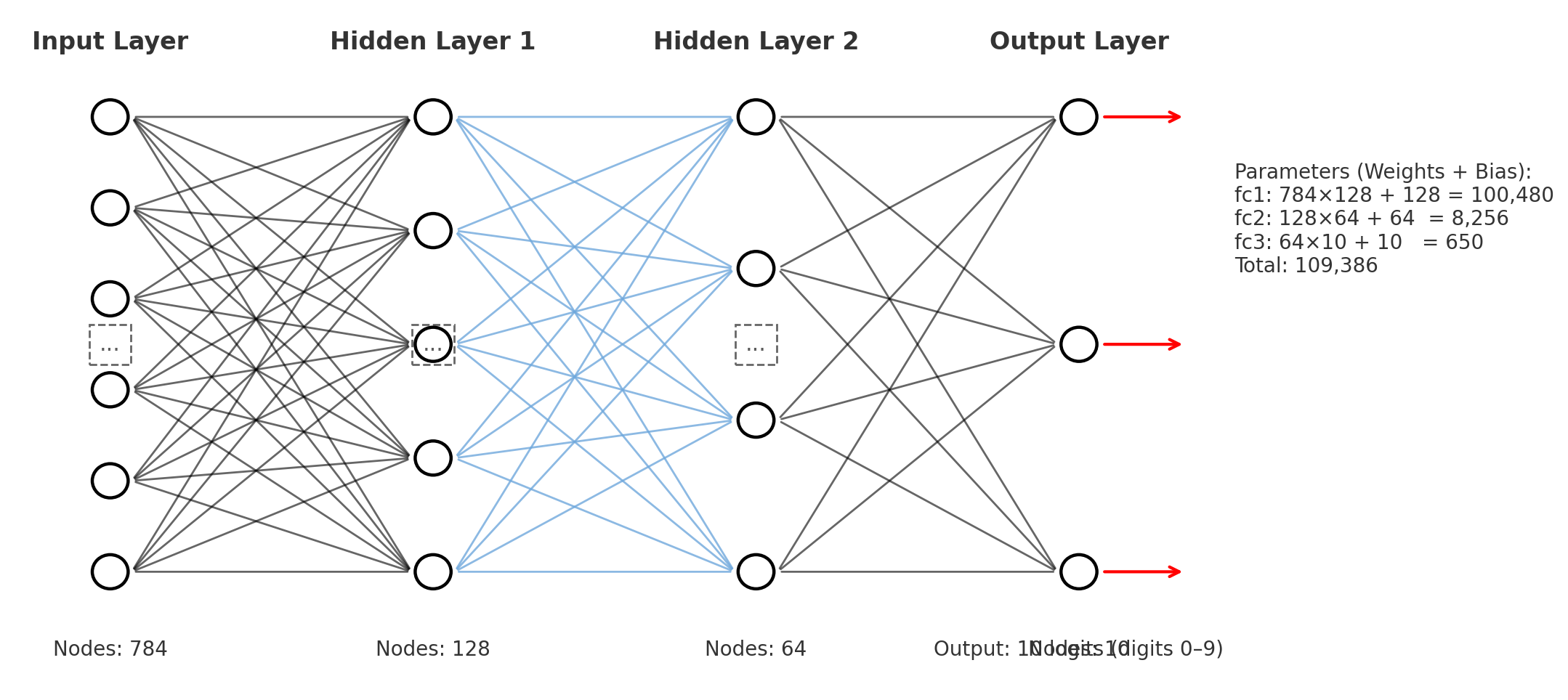
# nn.Module: 모든 PyTorch 신경망 모델의 기본 클래스
# Linear: 완전연결층 (입력 * 가중치 + 편향)
# ReLU: 비선형 활성함수 (0 이하를 0으로 만들고, 0 초과는 그대로 둠)
class Net(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(28*28, 128) # 입력 784(28x28) → 은닉층 128
self.fc2 = nn.Linear(128, 64) # 은닉층 128 → 은닉층 64
self.fc3 = nn.Linear(64, 10) # 은닉층 64 → 출력층 10 (숫자 0~9)
def forward(self, x):
# forward(): 입력이 신경망을 통과하는 계산 과정 정의
x = x.view(-1, 28*28) # 2D 이미지를 1D 벡터로 펼침
x = torch.relu(self.fc1(x)) # 첫 번째 은닉층 + ReLU
x = torch.relu(self.fc2(x)) # 두 번째 은닉층 + ReLU
return self.fc3(x) # 최종 출력층 (logits, softmax 미적용)
model = Net()
print("✅ 모델 정의 완료:", model)
✅ 모델 정의 완료: Net(
(fc1): Linear(in_features=784, out_features=128, bias=True)
(fc2): Linear(in_features=128, out_features=64, bias=True)
(fc3): Linear(in_features=64, out_features=10, bias=True)
)
3) 손실 함수와 옵티마이저 (Loss & Optimizer)
# 손실 함수(Loss Function):
# - 모델의 예측값과 실제값의 차이를 계산 (작을수록 좋음)
# - CrossEntropyLoss: 다중 클래스 분류에 사용되는 대표적인 손실 함수
criterion = nn.CrossEntropyLoss()
# 옵티마이저(Optimizer):
# - 손실(loss)을 줄이기 위해 가중치를 업데이트하는 알고리즘
# - Adam: 학습률을 자동으로 조정해 빠르게 수렴 (Adaptive Moment Estimation)
optimizer = optim.Adam(model.parameters(), lr=0.001)
print("✅ 손실 함수와 옵티마이저 설정 완료")4) 학습 루프 (Training Loop)
핵심 개념 설명
- epoch: 전체 데이터셋을 한 번 모두 학습하는 주기
(예: MNIST 60,000장을 5번 학습 → 5 epochs)- batch: 한 번에 학습하는 데이터 묶음 (여기선 64개)
- iteration: 한 epoch 내에서 batch 단위로 반복되는 횟수
(60,000 / 64 ≈ 937 iterations per epoch)- forward pass: 입력 → 모델 → 예측
- backward pass: 손실 → gradient 계산 → 가중치 업데이트
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
