
✍🏻 14, 15일 공부 이야기.
아래 작업한 태블로 시트는
https://public.tableau.com/app/profile/sungmi.hwang
링크에 올려두었습니다:)
퀵 테이블 계산
퀵 테이블 계산을 사용하면 원하는 시각화를 보다 빠르고 쉽게 할 수 있다.
누계
각각의 값을 누적해서 볼 때 사용
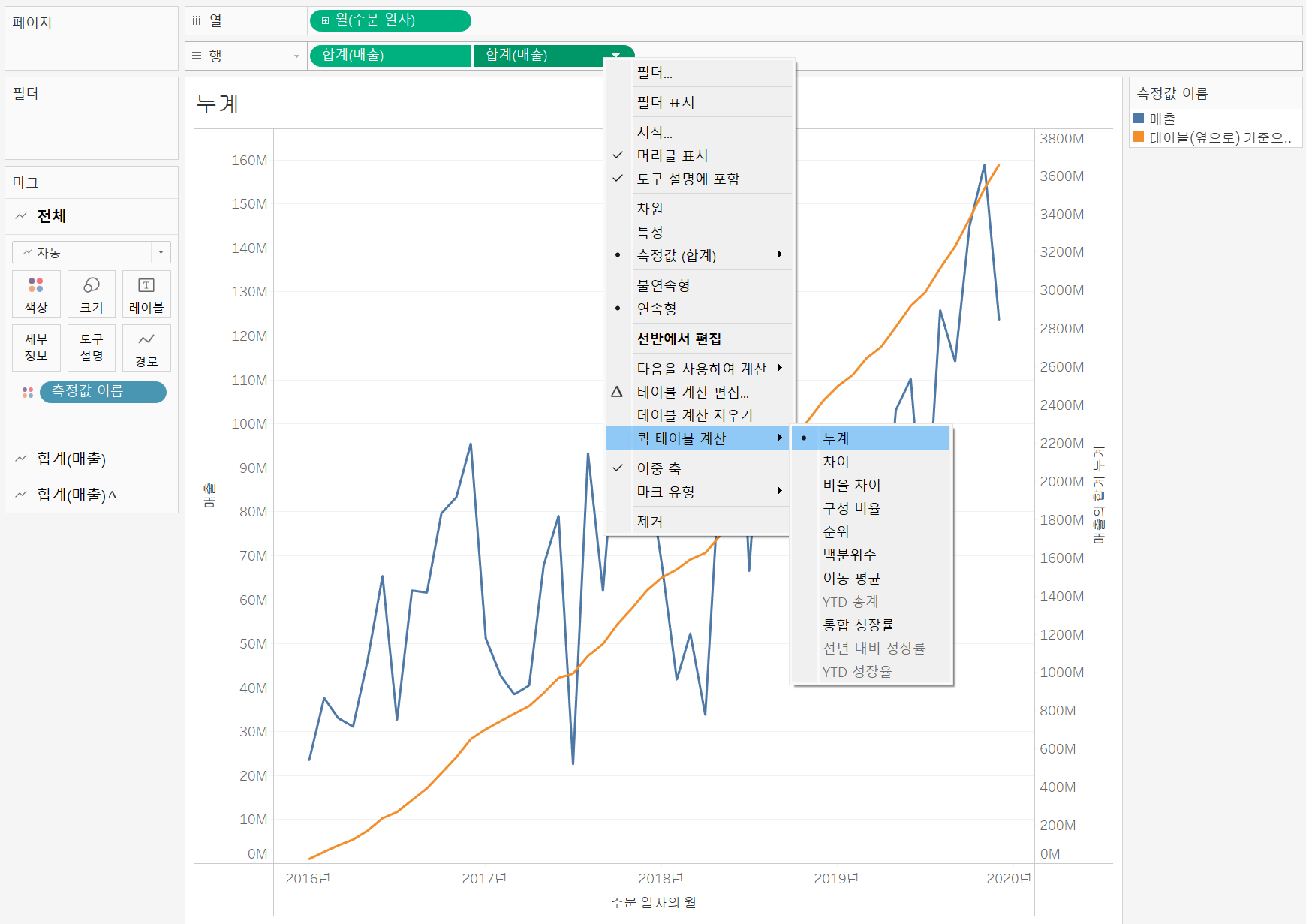
위와 같이 누계와 이중축을 같이 설정해주면 각 월의 매출값과 누적값을 한 번에 확인할 수 있다.
차이
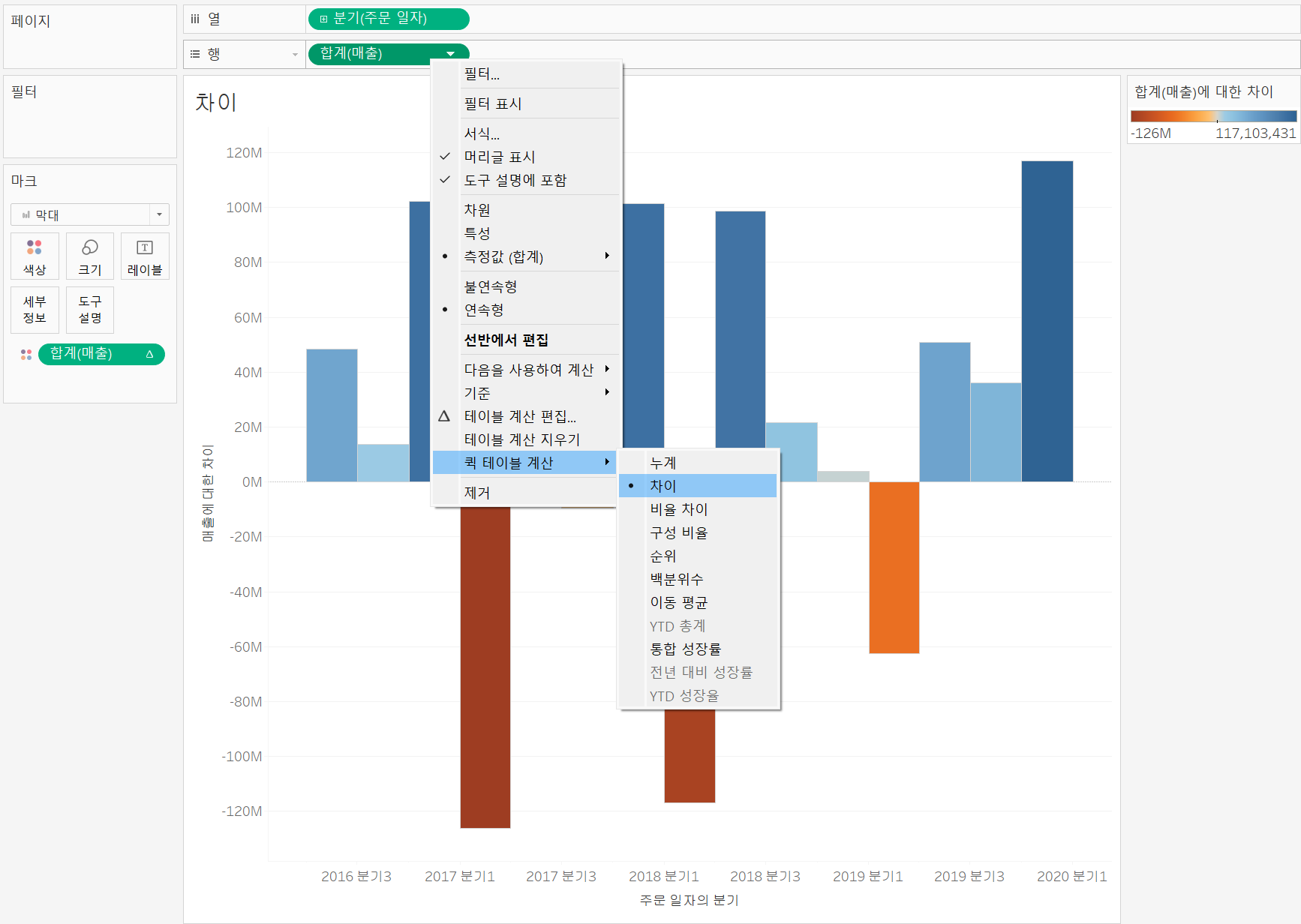
차이로 설정하고 마크 색상에 넣어주면 전 분기와의 차이를 시각적으로 표현할 수도 있다.
"바로 직전 분기가 아닌 차이도 구할 수 있을까?"
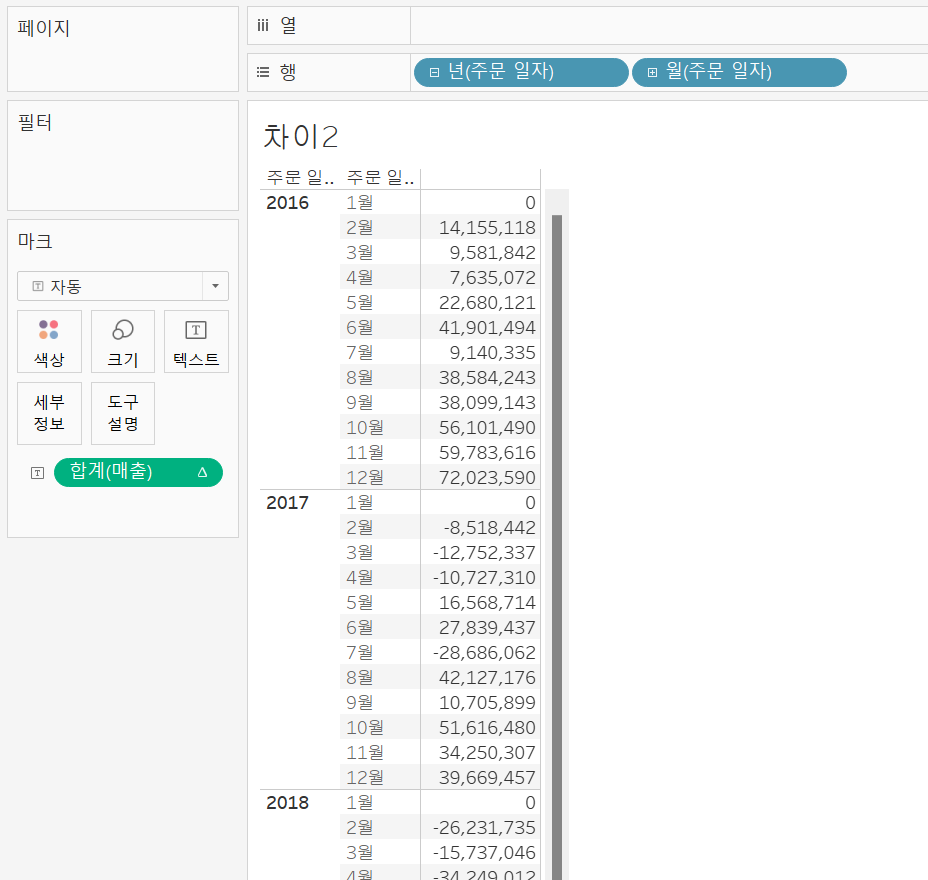
2016년 2월 ~ 12월 매출값을 2016년 1월 매출값과 비교하고 2017년 2월 ~ 12월 매출값을 2017년 1월 매출값과 비교해본 시트이다.
이는 단순히 매출 필드를 차이로 설정하는 것 뿐만 아니라, [기준] - 첫번째, [다음을 사용하여 계산] - 패널(아래로) 설정을 해주어야 위와 같은 비교를 할 수 있다.
구성 비율
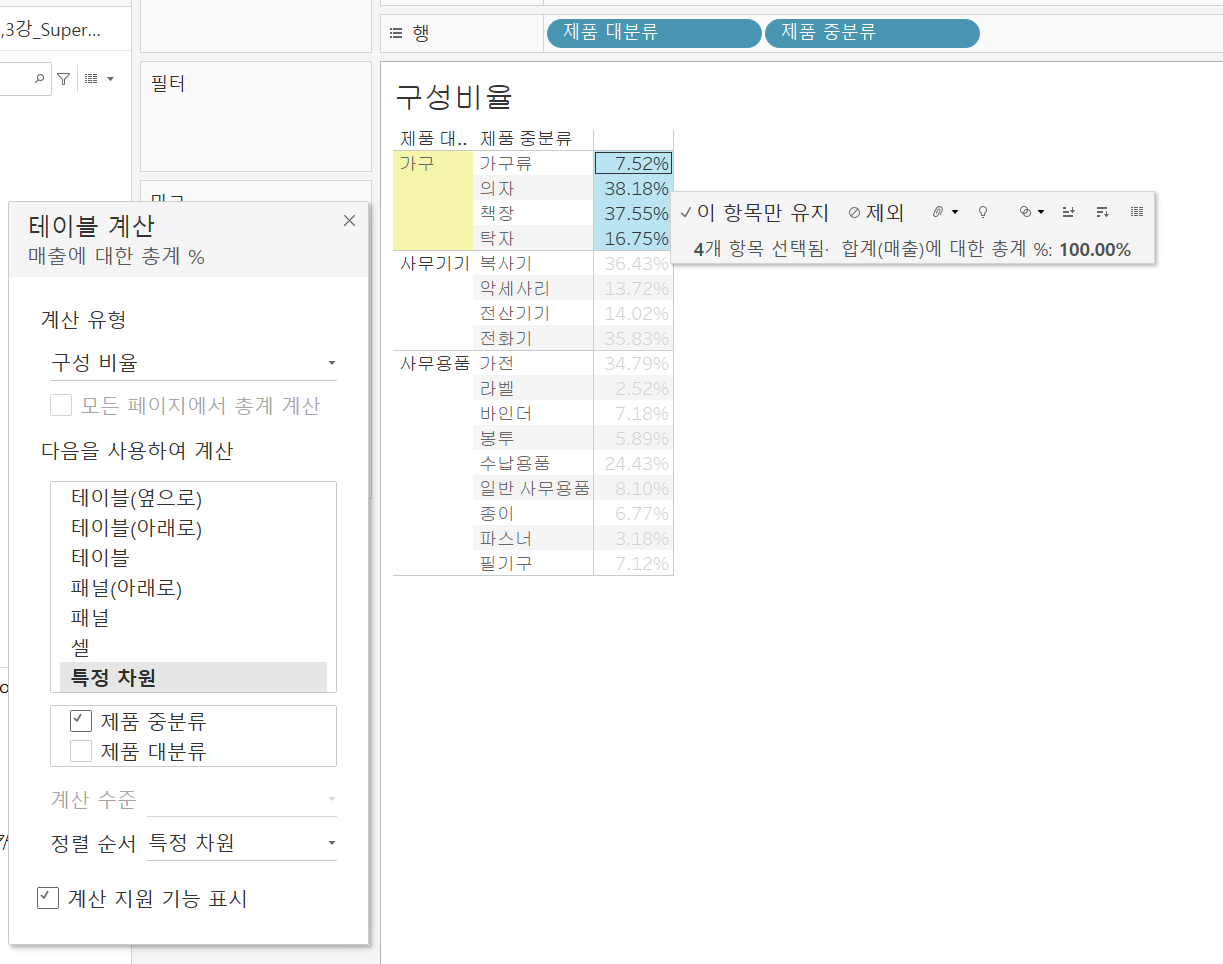
간단히 구성 비율만 설정하면 모든 값의 비율을 더하면 100%가 나오게 된다.
하나의 대분류에 대해 100% 즉, 모든 매출에 대한 비율이 300%가 나오게끔 설정을 할 수도 있다.
[다음을 사용하여 계산]을 눌러 편집할 수 있지만 [테이블 계산]에서 편집하면 각 계산되는 값들을 하이라이트로 표시해주어 더 편리하다.
