참고: https://blog-ko.superb-ai.com/what-is-the-transformer-model/
트랜스포머 모델이 혁신적인 핵심적인 이유는 기존 모델들이 가졌던 근본적인 한계를 '셀프 어텐션'이라는 새로운 메커니즘으로 해결했기 때문입니다.
기존 모델인 순환 신경망(RNN) 및 LSTM은 정보를 순차적으로 처리해야 했지만, 트랜스포머는 이 방식을 완전히 뒤집었습니다.
1. 기존 모델(RNN/LSTM)의 한계: 순차적 처리와 병목 현상
트랜스포머 이전의 주류 모델들은 다음과 같은 문제점을 가지고 있었습니다.
- 순차적 연산 (느린 속도): "나는 오늘 학교에 갔다"는 문장을 처리할 때, RNN은 '나' 다음에 '는', 그 다음에 '오늘' 순서로 단어를 하나씩 순서대로 읽어야만 다음 단어를 예측하거나 처리할 수 있었습니다. 이는 학습 속도를 매우 느리게 만들었습니다.
- 장거리 의존성 문제: 문장이 길어질수록 초반에 입력된 중요한 정보가 뒤로 갈수록 희미해지거나 손실되기 쉬웠습니다. 즉, 문맥 전체를 기억하고 연결하는 능력이 떨어졌습니다.
- GPU 활용의 비효율성: 현대 딥러닝에서 필수적인 GPU는 병렬 처리에 최적화되어 있는데, RNN의 순차적인 구조는 이러한 GPU의 강력한 병렬 처리 능력을 제대로 활용하지 못했습니다.
2. 트랜스포머의 혁신: 병렬 처리와 문맥 파악 능력 극대화
트랜스포머는 이러한 한계를 다음과 같은 방식으로 해결했습니다.
'셀프 어텐션'을 통한 병렬 처리
- 혁신: 트랜스포머는 문장 안의 모든 단어를 동시에 보고 한 번에 처리합니다. 순서를 기다릴 필요가 없습니다. "나는 오늘 학교에 갔다"라는 문장의 모든 단어가 서로에게 얼마나 중요한 영향을 미치는지 동시에 계산합니다.
- 결과: GPU의 병렬 처리 능력을 100% 활용할 수 있게 되어 학습 속도가 비약적으로 빨라졌습니다.
장거리 문맥 완벽 파악
- 혁신: '셀프 어텐션'은 문장의 어느 위치에 있는 단어든 직접적으로 연결하여 그 관계를 파악할 수 있습니다.
- 결과: RNN에서 어려움을 겪던 아주 긴 문맥(장거리 의존성)도 효과적으로 이해하고 기억할 수 있게 되었습니다. 이는 복잡한 언어 이해와 정확한 기계 번역을 가능하게 한 핵심 원동력입니다.
"Attention Is All You Need" (어텐션만으로 충분하다)
- 혁신: 트랜스포머는 복잡한 순환 구조를 완전히 제거하고 '어텐션' 메커니즘만으로 모델을 구성했습니다.
- 결과: 더 단순하면서도 훨씬 강력한 모델이 탄생했습니다.
요약하자면, 트랜스포머는 학습 속도를 혁신적으로 높이고(병렬 처리), 언어의 문맥을 완벽하게 파악할 수 있게 함으로써, 기존 AI가 도달하기 어려웠던 언어 이해 수준에 도달할 수 있는 기반을 마련한 것입니다.
