마치 10명의 친구에게 "가장 친한 친구는 누구야?"라고 물어봤을 때, 5명이 서로 "A랑 B가 제일 친하고, B랑 C가 제일 친해"라고 말하는 상황과 비슷해요. 서로 너무 밀접하게 엮여 있어서 "A가 가장 친한 친구"라고 단정하기 어려운 것처럼, 독립변수들도 서로 겹치는 정보가 많아 혼란을 주는 것이죠.
다중공선성(multicollinearity)
-
다중공선성(multicollinearity)란 독립 변수의 일부가 다른 독립 변수의 조합으로 표현될 수 있는 경우이다.
-
독립 변수들이 서로 독립이 아니라 상호상관관계가 강한 경우에 발생한다. 이는 독립 변수의 공분산 행렬이 full rank 이어야 한다는 조건을 침해한다.
-
다음 데이터는 미국의 거시경제지표를 나타낸 것이다.
-
TOTEMP - Total Employment
-
GNPDEFL - GNP deflator
-
GNP - GNP
-
UNEMP - Number of unemployed
-
ARMED - Size of armed forces
-
POP - Population
-
YEAR - Year (1947 - 1962)
-
| Variable | Meaning | Type |
|---|---|---|
TOTEMP | Total employment (what you want to predict) | endog (target) |
GNP, UNEMP, etc. | Predictor variables | exog (features) |
변수 간 상관관계
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from statsmodels.datasets.longley import load_pandas
# Load dataset
data = load_pandas()
dfy = data.endog
dfX = data.exog
# Combine into single DataFrame if needed
df = pd.concat([dfy, dfX], axis=1)
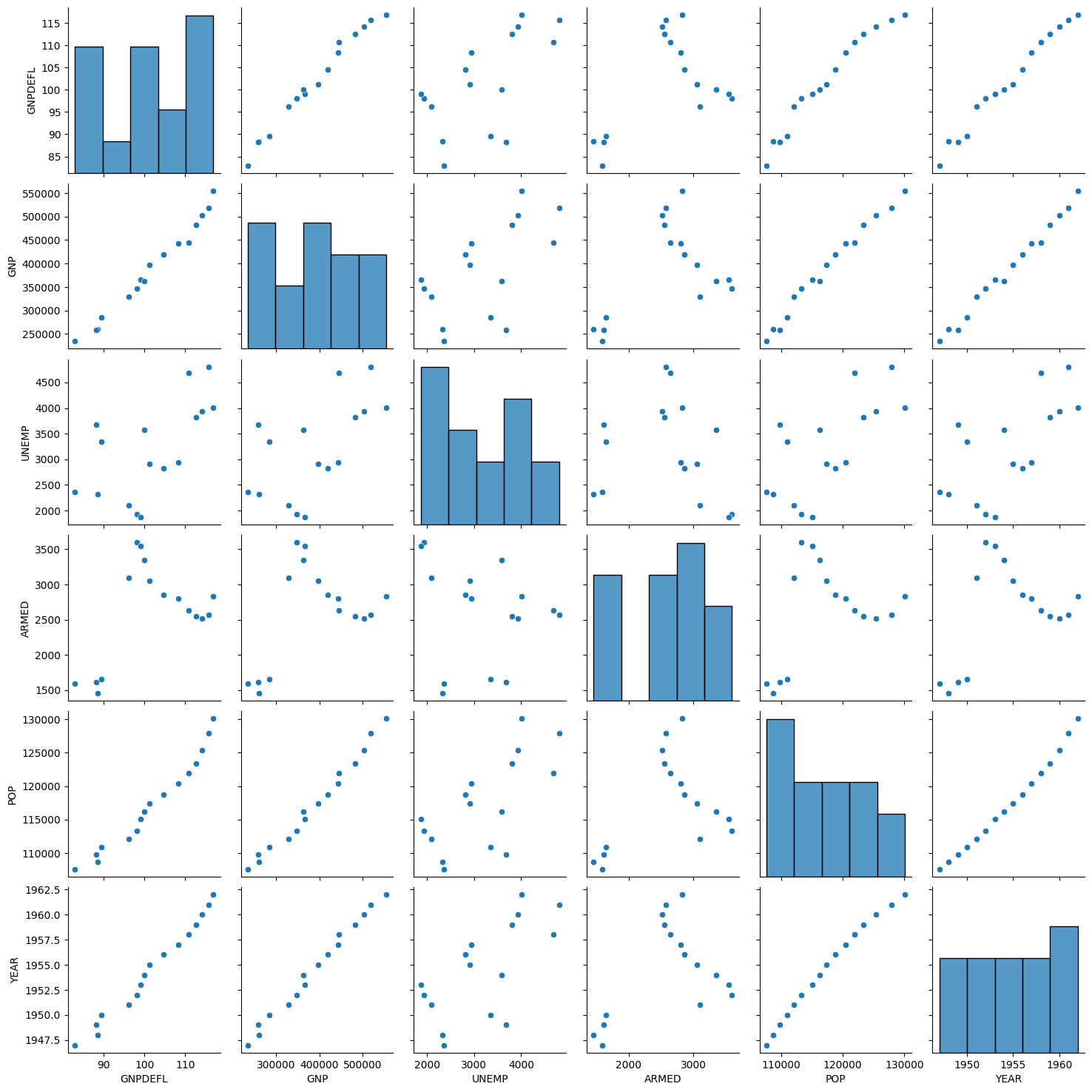
# Pairplot of the independent variables
sns.pairplot(dfX) #relationships between variables
plt.show()
- 스캐터 플롯에서 보듯이 독립변수간의 상관관계가 강하다.
import pandas as pd
df.corr(method='pearson')
# help(pd.DataFrame.corr)
# method : {'pearson', 'kendall', 'spearman'} default 'pearson'
cmap = sns.light_palette("darkgray", as_cmap=True)
sns.heatmap(dfX.corr(), annot=True, cmap=cmap)
plt.show()
Selection deleted
import pandas as pd
print(dfX.corr(method='pearson'))
print(df.corr())
