선형 회귀 : 보험료 예측하기

정리
- 선형 회귀(Linear Regression)는 독립변수(X)와 종속변수(y) 사이에 선형 관계가 있음을 가정하여 최적의 선을 찾아 예측하는 기법.
- 예: 키와 체중 간의 관계
- 완벽히 정비례하지 않더라도 데이터가 선형적인 경향을 보임.
손실 함수(Loss Function)를 최소화하는 선이 최적의 회귀선.
- 손실 함수란?
- 실젯값(실제값)과 예측값의 차이를 평가하는 함수.
- 예: MSE(Mean Squared Error), RMSE(Root Mean Squared Error) 등이 사용됨.
- 머신러닝은 손실 함수를 최소화하는 방향으로 최적의 선을 찾음.
라이브러리 및 데이터 불러오기
-
파이썬에서 데이터를 다룰 때 기본으로 사용되는 라이브러리인 판다스(pandas)를 불러오겠습니다. 라이브러리를 불러오는 걸 프로그래밍 용어로 ‘임포트(한다)’라고 합니다.
-
판다스를 불러왔으니 데이터를 불러오는 코드를 작성하겠습니다. 이번에 사용할 데이터는 insurance.csv 파일입니다. URL을 사용하여 불러오겠습니다.
pd.read_csv( )를 사용하면 판다스 데이터프레임 형태로 데이터를 불러오게 됩니다.
import pandas as pd # 판다스 라이브러리 임포트
file_url = 'https://media.githubusercontent.com/media/musthave-ML10/data_source/main/insurance.csv'
data = pd.read_csv(file_url) # 데이터셋 읽기
데이터 확인하기
data # 전체 데이터 출력
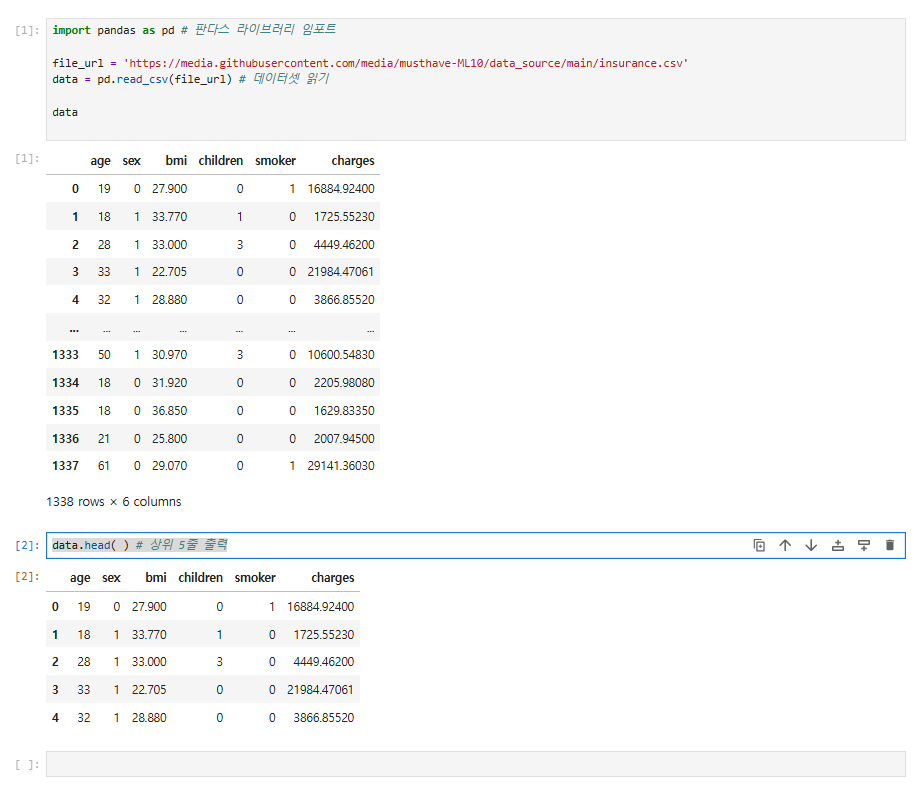
data.head( ) # 상위 5줄 출력
-
데이터를 불러왔으니, 불러온 데이터가 어떻게 생겼는지부터 다양한 방법으로 확인하겠습니다.
-
가장 직관적이고 단순한 방법은 저장한 데이터(data)를 그대로 입력해 출력하는 방식입니다.
① 1338 rows X 6 columns에서 볼 수 있듯이 data에는 총 1338줄, 즉 1338명에 대한 데이터가 있습니다.
② 6개의 변수가 있습니다.
③ 0부터 1337까지 있는 왼쪽 숫자를 인덱스라고 부르며, 기본값은 줄 번호입니다.
-
파이썬에서는 대부분 0부터 시작하는 것이 특징입니다. 1338줄 모두를 출력하지 않고 중략되었습니다.
-
-
data를 출력했을 때와 같은 형태이지만 5줄만 출력해 더 간결하게 볼 수 있다는 장점이 있습니다.
-
sex와 smoker는 사실 숫자로 표현되는 연속형 변수가 아닌, 범주형 변수입니다.
-
sex는 남성/여성으로 표시되어야 하고, smoker는 흡연자/비흡연자로 표시되어야 하는데, 컴퓨터로 학습하려면 (문자가 아니라) 숫자여야 해서 다음과 같이 표기
-
sex에서는 1이 남자, 0이 여자
-
smoker에서는 1이 흡연자, 0이 비흡연자
-
-
연속형 변수와 범주형 변수

-
연속형 변수는 나이, 키와 같이 연속적으로 이어지는 변수입니다.
-
연속형 변수에서는 데이터 간의 크고 작음을 비교하거나 사칙연산 등을 할 수 있습니다.
-
예를 들어, 키 180은 170보다 크다고 할 수 있고, 둘 사이의 평균도 구할 수 있습니다.
-
-
범주형 변수는 이어지는 숫자가 아닌 각 범주로 구성된 변수입니다.
-
예를 들어, 계절이나 성별은 범주형 변수에 속합니다.
-
범주형 데이터에서는 (예를 들어 겨울이 여름보다) 크거나 작다고 할 수 없으며, 평균이라는 개념 또한 존재할 수 없습니다.