num_epochs = 5 # 전체 데이터셋을 몇 번 반복 학습할지
train_losses = [] # epoch별 평균 손실값 저장
test_accuracies = [] # epoch별 정확도 저장
for epoch in range(num_epochs): # epoch 반복
model.train() # 모델을 학습 모드로 설정 (Dropout 등 활성화)
running_loss = 0.0 # 손실 누적 변수 초기화
for images, labels in trainloader: # 미니배치 단위 반복 (iteration)
images, labels = images.to(device), labels.to(device)
# 1️⃣ 기울기 초기화 (gradient 누적 방지)
optimizer.zero_grad()
# 2️⃣ 순전파 (forward pass)
outputs = model(images)
# 3️⃣ 손실 계산
loss = criterion(outputs, labels)
# 4️⃣ 역전파 (backward pass)
# - autograd 엔진이 각 파라미터의 gradient(기울기)를 자동 계산
loss.backward()
# 5️⃣ 파라미터 업데이트
optimizer.step()
# 6️⃣ 손실 누적
running_loss += loss.item()
avg_loss = running_loss / len(trainloader)
train_losses.append(avg_loss)
# ---------- 평가 (Accuracy 계산) ----------
model.eval() # 평가 모드 전환 (Dropout, BatchNorm 비활성)
correct, total = 0, 0
with torch.no_grad(): # 평가 시엔 gradient 계산 불필요
for images, labels in testloader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1) # 확률이 가장 높은 클래스 선택
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
test_accuracies.append(accuracy)
print(f"Epoch [{epoch+1}/{num_epochs}] | Loss: {avg_loss:.4f} | Accuracy: {accuracy:.2f}%")
print("✅ 학습 완료!")Epoch [1/5] | Loss: 0.4019 | Accuracy: 93.34%
Epoch [2/5] | Loss: 0.1879 | Accuracy: 95.05%
Epoch [3/5] | Loss: 0.1380 | Accuracy: 95.97%
Epoch [4/5] | Loss: 0.1137 | Accuracy: 96.07%
Epoch [5/5] | Loss: 0.0948 | Accuracy: 96.90%
✅ 학습 완료!5) 모델 평가 (Evaluation)
# 모델 평가 (전체 테스트셋 정확도)
model.eval()
correct, total = 0, 0
with torch.no_grad():
