래는 당장 노트북에서 실행 가능한 수준으로 만든
전처리 → 모델( HistGradientBoostingRegressor + ExponentialSmoothing ) 훈련 → FastAPI 서비스 구성까지 한 번에 보여주는 예제입니다.
- 데이터: 간단한 가상 매출 시계열 + 외부 특성(features)
- 모델 전략:
- 시계열 Level/Trend/Seasonality → ExponentialSmoothing
- 외부 특성(요일, 프로모션 여부 등) → HistGradientBoostingRegressor
- 최종 예측 = 시계열 베이스라인 + ML 보정값(residual boosting)
- FastAPI:
uvicorn main:app --reload로 즉시 실행 가능- 데이터 크기 작아서 노트북에서도 충분히 가능
1. 전체 구조
-
데이터 로딩 및 전처리
-
ExponentialSmoothing으로 baseline 예측
-
y_train→ 과거 매출 시계열 데이터 (y만 필요) -
trend="add"→ 매출이 시간에 따라 선형적으로 증가/감소한다고 가정 -
seasonal="add"→ 매출이 일정 주기로 흔들리는 계절성을 더하는 방식 -
seasonal_periods=7→ 7일 주기(주간 패턴)이 있다고 가정- 예: 주말에 높고 평일에 낮고 같은 패턴
-
fit()→ 모델 파라미터를 학습 (level, trend slope, seasonal pattern 등)
-
-
HGBR로 residual(잔차) 예측
-
이 residual을 머신러닝(XGB, HGB 등)이 학습하여 시계열 모델의 부족한 부분을 보완함.
-
실제 값(sales), 시계열 모델 baseline 예측값(baseline)
-
residual = 실제값 - baseline
-
-
두 모델 결합
-
Exponential Smoothing(Holt-Winters)은 X를 넣는 방식이 아니다.
-
구조 자체가 y의 과거값 기반 모델이라 X 인자를 받을 수 없음.
-
X를 쓰고 싶으면 ML이나 SARIMAX, Prophet 사용해야 한다.
-
지금 작성한 baseline → residual → ML 방식이 가장 흔한 실무 패턴.
-
-
FastAPI endpoint 구성
2. 예제 코드 (바로 실행 가능)
requirements.txt
pandas
numpy
scikit-learn
statsmodels
fastapi
uvicornjupyter notebook
# requirements
!pip install pandas numpy scikit-learn statsmodels fastapi uvicorn
Requirement already satisfied: pandas in c:\ann\env\lib\site-packages (2.3.3)
Requirement already satisfied: numpy in c:\ann\env\lib\site-packages (2.3.4)
Requirement already satisfied: scikit-learn in c:\ann\env\lib\site-packages (1.7.2)
Requirement already satisfied: statsmodels in c:\ann\env\lib\site-packages (0.14.5)
Collecting fastapi
Downloading fastapi-0.122.0-py3-none-any.whl.metadata (30 kB)
Collecting uvicorn
Using cached uvicorn-0.38.0-py3-none-any.whl.metadata (6.8 kB)
Requirement already satisfied: python-dateutil>=2.8.2 in c:\ann\env\lib\site-packages (from pandas) (2.9.0.post0)
Requirement already satisfied: pytz>=2020.1 in c:\ann\env\lib\site-packages (from pandas) (2025.2)
Requirement already satisfied: tzdata>=2022.7 in c:\ann\env\lib\site-packages (from pandas) (2025.2)
Requirement already satisfied: scipy>=1.8.0 in c:\ann\env\lib\site-packages (from scikit-learn) (1.16.3)
Requirement already satisfied: joblib>=1.2.0 in c:\ann\env\lib\site-packages (from scikit-learn) (1.5.2)
Requirement already satisfied: threadpoolctl>=3.1.0 in c:\ann\env\lib\site-packages (from scikit-learn) (3.6.0)
Requirement already satisfied: patsy>=0.5.6 in c:\ann\env\lib\site-packages (from statsmodels) (1.0.2)
Requirement already satisfied: packaging>=21.3 in c:\ann\env\lib\site-packages (from statsmodels) (25.0)
Collecting starlette<0.51.0,>=0.40.0 (from fastapi)
Downloading starlette-0.50.0-py3-none-any.whl.metadata (6.3 kB)
