로지스틱 회귀 : 타이타닉 생존자 예측하기
-
영화 〈타이타닉〉으로 유명한 타이타닉호는 북대서양 횡단 여객선입니다.
-
모두가 아는 것처럼 1912년 4월 10일 영국의 사우샘프턴에서 미국의 뉴욕으로 향하던 첫 항해 중에 빙산과 충돌하여 침몰했습니다.
-
안타깝게도 이 사건으로 많은 사상자가 발생했습니다. 이번에 다룰 타이타닉 데이터셋은 당신 승선한 승객의 정보를 담고 있습니다. 이름, 성별, 나이, 티켓 번호 등 같은 정보가 실제로 생존에 어떤 영향을 미치는지 확인해봅시다.

라이브러리 및 데이터 불러오기
import pandas as pd # 판다스 라이브러리 임포트
file_url = 'https://media.githubusercontent.com/media/musthave-ML10/data_source/main/titanic.csv'
data = pd.read_csv(file_url) # 데이터셋 읽기
데이터 확인하기
data.head( ) # 상위 5행 출력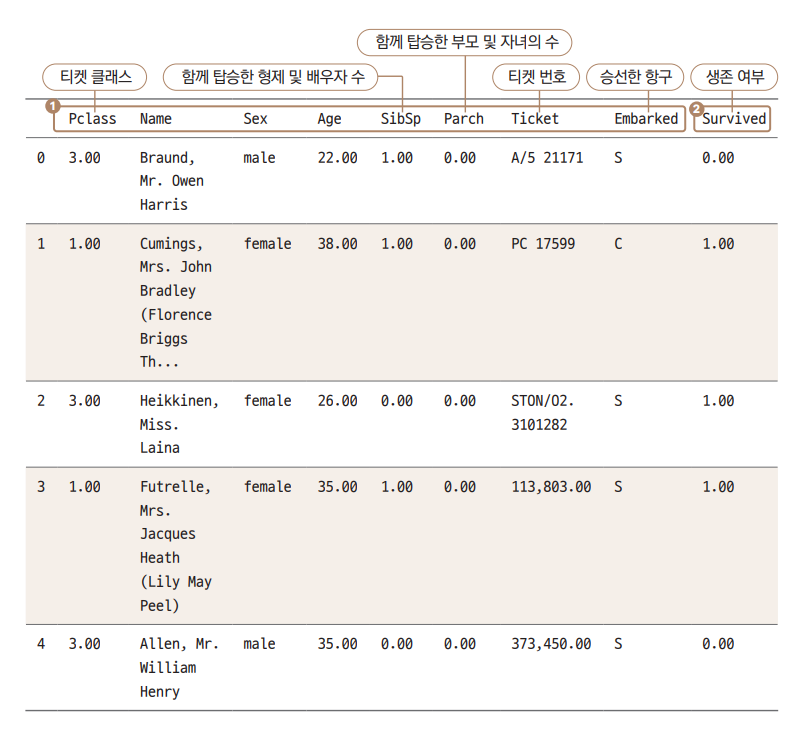
-
head( )함수로 상위 5행 출력해 데이터를 살펴봅시다.① 독립변수 8개
②종속변수(Survived) 1개
-
변수 이름에 대한 설명은 다음과 같습니다.
-
Pclass: 비행기처럼, 일종의 티켓 클래스입니다. -
Name: 승객 이름 -
Sex: 성별 -
Age: 나이 -
SibSp(Siblings and Spouse): 함께 탑승한 형제 및 배우자의 수 -
Parch(Parent and Child) : 함께 탑승한 부모 및 자녀의 수 -
Ticket: 티켓 번호 -
Embarked: 승선한 항구(C = Cherbourg, Q = Queenstown, S = Southampton) -
Survived: 생존 유무 (1 = 생존, 0 = 사망)
-
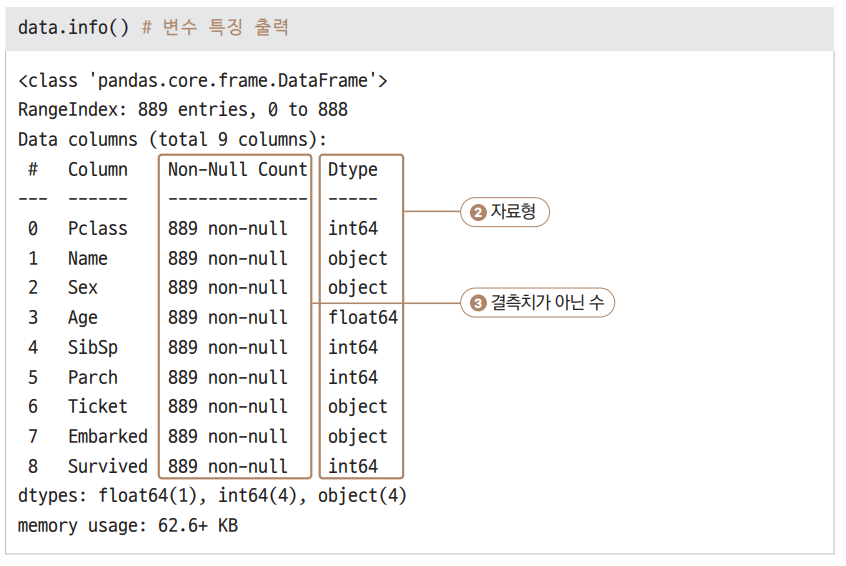
-
info( )함수를 호출해 각 변수의 특징을 살펴봅시다.-
이번에도 모든 변수의 ① Non-Null Count값이 889로 모두 같습니다.