-
data.info() #컬럼 정보 출력
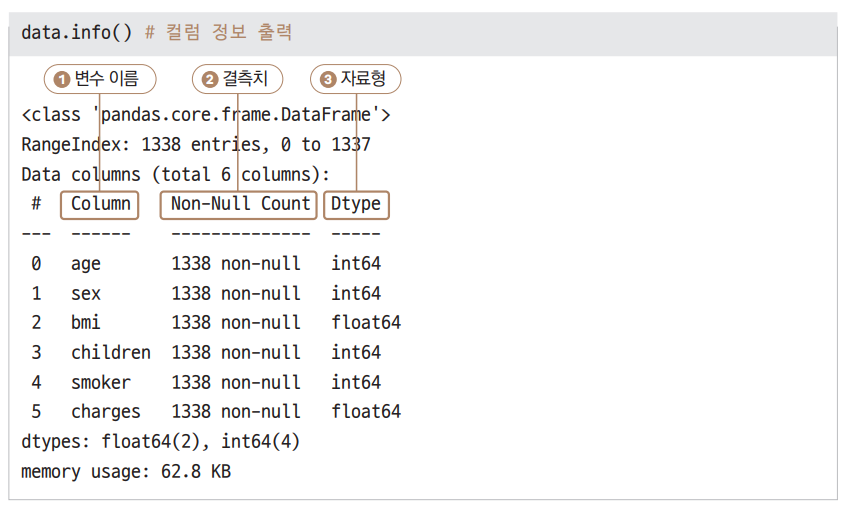
① Column에서는 data가 가진 변수 이름을 보여줍니다.
② Non-Null Count에서는 결측치를 보여줍니다.
-
Non-Null Count에서 Null은 결측치, 즉 비어 있는 값을 말합니다.
- Null값은 비어 있어서 알 수 없는 값이지, 0이 아니니 주의하시기 바랍니다.
-
non-null은 빈 값이 없다는 뜻입니다.
-
모든 변수가 1338입니다. 따라서 모든 변수에 빈 값이 없다는 사실을 확인할 수 있습니다.
③ Dtype은 자료형입니다.
- 모든 변수가 숫자형 데이터이기 때문에 float과 int로만 구성되어 있습니다.
data.describe( ) # 통계 정보 출력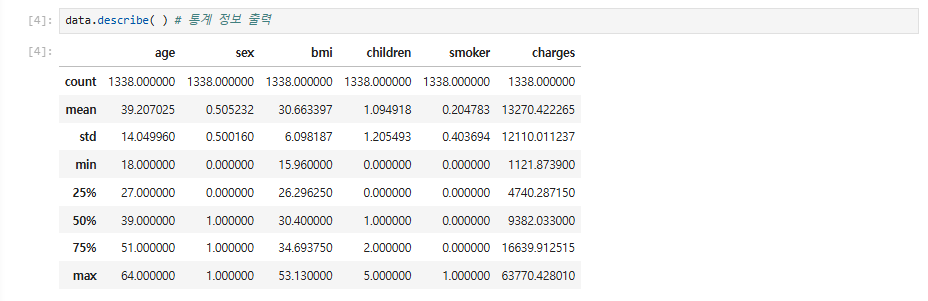
round(data.describe( ) , 2) # 소수점 2째자리까지만 표시해 통계 정보 출력
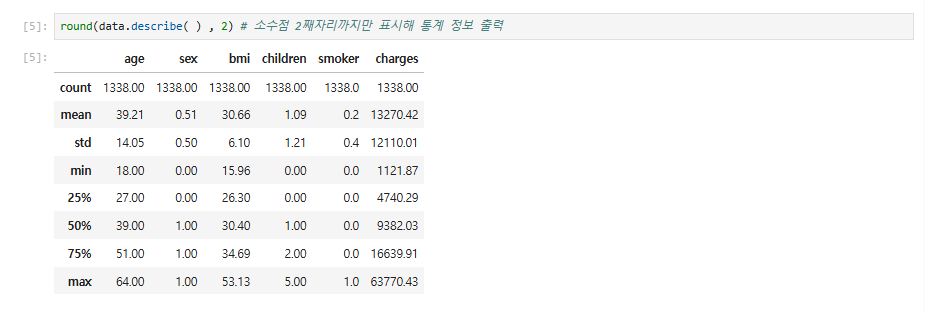
① 개수(count)는 모든 변수가 1338로 같은데, 여기에서도 데이터에 결측치가 없음을 확인할 수 있습니다.
② 평균(mean)
③ 표준편차(std)
④ 최솟값(min)
⑤ 사분위수 25%, 50%, 75%
-
사분위수(Quantile)
-
데이터를 오름차순으로 정리했을 때 25%, 50%, 75% 위치에서 확인한 값입니다.
-
예를 들어 100개의 값들이 있다고 하면 가장 낮은 숫자부터 하나씩 세어 25번째 데이터, 50번째 데이터, 75번째 데이터가 각각 사분위수 25%, 50%, 75%에 해당합니다.
- Q1, Q2, Q3라고도 표현합니다.
-
⑤ 최댓값(max)을 보여줍니다.
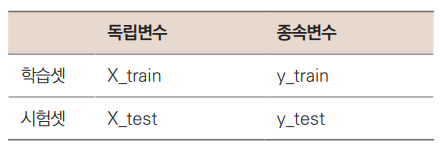
전처리 : 학습셋과 시험셋 나누기
-
데이터 클리닝 및 피처 엔지니어링
-
데이터 클리닝은 지저분한 데이터를 정리하는 과정입니다.
- 이는 결측치를 처리하는 과정부터, 오탈자 수정, 불필요한 문자 제거 등을 포괄합니다.
-
피처 엔지니어링은 가지고 있는 독립변수들을 활용해서 더욱 풍성하고 유용한 독립변수들을 만들어내는 작업입니다.
-
-
데이터를 나누는 작업은 크게 2가지 차원으로 진행됩니다.
-
첫째, 종속변수와 독립변수 분리입니다.
-
둘째, 학습용 데이터셋인 학습셋(Train set)과 평가용 시험셋(Test set)을 나누는 겁니다.
-
이렇게 2×2조합으로 총 4개 데이터셋으로 나눕니다.