# help(pd.DataFrame.corr)
# method : {'pearson', 'kendall', 'spearman'} default 'pearson'
cmap = sns.light_palette("darkgray", as_cmap=True)
sns.heatmap(dfX.corr(), annot=True, cmap=cmap)
plt.show()
GNPDEFL GNP UNEMP ARMED POP YEAR
GNPDEFL 1.000000 0.991589 0.620633 0.464744 0.979163 0.991149
GNP 0.991589 1.000000 0.604261 0.446437 0.991090 0.995273
UNEMP 0.620633 0.604261 1.000000 -0.177421 0.686552 0.668257
ARMED 0.464744 0.446437 -0.177421 1.000000 0.364416 0.417245
POP 0.979163 0.991090 0.686552 0.364416 1.000000 0.993953
YEAR 0.991149 0.995273 0.668257 0.417245 0.993953 1.000000
TOTEMP GNPDEFL GNP UNEMP ARMED POP YEAR
TOTEMP 1.000000 0.970899 0.983552 0.502498 0.457307 0.960391 0.971329
GNPDEFL 0.970899 1.000000 0.991589 0.620633 0.464744 0.979163 0.991149
GNP 0.983552 0.991589 1.000000 0.604261 0.446437 0.991090 0.995273
UNEMP 0.502498 0.620633 0.604261 1.000000 -0.177421 0.686552 0.668257
ARMED 0.457307 0.464744 0.446437 -0.177421 1.000000 0.364416 0.417245
POP 0.960391 0.979163 0.991090 0.686552 0.364416 1.000000 0.993953
YEAR 0.971329 0.991149 0.995273 0.668257 0.417245 0.993953 1.000000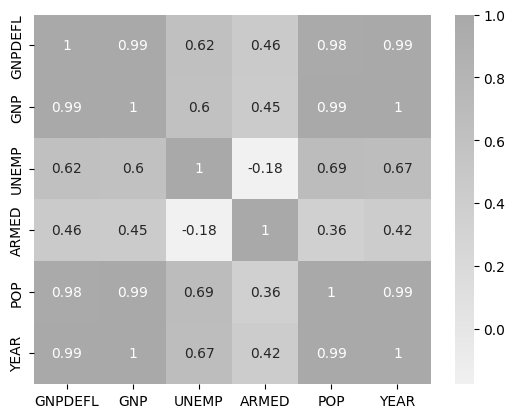
dfX와 df의 구성 차이
dfX = 관계(독립변수 vs 독립변수)
df = 관계(독립변수 vs 종속변수까지 포함)
| 목적 | dfX.corr() | df.corr() |
|---|---|---|
| 독립변수 간 공선성 확인 | ● 매우 중요 | ○ 가능하지만 필요 없음 |
| 종속변수와의 관계 파악 | X | ● 매우 중요 |
| 히트맵 깔끔함 | ● | ○ (변수가 하나 더 생김) |
| 회귀문제의 진단 | ● | ● |
따라서 보통 다음 순서로 분석합니다:
dfX.corr()→ 독립변수끼리 공선성 있는지 확인df.corr()→ 종속변수와 어떤 변수가 가장 관련 있는지 확인
둘 다 서로 다른 목적을 갖기 때문에 정답은 둘 다 본다입니다.