- 즉 빈 값(결측치)이 없습니다.
-
② Dtype에서 자료형을 살펴보니 문자형(object) 변수가 4개입니다.
- Name, Sex, Ticket, Embarked입니다.
-
data.describe( ) # 통계 정보 출력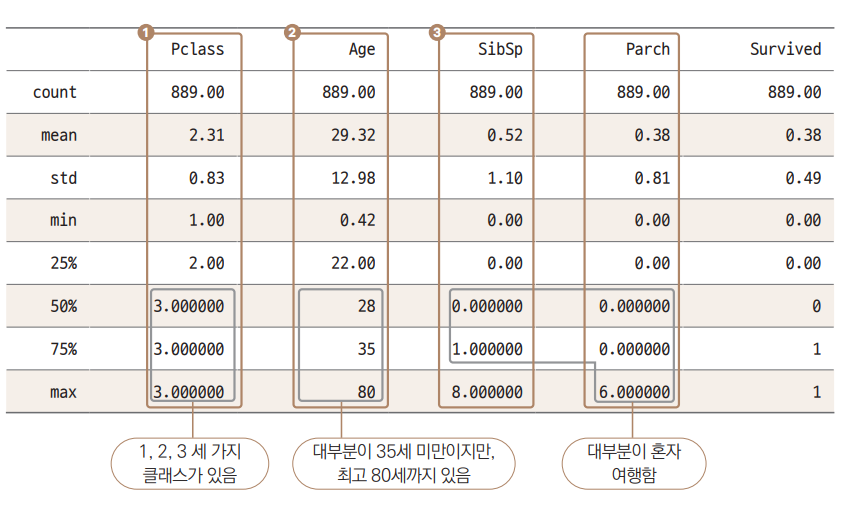
-
이번에는 통계 정보를 확인하겠습니다.
① Pclass에서 min부터 max까지의 값을 보면 1/2/3 총 3가지 값이 있습니다.
② Age는 50% 값(중앙값)이 28, 75%(상위 25%) 값이 35였다가 max가 80으로 갑자기 높아집니다. 대부분 승객이 비교적 젊은 층이지만, 일부 나이가 많은 승객들이 있다고 해석할 수 있습니다.
③ SibSp와 4 Parch는 25%(하위 25%)와 50% 값이 모두 0입니다.
④ Parch의 경우 75% 값까지 0입니다. 즉, 대부분 승객이 가족을 동반하지 않고 혼자 탑승했습니다.
data.corr( ) # 상관관계 출력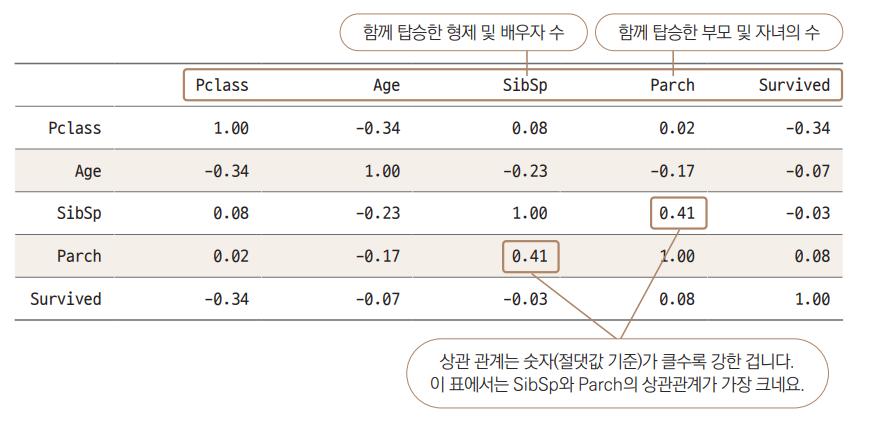
-
이번에는 각 변수의 상관관계를 확인하겠습니다.
- 상관관계는 두 변수 간의 변화가 서로 연관되었을 때, 즉 A가 증가할수록 B가 증가하거나, 반대로 A가 증가할수록 B가 감소하거나 하는 관계를 숫자로 보여줍니다.
-
결과 테이블을 보면 자료형이 object인 변수 4개가 빠져 있습니다.
-
상관관계는 숫자가 아니면 계산이 안 되기 때문에, 파이썬에서 자동으로 문자형 변수들을 제거하고 상관관계를 보여줍니다.
-
0에 가까울수록 상관관계가 없는 것
-
1 혹은 -1에 가까울수록 상관관계가 큰 겁니다.
-
-
#자동 제거 안되는 경우
# 숫자형 데이터만 포함된 새로운 DataFrame 생성
numeric_data = data.select_dtypes(include=['float64', 'int64'])
# 상관관계 계산
correlation_matrix = numeric_data.corr()
print(correlation_matrix)
#결과
Pclass Age SibSp Parch Survived
Pclass 1.000000 -0.336512 0.081656 0.016824 -0.335549
Age -0.336512 1.000000 -0.232543 -0.171485 -0.069822
SibSp 0.081656 -0.232543 1.000000 0.414542 -0.034040
Parch 0.016824 -0.171485 0.414542 1.000000 0.083151
Survived -0.335549 -0.069822 -0.034040 0.083151 1.000000
-
양수는 정적 상관, 즉 A가 증가할수록 B도 함께 증가하는 경우이며, 반대로 음수는 부적 상관으로 A가 증가할수록 B가 감소하는 경우입니다.
