선형 회귀(Linear Regression): 릿지 회귀 (Ridge Regression), 라쏘 회귀 (Lasso Regression), 엘라스틱 넷 (Elastic Net)
Artificial Intelligence
1. 릿지 회귀 (Ridge Regression)
-
릿지 회귀는 선형 회귀(Linear Regression)에 L2 정규화(Tikhonov 정규화)를 적용하여 오버피팅(Overfitting)을 방지하는 방법입니다.
- 기본 선형 회귀는 잔차(residual)를 최소화하며 데이터를 학습하지만, 고차원 데이터나 다중공선성(multicollinearity)이 있는 데이터에서는 과도하게 학습되어 오버피팅이 일어날 가능성이 큽니다.
L2 정규화란?
-
L2 정규화는 모델의 손실 함수에 가중치 벡터(모델의 파라미터 )의 L2 노름(제곱합)을 추가로 포함시키는 방식입니다.
- 가중치 값이 과도하게 커지는 것을 방지하며, 불필요한 모델 복잡도를 줄여줍니다.
릿지 회귀의 목적 함수
-
일반 선형 회귀의 목적 함수에 패널티(regularization term)를 추가한 형태
-
: 정규화의 강도를 조절하는 하이퍼파라미터로, 이 값을 조정해 가중치의 크기를 제어합니다.
-
: 일반 선형 회귀와 동일
-
: 가중치에 페널티를 적용
-
-
: 각 피처의 가중치 제곱을 패널티로 추가. 따라서 가중치 값이 커질수록 페널티가 커지고 모델이 이를 줄이려 노력합니다.
-
Ridge 주요 특성
-
장점
-
과적합 방지
-
다중공선성 문제 완화
-
-
단점
- 릿지 회귀는 모든 피처에 대해 작은(non-zero) 가중치를 유지하므로 피처 선택(feature selection)은 하지 못합니다.
사용 예제:
from sklearn.linear_model import Ridge
ridge = Ridge(alpha=1.0) # alpha는 λ와 동일
ridge.fit(X_train, y_train)
y_pred = ridge.predict(X_test)2. 라쏘 회귀 (Lasso Regression)
라쏘 회귀는 선형 회귀 모델에 L1 정규화를 적용하는 회귀 기법입니다. L1 정규화는 특정 피처의 가중치를 0으로 축소할 수 있어, 결과적으로 피처 셀렉션(feature selection) 역할을 수행합니다.
L1 정규화란?
- L1 정규화는 손실 함수에 피처 가중치 벡터의 L1 노름(절댓값 합)을 패널티로 추가합니다. 이로 인해 일부 피처의 가중치가 0으로 수렴하게 되어 중요하지 않은 피처가 모델에서 제외됩니다.
라쏘 회귀의 목적 함수
-
- : 정규화 강도를 조정하며, 값이 클수록 더 많은 가중치를 0으로 만듦.
Lasso 주요 특성
-
장점
-
불필요한 피처 제거 → 피처 선택 가능
-
과적합 방지
-
-
단점
-
피처 간 상관관계가 높은 경우, 어느 피처를 제거할지 랜덤하게 작동할 수 있음.
-
높은 차원 데이터(피처 개수가 샘플 수보다 많은 경우)에서 성능이 제한될 수 있음.
-
사용 예제
from sklearn.linear_model import Lasso
lasso = Lasso(alpha=0.1) # alpha는 λ와 동일
lasso.fit(X_train, y_train)
y_pred = lasso.predict(X_test)3. 엘라스틱 넷 (Elastic Net)
- 엘라스틱 넷은 릿지 회귀와 라쏘 회귀의 장점을 결합한 방법입니다. L1 정규화와 L2 정규화를 함께 사용하여 모델이 불필요하게 복잡해지는 것을 방지하면서도 피처 선택 기능을 추가로 제공합니다.
엘라스틱 넷의 목적 함수
-
-
: L1 정규화 강도
-
: L2 정규화 강도
-
두 규제 항목의 가중치를 동시에 조정하여 더 유연하고 안정적인 모델 학습 가능.
-
ElasticNet 주요 특성
-
장점
-
피처 선택 가능 (L1)
-
과적합 방지 및 다중공선성 완화 (L2)
-
고차원 데이터에서 효과적
-
-
단점
- 하이퍼파라미터 튜닝(, )이 증가해 복잡도 증가
사용 예제
from sklearn.linear_model import ElasticNet
elastic_net = ElasticNet(alpha=1.0, l1_ratio=0.5) # l1_ratio는 L1(Lasso)의 가중치 비율
elastic_net.fit(X_train, y_train)
y_pred = elastic_net.predict(X_test)-
alpha: 전체 정규화 강도
-
l1_ratio: 이면 릿지 회귀와 같고, 이면 라쏘 회귀와 같음. 는 L1과 L2를 균등하게 결합.