-
dfX.corr()→ 독립변수끼리만 상관 분석 → 공선성(multicollinearity) 체크 -
df.corr()→ 독립변수 + 종속변수 전체 상관 분석 → 어떤 변수가 종속변수를 설명하는지 확인
dfX(독립변수만)과df(독립변수 + 종속변수(TOTEMP))로 상관관계를 계산할 때 결과가 어떻게 달라지는지, 왜 차이가 있는지
dfX
-
dfX에는 독립변수들만 들어 있음- 즉, 특징(features)만 있는 입력 데이터셋입니다.
- 공선성 문제 진단에 매우 적합
- 회귀모형의 안정성(계수의 변동성) 확인용
dfX = data.exog- GNPDEFL
- GNP
- UNEMP
- ARMED
- POP
- YEAR
df
df에는 독립변수 + 종속변수(TOTEMP) 가 함께 포함됩니다:
TOTEMP이 포함되므로 종속변수와 각 독립변수의 상관관계까지 보임.
df = pd.concat([dfy, dfX], axis=1)- TOTEMP ← 종속변수
- GNPDEFL
- GNP
- UNEMP
- ARMED
- POP
- YEAR
조건수(Condition Number)
조건수는 독립변수들의 공선성과 관련된 안정성 지표이며, 조건수가 크면 모델이 입력의 작은 변화에도 크게 흔들리고 일반화 성능이 나빠진다.
- 조건수 κ(κappa)는 행렬의 안정성(stability) 또는 민감도(sensitivity)를 나타내는 지표로,
-
: 공분산 행렬의 가장 큰 고유값
-
: 가장 작은 고유값
조건수가 크면:
-
입력(X)이 아주 조금 변해도
-
추정계수(β)와 예측값이 크게 요동한다 → 불안정한 모델
조건수가 작으면:
-
입력이 조금 변해도
-
모델 결과가 안정적 → 일반화 성능(Test 성능) 좋아짐
조건수가 왜 커지는가?
1) 다중공선성(Multicollinearity)
독립변수들이 서로 비슷한 정보를 담고 있을 때
→ 공분산 행렬 고유값 중 하나가 매우 작아진다(≈0)
→ λmin ↓
→ 조건수 κ = λmax / λmin ↑
즉, 조건수를 키우는 핵심 원인은 “독립변수 간 선형 의존성(중복 정보)”이다.
2) 변수 스케일 차이(부차적인 원인)
변수 값의 단위, 크기가 크게 다르면
→ 고유값 분포가 벌어짐
→ 조건수 증가 가능
하지만 공선성이 주원인이고, 스케일은 보조적 원인이다.
조건수가 크면 어떤 문제가 생기나?
-
회귀계수가 불안정
-
아주 작은 데이터 변동에도 예측이 확 바뀜
-
테스트 성능(Test accuracy) 저하
-
Overfitting 위험 증가
-
변수 해석(p-value, 계수 부호)이 왜곡됨
-
X'X가 수치적으로 거의 역행렬 불가 상태(ill-conditioned)
즉,
조건수가 크다 = 공선성 크다 = 모델이 불안정하다
조건수를 줄이는 방법
1) 공선성 제거
-
VIF 기반 변수 제거
-
상관계수 높은 변수 제거
2) PCA로 변수 축소
독립적인 방향(주성분)만 남기므로 고유값 분포가 안정됨.
