https://hans-j.tistory.com/178
미디어쿼리로 반응형으로 만든거랑 더보기 기능 만든거;; 이게 그렇게 리드미에 자랑이 하고싶었나보다...진짜 가지가지하는 나
5MB이하만 허용된다길래
이미지 용량줄이기 짬밥으로
이번에도 별 거 없겠지 싶었는데 별 거 였다..참내
p.s. 귀여워서 가져옴
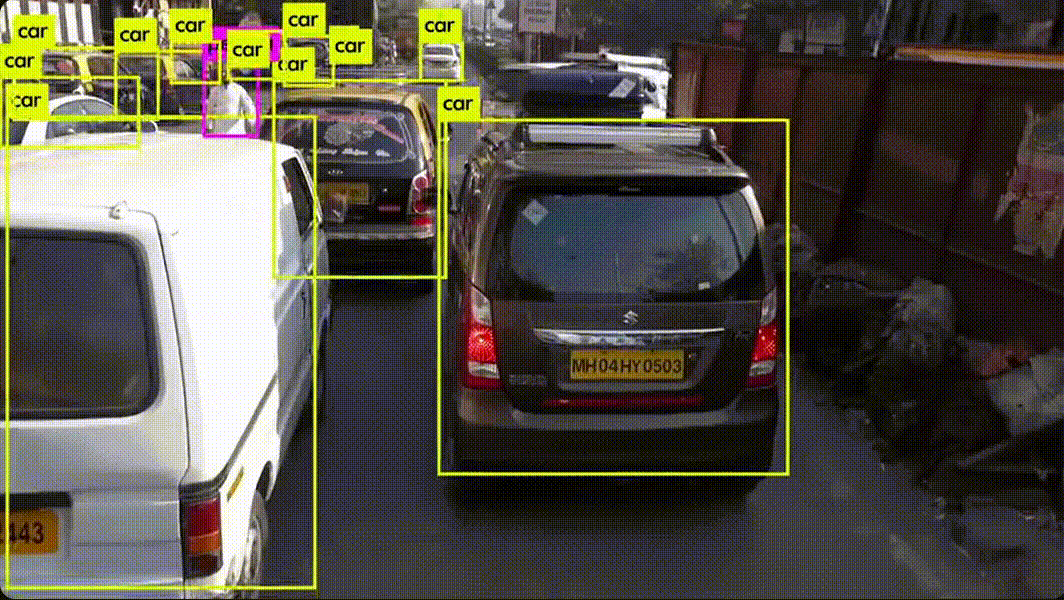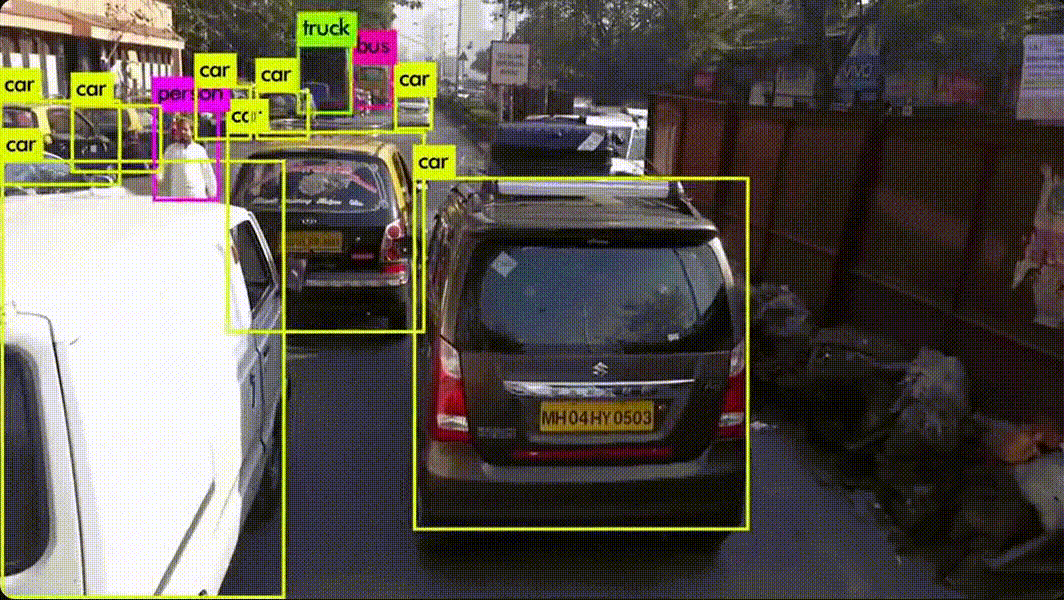