-
변수와 데이터셋을 나누는 이유
-
기본적으로 지도 학습에 속하는 머신러닝 모델은 독립변수를 통하여 종속변수를 예측하는 것이므로, 모델링할 때 어떤 변수가 종속변수인지 명확히 알려주어야 합니다.
- 이런 이유로 많은 머신러닝 알고리즘이 독립변수와 종속변수를 각각 별도의 데이터로 입력받습니다.
-
학습셋과 시험셋을 나누는 이유는 무얼까요?
-
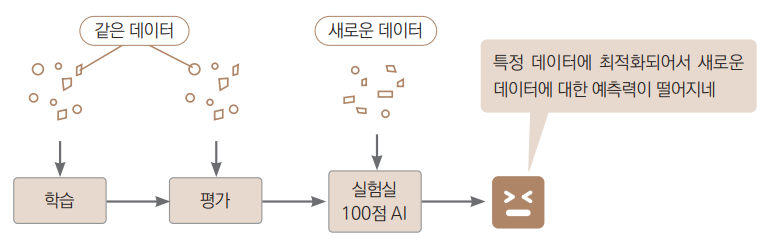
예를 들어 학습셋과 시험셋을 구분하지 않고 예측 모델을 만든다고 가정해보겠습니다.
-
전체 데이터를 가지고 모델링(학습)을 하고, 또 다시 전체 데이터에 대해서 예측값을 만들어서 종속변수와 비교해 예측이 잘 되었는지 평가한다고 합시다.
-
그 평가 결과가 어느 정도 괜찮았다고 해서 새로운 데이터에 대해서도 좋은 예측력을 보일까요?
- 학습에 사용한 데이터와 평가용으로 사용한 데이터가 동일하다는 것은 모델을 만들고 나서 새로운 데이터에도 맞는지 검증하지 않은 거나 다름 없기 때문입니다.
-
-
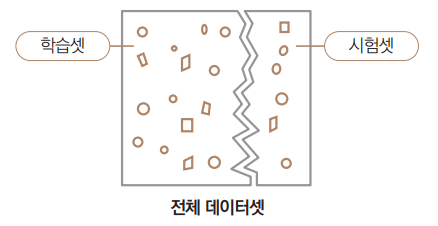
검증하지 않은 상태라는 불확실성을 줄일 목적으로 준비하는 것이 시험셋입니다.
-
예를 들어 1338개 데이터 중 1000개는 학습셋으로 나누어서 모델을 학습시키는 데 사용하고, 나머지 338개 데이터는 모델 학습이 완료된 이후에 평가용으로 사용할 수 있습니다.
-
이렇게 하면 학습된 모델에 있어 시험셋의 338개 데이터는 처음 만나게 되는 데이터인 겁니다.
-
시험셋으로 예측/평가를 했을 때도 예측력이 좋게 나타난다면, 향후 예측하게 될 새로운 데이터에 대해서도 잘 작동할 거라는 기대를 가질 수 있습니다.
-
-
-
일반적으로 학습셋:시험셋을 각각 7:3 혹은 8:2 정도 비율로 나눕니다.
-
비율은 데이터 크기에 따라 달라지기 마련인데, 전체 데이터 크기가 작을수록 시험셋 비율을 낮게 잡습니다.
-
두 데이터셋 중에 더 중요한 쪽을 따지자면 학습셋입니다.
- 실제 모델을 만드는 데 사용되는 데이터이기 때문에 충분한 양이 보장되지 않으면 모델 학습이 제대로 진행되지 않을 수 있습니다.
-
정답이 없기 때문에, 실제 분석을 하면서 비율을 수정해가며 다양한 시도를 해야 합니다.
-
데이터셋 나누기
-
종속변수와 독립변수를 나눈 후에 학습셋과 시험셋으로 나누겠습니다.
-
우선 독립변수를 X, 종속변수를 y로 나누겠습니다.
- X는 대문자, y는 소문자로 쓰는데, X는 변수가 여러 개 있는 데이터프레임(DataFrame)이기 때문에 대문자로, y는 변수가 하나인 시리즈(Series)이기 때문에 소문자로 씁니다. 관용적인 표현일 뿐, 다르게 쓴다고 해도 코드에서 문제는 없습니다.
Pandas는 데이터를 다루기 쉽게 하기 위해 DataFrame과 Series라는 구조를 제공
- 데이터프레임은 표 형태(tabular data)의 2차원 구조를 가진 데이터입니다.
- 행(Row)과 열(Column)로 이루어져 있으며, 스프레드시트나 SQL 테이블처럼 데이터가 저장
- 시리즈는 1차원 배열(One-dimensional array)과 같은 구조를 가진 데이터입니다.
- 파이썬의 리스트(List)나 NumPy의 배열(Array)과 비슷하지만, 인덱스(Index)를 함께 가지는 것이 특징입니다.
-
from sklearn.model_selection import train_test_split # 사이킷런 임포트
X = data[['age', 'sex', 'bmi', 'children', 'smoker']] # 독립변수
y = data['charges'] # 종속변수
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2,
random_state=100) # 데이터셋 분할

-
학습셋과 시험셋을 나누어줄 텐데 사이킷런(sklearn)에서는 관련 모듈(train_test_split)을 제공하므로 모듈을 불러옵시다.
-
독립변수/종속변수, 그리고 학습셋/시험셋 조합으로 총 4개 데이터셋(
X_train,X_test,y_train,y_test)이 나왔습니다. -
= 왼쪽(좌항)에 보통은 변수가 하나이기 마련인데 여기에서는 4개나 들어 있습니다. -
= 오른쪽 코드(우항)에는 괄호 안에 독립변수(X)와 종속변수(y)를 순서대로 입력해야 합니다. -
test_size는 시험셋의 비율을 의미합니다.- 여기에서는 0.2를 넣었으므로 20%, 즉 8:2로 데이터를 나누겠다는 의미입니다.
-
-
random_state는 랜덤 샘플링과 관련이 있는데, 우선 랜덤 샘플링을 알아봅시다.-
기본적으로
train_test_split( )함수는 랜덤 샘플링을 지원합니다.-
train_test_split( )함수는 랜덤하게 샘플링하면서도, 지속적으로 같은 데이터 분류를 지원합니다. -
random_state옵션을 사용하면 됩니다.- 여기에는 그 어떤 임의의 숫자를 넣어도 상관없습니다. 같은 숫자라면 같은 형태로 분류된 데이터셋들을 얻게 됩니다.