-
따라서 단순히 숫자가 크고 작음으로 상관관계의 크기를 판단하면 안 됩니다.
- -0.5는 0.1보다 작은 숫자지만, 음의 방향일뿐이지 상관관계는 더 크기 때문입니다.
-
-
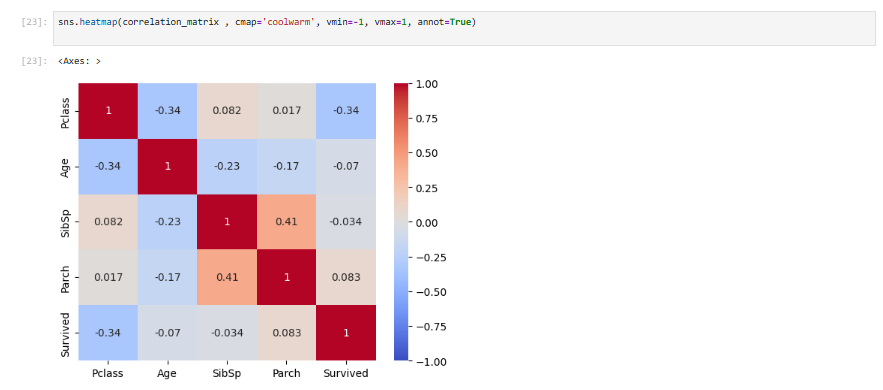
가장 큰 상관관계를 보이는 부분은 Parch와 SibSp입니다(약 0.41).
- 아마도 혼자 온 승객들이 상당히 많고, 가족을 동반할 경우 부모와 자녀, 형제와 배우자를 함께 동반하는 경우가 많기 때문이 아닐까 짐작할 수 있습니다.
-
상관관계의 강도에 대한 (절댓값 기준) 일반적인 해석
-
0.2 이하 : 상관관계가 거의 없음
-
0.2 ~ 0.4 : 낮은 상관관계
-
0.4 ~ 0.6 : 중간 수준의 상관관계
-
0.6 ~ 0.8 : 높은 상관관계
-
0.8 이상 : 매우 높은 상관관계
-
시각화
-
더 파악하기 쉬운 히트맵(heatmap)이라는 그래프를 그려보겠습니다.
-
히트맵 생성에는
sns.heatmap( )함수를 사용합니다.- 앞서 사용한 상관관계 테이블 생성 코드를 인수로 넣어주면 됩니다.
-
import matplotlib.pyplot as plt
import seaborn as sns
sns.heatmap(correlation_matrix) # 상관관계에 대한 히트맵 생성
plt.show( ) # 그래프 출력(맷플롯립과 시본이 최근 버전이면 제외해도 됨)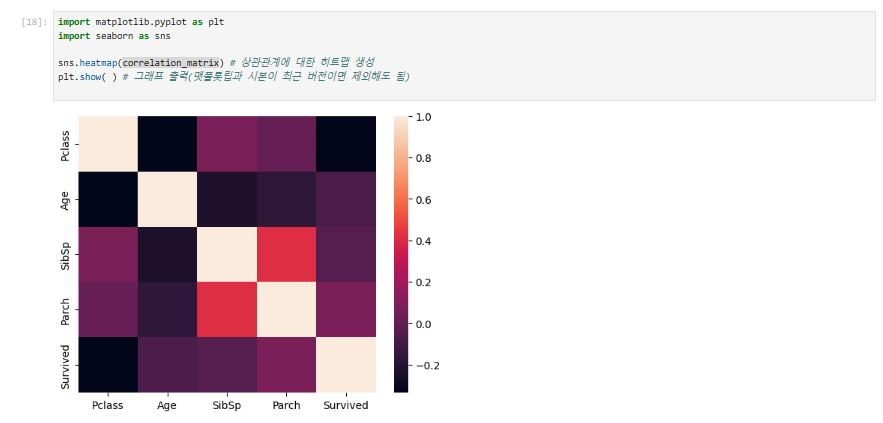
-
상관관계의 강도를 절댓값 기준으로 해석하기 때문에, 0을 기준으로 대칭이 되는 색상 배열을 사용하는 편이 더 좋습니다.
- 색상을 변경하는 매개변수를 추가해 해결
sns.heatmap(correlation_matrix , cmap='coolwarm', vmin=-1, vmax=1)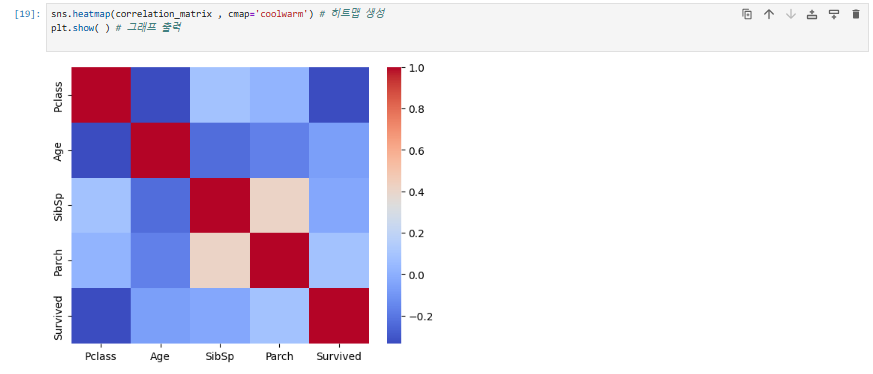
-
양수는 빨강, 음수는 파랑 계열로 표현되고 있으며, 관계가 강할수록 더 진하게 표시됩니다.