Collecting pydantic!=1.8,!=1.8.1,!=2.0.0,!=2.0.1,!=2.1.0,<3.0.0,>=1.7.4 (from fastapi)
Downloading pydantic-2.12.5-py3-none-any.whl.metadata (90 kB)
---------------------------------------- 0.0/90.6 kB ? eta -:--:--
---------------------------------------- 90.6/90.6 kB 2.5 MB/s eta 0:00:00
Requirement already satisfied: typing-extensions>=4.8.0 in c:\ann\env\lib\site-packages (from fastapi) (4.15.0)
Collecting annotated-doc>=0.0.2 (from fastapi)
Downloading annotated_doc-0.0.4-py3-none-any.whl.metadata (6.6 kB)
Collecting click>=7.0 (from uvicorn)
Downloading click-8.3.1-py3-none-any.whl.metadata (2.6 kB)
Requirement already satisfied: h11>=0.8 in c:\ann\env\lib\site-packages (from uvicorn) (0.16.0)
Requirement already satisfied: colorama in c:\ann\env\lib\site-packages (from click>=7.0->uvicorn) (0.4.6)
Collecting annotated-types>=0.6.0 (from pydantic!=1.8,!=1.8.1,!=2.0.0,!=2.0.1,!=2.1.0,<3.0.0,>=1.7.4->fastapi)
Using cached annotated_types-0.7.0-py3-none-any.whl.metadata (15 kB)
Collecting pydantic-core==2.41.5 (from pydantic!=1.8,!=1.8.1,!=2.0.0,!=2.0.1,!=2.1.0,<3.0.0,>=1.7.4->fastapi)
Downloading pydantic_core-2.41.5-cp311-cp311-win_amd64.whl.metadata (7.4 kB)
Collecting typing-inspection>=0.4.2 (from pydantic!=1.8,!=1.8.1,!=2.0.0,!=2.0.1,!=2.1.0,<3.0.0,>=1.7.4->fastapi)
Using cached typing_inspection-0.4.2-py3-none-any.whl.metadata (2.6 kB)
Requirement already satisfied: six>=1.5 in c:\ann\env\lib\site-packages (from python-dateutil>=2.8.2->pandas) (1.17.0)
Requirement already satisfied: anyio<5,>=3.6.2 in c:\ann\env\lib\site-packages (from starlette<0.51.0,>=0.40.0->fastapi) (4.11.0)
Requirement already satisfied: idna>=2.8 in c:\ann\env\lib\site-packages (from anyio<5,>=3.6.2->starlette<0.51.0,>=0.40.0->fastapi) (3.11)
Requirement already satisfied: sniffio>=1.1 in c:\ann\env\lib\site-packages (from anyio<5,>=3.6.2->starlette<0.51.0,>=0.40.0->fastapi) (1.3.1)
Downloading fastapi-0.122.0-py3-none-any.whl (110 kB)
---------------------------------------- 0.0/110.7 kB ? eta -:--:--
---------------------------------------- 110.7/110.7 kB 3.2 MB/s eta 0:00:00
Using cached uvicorn-0.38.0-py3-none-any.whl (68 kB)
Downloading annotated_doc-0.0.4-py3-none-any.whl (5.3 kB)
Downloading click-8.3.1-py3-none-any.whl (108 kB)
---------------------------------------- 0.0/108.3 kB ? eta -:--:--
---------------------------------------- 108.3/108.3 kB 6.1 MB/s eta 0:00:00
Downloading pydantic-2.12.5-py3-none-any.whl (463 kB)
---------------------------------------- 0.0/463.6 kB ? eta -:--:--
--------------- ------------------------ 174.1/463.6 kB 5.3 MB/s eta 0:00:01
--------------------------- ------------ 317.4/463.6 kB 3.9 MB/s eta 0:00:01
---------------------------------------- 463.6/463.6 kB 3.6 MB/s eta 0:00:00