1. Transformer의 등장과 기본 원리
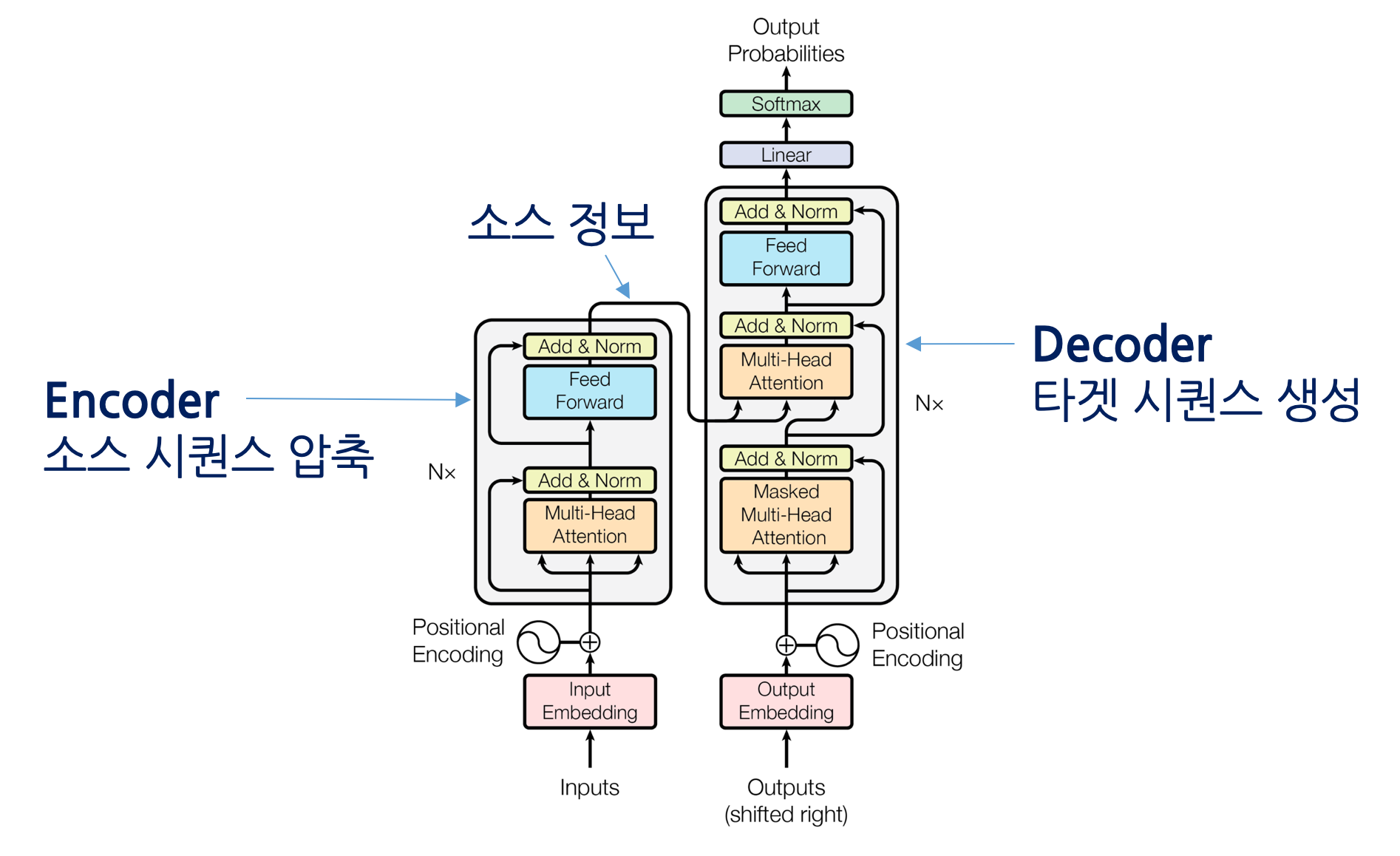
Transformer는 2017년 Google의 논문 “Attention Is All You Need” 에서 제안된 구조로,
순차적 처리를 기반으로 하던 RNN, LSTM을 병렬적 Self-Attention 메커니즘으로 대체하며
대규모 학습과 긴 문맥 이해를 가능하게 한 혁신적 모델입니다.
핵심 아이디어
-
Self-Attention: 문장 내 모든 토큰이 서로의 관계를 동시에 학습
-
Positional Encoding: 순서를 인코딩하여 시퀀스 정보 보존
-
Encoder-Decoder 구조: 입력(Encoder) → 요약/출력(Decoder)
이 구조는 이후 다양한 AI 분야로 확장되었습니다.
