1. epochs란?
-
딥러닝 모델을 학습할 때,
epochs와batch_size는 학습 방식에 큰 영향을 미칩니다. -
이 두 매개변수는 데이터가 모델에 어떻게 전달되고, 모델이 얼마나 자주 가중치를 업데이트하는지를 결정합니다.
-
이를 통해 모델이 데이터로부터 점진적으로 학습할 수 있게 합니다.
epochs(에포크)의 정의
-epochs는 전체 훈련 데이터셋을 한 번 완전히 모델에 학습시키는 과정을 의미합니다.
- 예를 들어, 데이터가 100개 있고
epochs=10이라면, 전체 데이터를 10번 반복해서 학습시킨다는 뜻입니다. - 즉, 모든 데이터가 모델에 10회 전달됩니다.
에포크의 역할
- 한 에포크(epoch) 동안 모델은 가중치를 여러 번 업데이트하며, 이를 반복할수록 점점 더 정확한 예측을 수행하게 됩니다.
에포크의 중요성
| 에포크 수 | 현상 | 결과 |
|---|---|---|
| 너무 적음 | 학습이 충분히 이루어지지 않음 | 과소적합 (Underfitting) |
| 너무 많음 | 훈련 데이터에 과도하게 맞춤 | 과적합 (Overfitting) |
-
적절한 에포크 수를 설정하는 것이 중요합니다.
-
너무 적으면 학습이 부족하고, 너무 많으면 모델이 데이터에만 최적화되어 일반화 능력이 떨어집니다.
2. batch_size란?
-
batch_size는 한 번의 학습(가중치 업데이트)에 사용되는 데이터 샘플의 개수를 의미합니다. -
모든 데이터를 한꺼번에 처리하지 않고, 일정한 크기(
batch_size)만큼 묶어서 모델에 전달합니다.
배치의 역할
-
모델은 하나의 배치(batch) 데이터를 처리한 후 가중치(weight)를 한 번 업데이트합니다.
-
한 에포크 안에서도 여러 번의 미니 학습이 일어나며, 이를 통해 모델은 점진적으로 손실(loss)을 줄여갑니다.
배치 크기의 선택
| 배치 크기 | 장점 | 단점 |
|---|---|---|
| 작은 배치 (예: 16~64) | 메모리 효율 높음, 일반화 성능 향상 | 학습 느림, 계산 횟수 증가 |
| 큰 배치 (예: 128~512) | 빠른 학습, 병렬 처리 유리 | 메모리 사용량 증가, 세밀한 조정 어려움 |
- GPU 메모리가 충분하다면 큰 배치를, 제한적이라면 작은 배치로 실험하는 것이 좋습니다.
3. epochs와 batch_size의 상관관계
-
두 매개변수는 함께 모델의 학습 속도와 품질을 결정합니다.
-
예시
-
데이터셋: 320개
-
batch_size=32,epochs=10
-
-
한 에포크(epoch) 동안
320 ÷ 32 = 10번의 가중치 업데이트가 이루어집니다.- 즉, 10 epoch 동안 총 100번의 업데이트가 진행됩니다.
| 변수 | 의미 | 영향 |
|---|---|---|
| epochs | 전체 데이터셋 반복 횟수 | 학습 주기 결정 |
| batch_size | 한 번에 처리하는 데이터 수 | 메모리 사용량, 학습 세밀도 결정 |
4. epochs와 batch_size 설정 예시 (Keras)
# 모델 컴파일
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 학습 수행
model.fit(x_train, y_train, epochs=10, batch_size=32)-
epochs=10: 전체 데이터를 10번 반복 학습 -
batch_size=32: 한 번에 32개 데이터 처리 후 가중치 업데이트- 즉, 전체 데이터셋을 10번 반복하면서 한 번에 32개씩 학습하는 구조입니다.