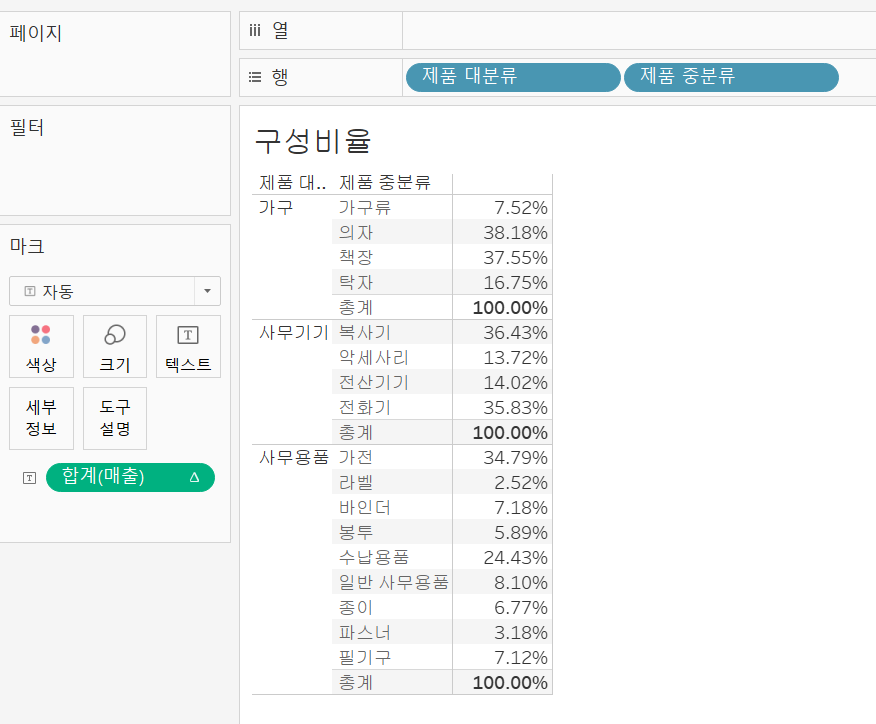
여기에 [분석] - [총계] 까지 소계에 넣어주면 아래와 같이 구성 비율에 대한 편집도 원하는 목적에 맞게 사용할 수 있다.
비율 차이 & 전년 대비 성장률
측정값들 차이의 퍼센트 차이 및 성장률을 의미
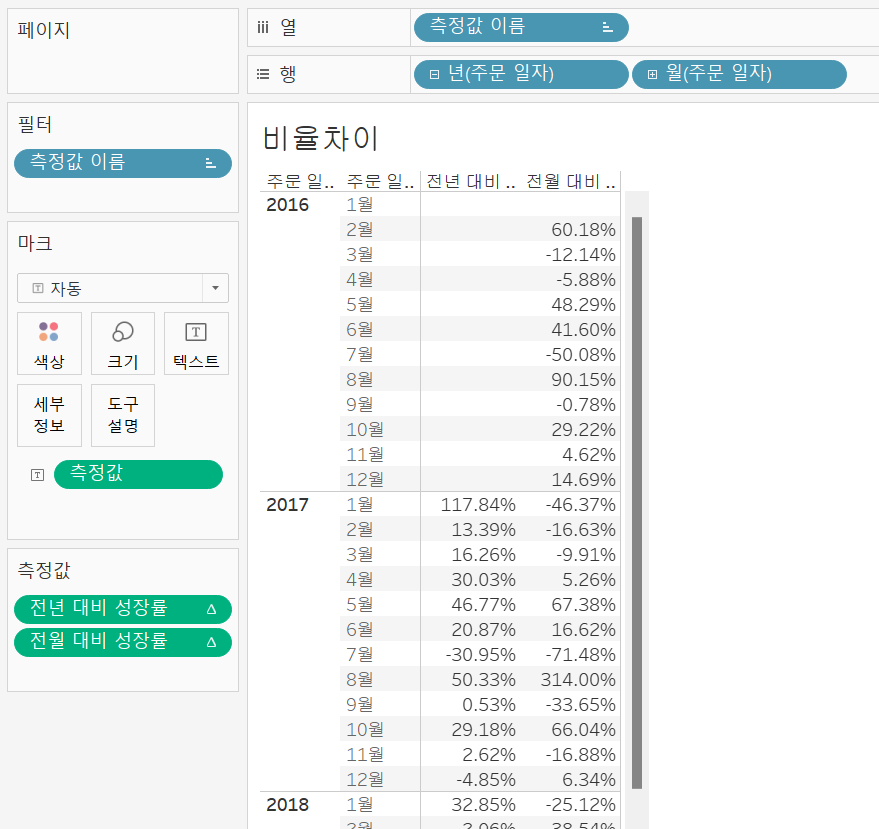
전월 대비 성장률은 '비율 차이'를 설정해서 구한 것이고
전년 대비 성장률은 '전년 대비 성장률'을 통해 구한 필드이다.
실무에서는 '비율 차이'를 더 많이 사용하는데
전년 대비 성장률은 날짜 데이터가 무조건 있어야 하며 전년도의 데이터가 없다면 값을 아예 안 구해주는 반면, '비율 차이'는 계산되는 기준을 자유롭게 설정할 수 있어 구할 수 있는 범위가 넓기 때문이다.
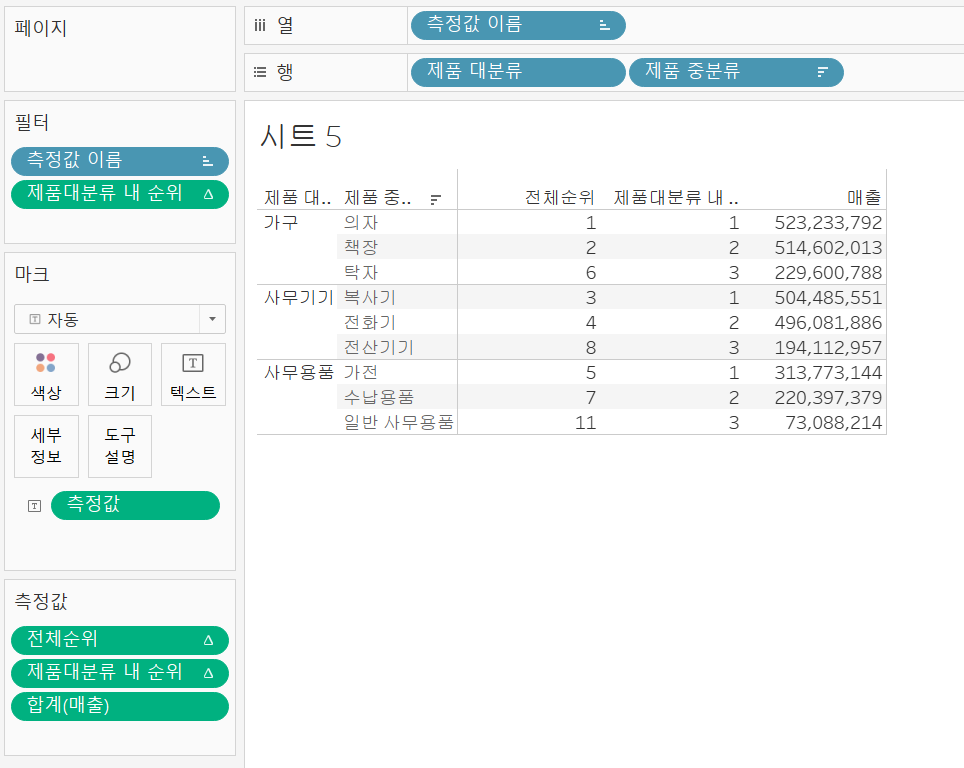
순위
위와 같이 제품 대분류 내 순위 1위~3위까지의 제품 중분류에 대한 전체 순위와 대분류 내 순위, 매출값 테이블을 만들어보자.
전체 순위는 매출 필드를 클릭하여 순위로 설정해주면 되고
제품 대분류 내 순위는 매출 필드를 하나 더 추가하여 순위, [테이블 계산] - [특정차원] - 제품 중분류만 체크 하여 만들 수 있다.
[💡필드명 변경하는 방법]
이렇게 만들어진 필드는 이름을 잘 알 수 없다. 이를 Crtl로 잡고 측정값에서 데이터 쪽으로 드래그 앤 드롭하면 필드가 새로 생기는데 이곳에서 필드명을 변경할 수 있다.
필터에 제품 대분류 내 순위를 넣어주고 범위를 1 ~ 3으로 설정하면 위와 같은 시트를 만들 수 있다.
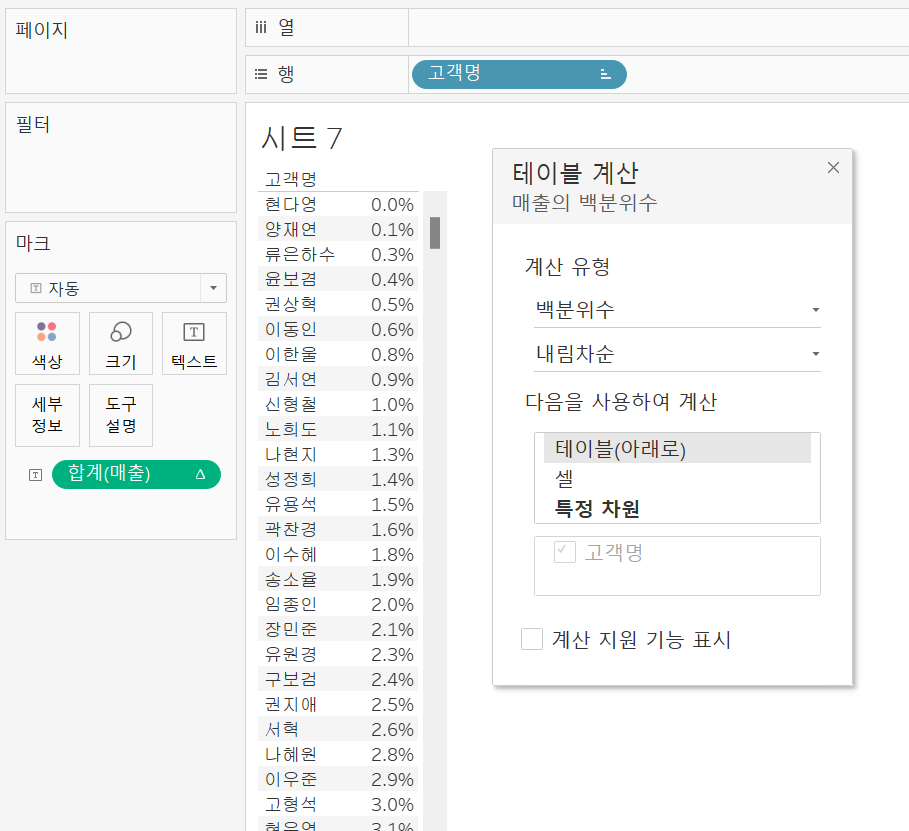
백분위수
매출을 내림차순 정렬된 채로 백분위수를 클릭하게 되면
매출이 가장 큰 현다영 고객이 100%, 매출이 가장 적은 고객이 0%로 표시된다.
실제로는 '상위 ~%'와 같이 큰 값을 0%로 시작하는 경우가 많으므로 [테이블 계산] - 내림차순 설정을 해준다면 원하는 값으로 변경되는 것을 볼 수 있다.
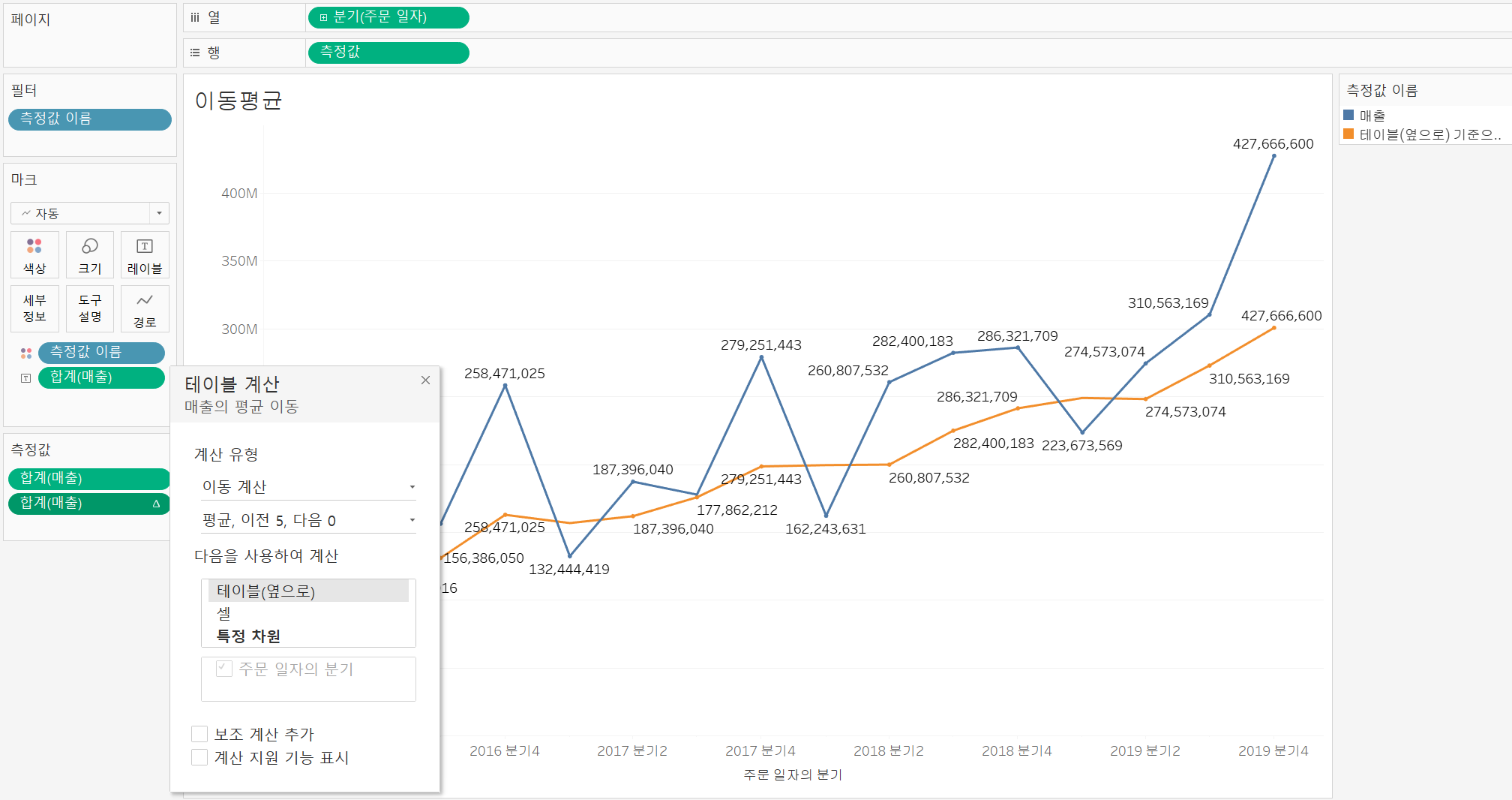
이동평균
평균을 구하는 기간을 설정하고 그 기간의 수를 나눠주는 것으로 주식시장과 같이 5일, 20일과 같은 단기 트렌드 또는 60일, 120일과 같은 중장기 트렌드를 볼 때 유용하다.
이동평균 선을 통해 성과가 좋았는지를 확인할 수 있다.