-
-
랜덤 샘플링은 데이터를 특정 비율로 나눌 때 마구잡이로 뒤섞어서 나누는 겁니다.
- 만약 랜덤 샘플링을 사용하지 않으면 데이터를 있는 순서 그대로 분할합니다.
-
예를 들어, 1338개 데이터의 앞에서부터 80%가 학습셋이 되고, 뒷부분인 나머지 20%가 시험셋이 됩니다.
-
종종 데이터가 특정 순서로 정렬된 경우도 있습니다.
-
예를 들어, 데이터 앞쪽에는 여자, 뒷쪽에는 남자를 두는 식으로 정리를 해둘 수 있죠.
-
이런 식으로 특정 기준에 따라 정렬된 데이터를 순서대로 분류해버리면 학습셋과 시험셋의 특징이 확연히 다를 수밖에 없습니다.
-
샘플링된 데이터셋은 그 특성이 최대한 전체 데이터셋과 비슷하게 유지되어야 하기 때문에 위험한 방식입니다.
- 이와 같은 이유로 랜덤 샘플링을 일반적으로 널리 사용합니다.
-
-
train_test_split( ) 함수는 기존 데이터의 순서와 상관없이 마구잡이로 섞어서 데이터를 분류시킵니다.
- 그렇기 때문에 매번 실행할 때마다
train_set과test_set에 들어가는 데이터가 달라집니다.
- 그렇기 때문에 매번 실행할 때마다
-
-
모델링

-
모델링은 머신러닝 알고리즘으로 모델을 학습시키는 과정이며, 그 결과물이 머신러닝 모델이 됩니다.
-
모델링에 사용할 머신러닝 알고리즘을 선택하고, 독립변수와 종속변수를
fit( )함수에 인수로 주어 학습합니다.
-
이번 데이터셋에는 선형 회귀 알고리즘을 사용합니다.
- 따라서
sklearn.linear_model에서 선형 회귀 라이브러리를 불러옵니다.
파이썬은 대소문자에 민감하므로 반드시 대소문자 구분해 사용해주세요.
-
이제 모델을 만들어주어야 합니다.
- 여기서는
model이라는 이름의 객체에 선형 회귀의 속성을 부여하겠습니다.
- 여기서는
-
선형 회귀에 사용할
model객체를 생성했으니 객체를 사용해서 선형 회귀로 학습하고 예측할 수 있게 됩니다.
- 따라서
-
fit( )함수의 인수로 독립변수와 종속변수를 입력합니다.-
이미 데이터를 나누었기 때문에 쉽게 독립변수와 종속변수를 나눠 입력할 수 있습니다. 학습 과정이므로 학습셋을 사용합니다.
-
여기서 ‘학습시킨다’함은, 데이터를 모델 안에 넣어서 독립변수와 종속변수 간의 관계들을 분석해 새로운 데이터를 예측할 수 있는 상태로 만드는 겁니다.
-
이로써 model은 데이터를 통해 학습을 완료해 예측을 할 수 있게 되었습니다.
-
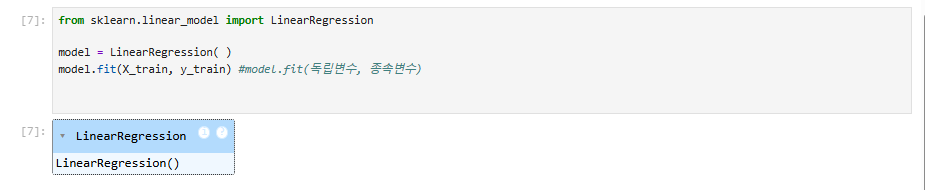
from sklearn.linear_model import LinearRegression
model = LinearRegression( )
model.fit(X_train, y_train) #model.fit(독립변수, 종속변수)
모델을 활용해 예측하기
-
오버피팅(overfitting)
-
모델이 학습셋에 지나치게 잘 맞도록 학습되어서 새로운 데이터에 대한 예측력이 떨어지는 현상을 의미합니다.
-
과적합, 과학습으로도 부릅니다.
-
pred = model.predict(X_test)
-
predict( )함수로 예측을 할 수 있으며, 괄호 안에는 예측 대상을 넣어주면 됩니다.-
목표 변수를 예측해야 하므로 여기에 들어가는 데이터에는 당연히 목표 변수가 포함되어서는 안 됩니다.
-
그러면 정답을 알려주는 꼴이 되기 때문입니다. 따라서 학습 때 사용했던 독립변수들을 가진 데이터를 넣어주어야 합니다.
-
-
train_test_split( )함수를 사용하면X_train과X_test가 같은 변수를 가지기 때문에 이 부분은 염려할 필요가 없습니다만, 향후 정말 새로운 데이터로 예측할 때는 주의해야 합니다.- 독립변수 중 하나라도 빠진 나머지 데이터로 예측을 시도한다면 모델은 예측 과정에서 오류를 발생하게 됩니다.
