OpenAI Embeddings 시각화 (PCA)
OPEN AI Embeddings 활용 버전
환경구성
C:\vectorDB\ ├─ .env ├─ vector.py ├─ requirements.txt └─ .venv\
requirement.txt
openai python-dotenv faiss-cpu numpy
.env
OPENAI_API_KEY=sk-여기에_발급받은_API_키
import os
import numpy as np
import faiss
from openai import OpenAI
from dotenv import load_dotenv
# .env 파일 로드
load_dotenv()
# 환경변수에서 API 키 가져오기
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY가 .env 파일에 설정되어 있지 않습니다.")
client = OpenAI(api_key=api_key)
def get_embedding(text):
response = client.embeddings.create(
model="text-embedding-3-small", # 또는 text-embedding-3-large
input=text
)
return np.array(response.data[0].embedding, dtype='float32')
def build_index(texts):
embeddings = [get_embedding(t) for t in texts]
dimension = len(embeddings[0])
index = faiss.IndexFlatL2(dimension)
index.add(np.array(embeddings))
return index, texts
def search_query(query, index, texts, k=2):
query_vector = get_embedding(query)
distances, indices = index.search(np.array([query_vector]), k)
results = [(texts[idx], distances[0][i]) for i, idx in enumerate(indices[0])]
return results
def main():
texts = [
"안녕하세요, 저는 AI를 좋아합니다.",
"텍스트 데이터를 벡터로 변환합니다.",
"오늘 날씨가 참 좋네요."
]
index, texts = build_index(texts)
query = "AI 관련 문장"
results = search_query(query, index, texts)
for text, dist in results:
print(f"문장: {text}, 거리: {dist}")
if __name__ == "__main__":
main()
# 가상환경 활성화
.\.venv\Scripts\Activate
# 라이브러리 설치
pip install -r requirements.txt
# 실행
python vector.py
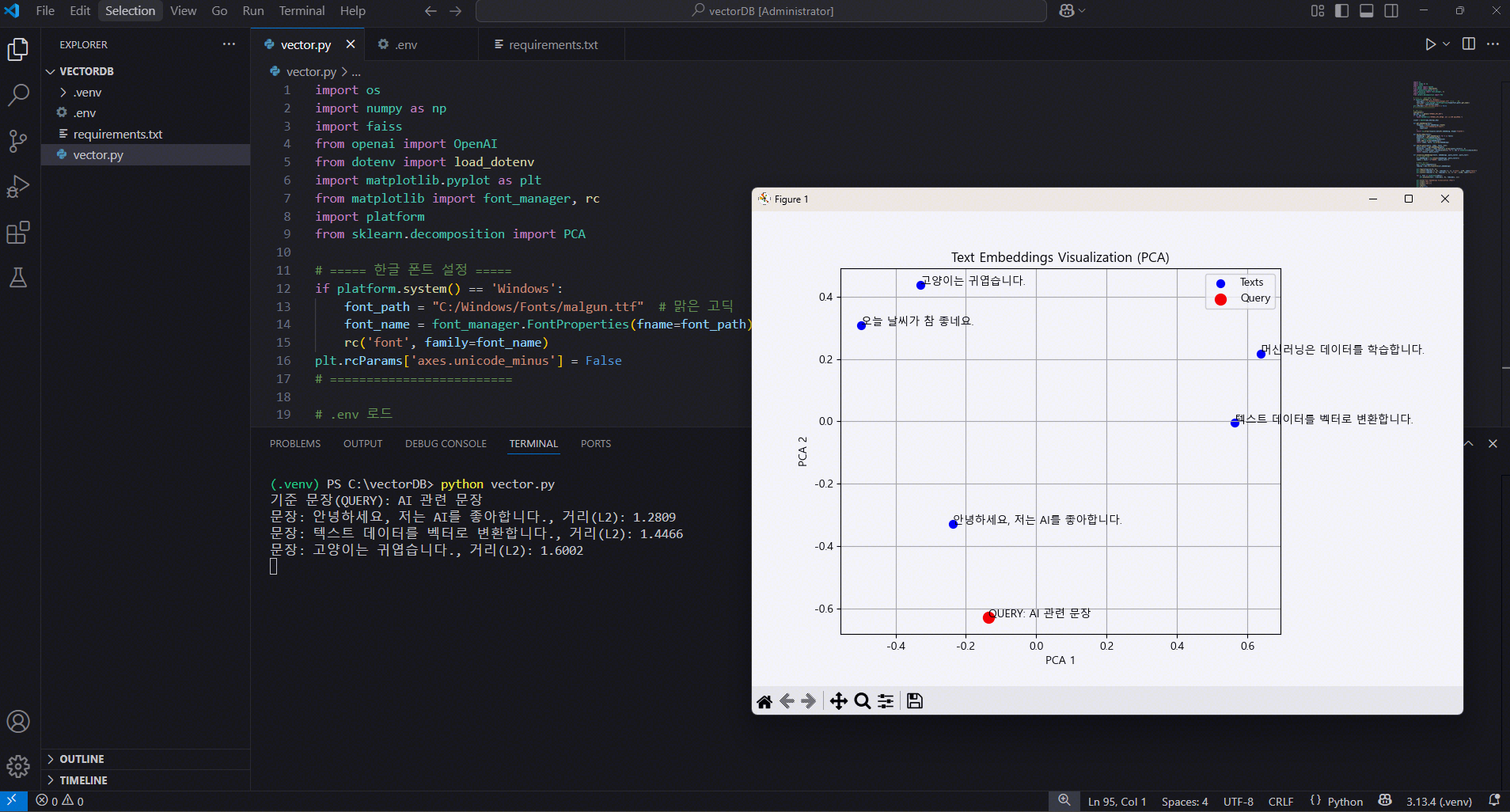
(.venv) PS C:\vectorDB> python vector.py
문장: 안녕하세요, 저는 AI를 좋아합니다., 거리: 1.2814680337905884
문장: 텍스트 데이터를 벡터로 변환합니다., 거리: 1.4465742111206055OpenAI Embeddings 시각화 (PCA)
import os
import numpy as np
import faiss
from openai import OpenAI
from dotenv import load_dotenv
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