Downloading pydantic_core-2.41.5-cp311-cp311-win_amd64.whl (2.0 MB)
---------------------------------------- 0.0/2.0 MB ? eta -:--:--
--- ------------------------------------ 0.2/2.0 MB 3.3 MB/s eta 0:00:01
----- ---------------------------------- 0.3/2.0 MB 2.9 MB/s eta 0:00:01
-------- ------------------------------- 0.4/2.0 MB 2.9 MB/s eta 0:00:01
----------- ---------------------------- 0.6/2.0 MB 3.1 MB/s eta 0:00:01
-------------- ------------------------- 0.7/2.0 MB 3.2 MB/s eta 0:00:01
------------------ --------------------- 0.9/2.0 MB 3.3 MB/s eta 0:00:01
---------------------- ----------------- 1.1/2.0 MB 3.5 MB/s eta 0:00:01
-------------------------- ------------- 1.4/2.0 MB 3.6 MB/s eta 0:00:01
------------------------------- -------- 1.6/2.0 MB 3.7 MB/s eta 0:00:01
---------------------------------- ----- 1.8/2.0 MB 3.7 MB/s eta 0:00:01
-------------------------------------- - 1.9/2.0 MB 3.7 MB/s eta 0:00:01
---------------------------------------- 2.0/2.0 MB 3.7 MB/s eta 0:00:00
Downloading starlette-0.50.0-py3-none-any.whl (74 kB)
---------------------------------------- 0.0/74.0 kB ? eta -:--:--
---------------------------------------- 74.0/74.0 kB 4.0 MB/s eta 0:00:00
Using cached annotated_types-0.7.0-py3-none-any.whl (13 kB)
Using cached typing_inspection-0.4.2-py3-none-any.whl (14 kB)
Installing collected packages: typing-inspection, pydantic-core, click, annotated-types, annotated-doc, uvicorn, starlette, pydantic, fastapi
Successfully installed annotated-doc-0.0.4 annotated-types-0.7.0 click-8.3.1 fastapi-0.122.0 pydantic-2.12.5 pydantic-core-2.41.5 starlette-0.50.0 typing-inspection-0.4.2 uvicorn-0.38.0
[notice] A new release of pip is available: 24.0 -> 25.3
[notice] To update, run: python.exe -m pip install --upgrade pip
3. 모델 훈련 코드(train_model.py)
import pandas as pd
import numpy as np
from sklearn.ensemble import HistGradientBoostingRegressor
from statsmodels.tsa.holtwinters import ExponentialSmoothing
import pickle
# ---------------------------------------
# 1) 간단한 가상 데이터 생성
# ---------------------------------------
def generate_data():
dates = pd.date_range("2022-01-01", periods=500)
df = pd.DataFrame({"date": dates})
# 계절성 + 추세 + 랜덤성
df["sales"] = (
50
+ 0.05 * np.arange(len(df)) # 가벼운 추세
+ 10 * np.sin(2 * np.pi * df.index / 30) # 30일 주기
+ np.random.normal(0, 3, size=len(df))
)
# 외부 변수 예시
df["dow"] = df["date"].dt.dayofweek # 요일
df["is_weekend"] = (df["dow"] >= 5).astype(int)
df["promo"] = (np.random.rand(len(df)) > 0.9).astype(int) # 10% 확률 프로모션
return df
# ---------------------------------------
# 2) 데이터 준비
# ---------------------------------------
df = generate_data()
df = df.set_index("date")
# Train/Test split
train = df.iloc[:-30]
test = df.iloc[-30:]
y_train = train["sales"]