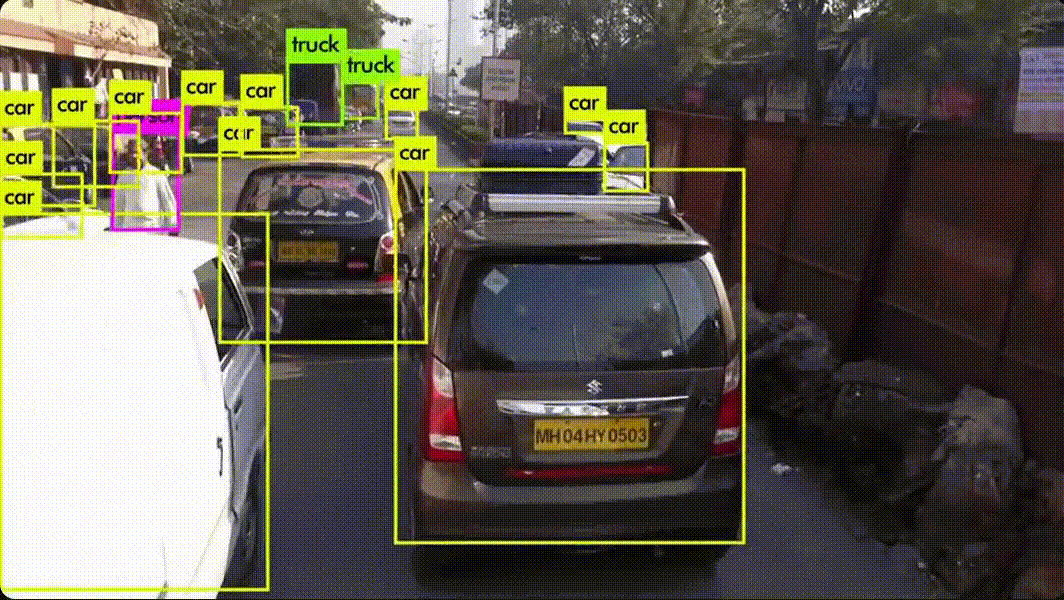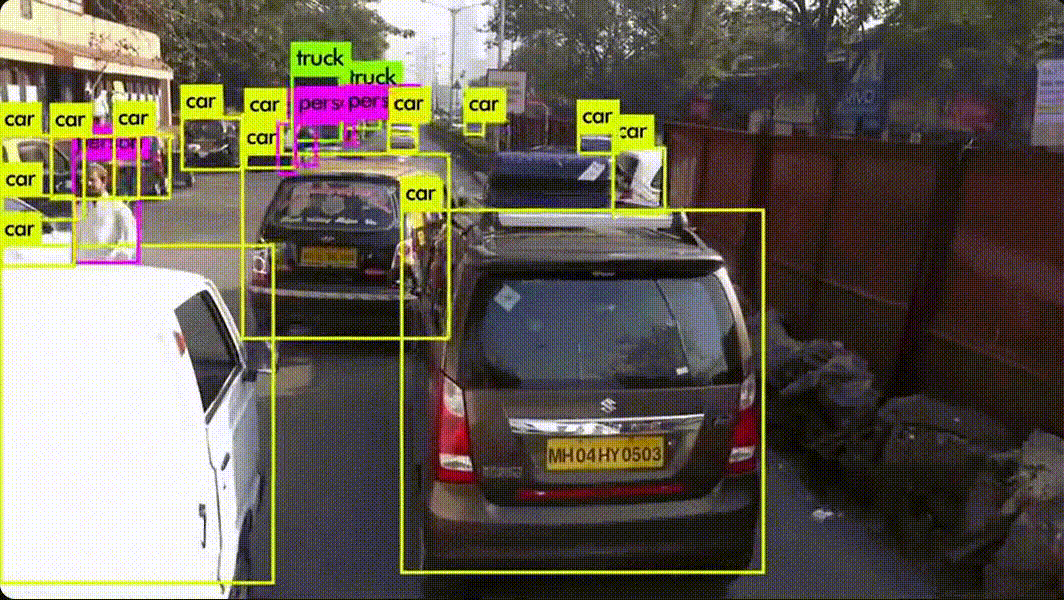
YOLO (You Only Look Once) 알고리즘
1) 배경 및 등장 맥락
YOLO(You Only Look Once) 알고리즘은 객체 탐지(Object Detection) 분야에서 기존 패러다임을 근본적으로 재정의한 모델로, 약 2015년에 제안되었다.
