AI의 복잡한 수식 뒤에는 언제나 “하나의 직선으로 세상을 설명하려는 시도”가 숨어 있다는 사실을 기억해보자.
Linear Regression
Linear Regression 모델은 매우 간단하고, 직관적이여서, 머신러닝하면 가장 대표적으로 생각나는 모델이다. 딥러닝 관련 책들에 항상 1장으로 등장했을만큼, 기초적이고 매우 중요하다.
-
Linear Regression은 어떠한 독립 변수들과 종속 변수 간의 관계를 예측할때, 그 사이 관계를 선형 관계(1차 함수)로 가정하고, 모델링하는 지도 학습 알고리즘이다.
-
Linear Regression은 보통, 인자와 결과 간의 대략적인 관계 해석이나, 예측에 활용된다.
-
Linear Regression은 확률 변수를 수학적 함수의 결과인 변수(모델링 결과값)으로 연결해준다는데, 그 의미가 크다.
-
Linear Regression은 변수의 수에 따라, 다음과 같이 구분된다.
-
변수 1개와 종속 변수 간의 선형 관계 모델링은 단순 선형 회귀 분석이라고 한다.
-
독립 변수 여러 개와 종속 변수 간의 선형 관계 모델링은 다중 선형 회귀 분석이라고 한다.
-
단순 선형 회귀 분석은 Visualization이 쉽고(2차원 공간에서 선형 함수로 표현 가능), 변수가 하나여서 이해가 쉽지만, 실생활에서의 문제들은 보통 다중 선형 회귀 문제인 경우가 많다.
Linear Regression 선형 관계식
일반적인 다중 선형 회귀(Multiple Linear Regression)
-
: 종속 변수
-
: 독립 변수
-
: 회귀 계수
-
: 절편
-
: 오차항(모델로 설명할 수 없는 부분)
단순 선형 회귀(Simple Linear Regression)
- 독립 변수 하나만 존재할 때
-
직선 형태(1차식)
-
: X가 1 증가할 때 y가 어떻게 변하는지 의미함
Linear Regression의 Residual(잔차)
-
앞서 말한대로, Linear Regression에서 종속 변수는 관찰의 결과인 확률변수이기 때문에, 오차(error)를 포함한다.
-
오차를 알기 위해서는, 모델링을 위한 인자와 종속 변수 간의 모든 경우의 수를 학습해야하지만, 현실적으로 불가능하다.
-
따라서, Linear Regression에서는 오차를 사용하지 않고, 표본집단(학습데이터)으로 학습된 모델의 예측값과 실제 관측값 사이의 차이인 잔차(residual) 개념을 사용한다.
-
-
Linear Regression은 i.i.d 라는 가정을 따른다.
iid는 "independent and identically distributed"의 약자로, 각 값이 서로 독립적이며, 동일한 확률 분포에서 나왔다는 의미입니다.
두 가지 조건이 모두 만족되어야 합니다.- independent: 각각의 값이 서로 영향을 주지 않는 상태
- identically distributed: 각각의 값이 같은 분포에서 나온 상태
-
정규성 가정 : 잔차는 정규 분포를 따른다고 가정한다. 잔차가 정규 분포를 따르지 않고, 특정한 분포를 따른다면, 회귀 모델의 예측값을 신뢰하기 어렵다.
- 확인 방법 : 잔차 분포도 Visualization 확인, 잔차 정규성 검정
-
등분산성 가정 : 잔차의 분산은 일정하다.
- 확인 방법 : 잔차-예측값 산포도 확인,
-
독립성 가정 : 모든 잔차들은 서로 독립적이다. 만약, 잔차 간의 상관 관계가 있다면, 추정된 회귀식에서 설명하지 못하는 다른 어떠한 관계가 존재할 수 있다.
- 확인 방법 : 잔차의 자기상관 함수 확인
잔차(residual) 정의
Linear Regression의 학습
-
Linear Regression의 학습 목적은 종속 변수와 설명 변수 간의 관계를 가장 잘 나타낼 수 있는 선형식을 모델링하는 것이다.
-
Linear Regression의 모델 추정을 위해서, 보통 예측값과 실제관측값인 잔차의 제곱을 최소화하는 최소제곱법(OLS)을 사용한다.
-
최소제곱법을 활용하는 이유는 다음과 같다.
-
잔차의 제곱은 항상 양수이기 때문에
-
잔차의 제곱은 큰 오차를 더욱 강조가 가능하기 때문에
-
잔차의 제곱은 미분이 가능하기 때문
-
최소제곱법(OLS) 손실 함수
-
데이터의 실제 값 와 예측값 의 차이(잔차)를 제곱하여 모두 더한 값을 최소화한다.
- OLS의 목표는 이것을 최소화하는 β를 찾는 것이다.
단순 선형 회귀 분석(Simple Linear Regression)
- 단순 선형 회귀에서 최소제곱법을 이용하면 회귀계수는 다음과 같이 추정된다.
- 기울기(slope) 추정식
- 절편(intercept) 추정식
다중 선형 회귀 분석(Multiple Linear Regression)
-
다중 선형 회귀에서 최소제곱법을 이용하면 회귀계수 벡터(행렬)는 아래와 같이 추정된다.
-
행렬 형태의 OLS 해(Normal Equation)
-
: 독립변수 행렬 (관측치 변수 )
-
: 종속변수 벡터
-
: 추정된 회귀계수 벡터
Linear Regression의 평가
- 회귀모형이 데이터를 얼마나 잘 설명하는지 평가하기 위해 결정계수(R²) 를 사용한다.