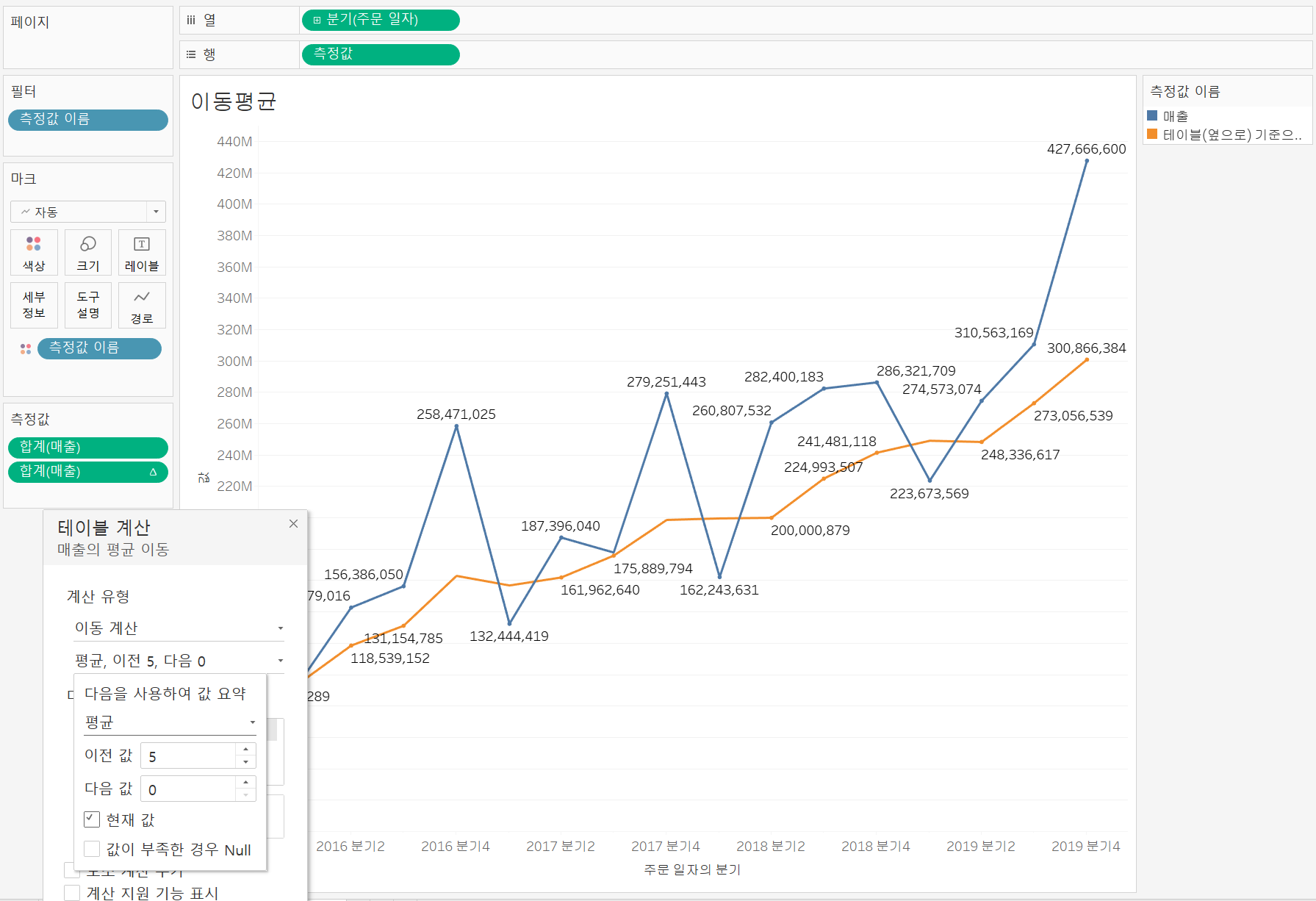
이동평균을 선택하고 [테이블 계산]에서 기간을 설정해줄 수 있는데 '평균, 이전 5, 다음 0'의 의미는 아래와 같다.
2019년 4분기의 300,866,384는 2018년 3분기/4분기, 2019년의 1분기/2분기/3분기/4분기의 합계 ÷ 6
YTD 총계
YTD는 해당 년도 시작일부터 현재일을 의미하는 것으로 YTD 총계는 해당 기간으로부터의 합계이다.
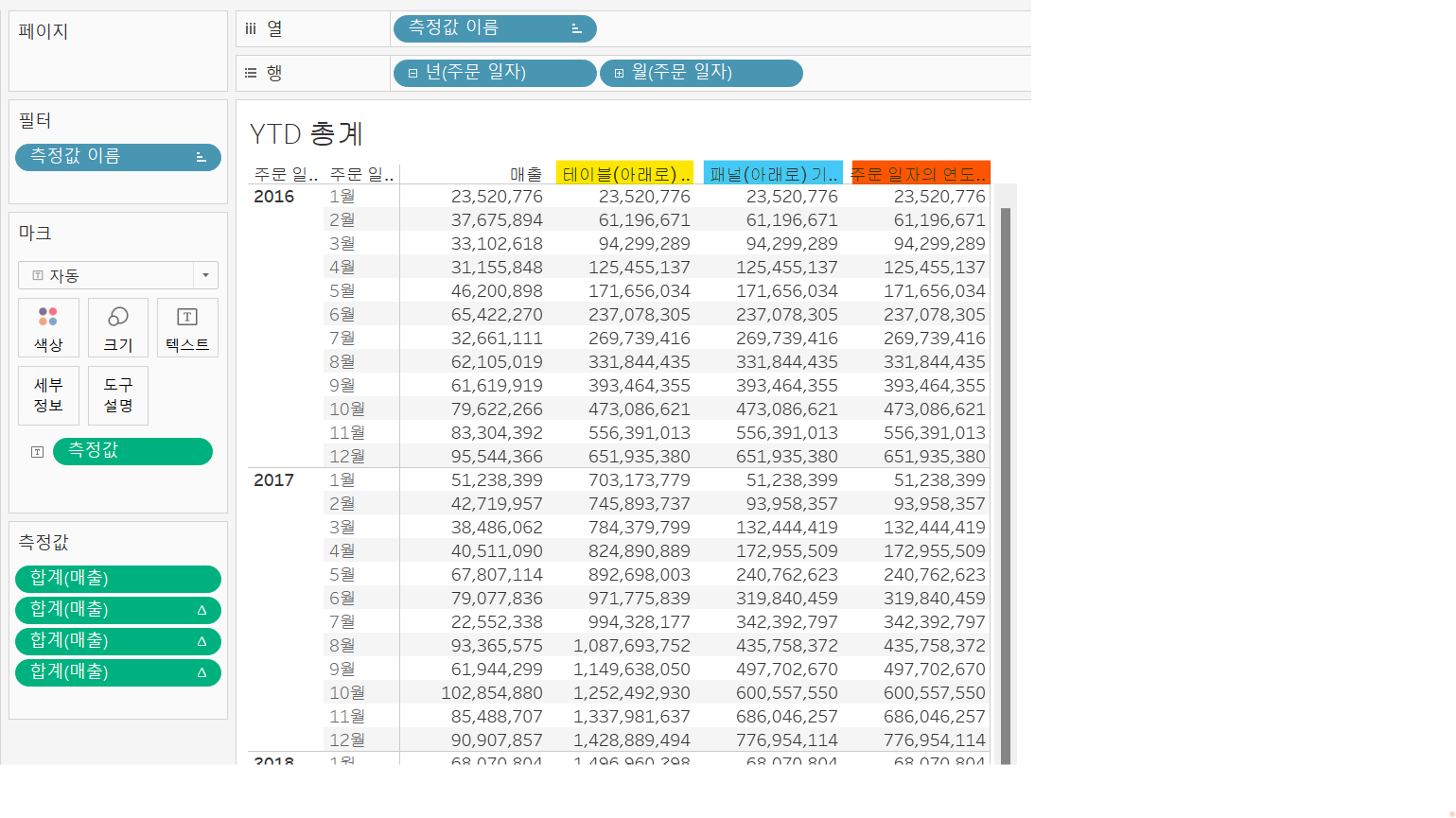
주황색이 YTD 총계로 설정하여 계산된 값이다. 1년을 기준으로 합계가 계산되는 것을 볼 수 있다.
앞서 보던 '누계'와 비슷한 방식인데, '누계'만 설정한 것(= 노란색)은 년도와 상관없이 계속 누적되는 것을 볼 수 있고, '패널(아래로)'설정까지 한 '누계'(= 파란색)은 YTD 총계와 동일한 값을 나타내고 있음을 알 수 있다.
통합 성장률(= 연평균 성장률)
태블로에서는 통합 성장률로 표기되고 있지만, 의미상 연평균 성장률이 더 옳은 것 같다.
- 연평균 성장률(CAGR) = (최종연도값/최초연도값)^(1/연도간격)-1
: 여러 해 동안의 성장률을 평균으로 환산한 것으로, 매년의 성장률을 산술평균이 아닌 기하평균으로 환산.
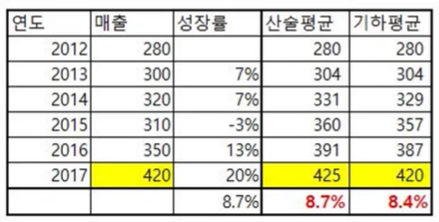
산술 평균으로 계산할 시, 왜곡이 발생하기 때문에 복리 의미를 추가한 기하 평균으로 계산하는 것이 좀 더 현실적이다.
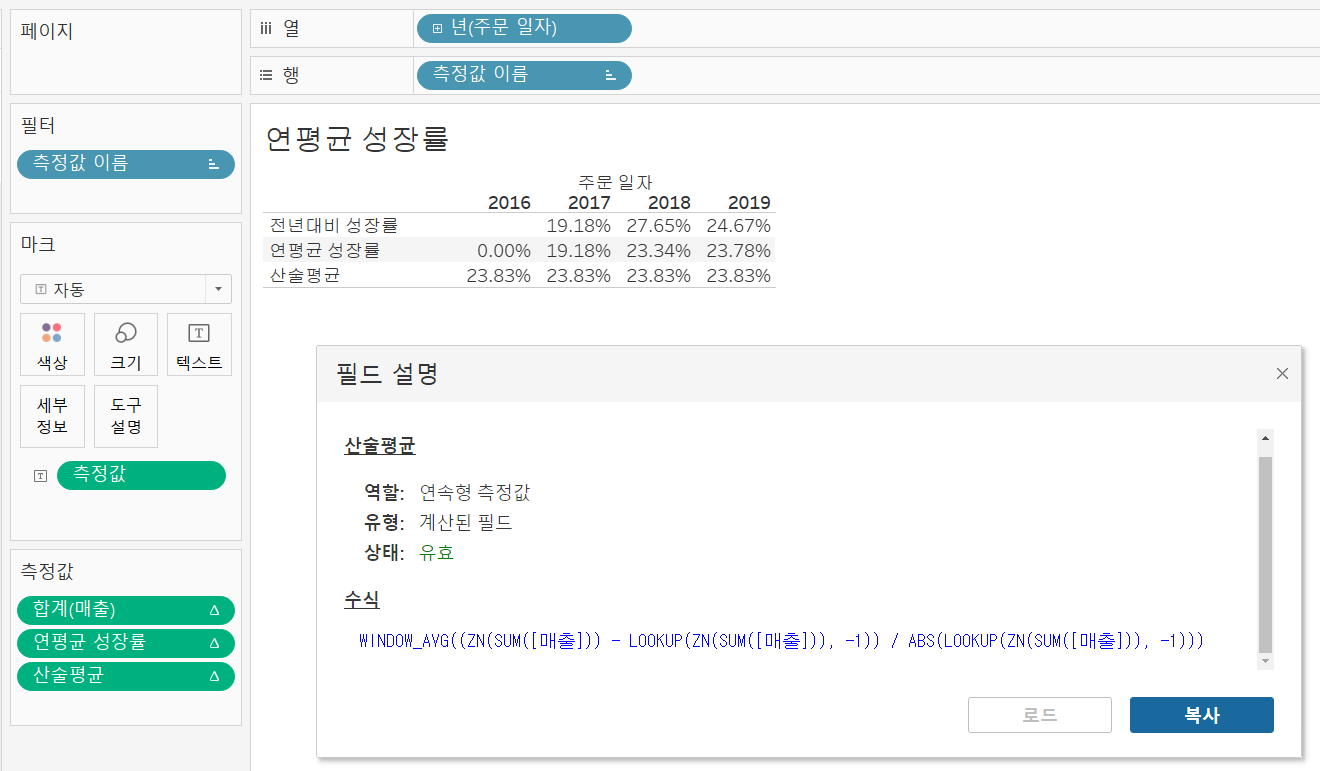
전년 대비 성장률과 연평균 성장률을 넣어준 후, 전년 대비 성장률을 이용한 산술 평균을 계산된 필드의 WINDOW_AVG를 통해 계산하면 연평균 성장률과 다르게 계산된 것을 볼 수 있다.
계산된 필드
데이터 원본에 존재하는 필드를 활용해 새로운 필드를 만드는 것이다.
연산자
함수, 필드, 매개 변수 등을 연결하고 계산을 판단하는 요소
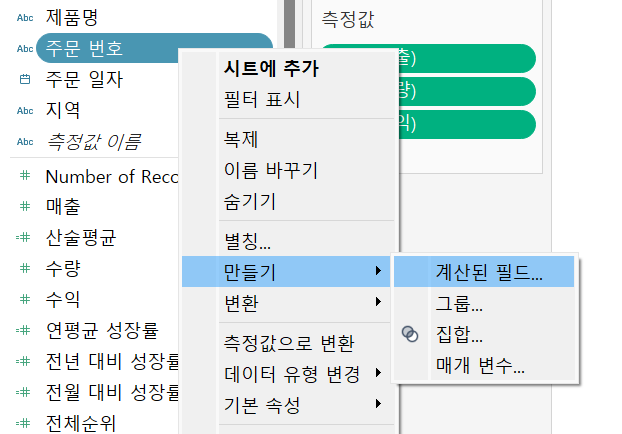
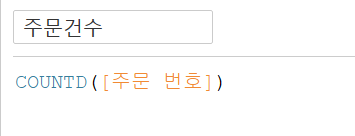
주문번호 필드를 활용해 주문건수 필드를 만들어보자.
 |  |
|---|
고객이 여러 개를 주문한 경우, 다수의 주문 번호가 있기 때문에 중복이 되므로 그냥 count가 아닌 distinct count를 해주어야한다.
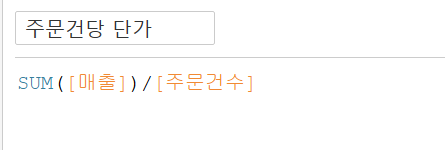
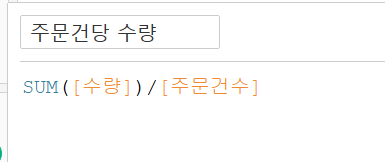
그리고 한 번 주문할 때 발생되는 평균 금액이 얼마인지 확인하기 위해 주문건당 금액필드와 하나의 주문 건수에 얼마나 많이 주문하는지에 대한 주문건당 수량 필드를 만들어보자.
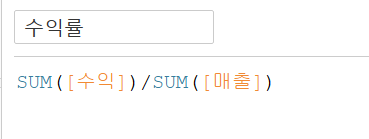
또한, 수익을 금액보다는 '수익률'로 보는 것이 좀 더 직관적이기 때문에 수익률필드를 만들어보았다.
 |  |  |
|---|
이때 주문건수를 SUM하지 않는 이유는 이미 COUNTD가 되어있는 변수이기 때문이다.
주요 KPI를 다 만들었다면, 뷰에 넣어보자.
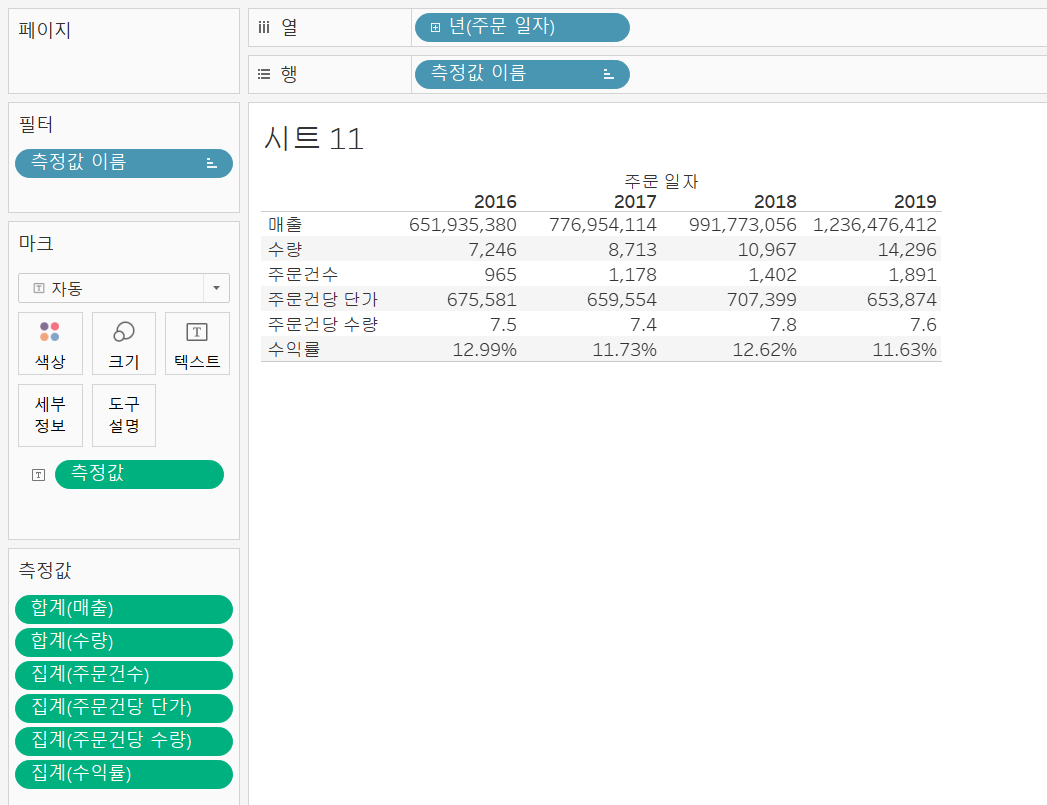
수익률필드의 속성을 백분율로, 주문건당 수량필드의 속성을 숫자(사용자속성) - 소수점 자리수 1로 설정한 후 주문일자를 열 선반에 놓으면 위와 같은 KPI지표를 확인할 수 있다.