요약 비교
| 모델 | 정규화 방식 | 장점 | 단점 |
|---|---|---|---|
| 릿지 회귀 (Ridge Regression) | L2 | 과적합 방지, 다중공선성 완화 | 피처를 선택하지 못함 (모든 피처 유지) |
| 라쏘 회귀 (Lasso Regression) | L1 | 과적합 방지, 불필요한 피처 제거 가능 (피처 선택 기능) | 피처 간 상관관계가 높은 경우 동작 불안정 |
| 엘라스틱 넷 (Elastic Net) | L1 + L2 | 과적합 방지, 피처 선택 가능, 상관관계 높은 피처에서도 잘 동작 | 하이퍼파라미터 튜닝(α, l1_ratio)의 복잡성 증가 |
언제 어떤 회귀를 사용해야 할까?
-
릿지 회귀 (Ridge Regression): 피처가 많고 다중공선성이 큰 경우, 하지만 모든 피처를 보존해야 하는 경우.
-
다중공선성(Multicollinearity)은 회귀 분석(특히 선형 회귀)에서 발생하는 문제로, 독립 변수(피처)들 간에 높은 상관관계가 있는 경우를 말합니다.
- 즉, 두 개 이상의 입력 변수(피처)가 서로 강하게 연관되어 있어서, 해당 변수들이 모델 학습에 있어 중복된 정보를 제공할 때를 의미합니다.
-
-
라쏘 회귀 (Lasso Regression): 불필요한 피처를 제거하고 싶거나, 중요한 피처만 남기고 싶을 때.
-
엘라스틱 넷 (Elastic Net): 고차원 데이터에서 L1, L2 방식의 조합으로 안정적 학습이 필요할 때.
실습
샘플 데이터 생성
-
예제 데이터는 sklearn의 보스턴 주택 데이터셋(또는 사용자가 직접 준비한 데이터)을 사용
-
Ridge, Lasso, ElasticNet 회귀를 학습하고 각 알고리즘이 데이터를 모델링한 결과를 시각화할 준비를 합니다.
# 필요한 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Ridge, Lasso, ElasticNet
from sklearn.datasets import make_regression
# 샘플 데이터 생성 (선형 회귀용)
X, y = make_regression(n_samples=100, n_features=1, noise=20, random_state=42) # 1차원 데이터셋
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 스케일링 (특히 Lasso나 ElasticNet은 스케일링이 중요함)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
코드 설명
X, y = make_regression(n_samples=100, n_features=1, noise=20, random_state=42)-
위 코드는
sklearn.datasets의make_regression함수로 샘플 선형 회귀 데이터를 생성합니다.-
n_samples=100: 데이터 샘플 100개 생성. -
n_features=1: 입력 변수(피처) 1개 사용. -
noise=20: 출력값(y)에 랜덤 노이즈를 추가(값이 클수록 산포 증가). -
random_state=42: 결과를 재현 가능하게 만드는 난수 시드값.
-
X: 입력 데이터 (크기:(100, 1)) -
y: 출력 데이터 (크기:(100,))
-
-
이 데이터는 기울기와 노이즈가 포함된 선형 회귀 문제를 학습하기 위한 가상의 데이터셋입니다.
- 즉,
y = X * 계수 + 노이즈형태입니다.