5. PyTorch 실험 예시: Epoch vs Batch Size에 따른 Loss 변화
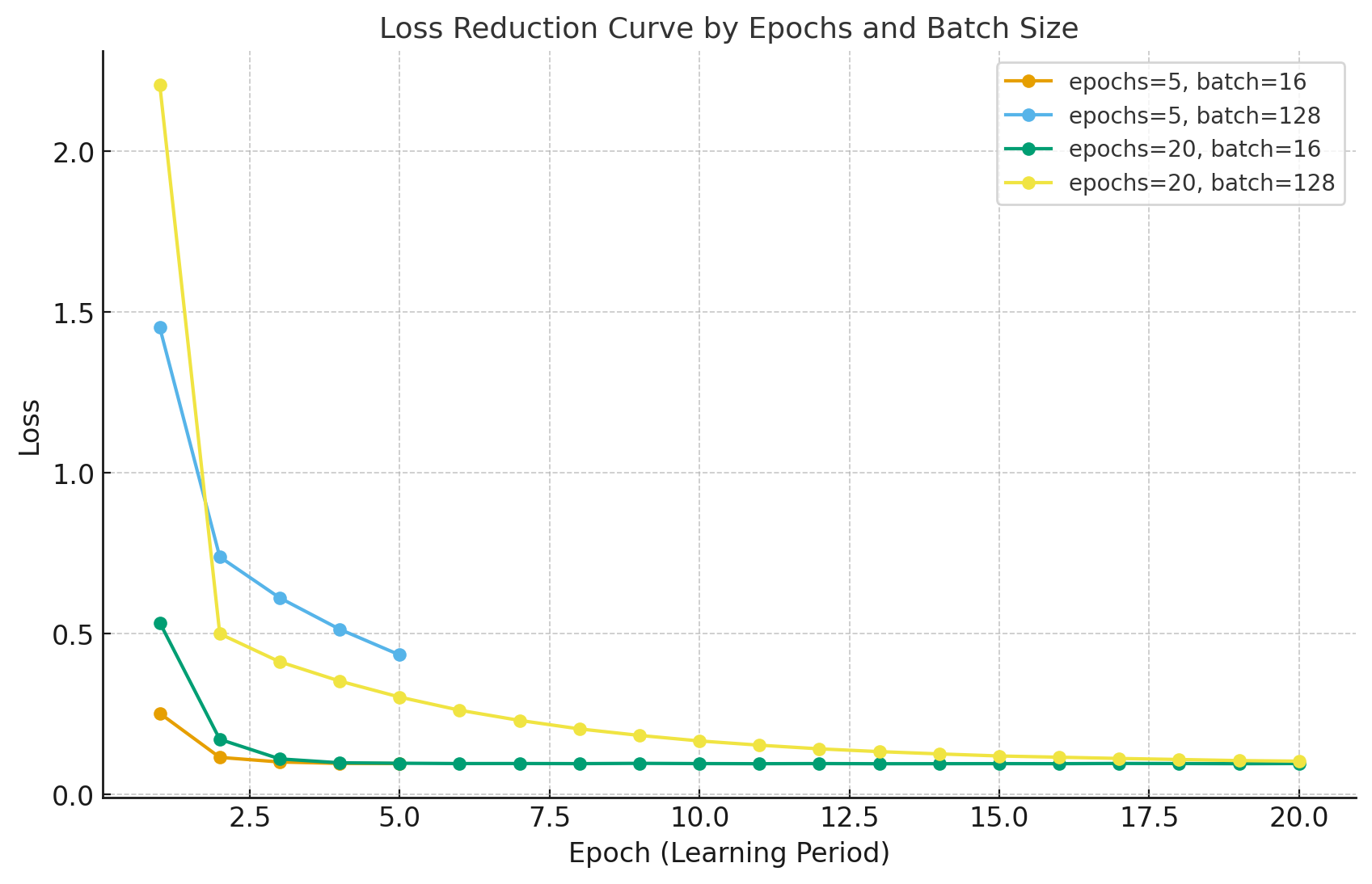
-
아래는 PyTorch로 구현한 에포크와 배치 크기 변화에 따른 손실 곡선(loss curve) 실험입니다.
-
데이터가 단순한 경우, batch 크기와 epoch 차이에 따른 수렴 패턴을 시각적으로 비교할 수 있습니다.