for images, labels in testloader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f"✅ 최종 테스트 정확도: {accuracy:.2f}%")✅ 최종 테스트 정확도: 96.90%6) 시각화 (Visualization)

plt.figure(figsize=(10, 4))
# 손실(Loss) 시각화
plt.subplot(1, 2, 1)
plt.plot(train_losses, marker='o')
plt.title("Training Loss per Epoch")
plt.xlabel("Epoch (학습 주기)")
plt.ylabel("Loss (손실 값)")
# 정확도(Accuracy) 시각화
plt.subplot(1, 2, 2)
plt.plot(test_accuracies, color='orange', marker='o')
plt.title("Test Accuracy per Epoch")
plt.xlabel("Epoch (학습 주기)")
plt.ylabel("Accuracy (%)")
plt.tight_layout()
plt.show()7) 모델 저장 및 불러오기 (Save / Load)
# 모델 저장
# state_dict(): 모델의 모든 가중치(파라미터)를 딕셔너리 형태로 저장
torch.save(model.state_dict(), "mnist_model.pth")
print("✅ 모델 저장 완료: mnist_model.pth")
# 모델 불러오기
new_model = Net()
new_model.load_state_dict(torch.load("mnist_model.pth"))
new_model.eval()
print("✅ 저장된 모델 불러오기 완료")주요 용어 정리 표
| 용어 | 설명 |
|---|---|
| Epoch | 전체 학습 데이터셋을 한 번 모두 학습하는 주기 |
| Batch (미니배치) | 한 번의 학습에 사용되는 데이터 묶음 (예: 64개) |
| Iteration | 한 epoch 동안 수행되는 미니배치 학습 횟수 (데이터 개수 ÷ batch_size) |
| Loss Function | 모델의 예측이 얼마나 틀렸는지를 수치로 표현 |
| Optimizer | 손실을 줄이기 위해 가중치를 업데이트하는 알고리즘 |
| Forward Pass | 입력 데이터를 통해 예측값을 계산하는 단계 |
| Backward Pass | 손실을 기반으로 gradient를 계산하는 단계 |
| Gradient | 손실에 대한 파라미터의 변화율 (기울기) |
| Activation Function | 모델의 비선형성 부여 (예: ReLU, Sigmoid) |
| Dropout | 일부 뉴런을 랜덤으로 비활성화하여 과적합 방지 |
| state_dict | PyTorch 모델의 학습 가능한 파라미터 저장 구조 |
Batch, Backward Pass, Gradient
1) Batch
-
전체 데이터셋이 너무 크기 때문에 한 번에 전부 학습시키기 어렵다.
-
데이터를 여러 묶음(batch)으로 나누어 순차적으로 학습시킨다.
-
각 batch는 모델이 한 번의 순전파(Forward) 와 역전파(Backward) 를 수행하는 단위이다.