예측 모델 평가하기
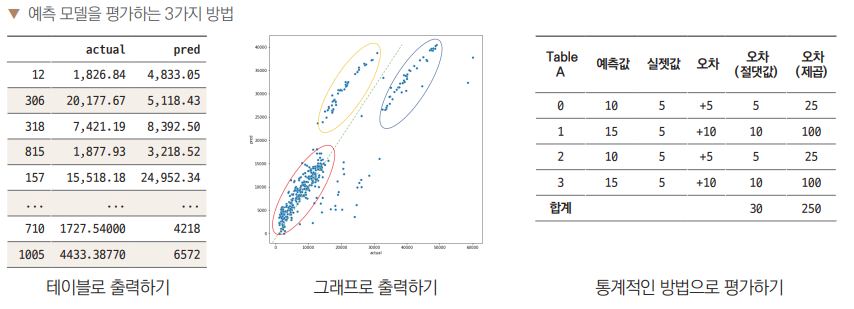
테이블로 평가하기
-
예측한 값은
pred에, 각각 관측치에 대한 실제 정보는y_test에 저장되어 있습니다.-
예측값이 얼마나 정확한지는
pred와y_test를 비교하는 것으로 단순하게나마 확인할 수 있습니다. -
pred와y_test를 각각 별도로 출력해 확인할 수도 있겠지만, 보기 편하게 두 데이터를 합쳐서 테이블 하나로 생성-
판다스의
DataFrame( )함수로 테이블 생성 -
actual이라는 컬럼 이름으로y_test값을 넣고,pred라는 컬럼 이름으로pred데이터값을 할당 -
테이블을
comparison에 저장
-
-
comparison = pd.DataFrame({'actual': y_test, 'pred': pred})
comparison
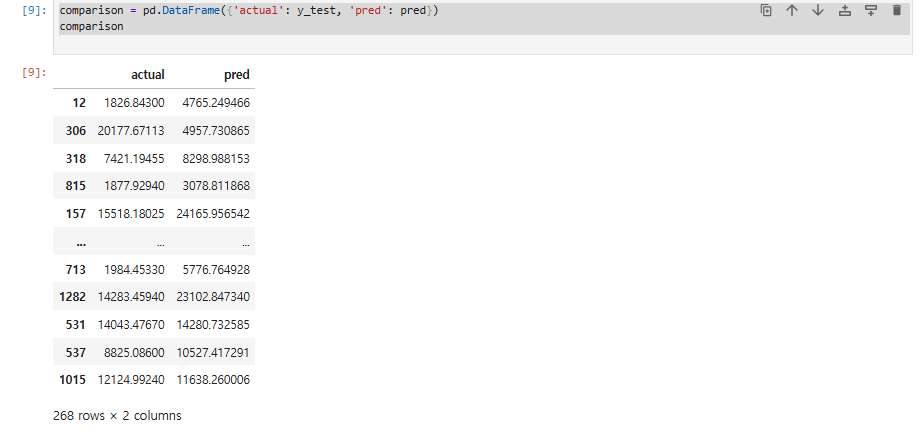
-
첫 번째 관측치를 보면 실젯값이 1826이고 예측값은 4765 정도로 차이가 큽니다.
- 마지막 관측치는 실젯값 12124, 예측값 약 11638로 그나마 좀 비슷합니다.
그래프로 평가하기
-
파이썬에서 그래프를 그리는 데 matplotlib과 seaborn 라이브러리를 가장 많이 사용합니다.
① matplotlib은 plt
② seaborn은 sns
-
여기에서는 그래프 크기를 정하는 코드와 산점도 그래프를 만드는 코드 두 줄을 써보겠습니다.
import matplotlib.pyplot as plt # ①
import seaborn as sns # ②
plt.figure(figsize=(10,10)) # ① 그래프 크기 정의
sns.scatterplot(x = 'actual', y = 'pred', data = comparison) # ②
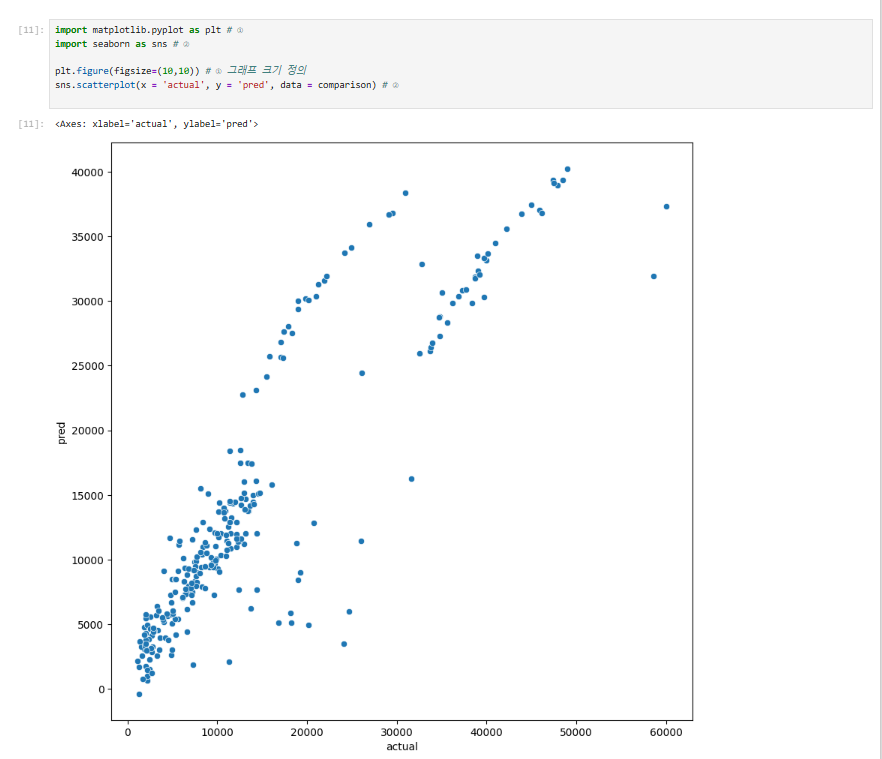
① 그래프 크기를 정하고
② scatterplot( ) 함수를 이용하여 산점도 그래프를 만들었습니다.
- 인수로 x축과 y축에 들어갈 데이터 컬럼을 지정합니다.
- x축에 실젯값인
actual, y축에는 예측값인pred를 지정했습니다. - x, y축에 지정해준 컬럼이 속한 데이터를 마지막에 넣어주었습니다.
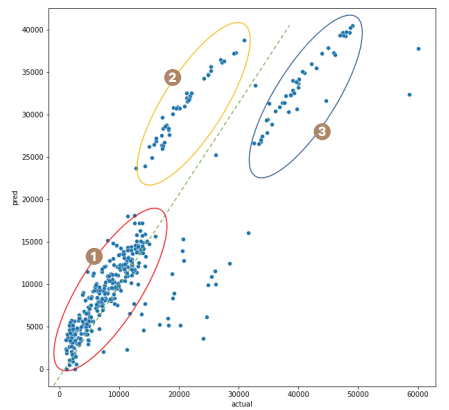
-
이해를 돕고자 그래프에 점선과 동그라미를 추가로 그렸습니다.
-
녹색 점선은 실젯값과 예측값이 정확히 같을 때, 즉 1:1로 매칭되었을 때를 의미합니다.
-
이 선에 가까울수록 더 잘 예측된 점이라고 해석할 수 있습니다.
-
이 그래프는 크게 3개의 영역으로 구분해 해석할 수 있습니다.