import platform
from sklearn.decomposition import PCA
# ===== 한글 폰트 설정 =====
if platform.system() == 'Windows':
font_path = "C:/Windows/Fonts/malgun.ttf" # 맑은 고딕
font_name = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font_name)
plt.rcParams['axes.unicode_minus'] = False
# =========================
# .env 로드
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY가 .env 파일에 없습니다.")
client = OpenAI(api_key=api_key)
def get_embedding(text):
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return np.array(response.data[0].embedding, dtype='float32')
def build_index(texts):
embeddings = [get_embedding(t) for t in texts]
dimension = len(embeddings[0])
index = faiss.IndexFlatL2(dimension)
index.add(np.array(embeddings))
return index, texts, np.array(embeddings)
def search_query(query, index, texts, k=3):
query_vector = get_embedding(query)
distances, indices = index.search(np.array([query_vector]), k)
results = [(texts[idx], distances[0][i]) for i, idx in enumerate(indices[0])]
return results, query_vector
def visualize_embeddings(texts, embeddings, query_vector, query_text):
# 쿼리 벡터 포함
all_embeddings = np.vstack([embeddings, query_vector])
labels = texts + [f"QUERY: {query_text}"]
# PCA로 2D 축소
pca = PCA(n_components=2)
reduced = pca.fit_transform(all_embeddings)
plt.figure(figsize=(8, 6))
plt.scatter(reduced[:-1, 0], reduced[:-1, 1], c='blue', s=50, label="Texts")
plt.scatter(reduced[-1, 0], reduced[-1, 1], c='red', s=100, label="Query")
for i, text in enumerate(labels):
plt.annotate(text, (reduced[i, 0], reduced[i, 1]))
plt.title("Text Embeddings Visualization (PCA)")
plt.xlabel("PCA 1")
plt.ylabel("PCA 2")
plt.legend()
plt.grid(True)
plt.show()
def main():
texts = [
"안녕하세요, 저는 AI를 좋아합니다.",
"텍스트 데이터를 벡터로 변환합니다.",
"오늘 날씨가 참 좋네요.",
"머신러닝은 데이터를 학습합니다.",
"고양이는 귀엽습니다."