이 시기는 딥러닝 기반 컴퓨터 비전 기술이 본격적으로 성숙기에 접어들던 시점으로, 특히 정확도 중심의 모델 설계에서 속도와 실시간성까지 고려해야 하는 요구가 증가하던 시기였다.
기존 객체 탐지 방식의 한계
YOLO 이전의 전통적인 객체 탐지 시스템은 대부분 다단계 파이프라인(multi-stage pipeline) 구조를 갖고 있었다.
대표적인 예가 R-CNN 계열 모델이다.
기존 방식의 일반적인 흐름은 다음과 같다.
-
Region Proposal
- 이미지 내에서 객체가 존재할 가능성이 있는 영역(Bounding Box 후보)을 다수 생성
-
Classification
- 각 제안 영역에 대해 분류기(Classifier)를 적용하여 객체 여부 및 클래스 판별
-
Bounding Box Regression
- 예측된 Bounding Box를 보다 정확하게 조정
-
Post-processing
-
중복 검출 제거(Non-Maximum Suppression)
-
클래스별 점수 재산정
-
이러한 구조는 정확도는 높지만 다음과 같은 구조적 단점을 가진다.
-
연산 비용이 매우 큼
-
추론 속도가 느려 실시간 처리 불가
-
각 단계가 독립적으로 학습되어 엔드 투 엔드(end-to-end) 최적화가 어려움
-
파이프라인 복잡성으로 인해 시스템 유지·확장 비용 증가
딥러닝 도입 이후의 변화
2012년, AlexNet이 ImageNet 대회에서 압도적인 성능을 기록하며 CNN 기반 딥러닝이 컴퓨터 비전의 표준 접근법으로 자리 잡았다.
이후 R-CNN, Fast R-CNN, Faster R-CNN 등의 모델이 등장하며 정확도는 지속적으로 개선되었지만, 여전히 실시간 처리에는 한계가 존재했다.
2) YOLO의 핵심 아이디어
YOLO는 기존의 “검출을 위한 다단계 문제”를 다음과 같이 재정의한다.
객체 탐지는 이미지 픽셀로부터 Bounding Box 좌표와 클래스 확률을 직접 예측하는 하나의 회귀 문제(regression problem)이다.
-
Region Proposal 단계 제거
-
Classification과 Localization을 단일 신경망에서 동시에 수행
-
한 번의 Forward Pass로 전체 이미지의 객체를 예측
이러한 접근을 통해 YOLO는 단일 파이프라인(single pipeline) 객체 탐지를 실현한다.
3) YOLO의 주요 특징
통합 아키텍처 (Unified Architecture)
-
하나의 Convolutional Neural Network가
- 여러 Bounding Box
- 각 Bounding Box에 대한 Confidence
- 클래스 확률을 동시에 예측
객체 탐지를 엔드 투 엔드 학습 문제로 변환
속도 (Speed)
YOLO의 가장 큰 장점은 속도이다.
-
기본 YOLO 모델
- Titan X GPU 기준 45 FPS
-
Fast YOLO:
- 150 FPS
이는 실시간성이 중요한 다음 분야에서 결정적인 강점을 가진다.
-
자율 주행
-
실시간 감시 시스템
-
로보틱스
-
증강현실(AR)
또한, 동시대의 실시간 객체 탐지 모델 대비 2배 이상의 mAP를 기록했다.
학습 방식의 특징
YOLO는 훈련 및 추론 과정에서 항상 이미지 전체를 한 번에 본다.
-
Region Proposal 기반 모델
- 부분 영역 중심 학습
-
YOLO:
- 전역적(Global) 맥락 학습
이로 인해 다음과 같은 효과가 나타난다.