①번 빨간 타원의 데이터는 녹색 점선에 가까우므로 실젯값과 예측값이 비슷한, 즉 비교적 예측이 잘된 경우입니다.
②번 노란 타원의 데이터는 전반적으로 실젯값보다 예측값이 더 높게 나타난 경우입니다.
③번 파란 타원은 실젯값보다 예측값이 더 낮은 경우입니다.
-
-
그래프로 그렸더니 테이블로 일일이 확인할 때보다 훨씬 평가가 수월하지만 그래프로 평가를 하는 방식은 어디까지나 직관적으로 예측력을 확인할 뿐이지, 객관적인 기준이 되지는 않습니다.
통계적인 방법으로 평가하기 : RMSE
-
연속형 변수를 예측하고 평가할 때 가장 흔하게 쓰이는 RMSERoot Mean Squared Error(루트 평균 제곱근 오차, 평균 제곱근 편차)를 사용해보겠습니다.
- RMSE를 아주 단순하게 말하면 실젯값과 예측값 사이의 오차를 각각 합산하는 개념입니다.
-
예를 들어 2개 데이터가 있고 예측값과 실젯값이 다음과 같다고 가정해봅시다.
-
각 차이가
-2와+2로, 이 둘을 더해버리면0이 됩니다.- 차이가 0이라고 하면 완전히 정확하게 예측한 것처럼 보이지만 실제로는 그렇지 않죠?
-
+-부호 때문에 단순히 차이를 합산하면 이런 문제가 발생합니다.- 부호 문제를 없애기 위해 절댓값을 쓰거나 제곱한 값을 사용할 수 있는데, 일반적으로 제곱한 값을 사용합니다.
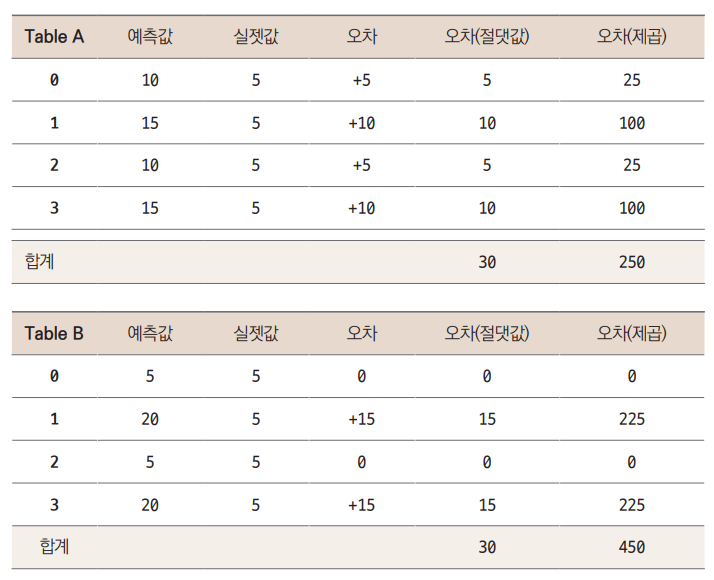
-
-
Table A는 오차가 각각
+5,+10,+5,+10으로 비교적 고르게 나왔습니다.- 반면 Table B에서는 오차가
0인 게 2건, 나머지 2건이+15로 꽤 크게 났습니다. 더 오차의 분포가 크다고 할 수 있습니다.
- 반면 Table B에서는 오차가
-
이제 각 테이블의 오차(절댓값)를 보면 두 경우 모두
30으로 같습니다.-
즉, 오차에 대한 분포에 상관없이 합산된 값이 같습니다. 반면 오차(제곱)는 Table A에서는
250, B에서는450으로, Table B에서 훨씬 더 큽니다. -
이는 오차가 클수록 (여기서는 1행과 3행) 제곱하면 더 큰 값이 되기 때문입니다.
-
그래서 통상 오차가 더 큰 때에 더 큰 패널티를 주고자 제곱의 차이를 사용하곤 합니다.
-
제곱을 사용하는 수식의 장점은 미분이 가능하다는 겁니다.
-

-
MAE(Mean Absolute Error, 평균 절대 오차): 절댓값 차이를 이용하는 방법
-
MSE(Mean Squared Error, 평균 제곱 오차): 제곱 차이를 활용하는 방법
일반적으로 MAE보다 MSE를 더 일반적으로 사용한다.
-
앞에 Mean이 붙은 이유는, 차이의 합을 총 개수로 나누어 평균을 내기 때문입니다.
-
Table A를 예로 들어 설명하겠습니다.
-
Table A에서 MAE는 오차(절댓값)의 총합 30을 4로 나눈 7.5가 됩니다.
-
MSE는 오차(제곱)의 합 250을 4로 나누어 62.5가 됩니다.
-
-
-
MSE의 단점은 제곱으로 인해 그 숫자의 규모가 실제 데이터의 스케일에 비해 너무 커진다는 겁니다.
-
즉, 두 테이블에서의 데이터의 차이는
0,5,10,15정도 수준인데 MSE는 평균을 낸 값임에도 불구하고 제곱한 값이므로 훨씬 더 큰 62.5라는 숫자를 보여줍니다.-
반면 MAE는 7.5로 뭔가 더 합리적으로 보이는 크기의 숫자입니다(실제 데이터에 더 근사한 오차를 보여줍니다).
-
이 부분을 해소해주기 위해 MSE에 루트를 한 번 씌워줍니다. 그러면 본래 데이터와 스케일도 맞아 떨어집니다.
-
-
이렇게 MSE에 루트를 씌워준 값을 RMSE(Root Mean Squared Error, 루트 평균 제곱 오차)라고 부르며, 이 지표가 연속형 변수를 예측할 때 가장 일반적으로 쓰이는 평가지표입니다.