-
우측 범례를 보면 빨강과 파랑 사이에서 가장 밝은 부분이 0보다 조금 위쪽인 ① 0.4 부근에 있습니다.
-
입력된 수치의 범위가 1부터 -0.5까지라서 그래프에서는 -1 ~ +1까지가 아닌, ② -0.5 ~ +1까지로 잡아 색상을 표시했기 때문입니다.
-
sns.heatmap(correlation_matrix , cmap='coolwarm', vmin=-1, vmax=1)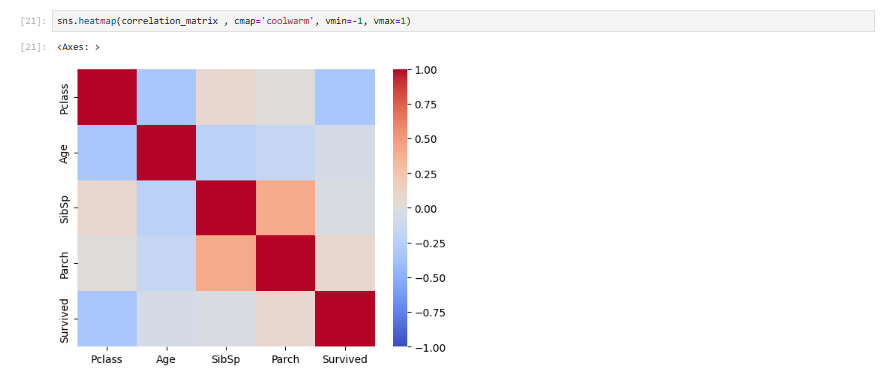
- 그래프에서 표시 범위를 -1에서 1까지로 조정하여 색상의 밸런스를 맞춰보겠습니다.
sns.heatmap(data.corr( ) , cmap='coolwarm', vmin=-1, vmax=1, annot=True)
-
vmin과 vmax 매개변수를 이용하여 데이터 범위의 최솟값과 최댓값을 지정하여 더 밸런스가 맞는 색상을 얻었습니다.
- 각 칸 안에 상관관계 수치를 표현
파이썬에서는 이와 같이 다양한 매개변수를 추가하여 활용할 수 있습니다. 매개변수는 그래프를 그릴 때 뿐만 아니라, 다양한 모듈에 적용됩니다.
- 모듈에 따라서 가지고 있는 매개변수가 다르기 때문에, 각 모듈에 맞는 매개변수를 적절히 활용해야 합니다.
전처리 : 범주형 변수 변환하기(더미 변수와 원-핫 인코딩)
-
타이타닉 데이터셋에는 자료형이 object인 변수들, 즉 데이터가 숫자가 아닌 문자인 변수가 4개 있습니다.
-
기본적으로 머신러닝 알고리즘에서는 문자열로 된 데이터를 이해하지 못합니다.
- object형까지도 처리해주는 알고리즘 대부분은 object 컬럼들을 숫자 데이터로 변환하는 기능을 제공합니다.
-
-
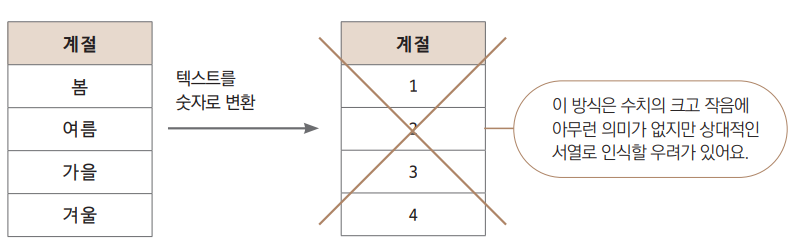
object형을 숫자화해봅시다. 단순하게는 각 값(특정 문자)을 숫자로 대체하는 방법이 있습니다.
- 계절이라는 변수의 값으로 봄, 여름, 가을, 겨울이 있다면 각각을 1, 2, 3, 4로 대체하는 방법입니다.
-
때에 따라서는 이 방법이 효과적일 때도 있으나 기본적으로 지양해야 합니다.
-
특히나 선형 모델에 이 방법을 사용하면 숫자가 상대적인 서열로 인식됩니다.
- 즉 봄(1)보다 겨울(4)이 더 큰 개념으로 학습됩니다.
-
-
이러한 문제를 피하는 데 더미 변수를 활용합니다.