3) 규제(Regularization)
-
Ridge(L2), ElasticNet
→ 작은 고유값을 인위적으로 키워 조건수 안정화
4) 변수 스케일링(StandardScaler)
스케일 차이로 인한 조건수 증가 문제를 완화
OLS 계수가 데이터 분할(seed)에 얼마나 민감한지 평가
from sklearn.model_selection import train_test_split
import statsmodels.api as sm
def get_model1(seed):
df_train, df_test = train_test_split(df, test_size=0.5, random_state=seed)
model = sm.OLS.from_formula("TOTEMP ~ GNPDEFL + POP + GNP + YEAR + ARMED + UNEMP", data=df_train)
return df_train, df_test, model.fit()
df_train, df_test, result1 = get_model1(3)
print(result1.summary())
OLS Regression Results
==============================================================================
Dep. Variable: TOTEMP R-squared: 1.000
Model: OLS Adj. R-squared: 0.997
Method: Least Squares F-statistic: 437.5
Date: Thu, 11 Dec 2025 Prob (F-statistic): 0.0366
Time: 11:45:49 Log-Likelihood: -44.199
No. Observations: 8 AIC: 102.4
Df Residuals: 1 BIC: 103.0
Df Model: 6
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept -1.235e+07 2.97e+06 -4.165 0.150 -5e+07 2.53e+07
GNPDEFL 106.2620 75.709 1.404 0.394 -855.708 1068.232
POP 2.2959 0.725 3.167 0.195 -6.915 11.506
GNP -0.3997 0.120 -3.339 0.185 -1.920 1.121
YEAR 6300.6231 1498.900 4.203 0.149 -1.27e+04 2.53e+04
ARMED -0.2450 0.402 -0.609 0.652 -5.354 4.864
UNEMP -6.3311 1.324 -4.782 0.131 -23.153 10.491
==============================================================================
Omnibus: 0.258 Durbin-Watson: 1.713
Prob(Omnibus): 0.879 Jarque-Bera (JB): 0.304
Skew: 0.300 Prob(JB): 0.859
Kurtosis: 2.258 Cond. No. 2.01e+10
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 2.01e+10. This might indicate that there are
strong multicollinearity or other numerical problems.| 항목 | 값 | 해석 |
|---|---|---|
| R-squared | 1.000 | Train 데이터(8개)에 완벽하게 맞춘 상태. 그러나 공선성 + 적은 표본 때문에 과적합(overfitting) 가능성이 매우 큼. |
| Adj. R-squared | 0.997 | Adjusted R²도 매우 높지만, 잔차 df = 1이라 사실상 의미가 약함. |
| F-statistic | 437.5 | 매우 큰 값이지만 df_resid=1이므로 신뢰성 낮음. |
| Prob(F-statistic) | 0.0366 | 모델 전체는 유의해 보이나, 표본이 너무 적어 이 값도 신뢰 어려움. |
| No. Observations | 8 | 표본 수가 지나치게 적음. 과적합과 불안정성이 필연적으로 발생. |
| Df Residuals | 1 | 잔차 자유도가 1개뿐 → 통계량의 안정성 거의 없음. |
| Df Model | 6 | 독립변수 6개 + intercept. 즉, 8개 데이터로 7개 모수를 추정하는 셈. |
학습용 데이터와 검증용 데이터로 나누어 회귀분석 성능을 비교
def calc_r2(df_test, result):
target = df.loc[df_test.index].TOTEMP
predict_test = result.predict(df_test)
RSS = ((predict_test - target)**2).sum()
TSS = ((target - target.mean())**2).sum()
return 1 - RSS / TSS
test1 = []
for i in range(10):
df_train, df_test, result = get_model1(i)
test1.append(calc_r2(df_test, result))
test1
[np.float64(0.9815050656812714),
np.float64(0.9738497543138936),
np.float64(0.9879366369912537),
np.float64(0.7588861967909392),
np.float64(0.9807206089304091),
np.float64(0.8937889315213675),
np.float64(0.8798563810622826),
np.float64(0.9314665778977191),
np.float64(0.8608525682245529),
np.float64(0.9677198735129439)]
1) 지금 계산한 test R² 리스트가 의미하는 것은?