매출 필드만 보는 것보단 이렇게 KPI지표를 모두 확인하는 것이 좋은데 그 이유는 점점 매출량은 증가하고 있지만 주문건당 단가와 수량, 수익률은 감소하는 형태를 띄고 있기 때문에 마냥 좋은 상황이 아니다라는 것을 확인할 수 있기 때문이다.
논리함수
함수란, 새로운 계산식을 적용하기 위해 기존 데이터 원본의 필드에 유형 및 역할을 결정하는데 영향을 주는 것을 말함
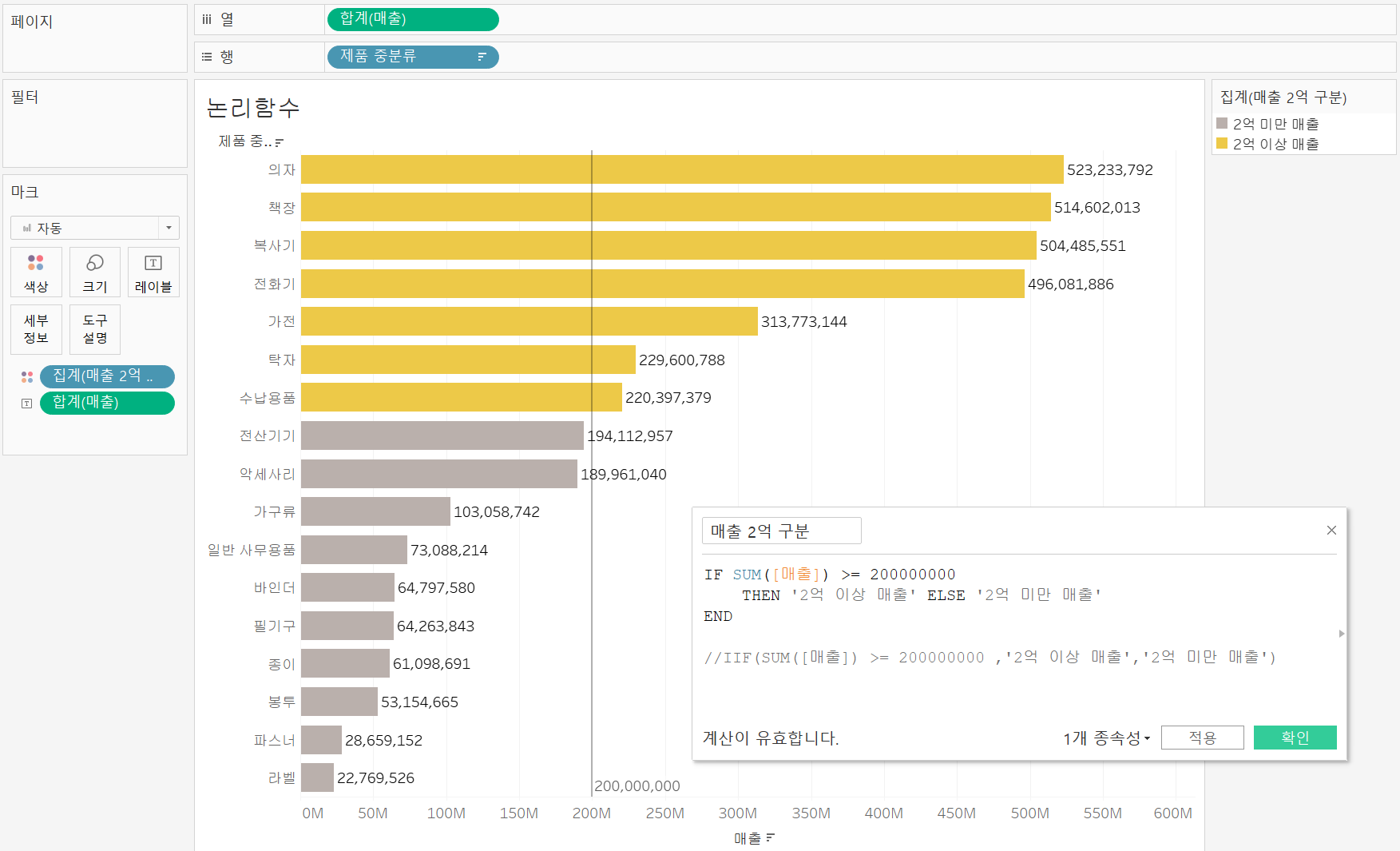
IF 함수를 이용해 2억을 구분하는 차트를 만들고 이를 마크 색상 카드에 넣어주면 위와 같은 차트가 만들어진다.
하지만 차트에서 색상 구분만 할거면 굳이 IF를 사용하지 않고 TRUE/FALSE로만 구분되어도 될 것이다.
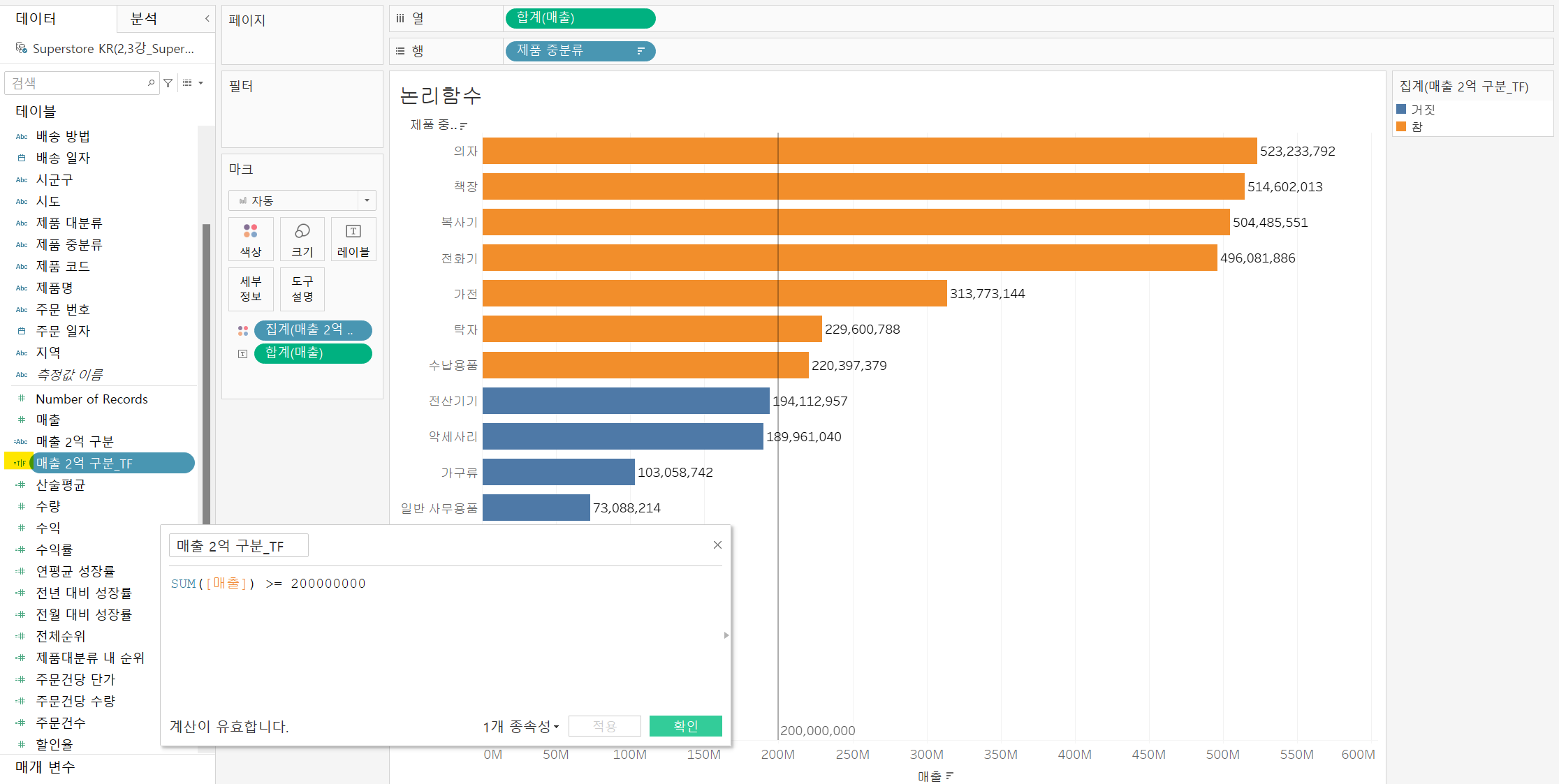
IF와 달리 앞에 T/F로 표시되는 것을 볼 수 있다. 결과물은 동일하지만, 문자열보다는 BOOL 방식이 데이터 처리 속도가 빠르므로 이 방식을 더 자주 사용하도록 하자.
매개변수
상수 값을 동적인 값으로 변경해주는 변수로 차트를 동적으로 만들 수 있다.
범위형, 목록형
📌 범위형
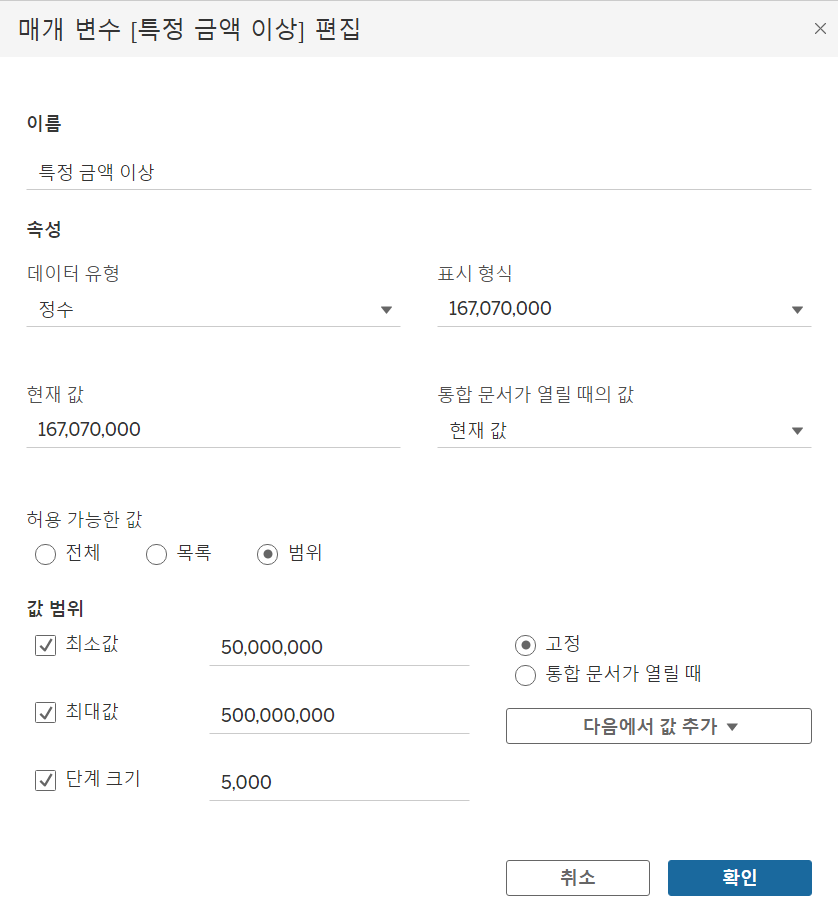 매개변수 만들기 매개변수 만들기 | 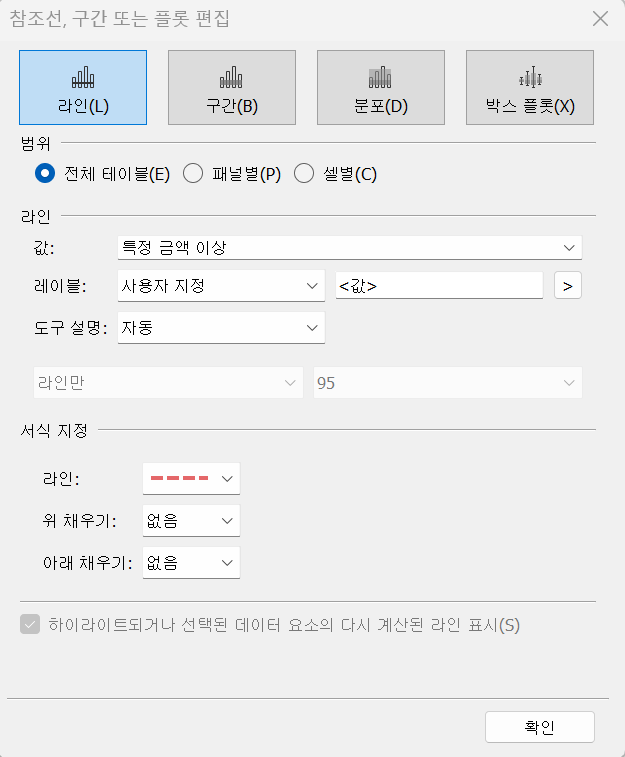 매개변수를 이용한 참조선 만들기 매개변수를 이용한 참조선 만들기 |
|---|
매개변수를 이용하여 참조선을 만든 후
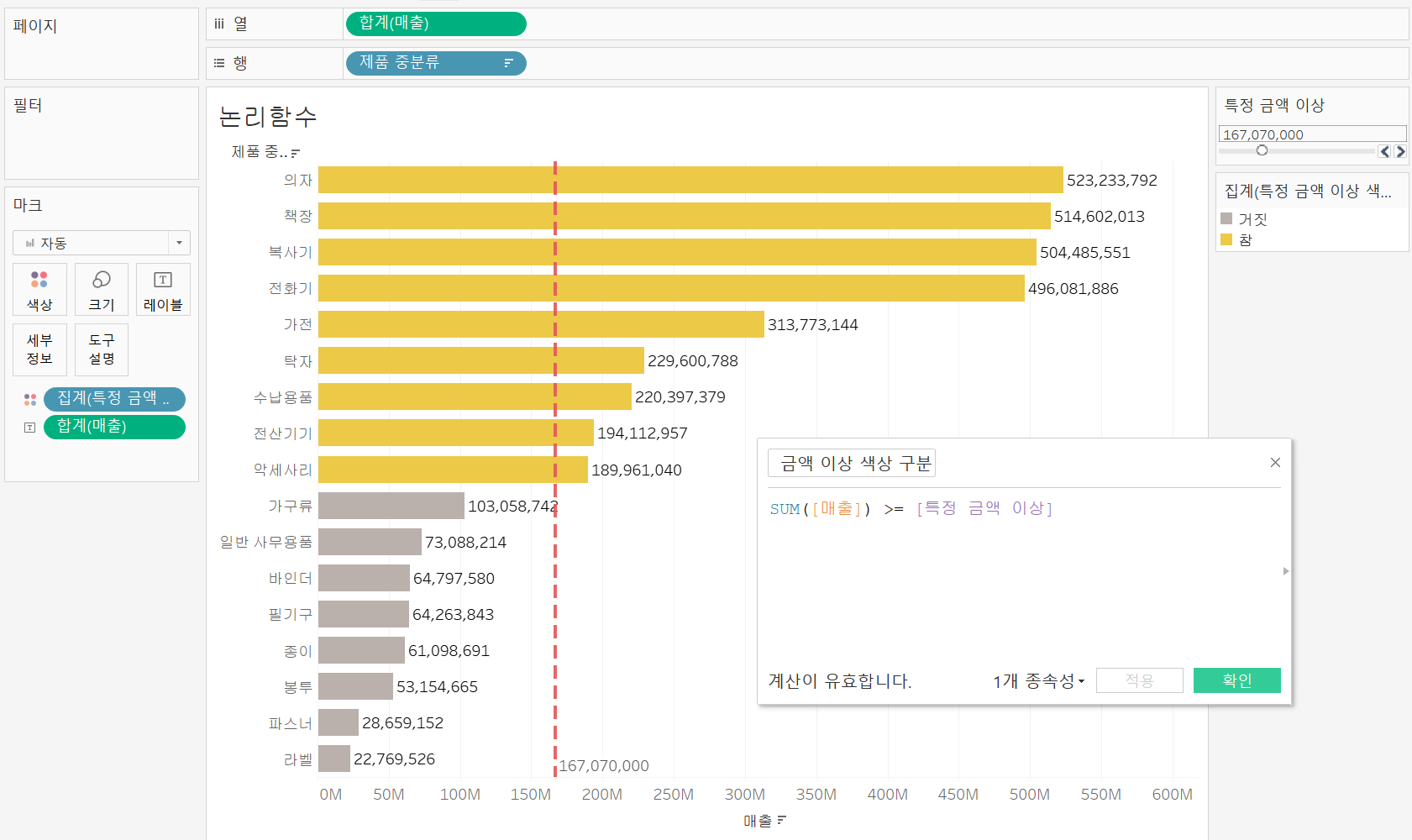
매개변수를 이용한 계산 필드를 만들어 마크 색상 카드에 넣어주면 우측 상단의 특정 금액 이상 매개변수를 조절할 때마다 참조선과 색상이 동적으로 변하는 것을 볼 수 있다.