-
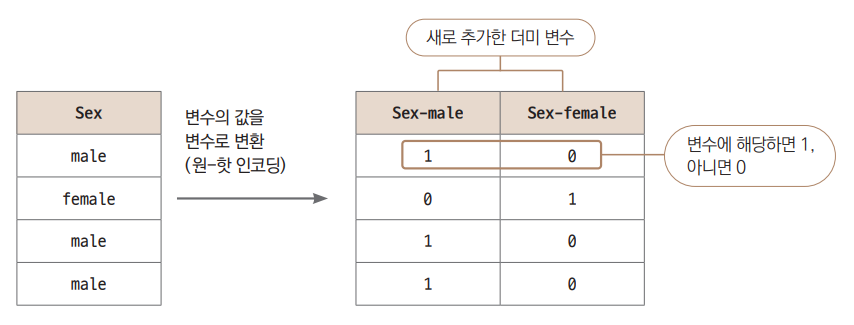
가장 쉬워보이는 Sex 변수를 가지고 설명하겠습니다.
- 이 컬럼이 가장 설명하기 쉬운 이유는 값이 male과 female 두 가지뿐이기 때문입니다.
-
-
기존에 하나던 컬럼을 각 male과 female 컬럼으로 분리했습니다.
-
그리고 하나에서 두 개로 늘어난 컬럼에는 변수에 해당하면 1, 해당하지 않으면 0을 숫자로 채웠습니다.
-
머신러닝에서는 이런 식으로 문자로 된 값을 숫자화하여 이해할 수 있게 됩니다.
-
-
이런 식으로 변환하는 것을 ‘더미(dummy) 변수를 만든다’, 혹은 원-핫 인코딩(one-hot encoding)이라고 합니다.
-
원-핫 인코딩을 할 때 한 가지 고려할 사항이 있습니다.
-
값 종류만큼 컬럼이 생성되어야 합니다.
-
예를 들어 값이 수백 수천 가지라면 어떻게 할까요? 새로운 컬럼을 수백 수천 개나 만들어야 할까요?
-
정말 중요하면 어떤 수단을 써서라도 숫자화해야겠지만, 그렇지 않다면 데이터에서 제외시키거나 다른 방법으로 처리하는 것이 좋습니다.
-
-
각 변수마다 고윳값이 몇 가지인지 살펴보겠습니다.
nunique( )함수로 고윳값 개수를 확인할 수 있습니다.
print('Name: ', data['Name'].nunique( ))
print('Sex: ', data['Sex'].nunique( ))
print('Ticket: ', data['Ticket'].nunique( ))
print('Embarked: ', data['Ticket'].nunique( ))

-
Sex에는 이미 알다시피 두 가지 값이 있고, Embarked(승선한 항구)도 3개로 그리 많지 않습니다.
- 하지만 Name이나 Ticket의 경우 고윳값이 수백 가지라서 더미 변수로 변환시키면 그 수만큼 컬럼이 생깁니다.
-
변수들이 결과를 도출하는 데 꼭 필요한지 결정 필요
-
우선은 이름에 따라 사망 여부가 갈린다고 추론하기는 어렵기 때문에 Name 변수 제외
-
Ticket은 티켓 번호, 이미 Pclass(티켓 클래스)와 컬럼을 가지고 있기 때문에 Ticket변수로 무언가 얻어낼 필요는 없다.
-
drop( )함수를 사용하여 Name과 Ticket을 제거하고head( )함수로 제대로 제거되었는지 확인
data = data.drop(['Name','Ticket'], axis=1)
data.head( )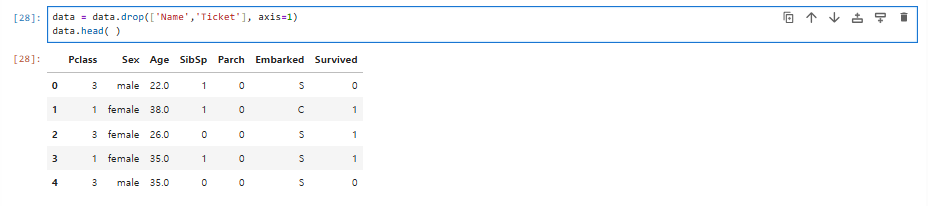
pd.get_dummies(data, columns = ['Sex','Embarked']) 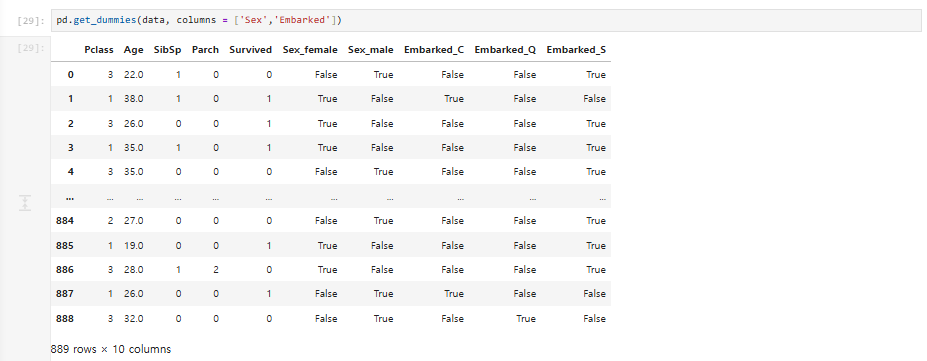
-
판다스의
get_dummies( )함수를 사용하여 문자 형태의 변수들을 원-핫-인코딩-
괄호 안에 데이터 프레임(여기서는 data)을 먼저 써주시고, columns라는 매개변수에 변환시킬 컬럼명을 리스트 형태로 넣으면 됩니다.