y_test = test["sales"]
# ---------------------------------------
# 3) Exponential Smoothing (baseline)
# ---------------------------------------
ts_model = ExponentialSmoothing(
y_train,
trend="add",
seasonal="add",
seasonal_periods=30
).fit()
# baseline 예측
train["baseline"] = ts_model.fittedvalues
test["baseline"] = ts_model.forecast(30)
# residual = 실제 - 베이스라인
train["residual"] = train["sales"] - train["baseline"]
# ---------------------------------------
# 4) ML 모델(HGBR)로 residual 예측
# ---------------------------------------
X_train = train[["dow", "is_weekend", "promo"]]
y_residual = train["residual"]
ml_model = HistGradientBoostingRegressor(
learning_rate=0.1,
max_leaf_nodes=31,
early_stopping=True
)
ml_model.fit(X_train, y_residual)
# ---------------------------------------
# 5) 모델 저장
# ---------------------------------------
with open("ts_model.pkl", "wb") as f:
pickle.dump(ts_model, f)
with open("ml_model.pkl", "wb") as f:
pickle.dump(ml_model, f)
print("모델 저장 완료!")데이터 생성
%config Completer.use_jedi = False
#train_model
import pandas as pd
import numpy as np
from sklearn.ensemble import HistGradientBoostingRegressor
from statsmodels.tsa.holtwinters import ExponentialSmoothing
import pickle
#가상 시계열 데이터 생성
def generate_data():
dates = pd.date_range("2022-01-01", periods=500)
df = pd.DataFrame({"date": dates})
df["sales"] = (
50
+ 0.05 * np.arange(len(df))
+ 10 * np.sin(2 * np.pi * df.index / 30)
+ np.random.normal(0, 3, size=len(df))
)
df["dow"] = df["date"].dt.dayofweek
df["is_weekend"] = (df["dow"] >= 5).astype(int)
df["promo"] = (np.random.rand(len(df)) > 0.9).astype(int)
return df
df = generate_data()
df = df.set_index("date")
train = df.iloc[:50]
test = df.iloc[-10:]
y_train = train["sales"]
# Exponential Smoothing baseline
ts_model = ExponentialSmoothing(
y_train,
trend="add",
seasonal="add",
seasonal_periods=7,
initialization_method="estimated"
).fit()
train["baseline"] = ts_model.fittedvalues
# forecast index를 test index와 동일하게 맞추기
fc = ts_model.forecast(len(test))
fc.index = test.index
test["baseline"] = fc
train["residual"] = train["sales"] - train["baseline"]
오류 해결 (train 데이터 길이 늘리기 및 seasonal_periods 줄이기)
...
train = df.iloc[:50] # 예: 마지막 10일만 test
test = df.iloc[-10:]
y_train = train["sales"]
...
ts_model = ExponentialSmoothing(
y_train,
trend="add",
seasonal="add",
seasonal_periods=7,
initialization_method="estimated"
).fit()
모델 학습 및 저장
# HistGradientBoostingRegressor 학습
X_train = train[["dow", "is_weekend", "promo"]]
y_residual = train["residual"]
ml_model = HistGradientBoostingRegressor(
learning_rate=0.1,
max_leaf_nodes=31,
early_stopping=True
)
ml_model.fit(X_train, y_residual)
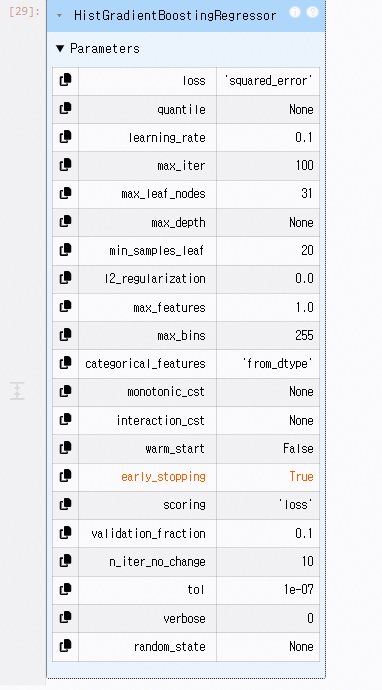
아래 5개 핵심 파라미터는 성능·복잡도·안정성을 직접적으로 조정하는 요소로, 이들만 다뤄도 모델 성능의 대부분을 관리할 수 있다.