]
index, texts, embeddings = build_index(texts)
# 기준 문장(검색 쿼리)
query = "AI 관련 문장"
results, query_vector = search_query(query, index, texts)
# 검색 결과 출력
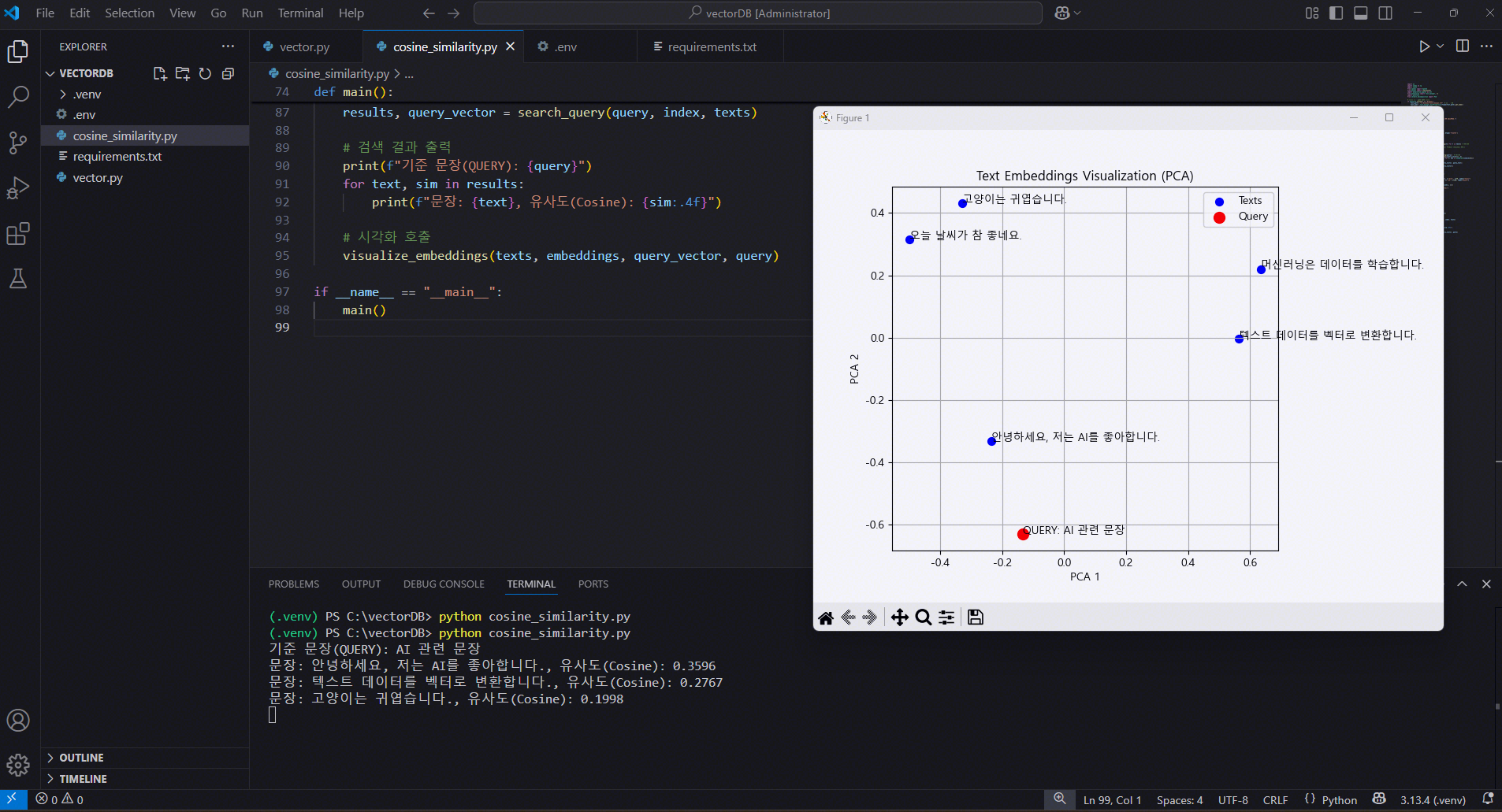
print(f"기준 문장(QUERY): {query}")
for text, dist in results:
print(f"문장: {text}, 거리(L2): {dist:.4f}")
# 시각화 호출
visualize_embeddings(texts, embeddings, query_vector, query)
if __name__ == "__main__":
main()
pip install matplotlib scikit-learn
python vector.py(.venv) PS C:\vectorDB> python vector.py
기준 문장(QUERY): AI 관련 문장
문장: 안녕하세요, 저는 AI를 좋아합니다., 거리(L2): 1.2809
문장: 텍스트 데이터를 벡터로 변환합니다., 거리(L2): 1.4466
문장: 고양이는 귀엽습니다., 거리(L2): 1.6002거리(distance) 판단 방식
예를 들어 지금 검색 결과가 이렇게 나왔을 겁니다:
문장: 안녕하세요, 저는 AI를 좋아합니다., 거리: 1.2808
문장: 텍스트 데이터를 벡터로 변환합니다., 거리: 1.4465이 수치의 의미
-
FAISS에서
IndexFlatL2를 썼기 때문에, 이 값은 L2 거리(Euclidean distance, 유클리드 거리) 입니다. -
L2 거리는 두 벡터 간의 차이를 직선 거리로 계산한 값입니다.
-
수식
-