-
배경 정보를 포함한 문맥(Context) 학습
-
Background Error 감소 (Fast R-CNN 대비 현저히 적음)
일반화 성능 (Generalization)
YOLO는 특정 객체 패턴에 과도하게 의존하지 않고 일반적인 시각적 특징을 학습한다.
그 결과,
- 새로운 환경
- 새로운 시점
- 데이터가 적은 상황
에서도 비교적 안정적인 성능을 보인다.
한계점 (Accuracy Limitation)
YOLO는 속도를 얻는 대신 다음과 같은 단점을 가진다.
-
작은 객체(small object)에 대한 위치 정밀도가 낮음
-
Bounding Box 위치 오차가 비교적 큼
이는 이후 YOLOv2, YOLOv3, Anchor Box 도입 등으로 점진적으로 개선된다.
4) Unified Detection 구조
Grid 기반 예측 방식
YOLO는 입력 이미지를 S × S 그리드로 분할한다.
-
객체의 중심(center) 이 특정 그리드 셀 안에 있으면
- 해당 셀이 그 객체를 책임지고 예측
각 그리드 셀은 다음을 예측한다.
-
B개의 Bounding Box
-
각 Bounding Box에 대한 Confidence Score
-
Conditional Class Probabilities
Bounding Box 파라미터 정의
각 Bounding Box는 총 5개의 값을 예측한다.
| 변수 | 의미 |
|---|---|
| x, y | 그리드 셀 기준 Bounding Box 중심 좌표 |
| w, h | 이미지 대비 상대 너비·높이 |
| confidence | 객체 존재 확률 × IOU |
Conditional Class Probability
- 그리드 셀 안에 객체가 존재한다는 조건 하에, 해당 객체가 특정 클래스일 확률
테스트 단계에서는 다음 값을 계산한다.
-
해당 Bounding Box에 특정 클래스 객체가 있을 확률
-
Bounding Box의 적합도(IOU)를 동시에 반영한다.
5) 네트워크 설계 (Network Design)
YOLO는 단일 CNN 구조를 사용한다.
-
기본 구조
-
24개의 Convolutional Layers
-
2개의 Fully Connected Layers
-
구조적 특징
-
GoogLeNet의 분류 아이디어에서 영감
-
Inception Module 대신
-
1×1 Convolution (차원 축소)
-
3×3 Convolution (특징 추출)
-
Fast YOLO
-
Convolutional Layers: 9개
-
속도 최적화 목적
출력 텐서
최종 출력은 다음 형태의 텐서이다.
(20 클래스 + 2 Bounding Box × 5)
6) 학습 과정 (Training)
사전 학습 (Pretraining)
-
ImageNet 분류 모델로 사전 학습
-
ImageNet 2012 validation:
- Top-5 accuracy: 88%
이후 객체 검출용 구조로 확장하여 학습.
활성화 함수
-
마지막 계층: Linear
-
나머지 계층: Leaky ReLU
Loss Function
YOLO는 SSE (Sum of Squared Error) 를 사용한다.
장점
-
구현 단순
-
학습 안정성
단점
-
Localization Loss와 Classification Loss에 동일 가중치
-
mAP 최적화 관점에서는 비효율적
Loss 보정 전략
-
객체 존재 여부에 따른 가중치 조정
-
객체 있는 Box: Loss 증가
-
객체 없는 Box: Loss 감소
-
-
Bounding Box 크기 보정
-
( w, h )에 Square Root 적용
-
큰 Box가 작은 변화에 과도하게 반응하지 않도록 조정
-
-
Bounding Box 선택
- 가장 높은 IOU를 가진 Box만 책임 할당
이를 통해 모델은 다양한
-
크기
-
종횡비
-
클래스에 대해 예측할 수 있도록 학습된다.
7) 정리
YOLO는 객체 탐지를 하나의 회귀 문제로 재정의함으로써,
-
파이프라인 단순화
-
실시간 처리 가능
-
엔드 투 엔드 학습
이라는 패러다임 전환을 이끌었다.
비록 초기 버전에서는 정확도 한계가 존재했지만,
YOLO의 접근 방식은 이후 객체 탐지 연구 전반에 결정적인 영향을 미쳤으며 실시간 비전 시스템의 표준 설계 철학을 형성했다.
YOLO v1
YOLO v2
YOLO v3
YOLO v4
YOLO v5
YOLO v7
YOLO v6 (v7 다음에 출시)
YOLO v8
YOLO v9