-
learning_rate (학습 속도/안정성 조절)
- 학습 단계마다 얼마나 크게 업데이트할지 결정. 작으면 안정적이고, 크면 빠르지만 과적합 위험이 증가함.
-
max_iter (모델 용량/반복 횟수)
- 생성할 트리 개수를 의미. 많을수록 표현력이 높아지지만 과적합 가능성도 높아짐.
-
max_leaf_nodes (트리 복잡도 제어)
- 한 트리 내 리프(끝 노드) 최대 개수. 복잡도를 증가시키면 더 많은 패턴을 학습하지만 과적합 위험도 커짐.
-
min_samples_leaf (과적합 제어/일반화)
- 리프 노드에 필요한 최소 샘플 수. 값이 크면 모델이 단순해지고 일반화 성능이 개선됨.
-
early_stopping (학습 안정성/과적합 방지)
- 성능 향상이 일정 기간 나타나지 않으면 조기 종료해 불필요한 학습과 과적합을 동시에 방지함.
# 모델 저장
with open("ts_model.pkl", "wb") as f:
pickle.dump(ts_model, f)
with open("ml_model.pkl", "wb") as f:
pickle.dump(ml_model, f)
print("모델 저장 완료")
4. FastAPI 서버 코드(main.py)
from fastapi import FastAPI
import pandas as pd
import pickle
import numpy as np
from datetime import datetime
# 모델 로드
with open("ts_model.pkl", "rb") as f:
ts_model = pickle.load(f)
with open("ml_model.pkl", "rb") as f:
ml_model = pickle.load(f)
app = FastAPI()
@app.get("/")
def root():
return {"message": "Sales Forecast API running"}
# ----------------------------
# 예측 API
# ----------------------------
@app.get("/predict")
def predict_sales(date: str, promo: int = 0):
"""
date: YYYY-MM-DD
promo: 0 or 1
"""
# 입력 처리
dt = pd.to_datetime(date)
dow = dt.dayofweek
is_weekend = 1 if dow >= 5 else 0
# 1) Exponential Smoothing baseline
baseline_forecast = ts_model.forecast(1)[0]
# 2) ML residual 예측
X = pd.DataFrame(
{"dow": [dow], "is_weekend": [is_weekend], "promo": [promo]}
)
residual_pred = ml_model.predict(X)[0]
# 3) 최종 예측 = baseline + residual
final_pred = baseline_forecast + residual_pred
return {
"date": date,
"baseline": float(baseline_forecast),
"residual_pred": float(residual_pred),
"final_prediction": float(final_pred)
}5. 실행 방법
1) 모델 학습
python train_model.py2) FastAPI 실행
uvicorn main:app --reload
(env) PS C:\ANN\hybrid_forecasting> uvicorn main:app --reload
INFO: Will watch for changes in these directories: ['C:\\ANN\\hybrid_forecasting']
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [61112] using StatReload
INFO: Started server process [74984]
INFO: Waiting for application startup.
INFO: Application startup complete.