-
이 값들은 각 seed에서 학습된 모델을 테스트 데이터에 적용했을 때의 R²입니다.
-
seed = 0 → R²_test ≈ 0.981
-
seed = 1 → R²_test ≈ 0.973
-
seed = 3 → R²_test = 0.758 (급격히 하락)
-
여기서 seed를 바꾼다는 것은 train/test 분할 방식만 다르다는 뜻입니다. 모델 구조는 동일합니다.
2) 어떤 기준으로 “과최적화(overfitting)”를 판단하는가?
-
OLS 모델이 정상적이고 안정적이면 train 성능과 test 성능이 비슷해야 하고, test 성능은 seed가 바뀌어도 크게 요동하지 않는다.
-
하지만 지금은 다음 두 문제가 동시에 발생
(기준 1) seed만 바꿨는데 R²_test 변동 폭이 너무 크다
- R²_test 최소–최대
최소: 0.758
최대: 0.987
차이: 0.229 (약 23%p 차이)-
정상적인 모델
-
보통 ±0.02(2%p) 내에서 움직이는 것이 정상
-
±0.05(5%p)만 돼도 “안정성 의심”
-
하지만 지금은 ±0.20 이상 변동
→ 매우 불안정 → Overfitting 판단 근거 1
-
(기준 2) train 성능(R²_train)이 비정상적으로 높다 (≈ 1.0)
-
Longley 데이터에서 OLS는 거의 항상 train R² ≈ 1.0이 나옵니다.
-
train에서는 완벽하게 맞추지만
-
test에서는 seed에 따라 성능이 크게 떨어짐
- 이 패턴은 전형적인 과적합 패턴입니다. → Overfitting 판단 근거 2
-
(기준 3) 다중공선성(multicollinearity)이 심하면 OLS 계수가 불안정 → test R²가 seed마다 흔들림
-
다중공선성이 있는 경우
-
XᵀX가 거의 singular 상태 → β(회귀계수)가 불안정
-
train/test split을 조금만 바꿔도 β가 크게 달라짐
-
β가 달라지면 test R²도 크게 달라짐
-
test1 = [...]-
값들이 seed마다 크게 달라지는 이유입니다.
-
seed에 따라 R²_test가 불안정
-
이는 공선성에 의한 과적합의 직접적인 증거
→ Overfitting 판단 근거 3
-
3) 문장 의미 해석
또한 다음처럼 학습용 데이터와 검증용 데이터로 나누어 회귀분석 성능을 비교하면 과최적화가 발생하였음을 알 수 있다.
-
train/test split을 변경(seed 변경)하면 test R² 값이 안정적이어야 하는데 실제로는 극도로 요동치므로
- 이 회귀모델은 과적합 상태이고 공선성 때문에 모델이 데이터에 과민반응한다
- 즉, test R²의 일관성(Consistency)이 Overfitting을 판단하는 핵심 기준입니다.
4) 결론: 어떤 기준으로 Overfitting이라고 판단하는가?
- 아래 3가지 기준을 충족하면 Overfitting이라고 판단합니다.
① test 성능이 seed에 따라 크게 변한다 (변동 폭이 큼)
-
정상: ±0.02 이내
-
이상: ±0.20 수준 → 지금이 바로 그런 상태
② train 성능이 지나치게 높다(R²=1.0)
- 완벽한 train 성능은 의심해야 함
③ 공선성으로 인해 계수 β가 seed마다 불안정
- β가 흔들리면 test R²도 흔들림 → OLS가 불안정
이 테스트에서 Overfitting이 이미 발생했고,
그 원인은 “독립변수 간의 높은 의존성(공선성)” 때문이다.
5) 과최적화(over-fitting) 문제 방지 방법
-
독립변수가 서로 의존하게 되면 이렇게 과최적화(over-fitting) 문제가 발생하여 회귀 결과의 안정성을 해칠 가능성이 높아진다.
-
이를 방지하는 방법들은 다음과 같다.
-
변수 선택법으로 의존적인 변수 삭제
-
PCA(principal component analysis) 방법으로 의존적인 성분 삭제
-
정규화(regularized) 방법 사용
-
VIF(Variance Inflation Factor)
-
다중 공선성을 없애는 가장 기본적인 방법은 다른 독립변수에 의존하는 변수를 없애는 것이다.