-
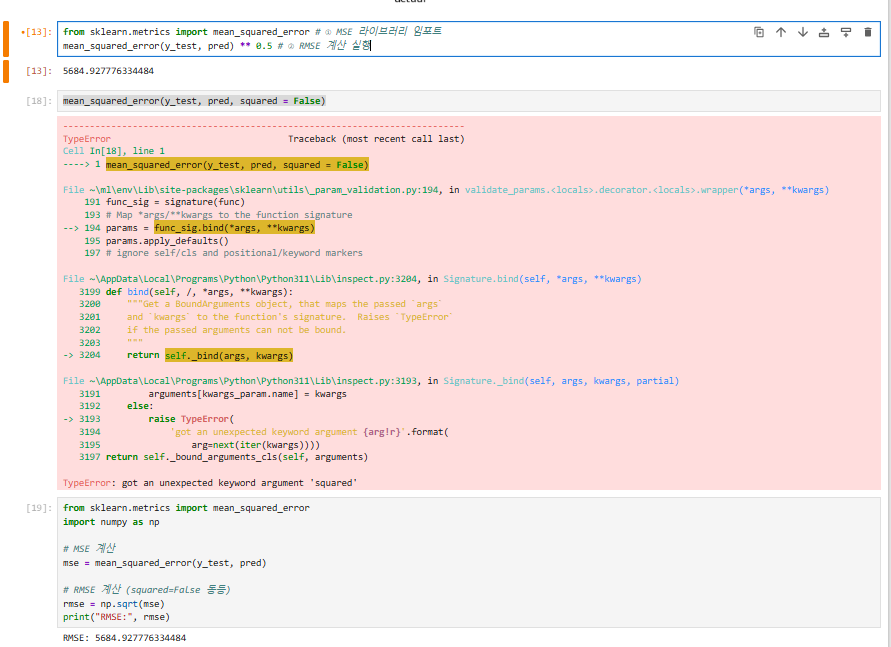
from sklearn.metrics import mean_squared_error # ① MSE 라이브러리 임포트
mean_squared_error(y_test, pred) ** 0.5 # ② RMSE 계산 실행 (실제값, 예측값)
mean_squared_error(y_test, pred, squared = False) #MSE 계산
#Scikit-learn 업그레이드 불가한 경우
from sklearn.metrics import mean_squared_error
import numpy as np
# MSE 계산
mse = mean_squared_error(y_test, pred)
# RMSE 계산 (squared=False 동등)
rmse = np.sqrt(mse)
print("RMSE:", rmse)
-
RMSE는 근본적으로 에러에 대한 합을 계산한 것이기 때문에, 작을수록 예측력이 좋다고 할 수 있습니다.
-
그럼 5684는 작은편에 속할까요, 큰편에 속할까요? 안타깝게도 RMSE를 평가하는 절대적인 기준은 없습니다.
-
이는 데이터의 특성에 따라 천차만별로 달라질 수 있기 때문에, 어느 수준 이하면 좋은 예측을 보인다는 등의 말을 하기가 어렵습니다.
-
그래서 RMSE는 절대 평가보다는 상대 평가에 사용합니다.
-
같은 데이터에 여러 가지 모델링을 해보고, 그중 어떤 모델이 가장 뛰어난 예측력을 보이는지를 판단할 때 RMSE가 가장 낮은 모델을 선택하면 됩니다.
-
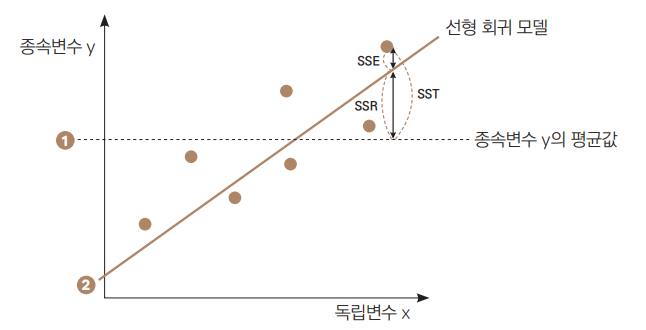
-
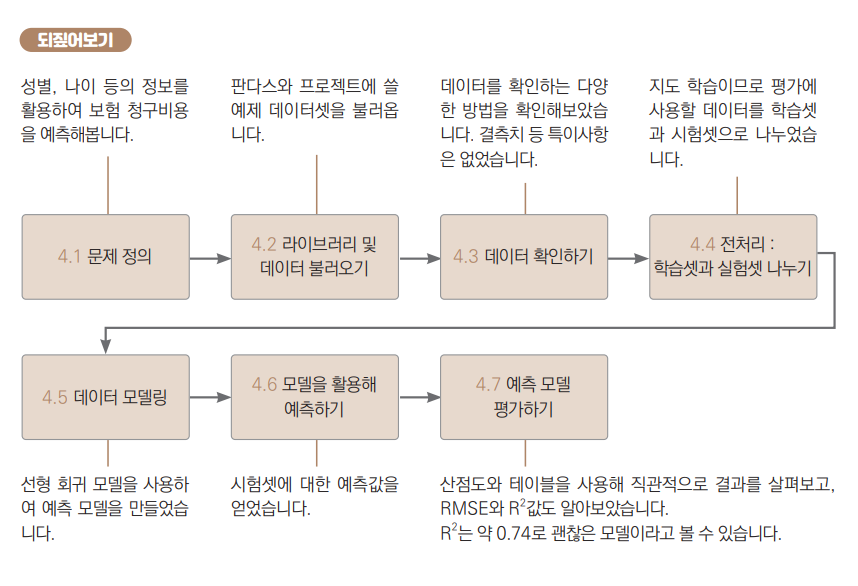
R2는 독립변수로 설명되는 종속변수의 분산 비율을 나타내는 통계적 측정값입니다.
①번 점선은 종속변수의 평균값으로 모델의 성능을 평가하는 비교 대상, 즉 일종의 기준선 역할입니다.
- ①번 점선으로부터 관측치까지 차이를 SST(Sum of Squares Total)라고 부릅니다.
②번 실선은 우리가 만든 예측 모델입니다.
-
특정 데이터의 x값을 기준으로 ①번 점선부터 ②번 실선까지의 거리가 SSR(Sum of Squares Regression)입니다.
- 즉, 평균으로 대충 때려 맞추었을 때와, 우리가 만든 모델을 이용했을 때의 차이죠.
②번 실선과 실제 데이터까지의 거리는 SSE(Sum of Squares Error)입니다. 우리가 만든 모델이 예측해내지 못한 에러를 나타냅니다.
-
R2는 SST에서 SSR가 차지하는 비율을 나타냅니다.
- 즉, 대충 평균값으로 넣었을 때, 예측값(평균값)과 실젯값의 차이 중 우리 모델이 얼마만큼의 비율로 실젯값에 가깝게 예측하는지를 의미합니다.
model.score(X_train, y_train)

이해하기: 선형 회귀
1. 선형 회귀란?