📌 목록형
이번엔 목록형 매개변수를 만들어 매출 값을 원화와 달러로 볼 수 있는 시트를 만들어보자.
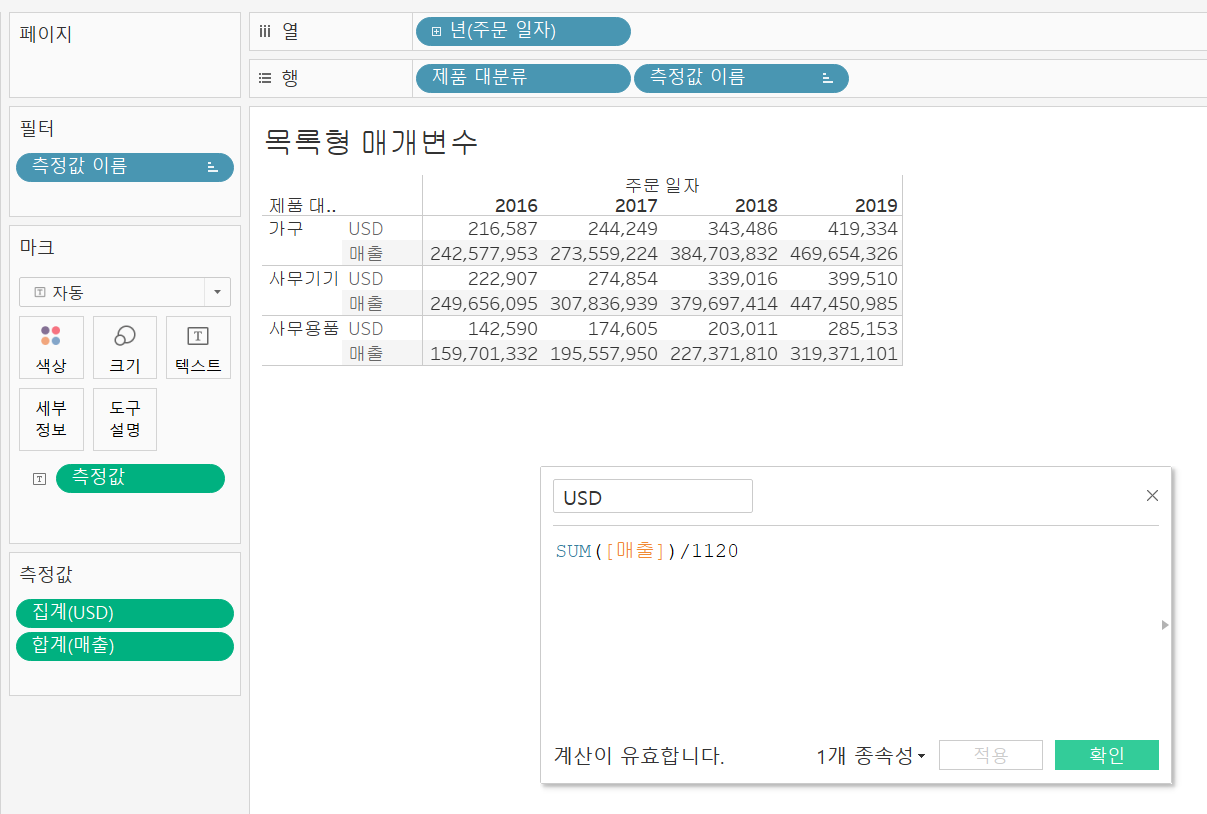
먼저, 기존의 매출 필드는 원화로 표시되어있다. 임의의 환율 1,120을 넣어 만든 계산된 필드를 통해 USD필드를 위와 같이 만들어 넣어주면 환율로 계산된 USD 필드를 볼 수 있다.
하지만, 매번 이렇게 보는 것은 다른 사람이 보기에도 힘드므로 매개변수를 통해 값을 확인할 수 있도록 바꿔보면 아래와 같이 바꿔진다.
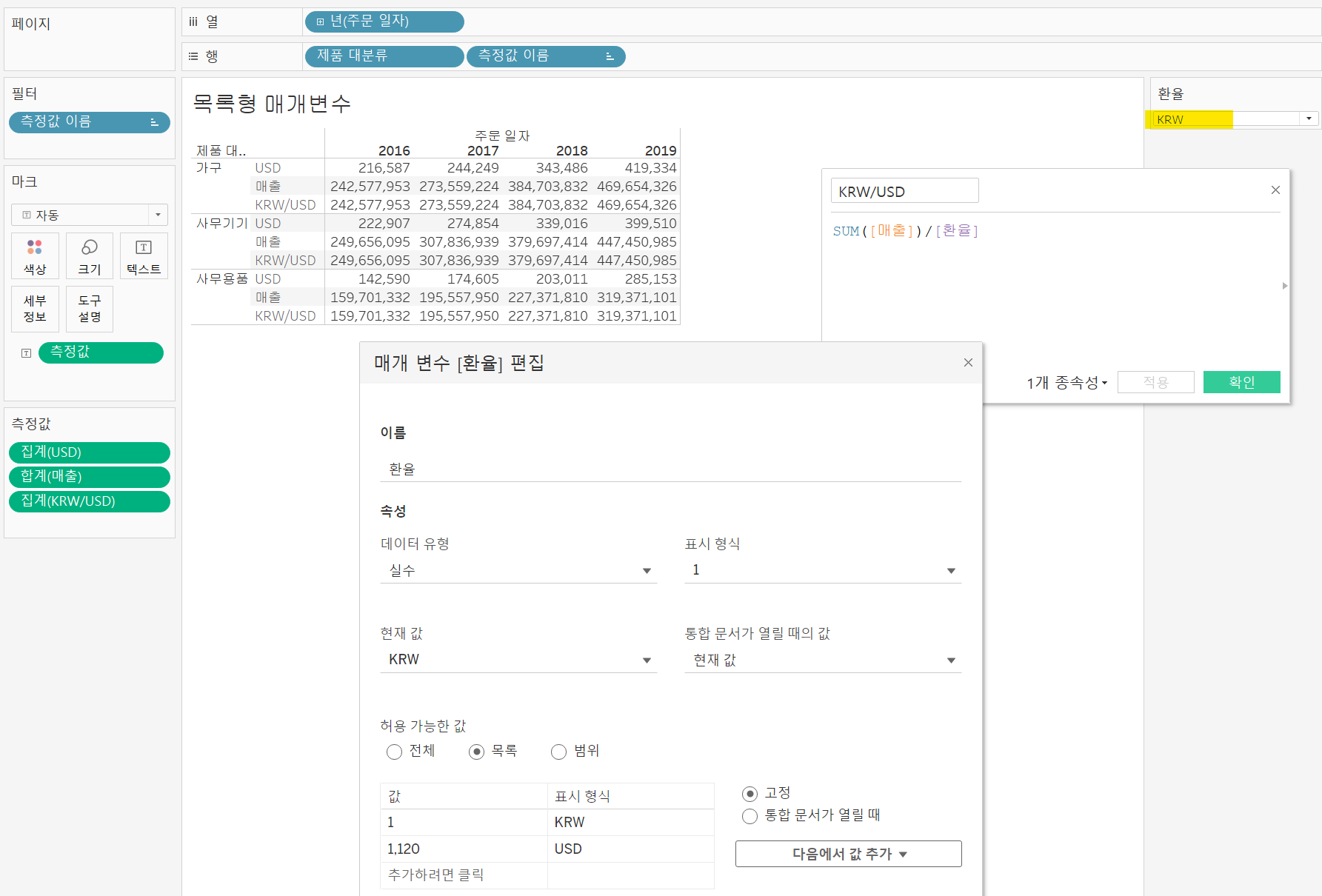 매개변수가 KRW일 때 매개변수가 KRW일 때 | 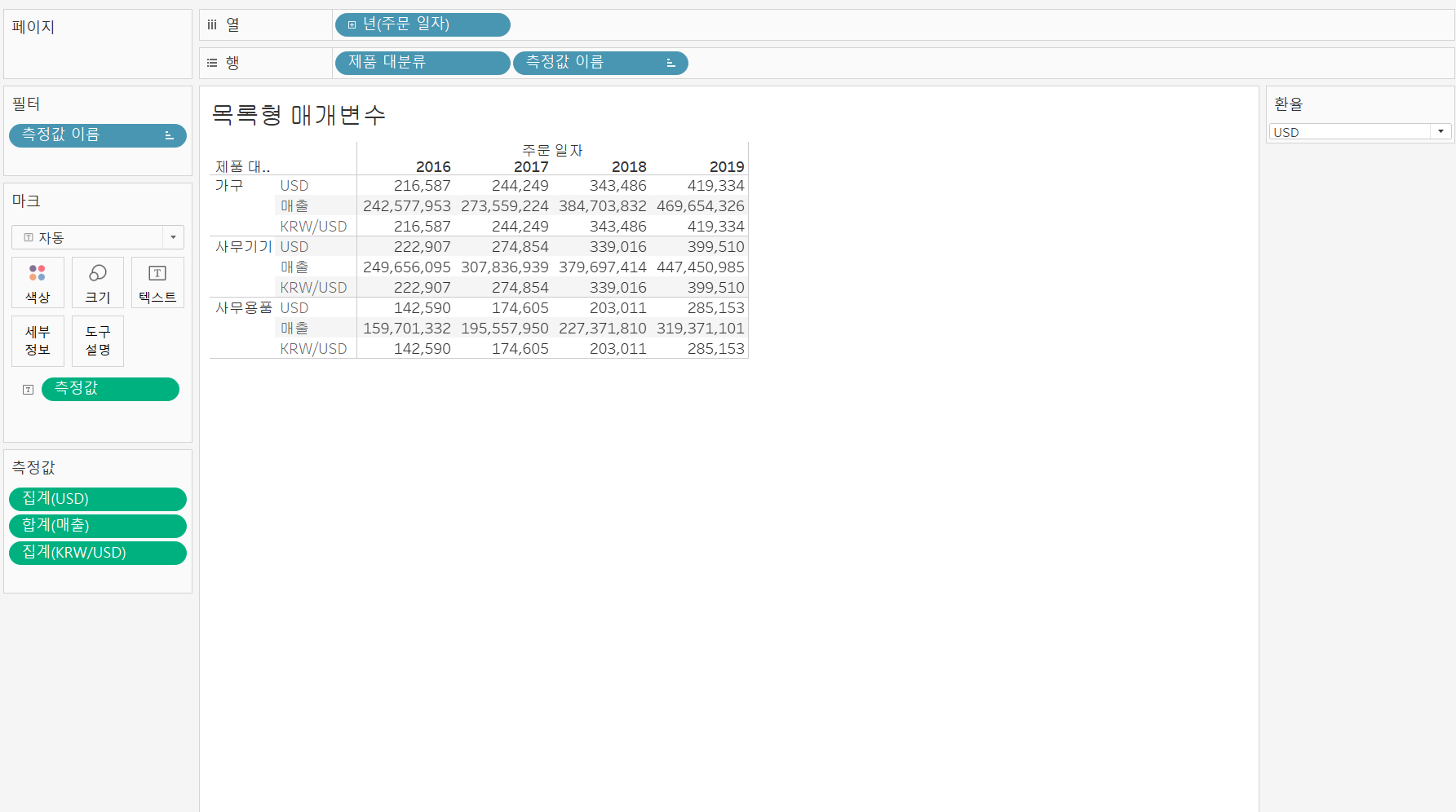 매개변수가 USD일 때 매개변수가 USD일 때 |
|---|
날짜형, 복합 매개 변수
📌 날짜형
월, 분기 단위로 보거나 특정 이벤트 기간만의 성과를 보고자 할 때 많이 사용됨
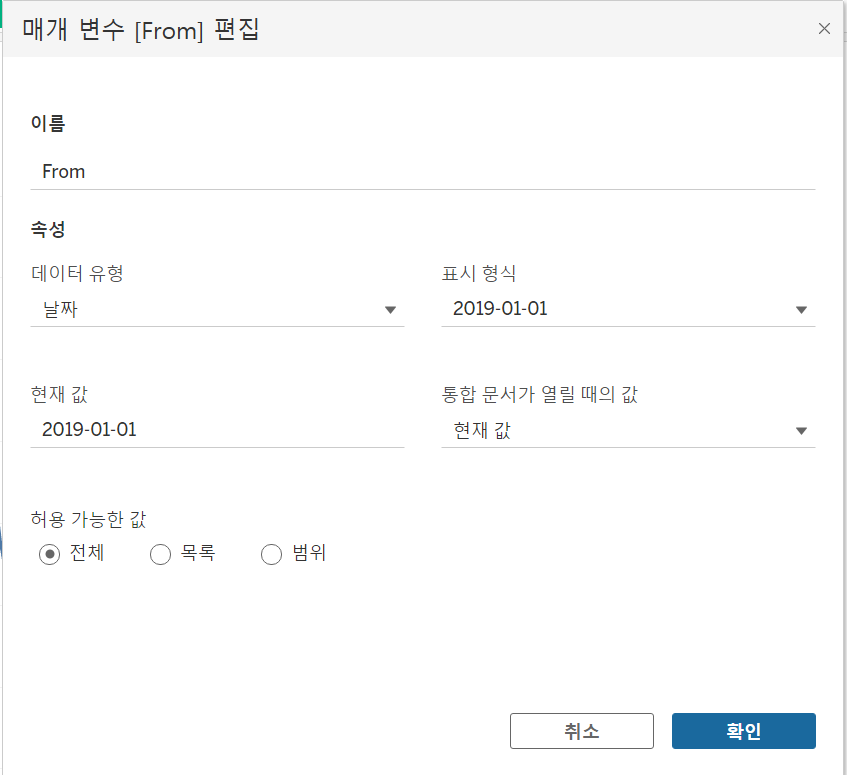 날짜형 매개변수 From, To 만들기 날짜형 매개변수 From, To 만들기 | 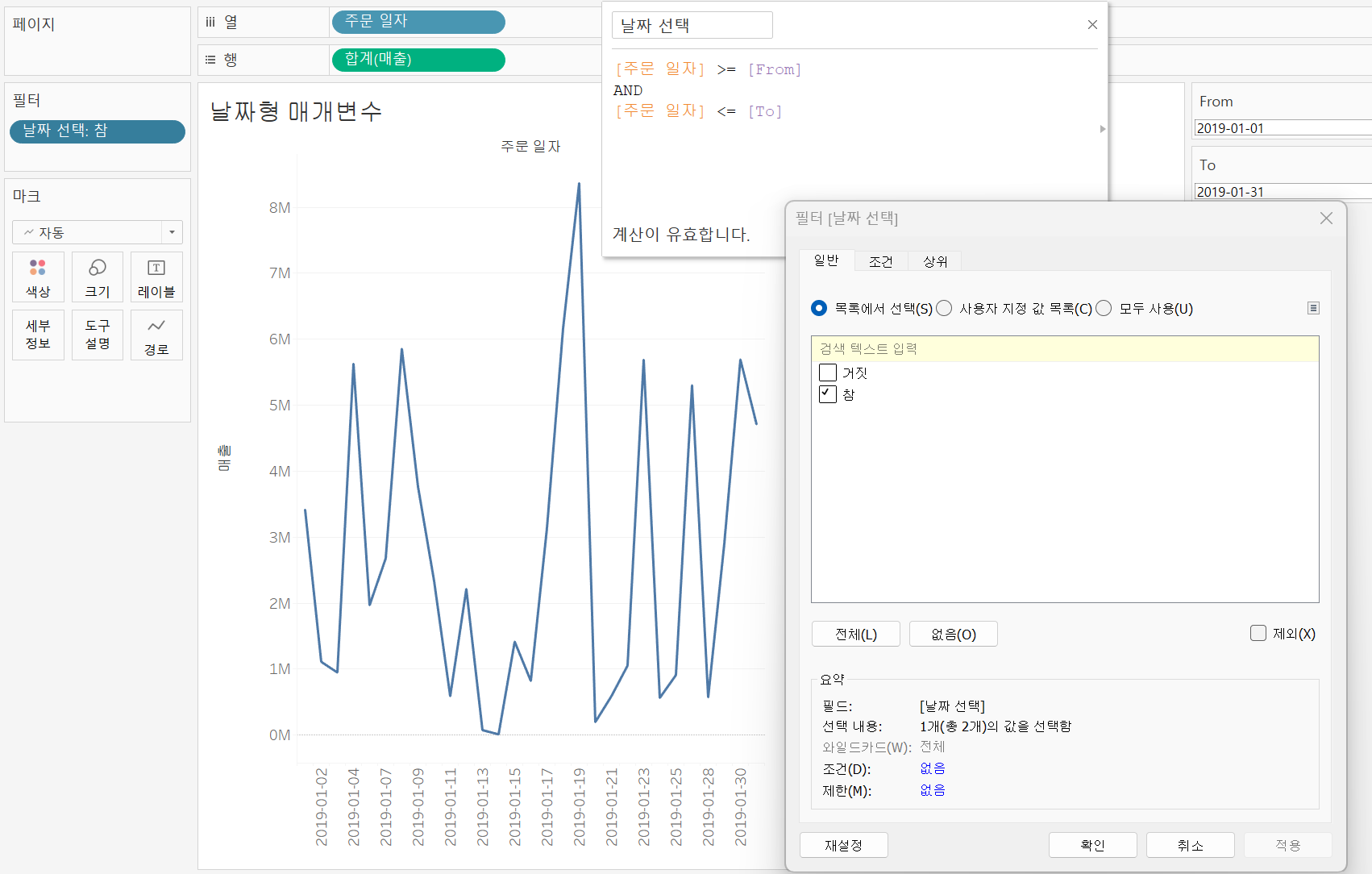 날짜 선택 계산 필드 생성 및 필터 설정 날짜 선택 계산 필드 생성 및 필터 설정 |
|---|
위와 같은 과정으로 날짜형 매개 변수를 만들고 계산 필드를 생성해주면 설정한 날짜에 해당하는 매출을 확인할 수 있다.