-
예시
-
전체 데이터: 60,000개
-
batch_size = 64- 한 epoch(전체 데이터 1회 학습)에
60,000 / 64 ≈ 938개의 배치 학습
- 한 epoch(전체 데이터 1회 학습)에
-
[1번째 batch] 64장 이미지 → 모델 통과 → gradient 계산 → 가중치 업데이트
[2번째 batch] 다음 64장 → 반복 …
[938번째 batch] 마지막 묶음까지 완료 → 1 epoch 종료장점
| 구분 | 설명 |
|---|---|
| 연산 효율 | GPU는 벡터 연산에 최적화되어 있으므로 여러 데이터를 동시에 처리하면 빠르다 |
| 메모리 절약 | 전체 데이터를 한 번에 메모리에 올릴 수 없으므로 적당히 나눈다 |
| 학습 안정성 | 배치 평균 손실을 이용해 gradient의 변동성을 완화한다 |
코드 예시
trainloader = DataLoader(dataset, batch_size=64, shuffle=True)
for images, labels in trainloader:
# images.shape = [64, 1, 28, 28]
# 한 번의 학습에 64개의 이미지와 라벨 사용2) Backward Pass (역전파)
-
모델의 예측과 실제 값의 차이(
loss)를 계산한 뒤, 그 정보를 이용해 가중치를 수정하는 과정이다. -
딥러닝의 학습은 역전파(Backpropagation) 알고리즘으로 이루어진다.
작동 순서
-
Forward pass: 입력 데이터를 통해 예측값(
y_pred) 계산 -
Loss 계산:
loss = criterion(y_pred, y_true) -
Backward pass:
-
loss.backward()호출 시 PyTorch의 autograd가 각 가중치에 대한 손실의 기울기를 계산한다. -
체인 룰(Chain Rule)을 이용해 미분을 역방향으로 전파한다.
-
-
Optimizer step():
- 계산된 gradient를 이용해 가중치를 업데이트한다.
수학적 예시
y_pred = w * x + b
loss = (y_pred - y_true)²d(loss)/dw = 2 * (y_pred - y_true) * x→ loss.backward() 는 이 과정을 자동으로 수행한다.
코드 예시
outputs = model(images) # 순전파
loss = criterion(outputs, labels) # 손실 계산
loss.backward() # 역전파 (gradient 계산)
optimizer.step() # 가중치 업데이트3) Gradient (기울기)
-
손실(loss)을 줄이기 위해 각 파라미터를 얼마나, 어떤 방향으로 바꿔야 하는지를 나타내는 값이다.
-
손실 함수의 경사 방향을 의미하며, 손실이 가장 적은 지점을 찾아가는 역할을 한다.
직관적 설명
-
Gradient는 손실 그래프의 경사 방향을 알려주는 나침반이다.
-
Gradient가
+이면 값을 줄이고,-이면 값을 늘려야 한다.
수학적 정의
-
손실 함수 ( L ) 이 가중치 ( w ) 에 따라 변한다고 할 때
-
가중치 업데이트 식
코드 예시
for name, param in model.named_parameters():
if param.grad is not None:
print(name, param.grad.norm().item()) # gradient 크기 확인
Gradient와 학습률의 관계
| 상황 | 설명 |
|---|---|
| Gradient 크기 ↑ | 손실이 급격히 변하는 구간 → 큰 폭으로 가중치 수정 |
| Gradient 크기 ↓ | 손실이 평평한 구간 → 천천히 수정 |
| Learning Rate | 한 번의 업데이트에서 이동하는 거리 (너무 크면 발산, 너무 작으면 느림) |
세 개념의 관계 정리
| 순서 | 개념 | 역할 |
|---|---|---|
| 1 | Batch | 학습 단위 데이터 묶음 |
| 2 | Backward Pass | 손실을 기준으로 gradient 계산 |
| 3 | Gradient | 손실이 줄어드는 방향과 크기 계산 |
전체 학습 과정
Batch 데이터 입력
↓
Forward Pass: 예측 생성
↓
Loss 계산
↓
Backward Pass: Gradient 계산
↓
Optimizer Step: 파라미터 업데이트
↓
다음 Batch 반복 → 1 Epoch 완료
Hi!