- 즉,
시각적으로 확인
- 선형 관계 + 노이즈가 포함된 데이터 생성
import matplotlib.pyplot as plt
plt.scatter(X, y, label="Data with noise", color="blue")
plt.title("Synthetic Regression Data")
plt.xlabel("X")
plt.ylabel("y")
plt.legend()
plt.show()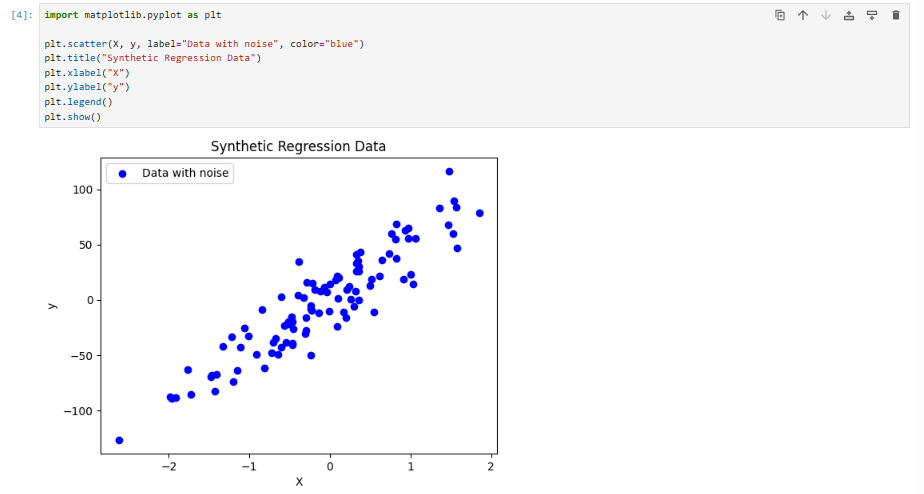
모델 학습(Ridge, Lasso, ElasticNet)
# Ridge 회귀
ridge = Ridge(alpha=1.0)
ridge.fit(X_train, y_train)
ridge_preds = ridge.predict(X_test)
# Lasso 회귀
lasso = Lasso(alpha=0.1)
lasso.fit(X_train, y_train)
lasso_preds = lasso.predict(X_test)
# ElasticNet 회귀
elastic_net = ElasticNet(alpha=1.0, l1_ratio=0.5)
elastic_net.fit(X_train, y_train)
elastic_preds = elastic_net.predict(X_test)
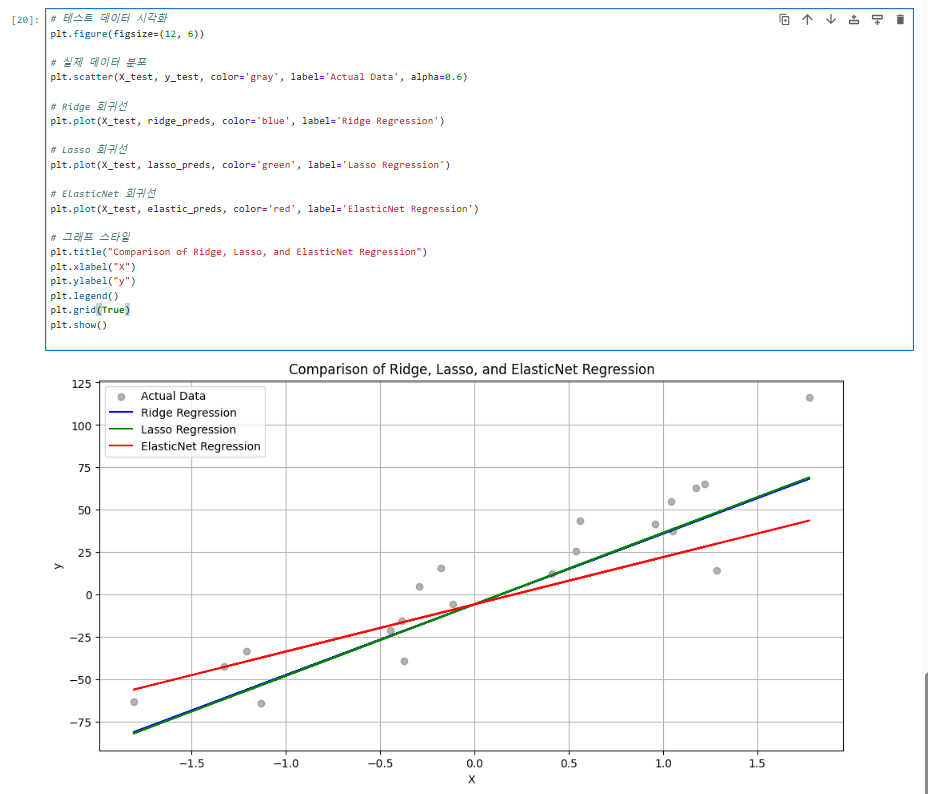
시각화
-
데이터 분포와 회귀선 시각화
- 각 모델에 의한 회귀선을 데이터와 함께 시각화합니다.