-
참고로 이 코드의 결과를 data에 저장하지는 않습니다.
-
pd.get_dummies(data, columns = ['Sex','Embarked'], drop_first = True)
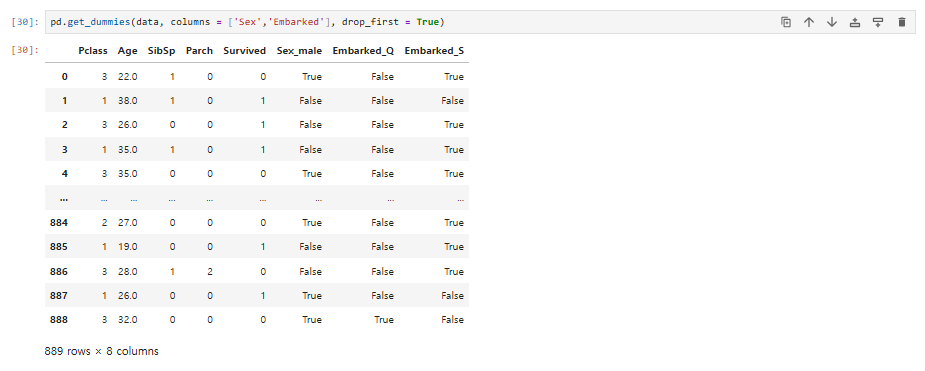
-
Sex는 Sex_female과 Sex_male로 분리되었죠. 과연 둘 다 필요할까요?
-
예를 들어, Sex_male이 0이면 당연히 이 승객은 female에 해당합니다.
-
Embarked_Q와 Embarked_S가 모두 0이면 Embarked_C에 해당하는 승객입니다.
-
즉, 우리는 더미 변수에서 고윳값 개수보다 하나를 덜 사용해도 구분하는 데 문제가 없습니다.
- 이렇게 컬럼 개수를 줄여주면 데이터 계산량이 줄어듭니다.
-
-
get_dummies( )함수는 이 기능도 제공합니다drop_first매개변수를 추가하면 됩니다.
data = pd.get_dummies(data, columns = ['Sex','Embarked'], drop_first = True)
- 이 코드는 변환된 모습을 보여줄 뿐 data에 저장하지 않습니다. data에 최종 데이터를 저장해줍시다.
모델링 및 예측하기
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression #로지스틱 회귀 임포트
X = data.drop('Survived', axis = 1) #데이터셋에서종속변수 제거 후 저장
y = data['Survived'] #데이터셋에서 종속변수만 저장
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 100) #학습셋, 시험셋 분리
model = LogisticRegression() #로지스틱 회귀 모델 생성
model.fit(X_train, y_train) #모델 학습
pred = model.predict(X_test) #예측
예측 모델 평가하기
-
이번 데이터 목푯값은 0과 1로 나누어진 이진분류 (Binary classification)이기 때문에 RMSE는 평가에 적합하지 않습니다.
-
다양한 이진분류 평가 지표
- 정확도(accuracy), 오차 행렬, 정밀도 (precision), 재현율(recall), F1 Score, 민감도, 특이도, AUC 등이 있습니다.
-
그중 가장 간단한 정확도를 사용하겠습니다.
-
정확도는 예측값과 실젯값을 비교하여 얼마나 맞추었는지를 확인하는 겁니다.
-
즉 시험셋 100개를 예측하고, 그중 90개를 정확히 맞췄다면 정확도는 0.9가 되고, 모두 맞추면 1.0이 됩니다.
-
from sklearn.metrics import accuracy_score # 정확도 라이브러리 임포트
accuracy_score(y_test, pred) # 실젯값과 예측값으로 정확도 계산
#결과
0.7808988764044944
이해하기 : 피처 엔지니어링
피처 엔지니어링이란?
-
피처 엔지니어링(Feature Engineering) 이란 기존 데이터를 손보아 더 나은 변수를 만드는 기법입니다(특징 공학 또는 특성 공학이라고도 합니다).
-
앞에서 경험한 더미 변수를 만드는 일도 일종의 피처 엔지니어링입니다.
- 더미 변수를 쓰지 않았다면 해당 컬럼(Sex와 Embarked)을 모두 버려야 했으나, 더미 변수로 만들어 예측에 도움이 되는 변수를 얻은 겁니다.
머신러닝에서 피처 엔지니어링의 중요성
-
피처 엔지니어링은 머신러닝에 있어서 엄청 중요합니다.
-
적합한 머신러닝 알고리즘을 선택하고 하이퍼파라미터를 튜닝하는 일도 중요하지만, 좋은 피처를 하나 더 마련하는 일만큼 강력한 무기는 없습니다.
- 여기서 피처라 함은 독립변수의 다른 표현입니다.
-
독립변수는 흔히 통계 영역에서 쓰이는 용어이고, 피처는 머신러닝에서 더 흔하게 사용됩니다. 이 책에서는 두 용어를 혼용합니다.
-
도메인 지식과 피처 엔지니어링
-
피처 엔지니어링에서는 도메인 지식의 활용이 중요합니다.
-
데이터에 대한 사전 지식이 있으면 어떤 변수를 어떻게 바꾸면 더 나은 피처를 얻을 수 있을지 생각해볼 여지가 있습니다.