= 쿼리 문장의 임베딩 벡터
-
= 데이터 문장의 임베딩 벡터
-
= 벡터 차원 수 (예: text-embedding-3-small은 1536차원)
해석 방법
-
작을수록 두 문장이 의미적으로 더 가깝다.
-
예
-
거리 0.5 → 거의 같은 의미
-
거리 1.2 → 어느 정도 관련 있음
-
거리 3.0 → 의미적으로 멀다
-
-
절대적인 기준은 없고, 데이터셋과 모델에 따라 상대적으로 비교하는 게 중요합니다.
-
L2 거리 값 범위
-
최소값: 0 → 두 벡터가 완전히 동일할 때 (차이가 없음)
-
최대값: 제한 없음 (∞) → 벡터가 서로 매우 멀리 떨어져 있을수록 값이 커짐
- 특히 임베딩 차원이 크면(예: 1536차원) 최대 거리가 꽤 커질 수 있음
-
-
임베딩 벡터 차원이 3이라고 가정하면
-
A = [0, 0, 0], B = [0, 0, 0] → 거리 = 0
-
A = [1, 1, 1], B = [-1, -1, -1] → 거리 =
-
차원이 커질수록, 각 좌표 차이가 누적되어 거리 값이 커짐
-
예시
| 문장 A | 문장 B | 거리(L2) | 의미 |
|---|---|---|---|
| "AI를 좋아합니다" | "머신러닝을 좋아합니다" | 0.9 | 매우 유사 |
| "AI를 좋아합니다" | "오늘 날씨가 좋네요" | 2.5 | 거의 무관 |
| "고양이는 귀엽습니다" | "강아지는 귀엽습니다" | 1.1 | 유사하지만 주제 다름 |
왜 L2 거리를 쓰나?
-
FAISS에서 가장 단순하고 빠른 검색 방법
-
하지만 의미 유사도를 더 직관적으로 보고 싶으면 Cosine Similarity를 쓰는 경우가 많습니다.
Cosine Similarity로 바꾸면?
-
Cosine Similarity는 두 벡터의 방향 유사도를 측정합니다.