2. Transformer 파생 주요 분야
2.1 자연어처리 (NLP)
-
언어모델 (Language Model)
-
GPT 시리즈 (OpenAI)
-
BERT, RoBERTa (Google, Meta)
-
T5, UL2, FLAN (Instruction-tuned models)
→ 문맥 이해, 문장 생성, 번역, 요약, 질의응답 등 전반적 NLP 성능 비약적 향상
-
-
대형 언어모델 (LLM, Large Language Model)
-
수십억~수천억 파라미터 규모로 확장된 Transformer
-
예시: GPT-4, Gemini, Claude, LLaMA, Mistral 등
-
특징
-
사전학습(Pretraining) + 미세조정(Fine-tuning) + RLHF 구조
-
다양한 멀티태스크 학습이 가능
-
-
-
멀티링구얼·지식확장형 모델
-
mBERT, XLM-R (다국어 처리)
-
RETRO, RAG, Retrieval-Augmented 모델 (외부 지식 참조)
-
2.2 컴퓨터 비전 (Vision Transformer, ViT)
-
ViT (Vision Transformer)
-
CNN 대신 이미지를 패치 단위로 나눠 Transformer에 입력
-
장점: 전역 정보 파악에 강함
-
대표 모델: ViT, Swin Transformer, DeiT
-
-
비전-언어 융합 (Vision-Language Models)
-
CLIP (OpenAI): 텍스트-이미지 매칭
-
BLIP, ALBEF, Flamingo: 멀티모달 표현 학습
-
응용: 이미지 검색, 캡셔닝, 비전 기반 질의응답(VQA)
-
2.3 음성·오디오 처리
-
Speech Transformer / Whisper
-
음성 인식(ASR)과 합성(TTS)에서 Attention 구조 활용
-
Whisper (OpenAI): 다국어 음성 인식 및 번역
-
-
AudioLM, MusicLM
- 오디오 토큰 단위의 언어모델 기반 음악 생성
2.4 멀티모달 AI (Multimodal Transformer)
-
여러 입력 형태(텍스트, 이미지, 영상, 음성)를 통합 이해
-
대표 모델
-
Flamingo (DeepMind): 텍스트+이미지
-
GPT-4V (OpenAI): Vision + Language 통합
-
Kosmos-2, Gemini, Claude 3
-
-
응용: 멀티모달 질의응답, 영상 분석, 문서 요약, 로봇 제어 등
2.5 과학·공학 응용 (Scientific Transformer)
-
단백질/유전자 서열 해석
-
AlphaFold, ESMFold: 생물학적 서열을 Transformer로 모델링
-
ProteinBERT, ProtTrans: 구조·기능 예측
-
-
코드 생성 및 분석
-
CodeBERT, Codex, CodeLlama: 프로그래밍 언어 모델링
-
자동 코드 완성, 오류 검출, 리팩토링
-
-
수학·물리·시뮬레이션
- Symbolic Transformer, PhysFormer: 수식 reasoning 및 물리 시뮬레이션
3. 확장·변형 구조
3.1 효율화 연구 (Efficient Transformers)
-
Longformer, Performer, Linformer: 긴 시퀀스 효율적 처리
-
FlashAttention, xFormers: 메모리·속도 최적화
3.2 구조 변형
-
Decoder-only: GPT 계열 (생성 중심)
-
Encoder-only: BERT 계열 (이해 중심)
-
Encoder-Decoder: T5, FLAN 등 (입출력 변환 중심)
3.3 파인튜닝·적응형 구조
-
LoRA, QLoRA, PEFT: 경량화된 미세조정 기법
-
Adapter, Prefix Tuning: 파라미터 효율적 재사용
4. 최신 트렌드 및 융합 영역
-
AGI 지향 모델: GPT-5, Gemini 2 등은 멀티모달+추론+에이전트 기능 통합
-
Agentic AI: LangChain, AutoGPT, ChatGPT o1과 같은 자동화형 AI
-
Retrieval-Augmented Generation (RAG): 외부 데이터 검색 기반 생성
-
Tool Use & API 호출형 AI: 코드 실행, 웹 탐색, DB 질의 통합
-
Robotics Transformer: 물리 세계 조작을 위한 비전+언어 융합
5. 요약
| 분야 | 대표 모델 | 주요 특징 |
|---|---|---|
| NLP | GPT, BERT, T5 | 문맥 이해, 생성, 질의응답 |
| Vision | ViT, Swin, CLIP | 이미지 패치 기반 인식 |
| Audio | Whisper, AudioLM | 음성 인식 및 생성 |
| Multimodal | GPT-4V, Flamingo | 텍스트+이미지+영상 통합 |
| Science | AlphaFold, CodeLlama | 생명과학·코드·물리 응용 |
| Efficiency | Longformer, FlashAttention | 긴 시퀀스·저자원 대응 |