📌 복합 매개변수
한 화면에서 다양한 각도의 분석이 필요할 때 많이 사용됨
제품 대분류/중분류의 차원을 변경하고 측정값은 매출, 수량, 수익, 할인율 4가지를 변경할 수 있도록 만들어보자.
먼저 아래와 같이 매개변수를 만들어준다.
 차원 선택 매개변수 생성 차원 선택 매개변수 생성 |  측정값 선택 매개변수 생성 측정값 선택 매개변수 생성 |
|---|
매개변수 생성 후, 매개변수 표시를 누르고 이들을 활용한 계산된 필드를 만들어준다.
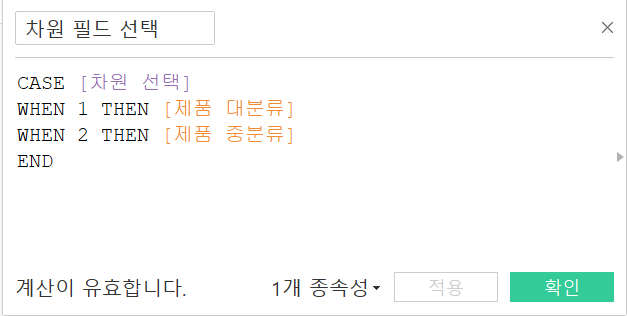 차원 필드 선택 계산 필드 차원 필드 선택 계산 필드 | 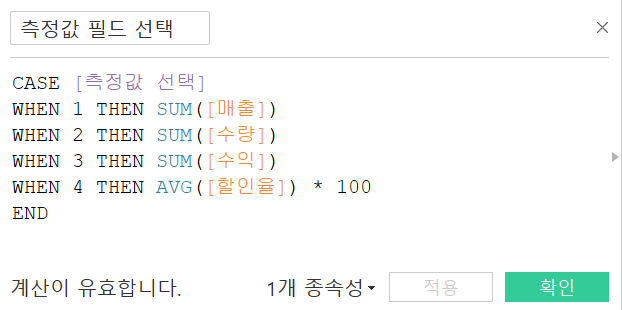 측정값 필드 선택 계산 필드 측정값 필드 선택 계산 필드 | 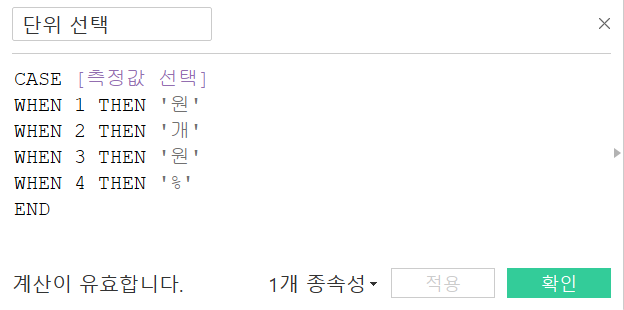 단위 선택 계산 필드 단위 선택 계산 필드 |
|---|
각 계산된 필드를 열 선반과 행 선반, 마크 레이블에 넣어주고 시트 이름 또한 매개변수를 이용하여 설정해주면 아래와 같이 동적으로 변하는 시트를 만들 수 있다.
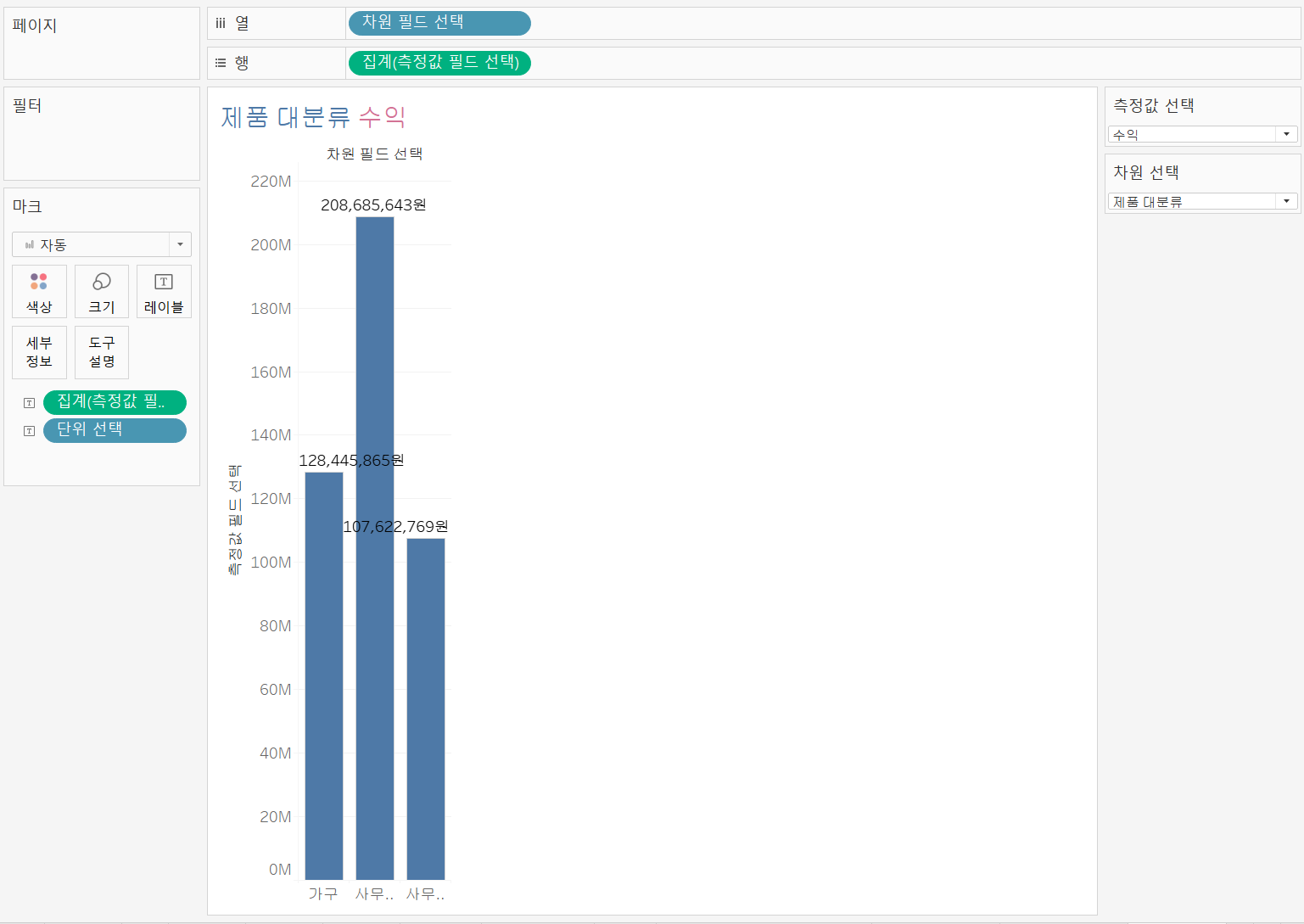 제품 대분류/수익 제품 대분류/수익 | 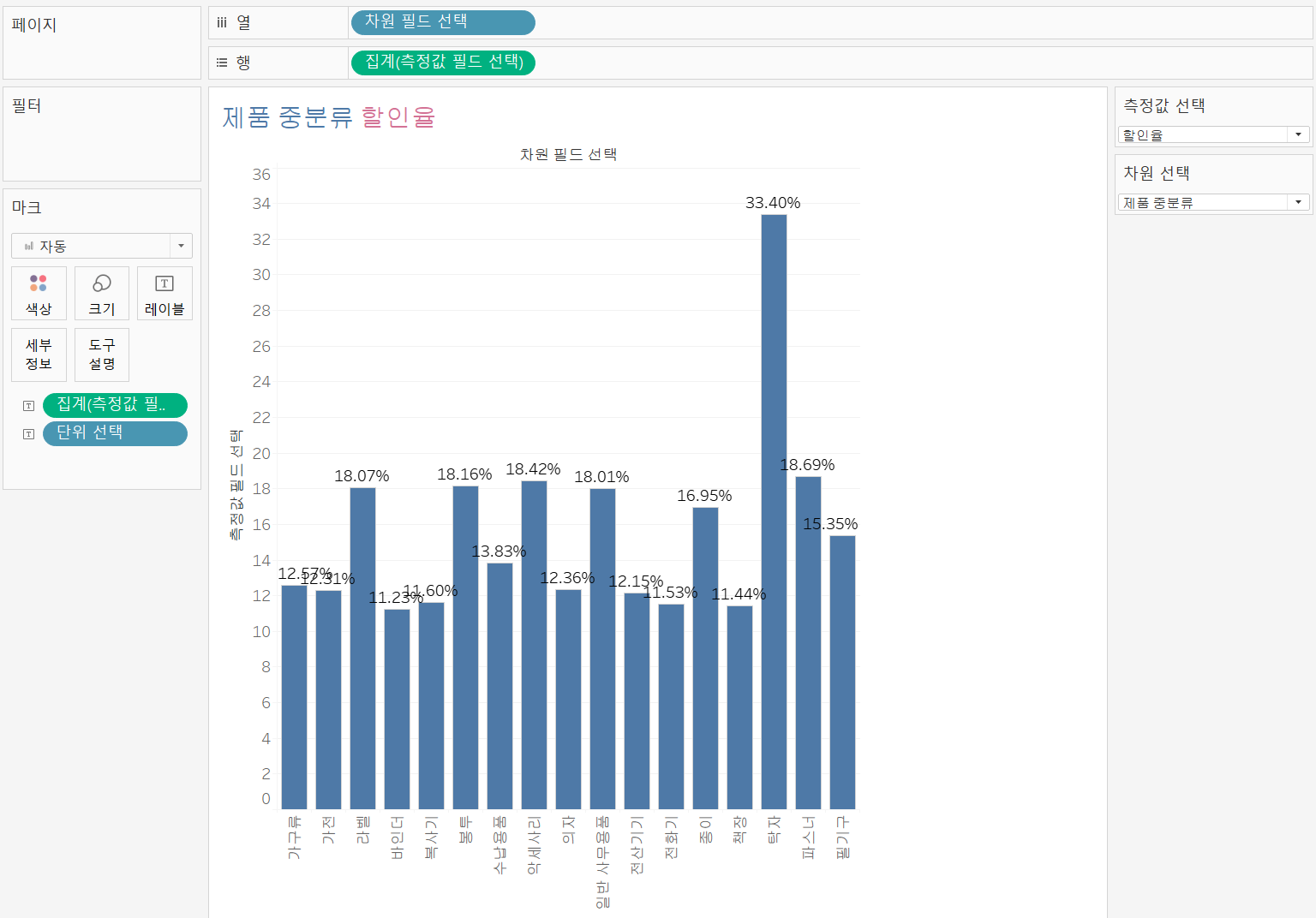 제품 중분류/할인율 제품 중분류/할인율 |
|---|
실무에서 논리 함수, 집계 함수 및 문자열 함수, 날짜 함수, 테이블 계산 함수 등을 많이 사용한다.
논리 함수와 집계 함수는 지금까지 많이 연습해 보았으니, 문자열 함수, 날짜 함수, 테이블 계산 함수에 대해 살펴보자.
PRIMARY 함수
테이블 계산 함수로 함수 내에 다른 함수가 포함된 함수로 대부분 [퀵 테이블 계산]으로 계산 가능한 함수들이다.
대표적으로는 RUNNING, TOTAL, LOOKUP, WINDOW가 있다.