-
값 범위: -1 ~ 1 (1에 가까울수록 유사)
-
수식
-
FAISS에서 cosine을 쓰려면 벡터를 정규화(normalize) 한 뒤 L2 거리로 검색하면 됩니다.
- 이 경우 L2 거리와 cosine 값은 변환 관계가 있습니다.
정리
- 지금 보이는 수치는 L2 거리
- 작을수록 의미적으로 가까움
- 절대값보다 상대적인 크기로 판단
- 더 직관적인 유사도(0~1)로 보고 싶으면 cosine similarity로 변환 가능
Cosine Similarity 버전 코드
import os
import numpy as np
import faiss
from openai import OpenAI
from dotenv import load_dotenv
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
import platform
from sklearn.decomposition import PCA
# ===== 한글 폰트 설정 =====
if platform.system() == 'Windows':
font_path = "C:/Windows/Fonts/malgun.ttf" # 맑은 고딕
font_name = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font_name)
plt.rcParams['axes.unicode_minus'] = False
# =========================
# .env 로드
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY가 .env 파일에 없습니다.")
client = OpenAI(api_key=api_key)
def get_embedding(text):
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return np.array(response.data[0].embedding, dtype='float32')
def normalize_vector(vec):
"""벡터를 L2 정규화하여 길이를 1로 만듦"""
return vec / np.linalg.norm(vec)
def build_index(texts):
embeddings = [normalize_vector(get_embedding(t)) for t in texts] # 정규화
dimension = len(embeddings[0])
index = faiss.IndexFlatIP(dimension) # Inner Product (Cosine과 동일)
index.add(np.array(embeddings))
return index, texts, np.array(embeddings)
def search_query(query, index, texts, k=3):
query_vector = normalize_vector(get_embedding(query)) # 정규화
similarities, indices = index.search(np.array([query_vector]), k)
results = [(texts[idx], similarities[0][i]) for i, idx in enumerate(indices[0])]
return results, query_vector
def visualize_embeddings(texts, embeddings, query_vector, query_text):
# 쿼리 벡터 포함
all_embeddings = np.vstack([embeddings, query_vector])
labels = texts + [f"QUERY: {query_text}"]
# PCA로 2D 축소
pca = PCA(n_components=2)
reduced = pca.fit_transform(all_embeddings)
plt.figure(figsize=(8, 6))
plt.scatter(reduced[:-1, 0], reduced[:-1, 1], c='blue', s=50, label="Texts")
plt.scatter(reduced[-1, 0], reduced[-1, 1], c='red', s=100, label="Query")
for i, text in enumerate(labels):
plt.annotate(text, (reduced[i, 0], reduced[i, 1]))
plt.title("Text Embeddings Visualization (PCA)")
plt.xlabel("PCA 1")
plt.ylabel("PCA 2")
plt.legend()
plt.grid(True)
plt.show()
def main():
texts = [
"안녕하세요, 저는 AI를 좋아합니다.",
"텍스트 데이터를 벡터로 변환합니다.",
"오늘 날씨가 참 좋네요.",
"머신러닝은 데이터를 학습합니다.",
"고양이는 귀엽습니다."