-
물론 도메인 지식 없이 몇몇 변수를 단순히 곱하거나 나누어서 무작위로 다양한 변수들을 만들어내는 것만으로도 도움이 될 때도 있습니다만, 도메인 지식을 바탕으로 정확한 목적을 가지고 수행하는 피처 엔지니어링이 더욱 효율적입니다.
선형모델과 다중공선성 문제
-
선형 회귀 분석과 로지스틱 회귀 분석을 선형 모델이라고 하는데, 이러한 선형 모델에서는 다중공선성(Multicollinearity) 문제를 주의해야 합니다.
-
다중공선성은 독립변수 사이에 상관관계가 높은 때에 발생하는 문제입니다.
-
예를 들어, 두 독립변수 A, B는 모두 목표 변수를 양의 방향으로 이끄는 계수를 가지고 있을 때 A와 B의 상관관계가 매우 높다면, y가 증가한 이유가 A 때문인지 B 때문인지 명확하지 않습니다.
-
그래서 그때그때 데이터의 특성에 따라 변덕스러운 결과를 보여주는 문제가 발생합니다.
-
-
다중공선성 문제는 상관관계가 높은 변수 중 하나를 제거하거나, 둘을 모두 포괄시키는 새로운 변수를 만들거나, PCA와 같은 방법으로 차원 축소를 수행해 해결할 수 있습니다.
- 이 장에서 다루는 데이터에서는 Parch와 SibSp가 그나마 조금 강한 상관관계를 보였으므로 이 둘을 새로운 변수로 만들겠습니다.
변수 합치기와 직관
-
사실 꼭 상관관계 수치 때문이 아니더라도, 직관적으로 이 두 변수를 합쳐보고 싶다는 생각이 들 수도 있습니다.
-
Parch는 부모와 자식, SibSp는 형제/자매와 배우자로, 결국 모두 가족구성원이라는 공통점이 있습니다.
-
그렇다면 이 두 변수를 합하여 가족구성원 숫자를 나타내는 변수로 만들어보면 어떨까요?
-
-
두 변수를 합하여
family라는 컬럼을 만들고 Parch와 SibSp 컬럼을 제거하겠습니다.
data['family'] = data['SibSp'] + data['Parch'] # SibSp와 Parch 변수 합치기
data.drop(['SibSp','Parch'], axis=1, inplace=True) # SibSp와 Parch 변수 삭제
data.head( ) # 5행 출력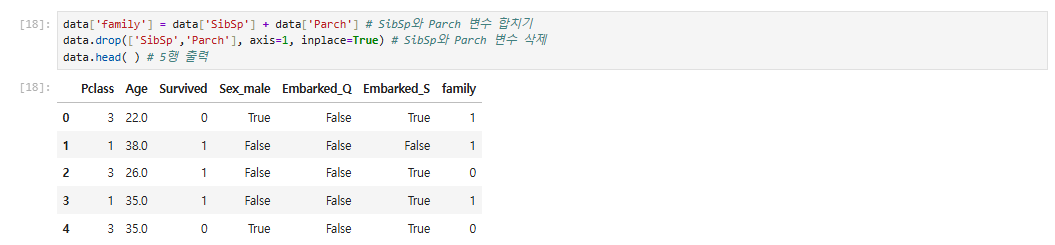
모델링 과정 재실행
- 피처 엔지니어링을 마쳤으니 이 데이터를 가지고 모델링 과정부터 평가까지 다시 진행하겠습니다.
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# (data 전처리 부분)
X = data.drop('Survived', axis=1)
y = data['Survived']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=100)
model = LogisticRegression()
model.fit(X_train, y_train)
pred = model.predict(X_test)
accuracy = accuracy_score(y_test, pred) # ← 정확도 계산
print(accuracy)
#결과
0.7921348314606742

-
총 독립변수 수가 하나 줄어지만 기존보다 정확도가 0.012 정도 높아졌습니다.
- 이렇게 모델링은 한 번만에 끝나는 것이 아니라, 다양한 시도를 해가며 수없이 재반복해 더 나은 결과물을 얻어내는 과정입니다.
피처 엔지니어링의 확장성과 정답 없음
-
여기서는 0.4 정도의 상관관계가 있는 변수를 합쳐주면 더 좋은 결과를 얻을 수 있을 겁니다.
- 그런데 언제나 유효한 기준은 아닙니다. 피처 엔지니어링에는 정답이 없습니다.
-
데이터 특성이나 도메인 지식에 따라 무궁무진하게 확장할 수 있습니다.
- 물론, 그 어떤 피처 엔지니어링도 수행할 수 없는 경우도 있겠죠.
-
그렇기 때문에 피처 엔지니어링은 매우 중요하면서도 아주 까다롭습니다.
이해하기 : 로지스틱 회귀
로지스틱 회귀가 이진분류에 적합한 이유
-
타이타닉 데이터처럼 이진분류 문제(목표값이 0과 1)는 왜 선형 회귀 분석을 쓰지 않을까요?
-
0과 1도 숫자이긴 하지만, 선형 회귀로 예측하면 아래와 같은 문제가 생깁니다.
-
x(독립변수)가 커지거나 작아지면 예측값이 1보다 커지거나 0보다 작아지는 경우가 생깁니다.
-
우리는 0과 1 사이에서만 결과가 나오길 바랍니다.