-
가장 의존적인 독립변수를 선택하는 방법으로는 VIF(Variance Inflation Factor)를 사용할 수 있다.
- VIF는 독립변수를 다른 독립변수로 선형회귀한 성능을 나타낸 것이다.
-
번째 변수의 VIF는 다음과 같이 계산한다.
-
는 다른 모든 독립변수로 ( X_j )를 선형회귀하여 얻은 결정계수입니다.
-
다른 변수들에 의해 잘 설명될수록 ( R_j^2 )가 커지고, 따라서 VIF도 커집니다.
-
-
VIF의 대안적 표현식: 확장된 형태로, 의 스케일과 표본 크기까지 고려한 해석을 제공할 때 사용됩니다.
-
: 오차항의 분산
-
: 표본 크기
-
: 독립변수 의 분산
-
: 다른 모든 독립변수로 를 회귀했을 때의 결정계수
-
해석 기준
-
VIF ≈ 1: 다중공선성 없음
-
1 ~ 5: 보통 허용 가능
-
5 ~ 10: 다중공선성 의심
-
VIF > 10: 심각한 다중공선성
StatsModels로 VIF 계산하기
from statsmodels.stats.outliers_influence import variance_inflation_factor
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(
dfX.values, i) for i in range(dfX.shape[1])]
vif["features"] = dfX.columns
vifVIF Factor features
0 12425.514335 GNPDEFL
1 10290.435437 GNP
2 136.224354 UNEMP
3 39.983386 ARMED
4 101193.161993 POP
5 84709.950443 YEAR
다중공선성 제거 전과 제거 후의 성능 비교
다중공선성 제거 후 모델 구성 및 성능
-
상관계수와 VIF를 사용하여 독립 변수를 선택하면, 원래의 전체 변수 대신 GNP, ARMED, UNEMP 세 가지 변수만으로도 종속 변수 TOTEMP를 상당히 잘 설명할 수 있다는 것을 확인할 수 있다.
-
다중공선성이 심각했던 YEAR, POP 등의 변수를 제거한 후, 아래와 같이 세 변수만을 포함하는 선형회귀모형을 적합한다.
-
종속 변수: TOTEMP
-
독립 변수: GNP, ARMED, UNEMP (표준화 적용:
scale())
-
모델 정의 및 학습/검증 분리
from sklearn.model_selection import train_test_split
import statsmodels.api as sm
def get_model2(seed):
# 학습/검증 데이터 분할
df_train, df_test = train_test_split(df, test_size=0.5, random_state=seed)
# 다중공선성을 줄인 모형: GNP, ARMED, UNEMP만 사용
model = sm.OLS.from_formula(
"TOTEMP ~ scale(GNP) + scale(ARMED) + scale(UNEMP)",
data=df_train
)
return df_train, df_test, model.fit()
# 예시: seed=3인 경우
df_train, df_test, result2 = get_model2(3)
print(result2.summary())
OLS Regression Results
==============================================================================
Dep. Variable: TOTEMP R-squared: 0.989
Model: OLS Adj. R-squared: 0.981
Method: Least Squares F-statistic: 118.6
Date: Thu, 11 Dec 2025 Prob (F-statistic): 0.000231
Time: 15:18:37 Log-Likelihood: -57.695
No. Observations: 8 AIC: 123.4
Df Residuals: 4 BIC: 123.7
Df Model: 3
Covariance Type: nonrobust
================================================================================
coef std err t P>|t| [0.025 0.975]
--------------------------------------------------------------------------------
Intercept 6.538e+04 163.988 398.686 0.000 6.49e+04 6.58e+04
scale(GNP) 4338.7051 406.683 10.669 0.000 3209.571 5467.839
scale(ARMED) -812.1407 315.538 -2.574 0.062 -1688.215 63.933
scale(UNEMP) -1373.0426 349.316 -3.931 0.017 -2342.898 -403.187
==============================================================================
Omnibus: 0.628 Durbin-Watson: 2.032
Prob(Omnibus): 0.731 Jarque-Bera (JB): 0.565
Skew: 0.390 Prob(JB): 0.754
Kurtosis: 1.958 Cond. No. 4.77
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.이때 출력 예시는 다음과 같다(요약):
- R-squared: 0.989
- Adj. R-squared: 0.981
- Cond. No.: 4.77 (조건수도 매우 낮아져 수치적으로 안정적)
즉, 변수 수를 줄였음에도 불구하고 설명력(R²)은 매우 높게 유지되면서, 공선성 지표(조건수)는 크게 개선된 것을 알 수 있다.