]
index, texts, embeddings = build_index(texts)
# 기준 문장(검색 쿼리)
query = "AI 관련 문장"
results, query_vector = search_query(query, index, texts)
# 검색 결과 출력
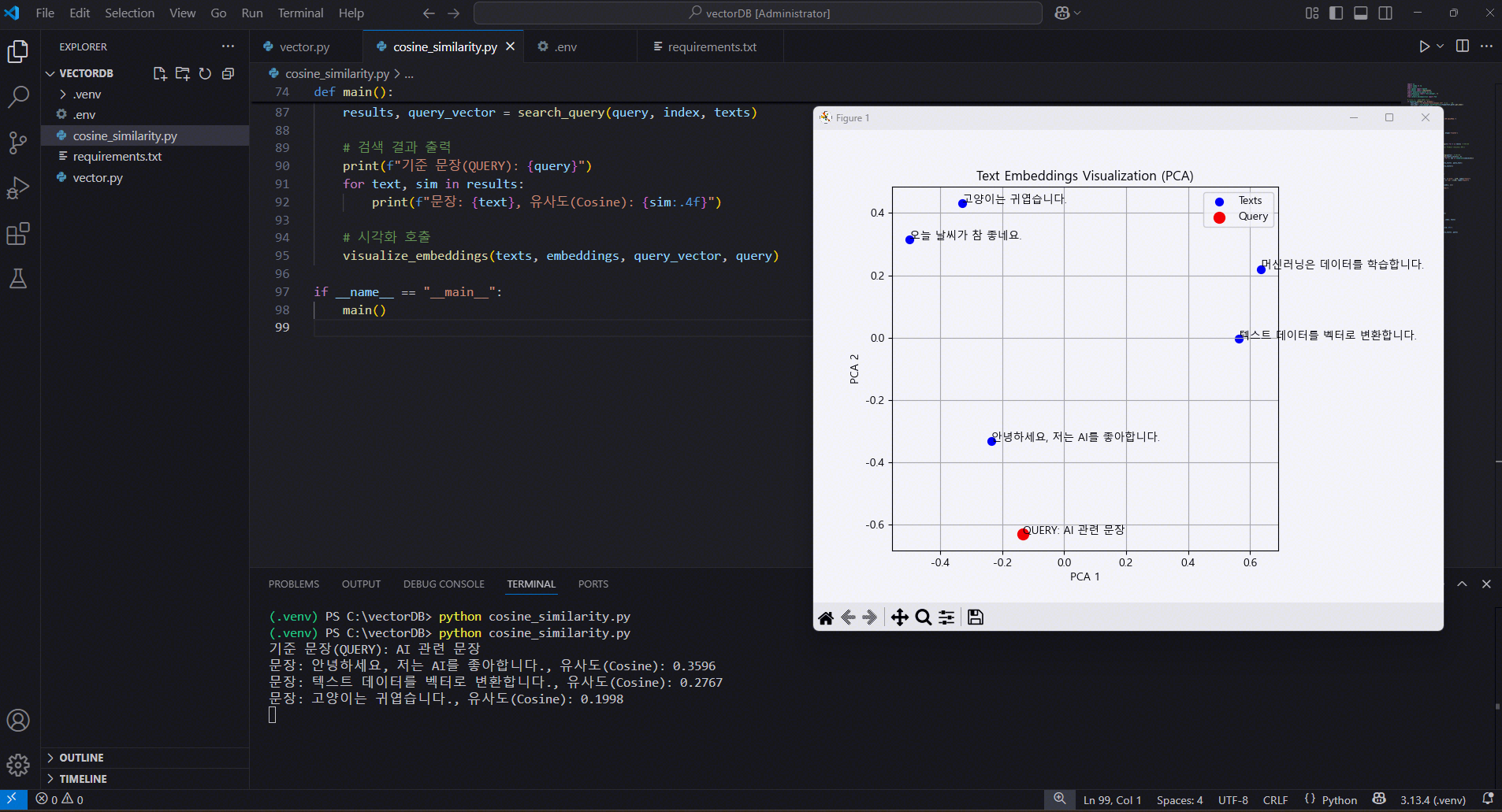
print(f"기준 문장(QUERY): {query}")
for text, sim in results:
print(f"문장: {text}, 유사도(Cosine): {sim:.4f}")
# 시각화 호출
visualize_embeddings(texts, embeddings, query_vector, query)
if __name__ == "__main__":
main()
(.venv) PS C:\vectorDB> python cosine_similarity.py
기준 문장(QUERY): AI 관련 문장
문장: 안녕하세요, 저는 AI를 좋아합니다., 유사도(Cosine): 0.3596
문장: 텍스트 데이터를 벡터로 변환합니다., 유사도(Cosine): 0.2767
문장: 고양이는 귀엽습니다., 유사도(Cosine): 0.1998상세 과정 출력
import os
import numpy as np
import faiss
from openai import OpenAI
from dotenv import load_dotenv
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
import platform
from sklearn.decomposition import PCA
# ===== 한글 폰트 설정 =====
if platform.system() == 'Windows':
font_path = "C:/Windows/Fonts/malgun.ttf" # 맑은 고딕
font_name = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font_name)
plt.rcParams['axes.unicode_minus'] = False
# =========================
# .env 로드
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("OPENAI_API_KEY가 .env 파일에 없습니다.")