-
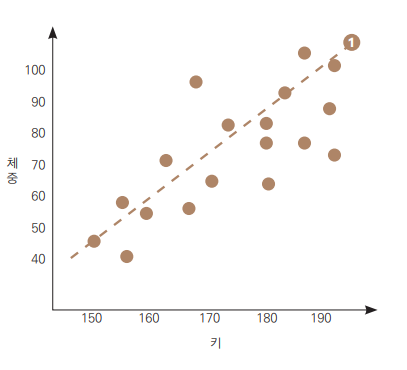
선형 회귀(Linear Regression)는 독립변수(X)와 종속변수(y) 사이에 선형 관계가 있음을 가정하여 최적의 선을 찾아 예측하는 기법.
-
예: 키와 체중 간의 관계
- 완벽히 정비례하지 않더라도 데이터가 선형적인 경향을 보임.
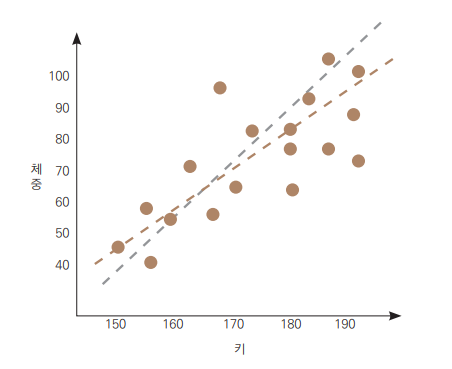
- 손실 함수(Loss Function)를 최소화하는 선이 최적의 회귀선.
-
손실 함수란?
-
실젯값(실제값)과 예측값의 차이를 평가하는 함수.
- 예: MSE(Mean Squared Error), RMSE(Root Mean Squared Error) 등이 사용됨.
-
머신러닝은 손실 함수를 최소화하는 방향으로 최적의 선을 찾음.
-
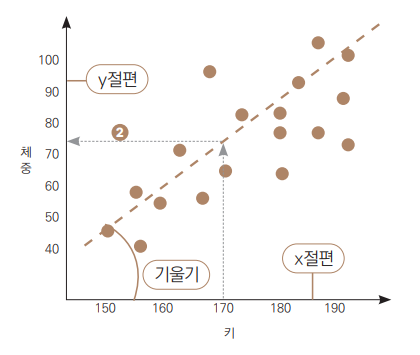
2. 선형 회귀 모델의 원리
-
1차 함수로 해당 모델을 표현
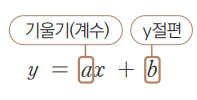
-
y: 종속변수(체중)
-
x: 독립변수(키)
-
a: 회귀선의 기울기
-
b: y절편
-
-
독립변수가 한 개라면 그림으로 시각화 가능.
-
독립변수가 여러 개라면
-
A~E: 기울기 (= 계수 coefficient), 모델 학습 통해 추정됨. -
intercept: y절편.
-
3. 계수 분석 방법
-
학습된 선형 회귀 모델은 각 독립변수의 기울기(계수)와 y절편 제공.
-
계수 확인 코드
model.coef_예시:
array([2.64799803e+02, 1.73446608e+01, 2.97514806e+02, 4.69339602e+02, 2.34692802e+04]) -
계수를 pandas.Series로 변환
pd.Series(model.coef_, index=X.columns) #출력 결과 age 264.799803 sex 17.344661 bmi 297.514806 children 469.339602 smoker 23469.280173 dtype: float64-
age: 나이가 1만큼 증가 → charges가 약 265 증가.
-
sex: 남자(1)는 여자(0)에 비해 charges가 약 17만큼 더 많음.
-
smoker: 흡연자(1)는 비흡연자(0)에 비해 charges가 큰 영향을 미침.
-
-
y절편 확인
model.intercept_ #출력 결과 -11576.999976112367 -
결합된 수식
4. 주의할 점
-
계수의 부호와 크기
-
계수의 절댓값이 클수록 변수의 영향력이 큼.
-
그러나 변수 간의 스케일 차이로 인해 단순 절댓값 비교에는 주의 필요.
-
-
스케일링 필요성
-
예: 성별(0, 1) vs 나이(20~60) → 서로 다른 단위를 가지므로, 직접 비교가 어려움.
-
스케일링(정규화, 표준화)을 통해 변수를 정규화하면 비교 가능.
-
5. 관련 모델
-
릿지 회귀 (Ridge Regression)
-
패키지:
from sklearn.linear_model import Ridge -
L2 정규화 적용 → 오버피팅 방지.
-
-
라쏘 회귀 (Lasso Regression)
-
패키지:
from sklearn.linear_model import Lasso -
L1 정규화 적용 → 피처 셀렉션 & 오버피팅 방지.
-
-
엘라스틱 넷 (Elastic Net)
-
패키지:
from sklearn.linear_model import ElasticNet -
릿지와 라쏘 회귀의 특성을 결합.
-
6. 핵심 용어
-
선형 회귀: 독립변수-종속변수 간 선형 관계를 기반으로 한 모델.
-
Null 값: 값이 비어 있는 상태 (NA, NaN 등으로 표현).
-
사분위수(Quantile): 데이터를 정렬했을 때 상위 25%, 50%, 75% 위치 값.
-
오버피팅(Overfitting): 학습 데이터에 너무 최적화되어 새로운 데이터에서 성능이 저하되는 현상.
7. 주요 함수 및 라이브러리
데이터 탐색
-
pandas.DataFrame(): 데이터를 DataFrame 형태로 변환. -
DataFrame.head(): 데이터프레임 상위 5줄 표시. -
DataFrame.info(): 데이터프레임 구조 요약. -
DataFrame.describe(): 통계적 요약 제공.
데이터 분리 및 모델 평가
-
train_test_split(): 훈련세트와 테스트세트 분리. -
mean_squared_error(): 평균 제곱 오차 계산.
모델 학습 및 예측
-
모델.fit(): 모델 학습. -
모델.predict(): 학습된 모델을 통한 예측 값 도출.
시각화
-
matplotlib.figure(): 새로운 도표 생성. -
seaborn.scatterplot(): 산점도 그래프 생성.