# 테스트 데이터 시각화
plt.figure(figsize=(12, 6))
# 실제 데이터 분포
plt.scatter(X_test, y_test, color='gray', label='Actual Data', alpha=0.6)
# Ridge 회귀선
plt.plot(X_test, ridge_preds, color='blue', label='Ridge Regression')
# Lasso 회귀선
plt.plot(X_test, lasso_preds, color='green', label='Lasso Regression')
# ElasticNet 회귀선
plt.plot(X_test, elastic_preds, color='red', label='ElasticNet Regression')
# 그래프 스타일
plt.title("Comparison of Ridge, Lasso, and ElasticNet Regression")
plt.xlabel("X")
plt.ylabel("y")
plt.legend()
plt.grid(True)
plt.show()
-
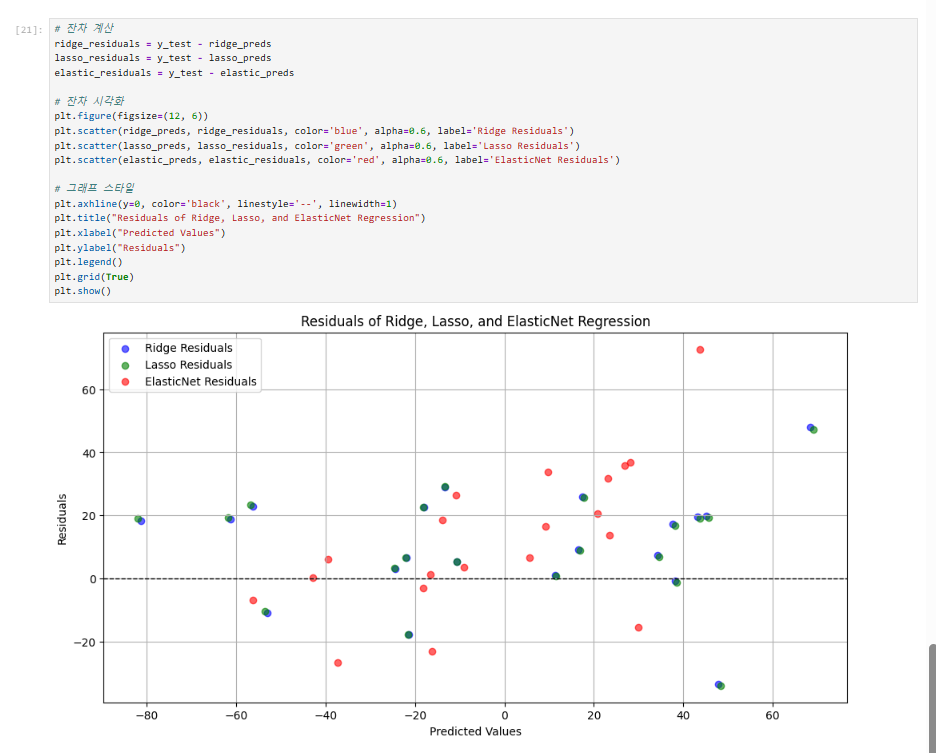
잔차(residual) 분석
- 잔차 분석은 모델의 예측값과 실제값 사이의 차이를 나타내며, 모델의 적합성을 평가하는 데 유용합니다.
# 잔차 계산
ridge_residuals = y_test - ridge_preds
lasso_residuals = y_test - lasso_preds
elastic_residuals = y_test - elastic_preds
# 잔차 시각화
plt.figure(figsize=(12, 6))
plt.scatter(ridge_preds, ridge_residuals, color='blue', alpha=0.6, label='Ridge Residuals')
plt.scatter(lasso_preds, lasso_residuals, color='green', alpha=0.6, label='Lasso Residuals')
plt.scatter(elastic_preds, elastic_residuals, color='red', alpha=0.6, label='ElasticNet Residuals')
# 그래프 스타일
plt.axhline(y=0, color='black', linestyle='--', linewidth=1)
plt.title("Residuals of Ridge, Lasso, and ElasticNet Regression")
plt.xlabel("Predicted Values")
plt.ylabel("Residuals")
plt.legend()
plt.grid(True)
plt.show()
-
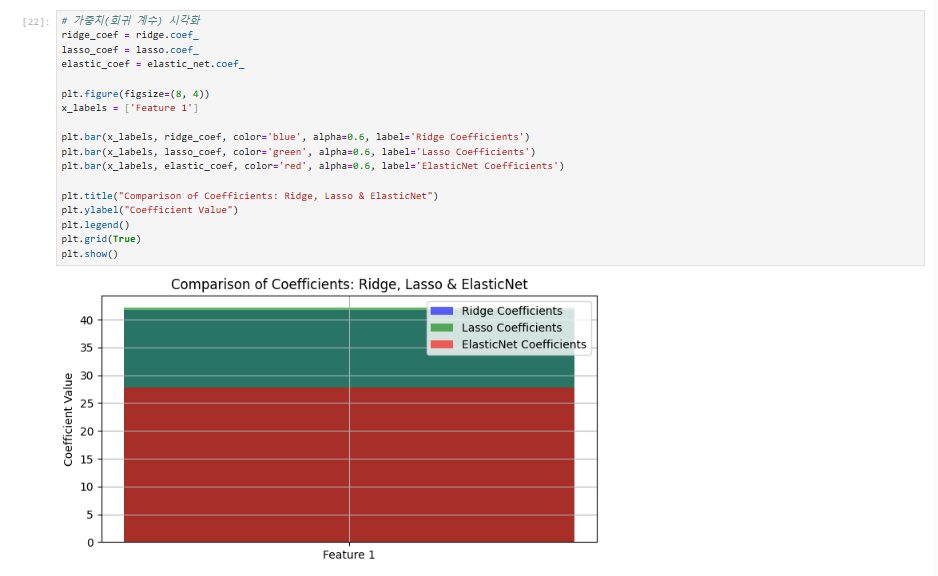
가중치(weight) 비교 시각화 (각 모델의 계수 비교)