3) 예측 요청
브라우저 또는 curl:
http://127.0.0.1:8000/predict?date=2024-02-10&promo=1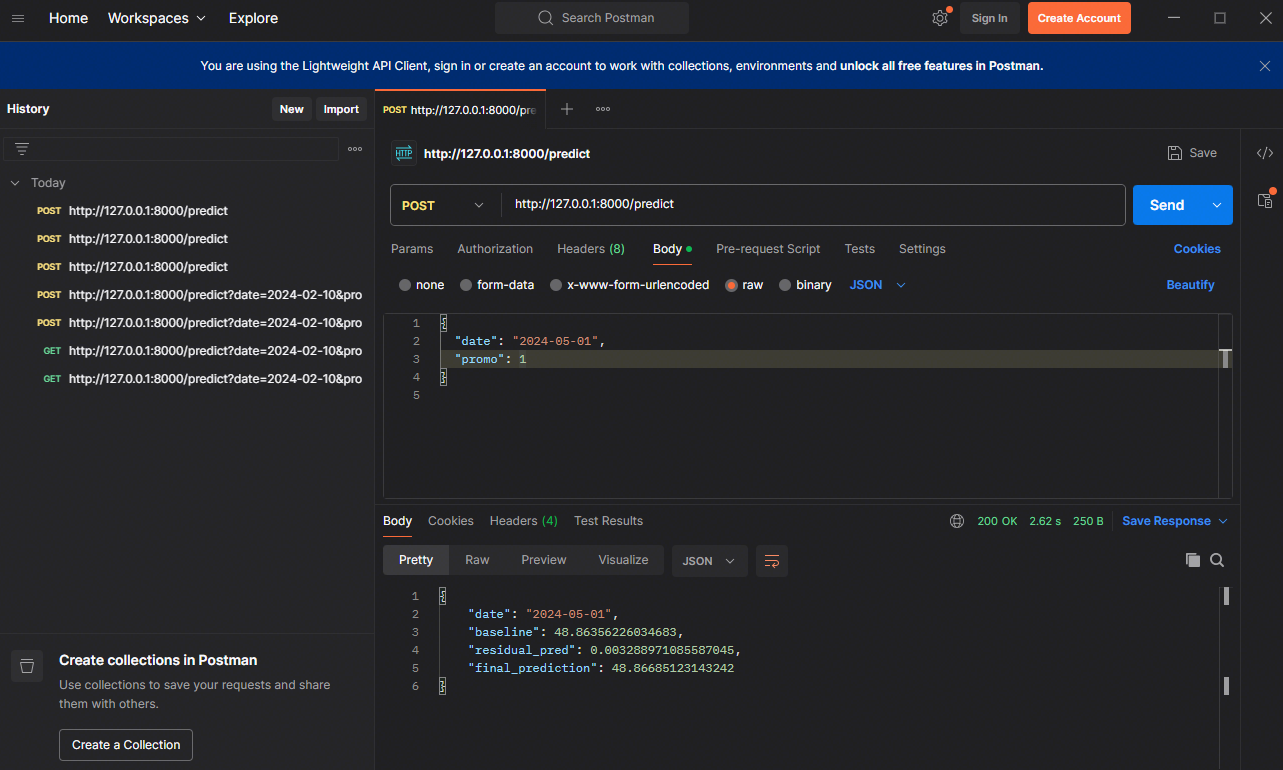
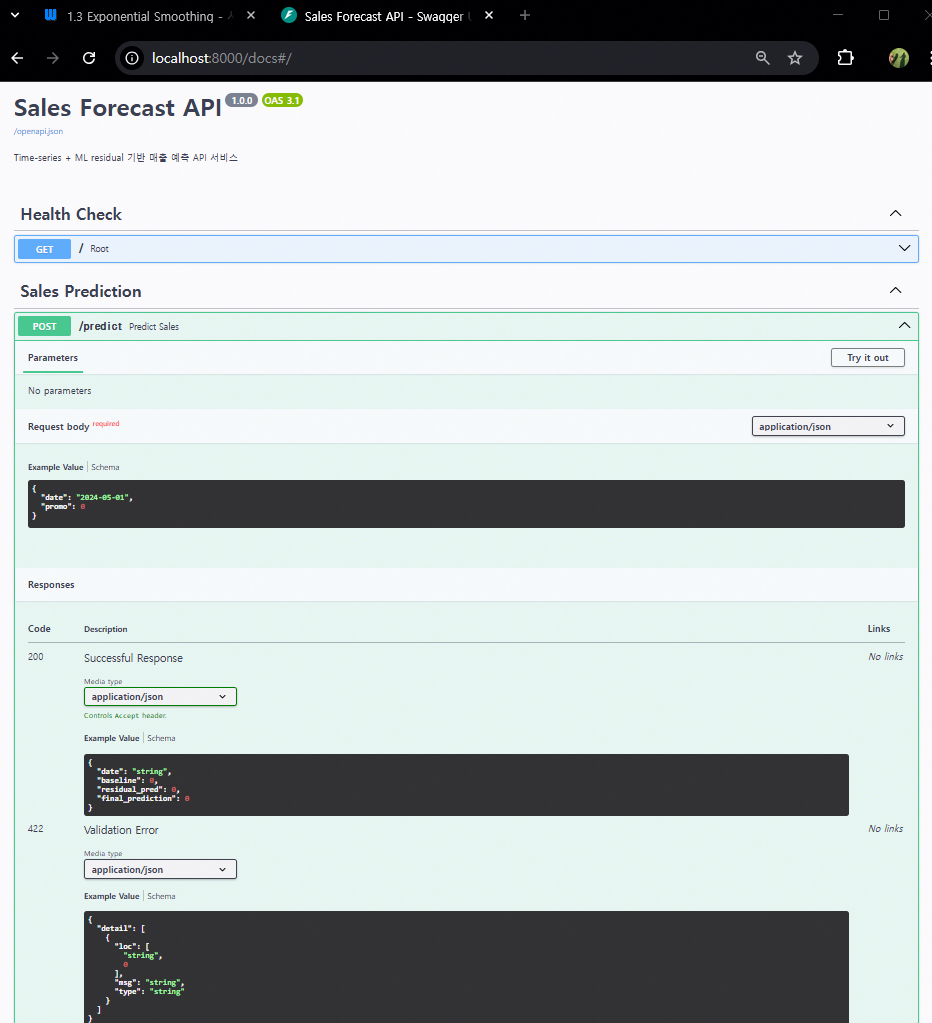
Swagger UI 개선 버전
from fastapi import FastAPI
from pydantic import BaseModel, Field
import pandas as pd
import pickle
class SalesRequest(BaseModel):
date: str = Field(..., example="2024-05-01")
promo: int = Field(0, example=1, description="프로모션 여부(0: 없음, 1: 있음)")
class SalesResponse(BaseModel):
date: str
baseline: float
residual_pred: float
final_prediction: float
# 모델 로드
with open("ts_model.pkl", "rb") as f:
ts_model = pickle.load(f)
with open("ml_model.pkl", "rb") as f:
ml_model = pickle.load(f)
app = FastAPI(
title="Sales Forecast API",
description="Time-series + ML residual 기반 매출 예측 API 서비스",
version="1.0.0"
)
@app.get("/", tags=["Health Check"])
def root():
return {"status": "running"}
@app.post("/predict", response_model=SalesResponse, tags=["Sales Prediction"])
def predict_sales(request: SalesRequest):
dt = pd.to_datetime(request.date)
dow = dt.dayofweek
is_weekend = 1 if dow >= 5 else 0
baseline_forecast = ts_model.forecast(1)[0]
X = pd.DataFrame({
"dow": [dow],
"is_weekend": [is_weekend],
"promo": [request.promo]
})
residual_pred = ml_model.predict(X)[0]
final_pred = baseline_forecast + residual_pred
return SalesResponse(
date=request.date,
baseline=float(baseline_forecast),
residual_pred=float(residual_pred),
final_prediction=float(final_pred)
)
6. 구조 설명
-
ExponentialSmoothing
→ 전체적인 매출 패턴(추세·계절성)을 잘 잡음
-
HistGradientBoostingRegressor
→ 요일·프로모션 같은 외생적 요인을 모델링
-
두 모델 합치기
→ 안정성과 예측력 모두 향상되는 Hybrid Forecasting Model
이 구조는 실제로 리테일/재고/수요예측에서 많이 쓰는 조합입니다.