다중공선성 제거 전·후의 검증 성능 비교
이제 시드값을 바꿔가며 학습/검증 데이터를 여러 번 나누어 보고,
각 경우의 검증 데이터 R² 값을 비교한다.
test2 = []
for i in range(10):
df_train, df_test, result = get_model2(i)
test2.append(calc_r2(df_test, result))
test2
[np.float64(0.9763608388904902),
np.float64(0.9841984331185697),
np.float64(0.9687069366140136),
np.float64(0.9397304053201785),
np.float64(0.9773357061188465),
np.float64(0.9561262155732307),
np.float64(0.9803852496698635),
np.float64(0.9917361722470805),
np.float64(0.9837134067639468),
np.float64(0.9789512977093214)]이 값들은 다중공선성 제거 전 실험에서 얻었던 test1과 비교하여 시각화할 수 있다.
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
# 한글 폰트 설정
plt.rcParams['font.family'] = 'Malgun Gothic'
plt.rcParams['axes.unicode_minus'] = False
plt.subplot(121)
plt.plot(test1, 'ro', label="검증 성능")
plt.hlines(result1.rsquared, 0, 9, label="학습 성능")
plt.legend()
plt.xlabel("시드값")
plt.ylabel("성능(결정계수)")
plt.title("다중공선성 제거 전")
plt.ylim(0.5, 1.2)
plt.subplot(122)
plt.plot(test2, 'ro', label="검증 성능")
plt.hlines(result2.rsquared, 0, 9, label="학습 성능")
plt.legend()
plt.xlabel("시드값")
plt.ylabel("성능(결정계수)")
plt.title("다중공선성 제거 후")
plt.ylim(0.5, 1.2)
plt.suptitle("다중공선성 제거 전과 제거 후의 성능 비교", y=1.04)
plt.tight_layout()
plt.show()
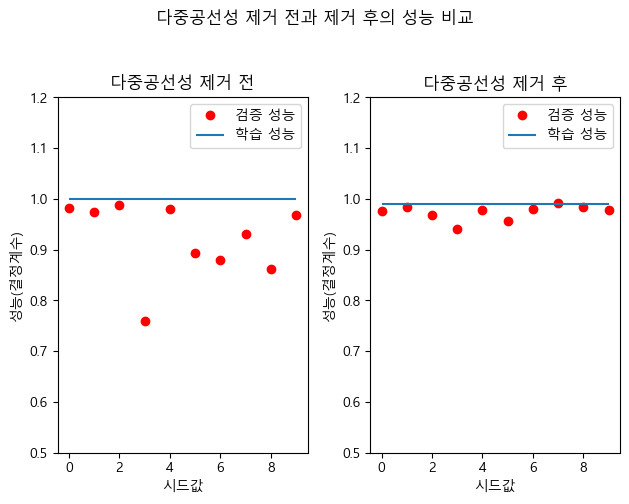
상관계수와 VIF를 이용하여 다중공선성이 심각한 변수들을 제거하고, GNP, ARMED, UNEMP 세 가지 변수만으로 모형을 재구성하였다. 이때 학습 데이터에서의 결정계수는 기존 모형과 비슷한 수준(약 0.98 이상)을 유지하면서도, 서로 다른 시드값으로 학습/검증 데이터를 반복 분할했을 때 검증 성능의 변동 폭이 감소하였다.
즉, 다중공선성을 제거한 이후에는 학습 성능과 검증 성능 간의 차이가 줄어들어 과최적화(overfitting)가 완화되었음을 확인할 수 있다. 이는 공선성이 심한 변수를 그대로 포함할 경우, 모델이 데이터의 특정 패턴에 과도하게 적합되어 새로운 데이터에 대한 일반화 성능이 떨어질 수 있음을 잘 보여준다.