client = OpenAI(api_key=api_key)
def get_embedding(text):
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return np.array(response.data[0].embedding, dtype='float32')
def normalize_vector(vec):
"""벡터를 L2 정규화하여 길이를 1로 만듦"""
return vec / np.linalg.norm(vec)
def build_index(texts):
embeddings = []
for t in texts:
emb = get_embedding(t)
print(f"[원본 임베딩] '{t}': {emb[:5]} ...") # 앞 5개만 출력
norm_emb = normalize_vector(emb)
print(f"[정규화 임베딩] '{t}': {norm_emb[:5]} ...")
embeddings.append(norm_emb)
dimension = len(embeddings[0])
index = faiss.IndexFlatIP(dimension) # Inner Product (Cosine과 동일)
index.add(np.array(embeddings))
print(f"[인덱스 추가 완료] 총 벡터 수: {index.ntotal}")
return index, texts, np.array(embeddings)
def search_query(query, index, texts, k=3):
query_emb = get_embedding(query)
print(f"[쿼리 원본 임베딩] '{query}': {query_emb[:5]} ...")
query_vector = normalize_vector(query_emb)
print(f"[쿼리 정규화 임베딩] '{query}': {query_vector[:5]} ...")
similarities, indices = index.search(np.array([query_vector]), k)
print(f"[검색 결과 인덱스] {indices}")
print(f"[검색 결과 유사도] {similarities}")
results = [(texts[idx], similarities[0][i]) for i, idx in enumerate(indices[0])]
return results, query_vector
def visualize_embeddings(texts, embeddings, query_vector, query_text):
# 쿼리 벡터 포함
all_embeddings = np.vstack([embeddings, query_vector])
labels = texts + [f"QUERY: {query_text}"]
# PCA로 2D 축소
pca = PCA(n_components=2)
reduced = pca.fit_transform(all_embeddings)
plt.figure(figsize=(8, 6))
plt.scatter(reduced[:-1, 0], reduced[:-1, 1], c='blue', s=50, label="Texts")
plt.scatter(reduced[-1, 0], reduced[-1, 1], c='red', s=100, label="Query")
for i, text in enumerate(labels):
plt.annotate(text, (reduced[i, 0], reduced[i, 1]))
plt.title("Text Embeddings Visualization (PCA)")
plt.xlabel("PCA 1")
plt.ylabel("PCA 2")
plt.legend()
plt.grid(True)
plt.show()
def main():
texts = [
"안녕하세요, 저는 AI를 좋아합니다.", # index 0