- 릿지, 라쏘, 엘라스틱넷 모델의 가중치를 비교하여 정규화의 영향을 확인합니다.
# 가중치(회귀 계수) 시각화
ridge_coef = ridge.coef_
lasso_coef = lasso.coef_
elastic_coef = elastic_net.coef_
plt.figure(figsize=(8, 4))
x_labels = ['Feature 1']
plt.bar(x_labels, ridge_coef, color='blue', alpha=0.6, label='Ridge Coefficients')
plt.bar(x_labels, lasso_coef, color='green', alpha=0.6, label='Lasso Coefficients')
plt.bar(x_labels, elastic_coef, color='red', alpha=0.6, label='ElasticNet Coefficients')
plt.title("Comparison of Coefficients: Ridge, Lasso & ElasticNet")
plt.ylabel("Coefficient Value")
plt.legend()
plt.grid(True)
plt.show()
-
모델의 성능 평가 (MSE, R²)
- 회귀 모델의 성능을 수치적으로 비교하기 위해 평균 제곱 오차(MSE)와 결정 계수(R²)를 확인합니다.
📌 R² 값의 의미
1.0에 가까울수록 모델이 데이터를 잘 설명하고 있다는 의미입니다.
- R² = 1이면, 모든 데이터가 완벽하게 예측되었다는 뜻입니다(모델이 최적의 성능을 보임).
0에 가까울수록 설명력이 떨어지는 모델입니다.- R² = 0이면, 모델이 데이터를 전혀 설명하지 못하고 있다는 뜻입니다(단순 평균 수준의 예측).
R²가 음수일 수도 있습니다.
- 이 경우 모델이 타깃 변수를 예측하는 데 완전히 실패했음을 뜻합니다. 모델의 예측이 단순히 평균값을 사용하는 것보다 나쁠 정도로 부정확하다는 의미입니다.
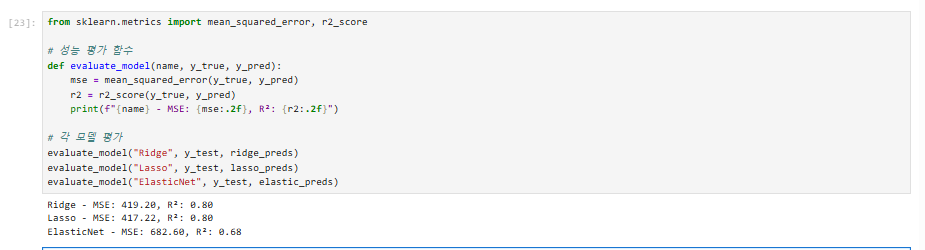
from sklearn.metrics import mean_squared_error, r2_score
# 성능 평가 함수
def evaluate_model(name, y_true, y_pred):
mse = mean_squared_error(y_true, y_pred)
r2 = r2_score(y_true, y_pred)
print(f"{name} - MSE: {mse:.2f}, R²: {r2:.2f}")
# 각 모델 평가
evaluate_model("Ridge", y_test, ridge_preds)
evaluate_model("Lasso", y_test, lasso_preds)
evaluate_model("ElasticNet", y_test, elastic_preds)