평가에 필요한 세 가지 제곱합
1) 전체 변동(SST)
2) 모델이 설명한 변동(SSR)
3) 모델이 설명하지 못한 변동(RSS)
세 값의 관계:
결정계수(R²)
공식 1: 모델이 설명한 비율
공식 2: 전체 변동에서 오차 비율을 뺀 것
R² 해석
-
1에 가까울수록 설명력이 좋다.
-
0이면 평균 예측과 동일한 수준.
-
음수가 될 수 있음(평균보다 못한 모델).
-
절대적인 지표는 아니므로, Adjusted R², 잔차 분석, p-value, F-test 등을 함께 고려해야 한다.
Linear Regression의 Python 구현
- Linear Regression은 scikit-learn의 linear_model의 LinearRegression을 통해 쉽게 사용 가능하다.
%config Completer.use_jedi = False
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
if __name__ == '__main__':
# 테스트용 데이터 생성
x = np.random.rand(1000)*100
y = 0.8*x+np.random.randn(1000)*30
# Linear Regrssion model 생성
model = LinearRegression()
# Linear Regression model 학습
model.fit(x.reshape(-1,1), y)
# Prediction
y_new = model.predict(np.array([6]).reshape((-1, 1)))
print("Data Prediction: ", y_new)
# Linear Regression model 평가
r_sq = model.score(x.reshape(-1,1), y)
print("결정 계수: ", r_sq)
# Linear Model 식
b0,b1 = model.intercept_, model.coef_[0] #기울기(slope), 절편(intercept)
print("b0",b0)
print("b1",b1)
# 시각화
plt.scatter(x, y, s=5)
plt.plot(x, model.predict(x.reshape(-1,1)), color='red', linewidth=2) #-1: 자동 계산
plt.annotate(
'y = {:.2f}x + {:.2f}'.format(b1, b0),
xy=(100, 100),
xytext=(80, 80),
color='red',
fontsize=9,
fontweight='bold')
plt.show()
결과 해석
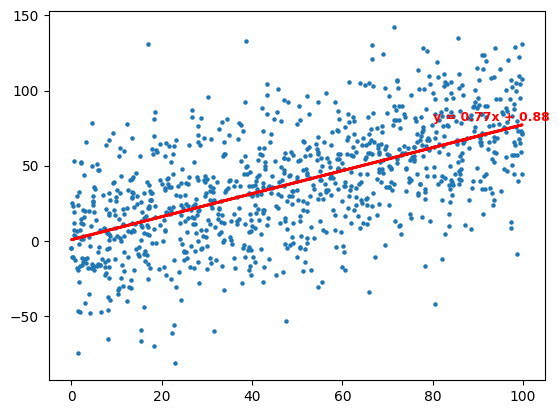
Data Prediction: [5.47553962]
결정 계수: 0.34857663141221407
b0 0.8829451084042717
b1 0.7654324188451549
-
Data Prediction: [5.47553962]
-
x=6일 때 y 예측값이 약 5.48
-
즉, 모델이 보는 관점에서는 x가 6일 때 결과가 약 5.5 근처라는 뜻
-
하지만 이 값이 “신뢰할 만한지”는 아래 R²와 기울기 등과 함께 해석해야 함
-
실무 판단
• 예측값 자체는 큰 의미 없음
• “해석 가능하고 믿을 만한 예측인가?”가 중요 → R²로 판단
-
결정 계수 R²: 0.34857663141221407
-
약 0.35
-
0~1 사이 값이며 1에 가까울수록 모델이 데이터를 잘 설명함
-
해석
• 0.35는 설명력이 낮은 모델
• 즉, x만으로 y를 설명하는 능력이 약함
• 데이터의 변동성(노이즈)이 많거나, y에 영향을 주는 다른 변수가 더 많다는 의미
실무 판단 기준
• 0.7 이상: 꽤 설명력이 좋다
• 0.5~0.7: 중간 정도, 참고용
• 0.3~0.5: 설명력 낮음, 단순 경향만 파악
• 0.3 이하: 모델 신뢰 어려움
→ 너 모델은 “단순한 방향성 파악은 가능하지만, 정확한 예측용은 아님”
-
b0 = 0.8829451084042717 (절편)
-
x=0일 때 y ≈ 0.88
-
데이터가 시작하는 기준점(Baseline)
-
실무에서 절편
• x 값이 실제로 0이 가능한 변수인가? 확인해야 의미가 있음
예: 광고비=0이면 매출=? → 의미 있음
예: 시험 점수=0은 거의 의미 없음 → 단순 수학적 절편일 뿐
여기선 큰 의미 없는 경우가 많지만 회귀식 구성 요소로는 필요함.
-
b1 = 0.7654324188451549 (기울기)
-
x가 1 증가할 때 y는 약 0.765 증가
-
즉, x와 y는 양의 상관 관계
-
하지만 절대적으로 영향력은 “매우 크다”고 보긴 어려움
-
실무 해석 요령
• b1이 양수 → x 증가하면 y 증가
• b1의 크기 → x의 영향력(민감도)
• R²가 낮기 때문에 “경향성은 있지만 변동성이 크다”고 보는 게 옳음
종합 해석 (실무 기준 한 줄 요약)
• x가 증가하면 y는 대체로 증가한다(b1>0).
• 하지만 데이터의 노이즈가 커서(R²=0.35) 예측력은 낮다.
• 따라서 이 모델은 정확한 예측용보다는 ‘대략적인 경향’ 확인용으로 적합하다.