RUNNING - TOTAL
-
RUNNING_SUM: 첫 번째 행에서 현재 행까지 주어진 식의 누계 합계를 반환 (퀵 테이블 계산의 누계와 같은 값을 반환함)
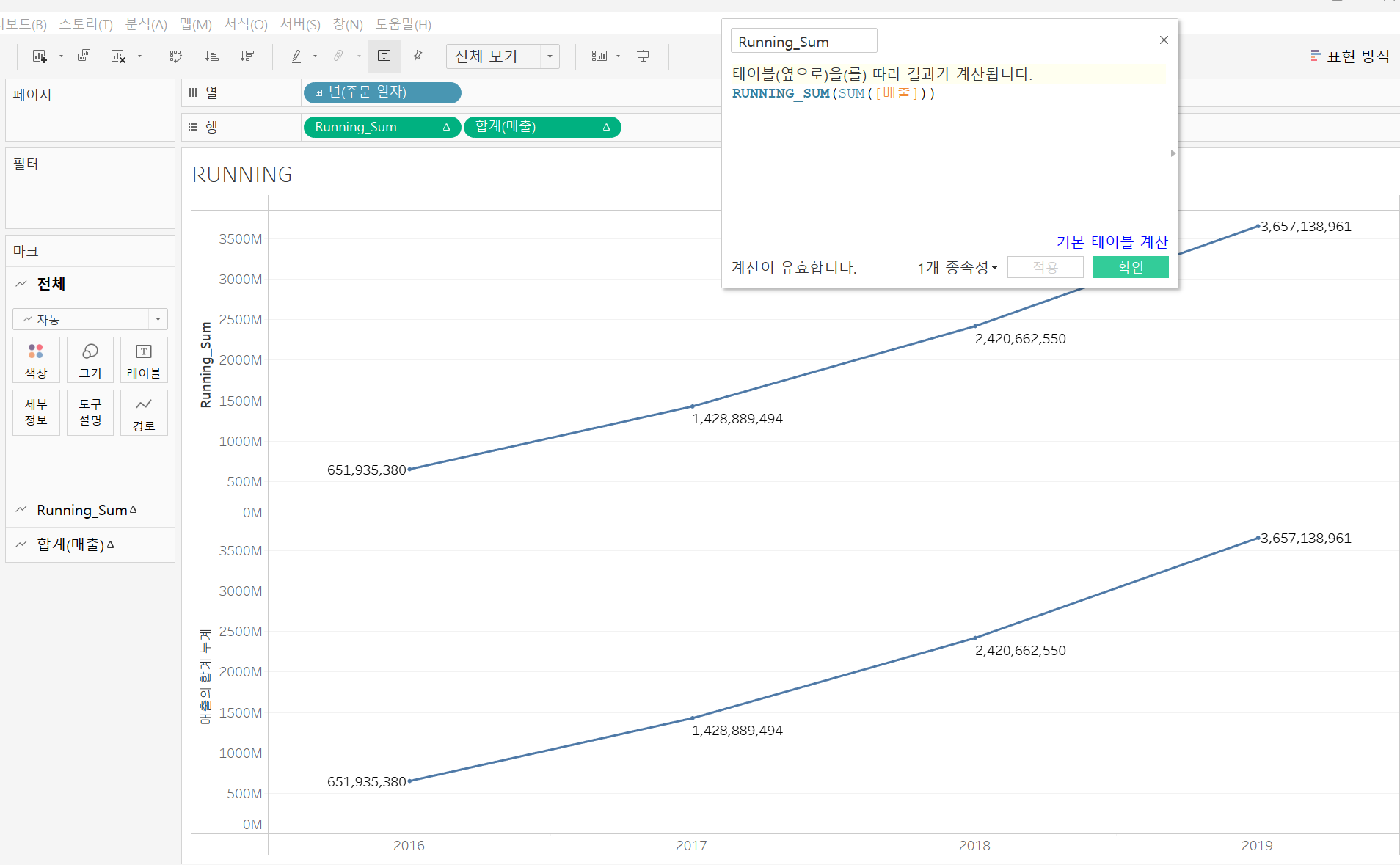
RUNNING_SUM함수로 계산된 필드와 퀵 테이블의 누계를 설정해서 만든 필드의 값이 같은 것을 볼 수 있음 -
RUNNING_AVG: 첫 번째 행에서 현재 행까지 주어진 식의 누계 평균을 반환🤔
RUNNING_AVGvs 이동평균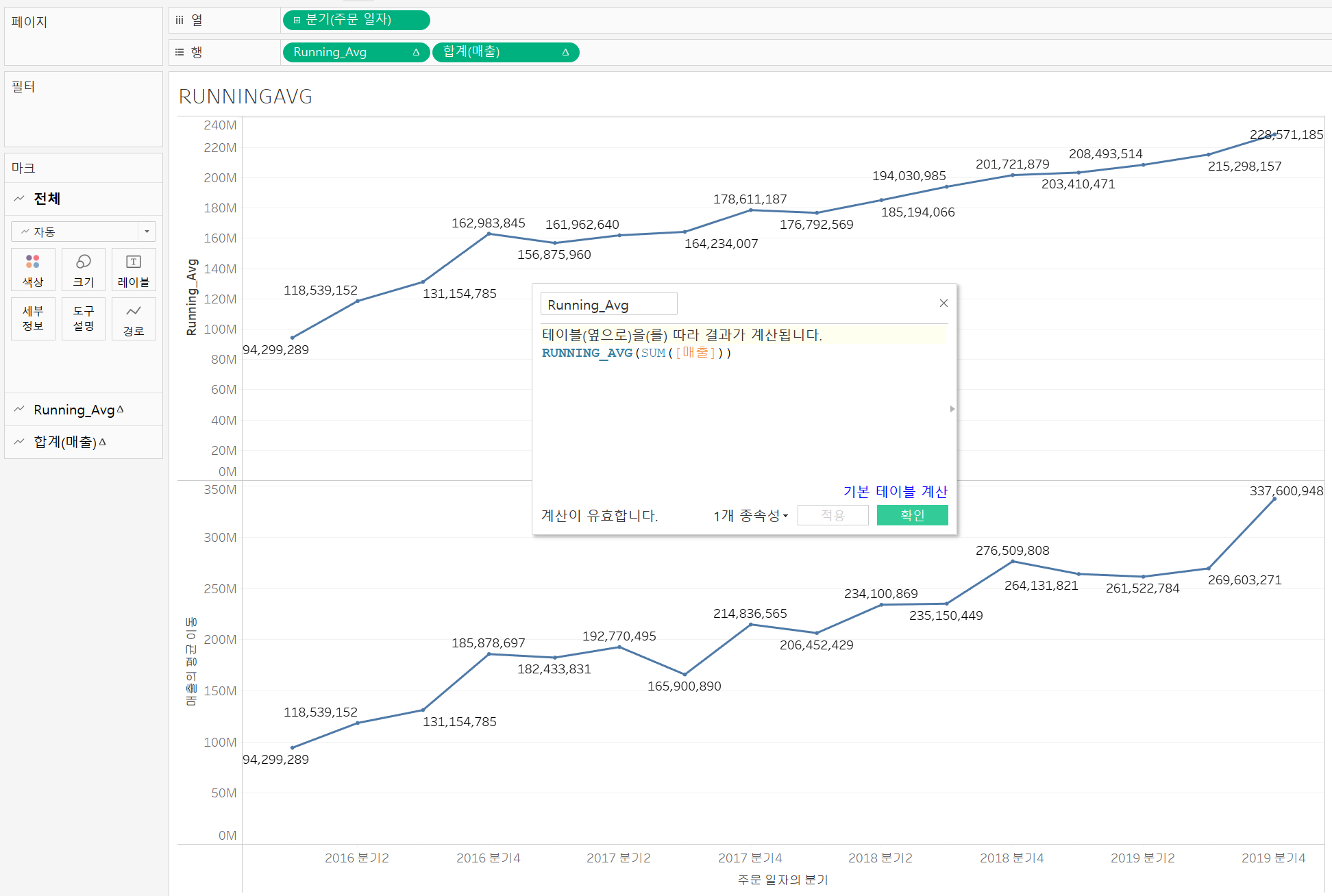
RUNNING_AVG는 특정 기간을 포함한 이전 기간의 모든매출에 대한 평균을 의미하며,이동평균은 특정 기간으로 부터 사용자가 지정한 이전 기간의
매출의 평균이다.
-
TOTAL: 총 합계를 반환🤔
TOTALvsSUM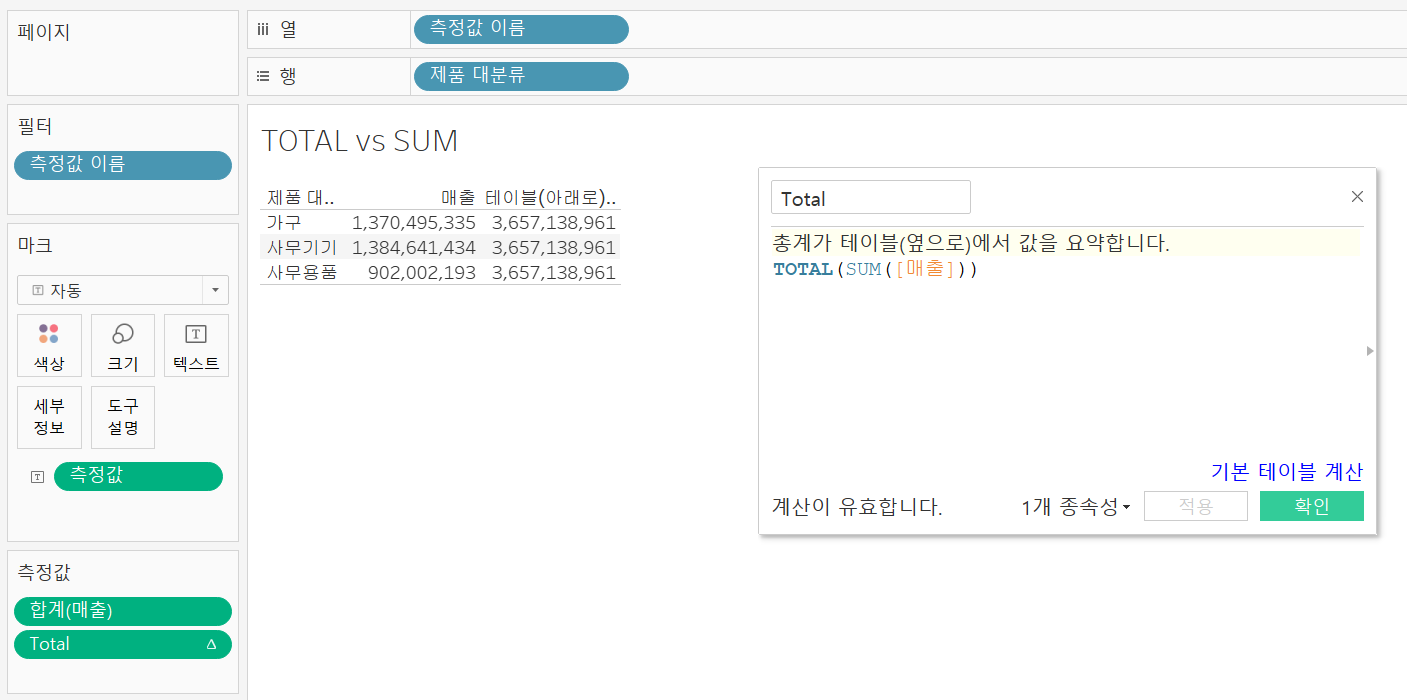
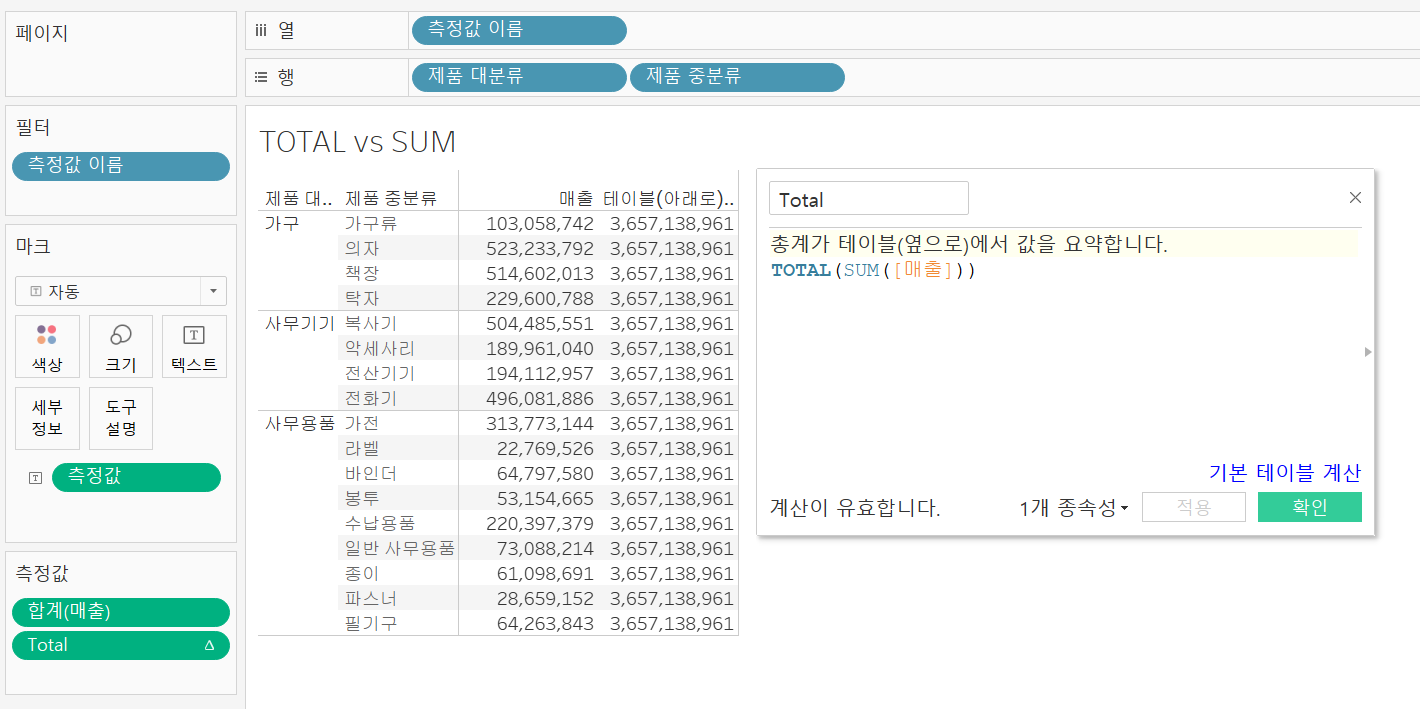
SUM은 행 선반의 값에 따라 합계를 새로 계산해주지만TOTAL은 무조건 전체 합계를 반환하므로 매출 비중을 표현하고자 할 때 많이 사용됨( = 퀵 테이블 계산의 비중과 동일)
LOOKUP/WINDOW
-
LOOKUP: 현재 행을 기준으로 오프셋 만큼 떨어진 행에 대해 주어진 식의 값을 반환한다.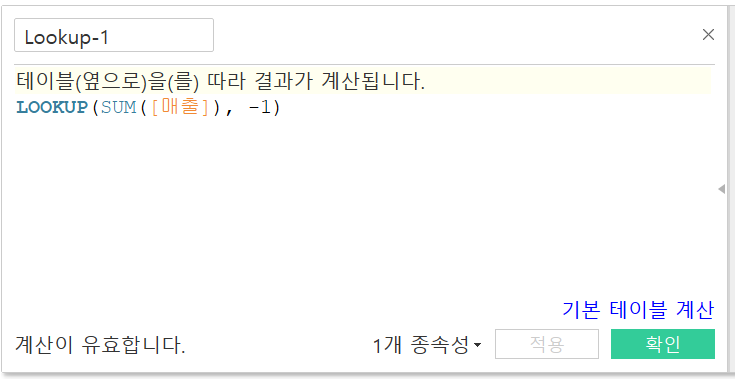
LOOKUP함수 예시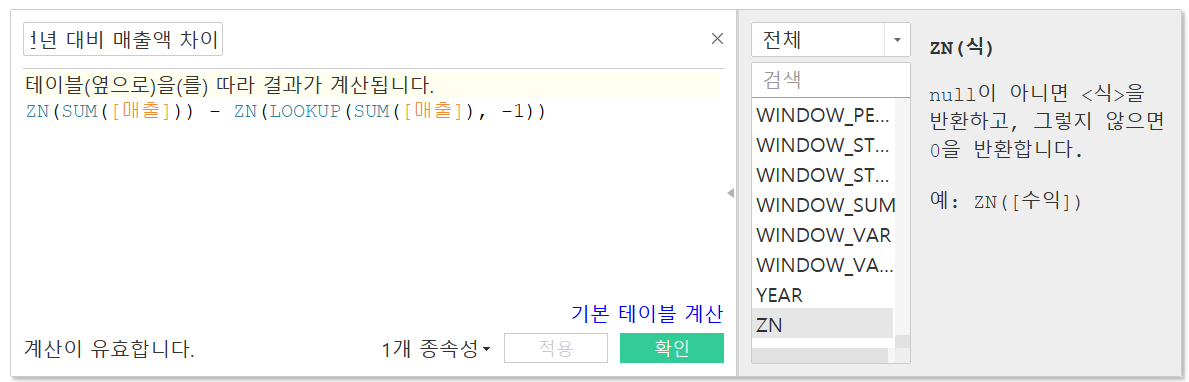 전년 대비 매출액 차이
전년 대비 매출액 차이 퀵 테이블 계산 - 차이
퀵 테이블 계산 - 차이위와 같이 계산된 필드를 만들고 측정값에 넣어주면 아래와 같은 시트가 생성된다.