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import matplotlib.pyplot as plt
# 1. 가짜 데이터 (y = 3x + noise)
torch.manual_seed(0)
X = torch.linspace(0, 1, 1000).unsqueeze(1)
y = 3 * X + 0.3 * torch.randn_like(X)
dataset = TensorDataset(X, y)
# 2. 간단한 선형 모델
class LinearModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
return self.linear(x)
# 3. 학습 함수
def train_model(num_epochs, batch_size):
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
model = LinearModel()
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
losses = []
for epoch in range(num_epochs):
running_loss = 0.0
for inputs, targets in dataloader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
running_loss += loss.item()
losses.append(running_loss / len(dataloader))
return losses
# 4. 서로 다른 epoch/batch_size 조합 비교
experiments = [
{"epochs": 5, "batch_size": 16},
{"epochs": 5, "batch_size": 128},
{"epochs": 20, "batch_size": 16},
{"epochs": 20, "batch_size": 128},
]
plt.figure(figsize=(10, 6))
for exp in experiments:
losses = train_model(exp["epochs"], exp["batch_size"])
label = f"epochs={exp['epochs']}, batch={exp['batch_size']}"
plt.plot(range(1, exp["epochs"] + 1), losses, marker='o', label=label)
plt.title("Training Loss vs Epochs for Different Batch Sizes", fontsize=13)
plt.xlabel("Epoch")
plt.ylabel("Loss Value")
plt.legend()
plt.grid(True)
plt.show()결과 해석
- 모델이 단순한 경우, 충분한 epoch 이후에는 모든 조합이 거의 같은 손실값으로 수렴합니다.
- 즉, 학습이 수렴(converge)하여 더 이상 개선 여지가 없다는 뜻입니다.
| 조합 | 특징 | 해석 |
|---|---|---|
| epochs=5, batch=16 | 자주 업데이트 → 빠른 하락 | 초기 손실 급격히 감소 |
| epochs=5, batch=128 | 안정적이나 느림 | 평균화된 학습 진행 |
| epochs=20, batch=16 | 가장 세밀하게 수렴 | 낮은 손실 도달 |
| epochs=20, batch=128 | 완만한 수렴 | 수렴 속도 느림 |
6. epochs와 batch_size 선택 시 고려 사항
| 항목 | 설명 |
|---|---|
| 데이터 크기 | 데이터셋이 클수록 batch_size를 크게 해도 효율적 |
| 하드웨어 자원 | GPU 메모리에 따라 batch_size 조정 필요 |
| 학습 안정성 | 작은 batch일수록 업데이트 자주 → 불안정하지만 세밀한 조정 가능 |
| 일반화 성능 | 작은 batch가 일반화 성능 향상에 유리한 경향 |
7. 실전에서의 최적화 전략
Early Stopping (조기 종료)
- 모델이 과적합되기 시작할 때 학습을 자동으로 멈추는 기법입니다.
from tensorflow.keras.callbacks import EarlyStopping
es = EarlyStopping(monitor='val_loss', patience=3, restore_best_weights=True)
model.fit(x_train, y_train, epochs=50, batch_size=64, validation_data=(x_val, y_val), callbacks=[es])-
손실(
val_loss)이 일정 횟수 이상 개선되지 않으면 자동 중단됩니다. -
이를 통해 모델의 일반화 성능을 유지하면서 과적합을 방지할 수 있습니다.
8. 정리 요약
| 항목 | 의미 | 영향 |
|---|---|---|
| Epoch | 전체 데이터셋 반복 학습 횟수 | 학습이 충분하지 않으면 과소적합, 너무 많으면 과적합 |
| Batch Size | 한 번에 학습하는 데이터 수 | 메모리, 학습 세밀도, 수렴 속도에 영향 |
| 관계 | 작은 batch → 빠른 손실 감소, 큰 batch → 안정적 수렴 | 충분한 epoch 후에는 수렴점 동일 |
핵심 요약
-
Epoch: 전체 데이터를 몇 번 반복 학습할지
-
Batch Size: 한 번에 몇 개 데이터를 학습할지
-
Trade-off
-
작은 batch → 빠르고 세밀하지만 계산량 증가
-
큰 batch → 안정적이지만 일반화 약화
-
-
일반적으로 CNN은 32~128, Transformer는 128~1024 정도가 일반적이며, Early Stopping과 함께 최적화하는 것이 좋습니다.