"텍스트 데이터를 벡터로 변환합니다.", # index 1
"오늘 날씨가 참 좋네요.", # index 2
"머신러닝은 데이터를 학습합니다.", # index 3
"고양이는 귀엽습니다." # index 4
]
index, texts, embeddings = build_index(texts)
# 기준 문장(검색 쿼리)
query = "AI 관련 문장"
results, query_vector = search_query(query, index, texts)
# 검색 결과 출력
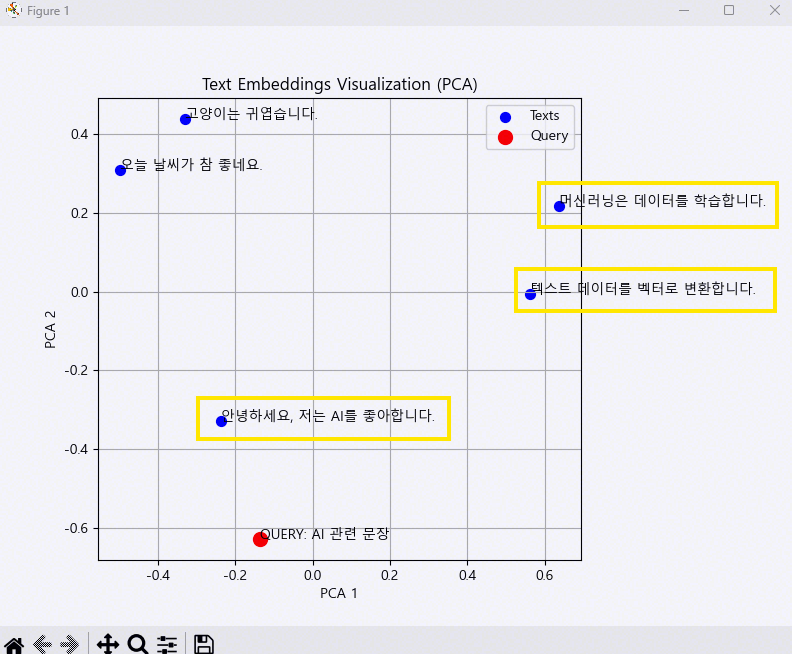
print(f"기준 문장(QUERY): {query}")
for text, sim in results:
print(f"문장: {text}, 유사도(Cosine): {sim:.4f}")
# 시각화 호출
visualize_embeddings(texts, embeddings, query_vector, query)
if __name__ == "__main__":
main()
(.venv) PS C:\vectorDB> python cosine_similarity.py
[원본 임베딩] '안녕하세요, 저는 AI를 좋아합니다.': [ 0.01376438 -0.05957488 -0.03256734 0.01288601 0.03613875] ...
[정규화 임베딩] '안녕하세요, 저는 AI를 좋아합니다.': [ 0.01376438 -0.05957488 -0.03256734 0.01288601 0.03613875] ...
[원본 임베딩] '텍스트 데이터를 벡터로 변환합니다.': [-0.00962334 0.01652393 -0.03468546 -0.01388997 0.01675083] ...
[정규화 임베딩] '텍스트 데이터를 벡터로 변환합니다.': [-0.00962334 0.01652393 -0.03468546 -0.01388997 0.01675083] ...
[원본 임베딩] '오늘 날씨가 참 좋네요.': [ 0.01764893 -0.01802478 -0.1094887 -0.01576147 0.02542753] ...
[정규화 임베딩] '오늘 날씨가 참 좋네요.': [ 0.01764893 -0.01802478 -0.1094887 -0.01576147 0.02542753] ...
[원본 임베딩] '머신러닝은 데이터를 학습합니다.': [-0.0112118 0.02411372 0.00905493 -0.00343675 0.05726762] ...
[정규화 임베딩] '머신러닝은 데이터를 학습합니다.': [-0.0112118 0.02411372 0.00905493 -0.00343675 0.05726762] ...
[원본 임베딩] '고양이는 귀엽습니다.': [ 0.01889732 0.00614327 -0.07117586 -0.01283821 0.00697546] ...
[정규화 임베딩] '고양이는 귀엽습니다.': [ 0.01889732 0.00614327 -0.07117587 -0.01283821 0.00697546] ...
[인덱스 추가 완료] 총 벡터 수: 5
[쿼리 원본 임베딩] 'AI 관련 문장': [-0.01482688 0.05272911 0.0115823 0.03046968 0.002392 ] ...
[쿼리 정규화 임베딩] 'AI 관련 문장': [-0.01482688 0.05272911 0.0115823 0.03046968 0.002392 ] ...
[검색 결과 인덱스] [[0 1 4]]
[검색 결과 유사도] [[0.35957015 0.2766767 0.19984645]]
기준 문장(QUERY): AI 관련 문장
문장: 안녕하세요, 저는 AI를 좋아합니다., 유사도(Cosine): 0.3596
문장: 텍스트 데이터를 벡터로 변환합니다., 유사도(Cosine): 0.2767
문장: 고양이는 귀엽습니다., 유사도(Cosine): 0.1998