-
-
선형회귀의 예시
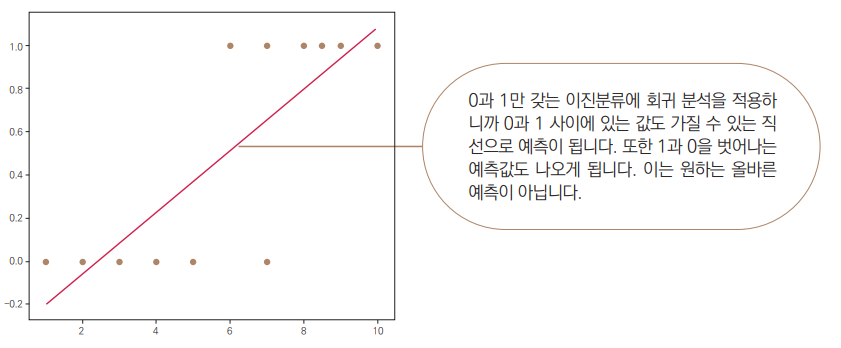
-
x축: 독립변수 1개
-
y축: 0 또는 1 (점)
-
-
선형 회귀선(빨간선)은 어떤 범위에선 1을 넘고, 또 어떤 범위에선 0 아래(음수)도 예측합니다.
-
이 문제를 억지로 해결하려면 결과값이 1.7이면 1, -0.3은 0으로 강제 변환할 수 있습니다.
하지만 이런 처리는 일반적으로 정확하지 않습니다.
로지스틱 회귀 분석의 원리
-
로지스틱 회귀는 이런 문제를 해결합니다.
-
로지스틱 함수(Logistic function)라는 S자 형태의 곡선을 사용.
-
직선을 S곡선으로 변환하여 예측값이 항상 0~1 사이에 있도록 만듭니다.
-
x값이 커질수록 1에 가까워지지만, 절대 1을 넘지 않고, x값이 작아질수록 0에 수렴하지만 음수로 내려가지 않습니다.
-
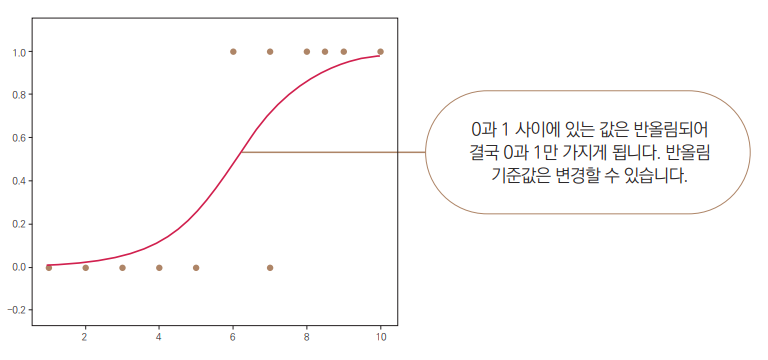
-
로지스틱 함수 공식
-
P: 결과가 1일 확률 -
a: 절편 -
b: 기울기 -
X: 입력 변수 -
e는 자연로그의 밑(약 2.718)이고, 지수부
a+bX는 1차 함수의 형태와 같습니다.- e의 역할은 "직선"을 S자형 곡선(시그모이드)로 변환한다는 점입니다.
-
예측값 0.3 → 1일 확률이 30%
예측값 0.7 → 1일 확률이 70%
- 일반적으로
predict()함수는 0.5 기준으로 0/1로 변환한 결과를 보여주지만, 0~1 사이 확률이 궁금하다면predict_proba()함수를 사용하면 됩니다.
학습 마무리
핵심 용어 정리
-
로지스틱 회귀
- 선형 회귀 분석을 기반으로 한 모델로, 연속형 종속변수가 아닌 이진분류 문제를 위한 알고리즘입니다.
-
피처 엔지니어링
- 기존 변수에서 더 나은 변수를 도출해내는 작업입니다. 실제로 Parch와 SibSp를 통해 새로운 변수 family를 만들어보았습니다.
-
상관관계
- 두 변수 간의 연관성을 나타내며, 상관관계가 높으면 절댓값이 1에 가까움.
-
PCA(주성분 분석)
- Principal Component Analysis의 약자, 주성분 분석이라고도 합니다.
-
다중공선성 문제
-
변수 간의 강한 상관관계가 있을 때 발생하는 문제.
-
선형 모델은 독립변수 간의 독립성을 전제로 하므로 이를 해결할 필요가 있습니다.
-
-
더미 변수와 원-핫 인코딩
-
범주(카테고리) 형태(혹은 문자 형태) 변수를 숫자로 표현하는 방법입니다.
-
변수의 고윳값 별로 새로운 컬럼을 만들어 1 또는 0으로 표시합니다.
-
새로운 함수와 라이브러리
-
len( ): 데이터의 길이 확인 -
pandas.DataFrame.nunique( ): 고윳값의 개수 확인 -
pandas.DataFrame.drop( ): 데이터프레임의 행/열 제거 -
pandas.get_dummies( ): 더미 변수로 변환 -
sns.heatmap( ): 히트맵 그리기
참고
-
predict_proba()를 사용하면 확률값(0과 1 사이 값)을 직접 확인할 수 있습니다. -
LightGBM 등 다른 분류모델에서 기준 값을 0.5가 아닌 다른 값으로 분류할 수도 있습니다.