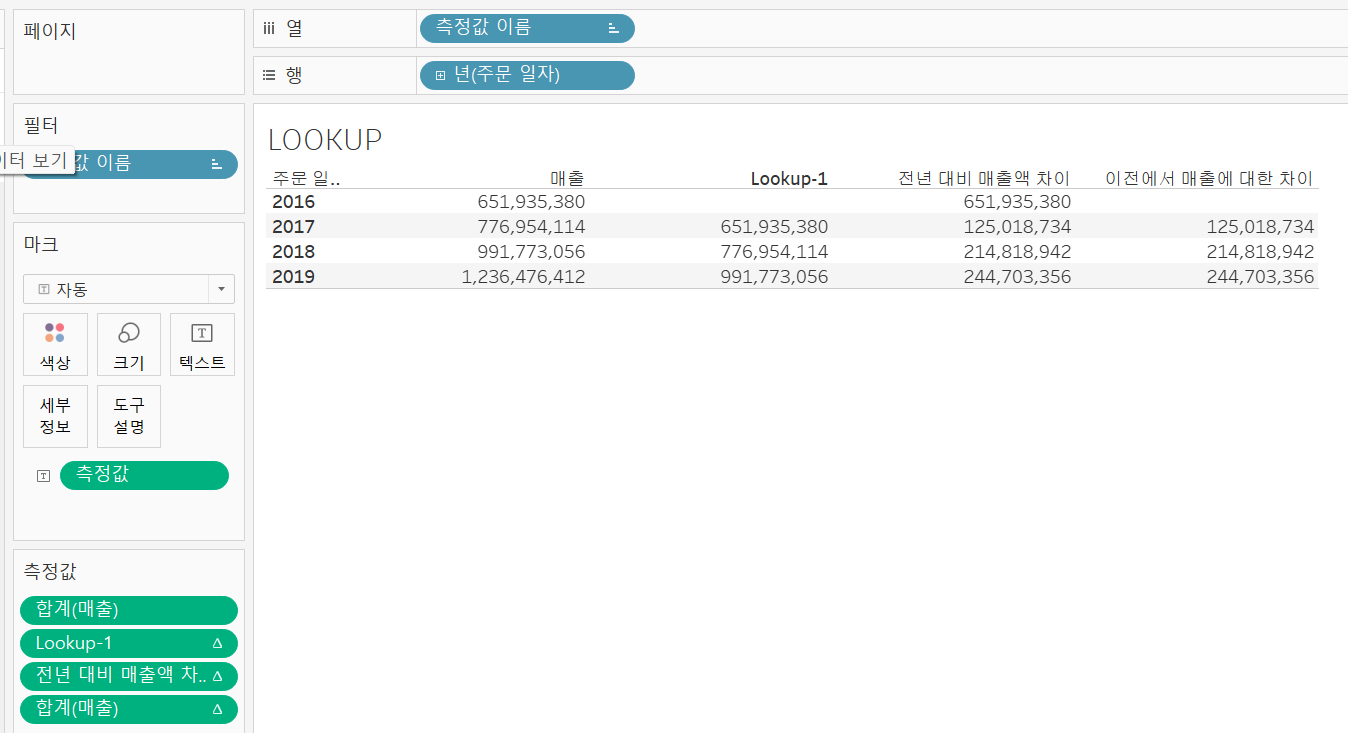
오프셋 옵션은 부호에 따라 가져오는 행이 달라지는데
-는 이전의 값을,+는 이후의 값을 가져온다. 따라서LOOKUP(SUM([매출]), -1)로 계산된Lookup-1필드는 2016년은 이전의 값이 없기 때문에 공백, 2017년은 2016년의매출의 합계, 2018년은 2017년의매출의 합계가 표시된 것이다.이 함수를 통해
전년 대비 매출액 차이도 구할 수 있으며 이는 [퀵 테이블 계산] - [차이] 와 동일한 값을 반환해준다.
-
WINDOW
: 현재 화면 내에서 주어진 식의 값을 반환한다.RUNNING함수와 유사하지만, 특정 기간을 설정할 수 있다는 차이가 있다.WINDOW_AVG: 이동 평균이 계산될 때 사용되는 함수로 계산된 필드로 직접 이동 평균을 만들 수도 있다.
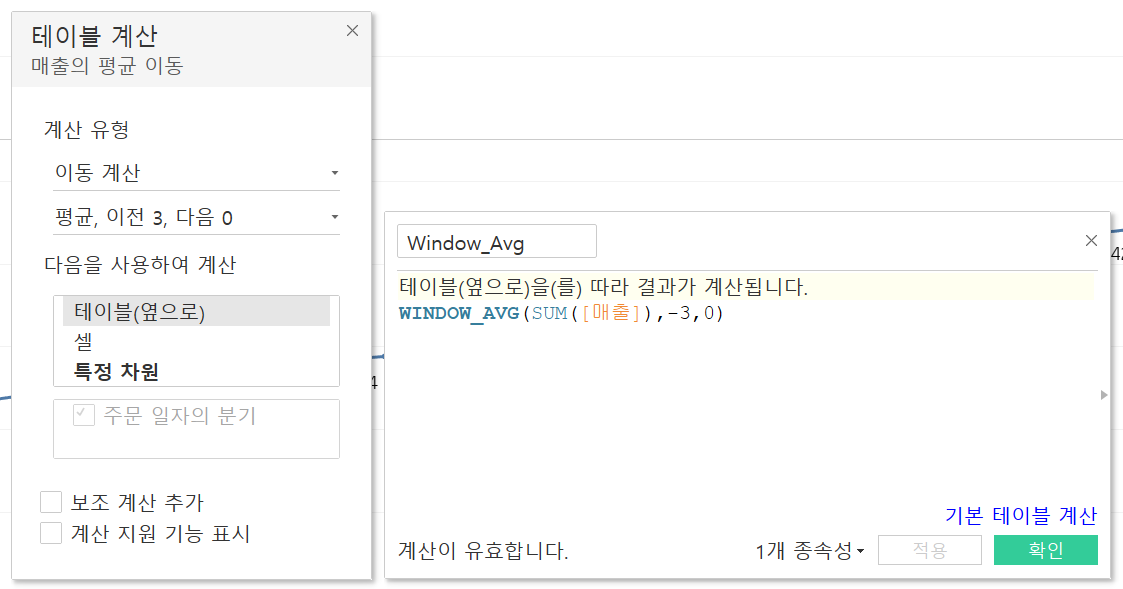
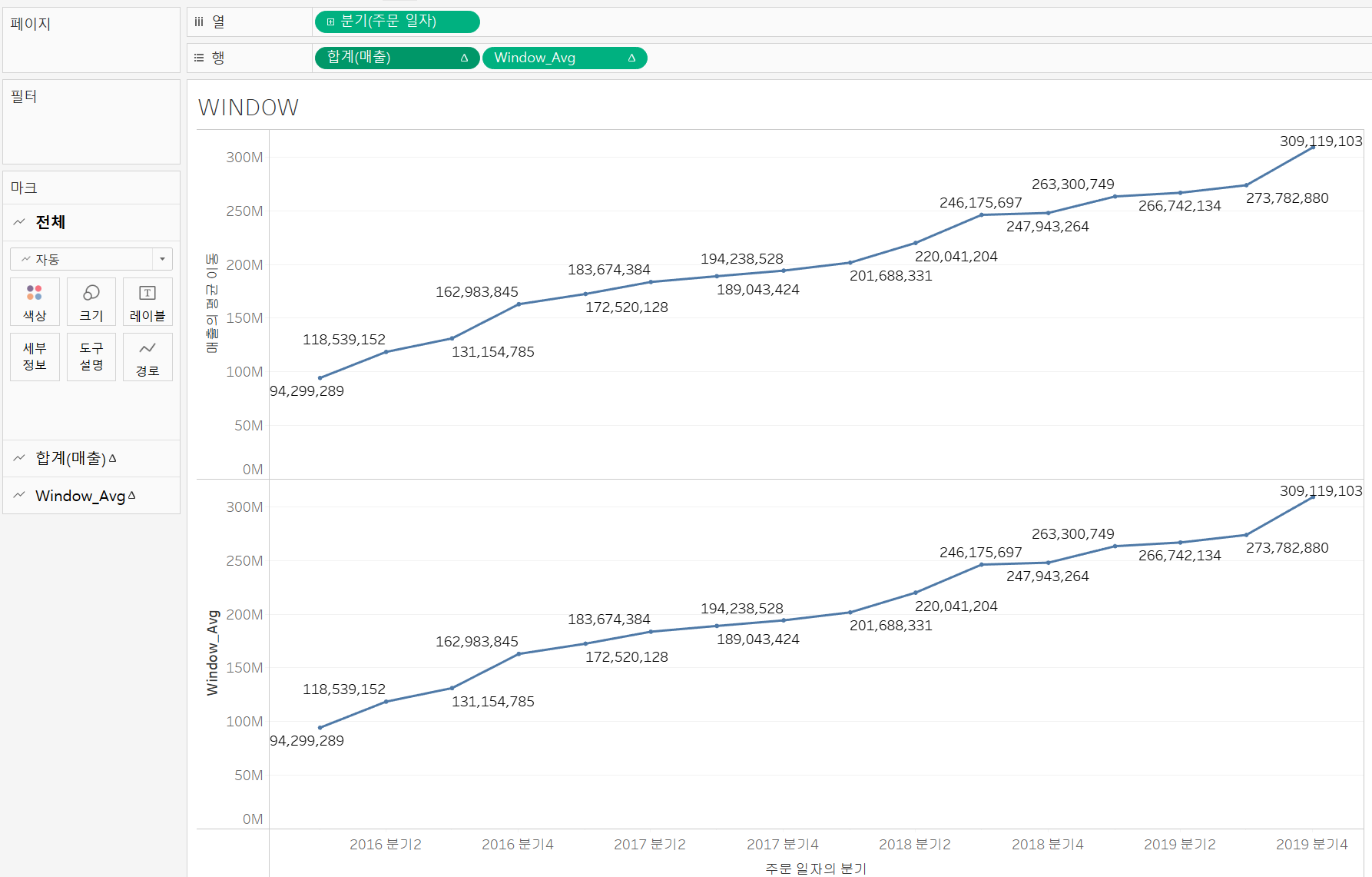
문자열 함수
문자열 함수를 잘 사용하면 현재 가지고 있는 데이터를 분해시켜 다른 시각의 인사이트를 도출할 수 있다.
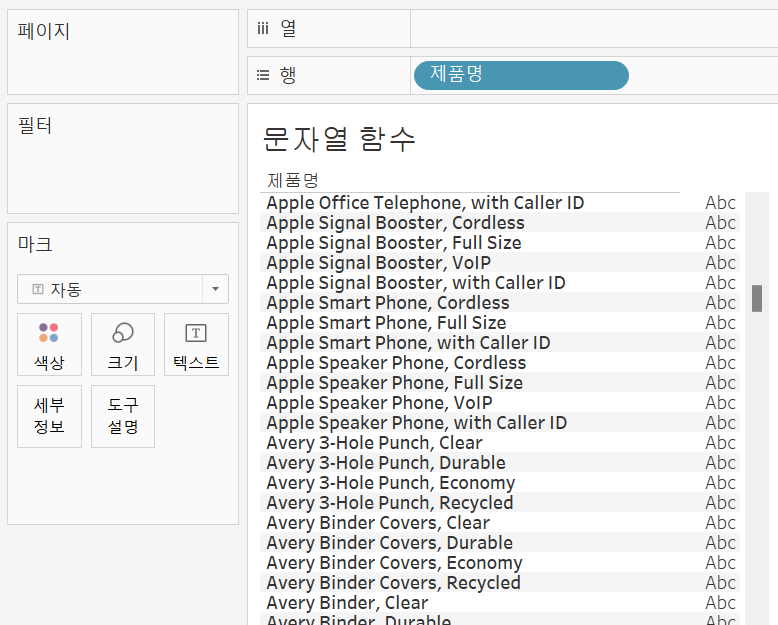
먼저 원본 데이터의 제품명 필드에는 회사명, 제품평과 같이 혼합된 형식임을 알 수 있다.
CONTAIN
CONTAIN함수를 이용해 'Smart Phone'을 판매한 회사들을 추출해보자.
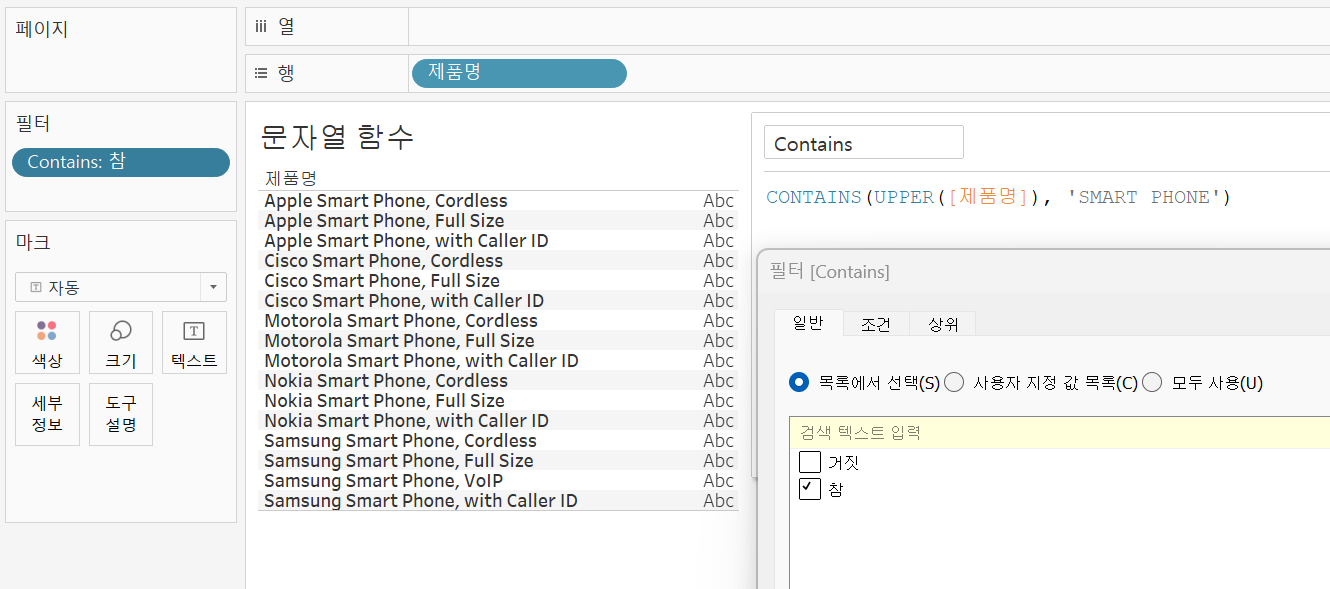
다른 회사에서 판매한 'Smart Phone'도 'Smart Phone'이라 표기되어있는지는 모른다. 따라서 제품명필드를 모두 대문자로 바꿔주는 UPPER 함수를 사용하고 찾을 값 또한 대문자인 'SMART PHONE'이라 작성하여 필터에 넣어주면 위와 같은 결과를 얻을 수 있다.
SPLIT
SPLIT(문자열, 구분 기호, 가져올 문자열 위치)
그렇다면 위에서 얻은 결과를 SPLIT 함수를 이용해 회사명과 제품명을 나눠보자.
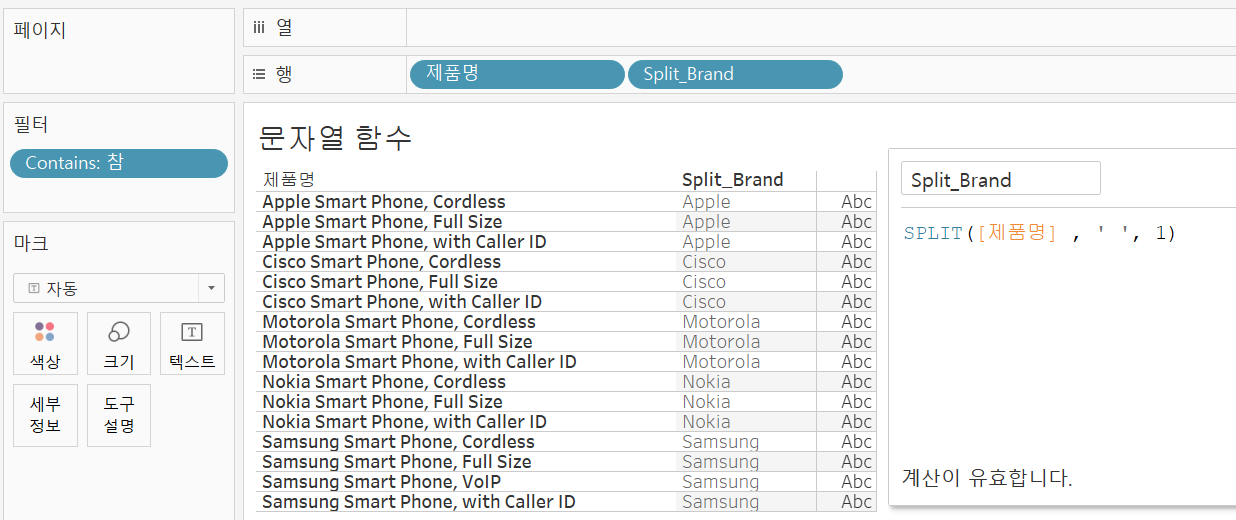
공백 기준으로 나누었을 때 처음 문자열이 1이다.
REPLACE
REPLACE(문자열, 변경 전 문자열, 변경 후 문자열)
이번에는 'Smart Phone'이라는 문자열을 추출하고 싶다.
SPLIT함수를 바로 사용하고 싶지만 공백을 기준으로 분리하면 'Smart Phone' 사이에 공백이 있어 한 번에 가져올 수 없다. 따라서 REPLACE를 통해 'Smart Phone'의 공백을 없애준 후 해당 문자열을 가져와보자.
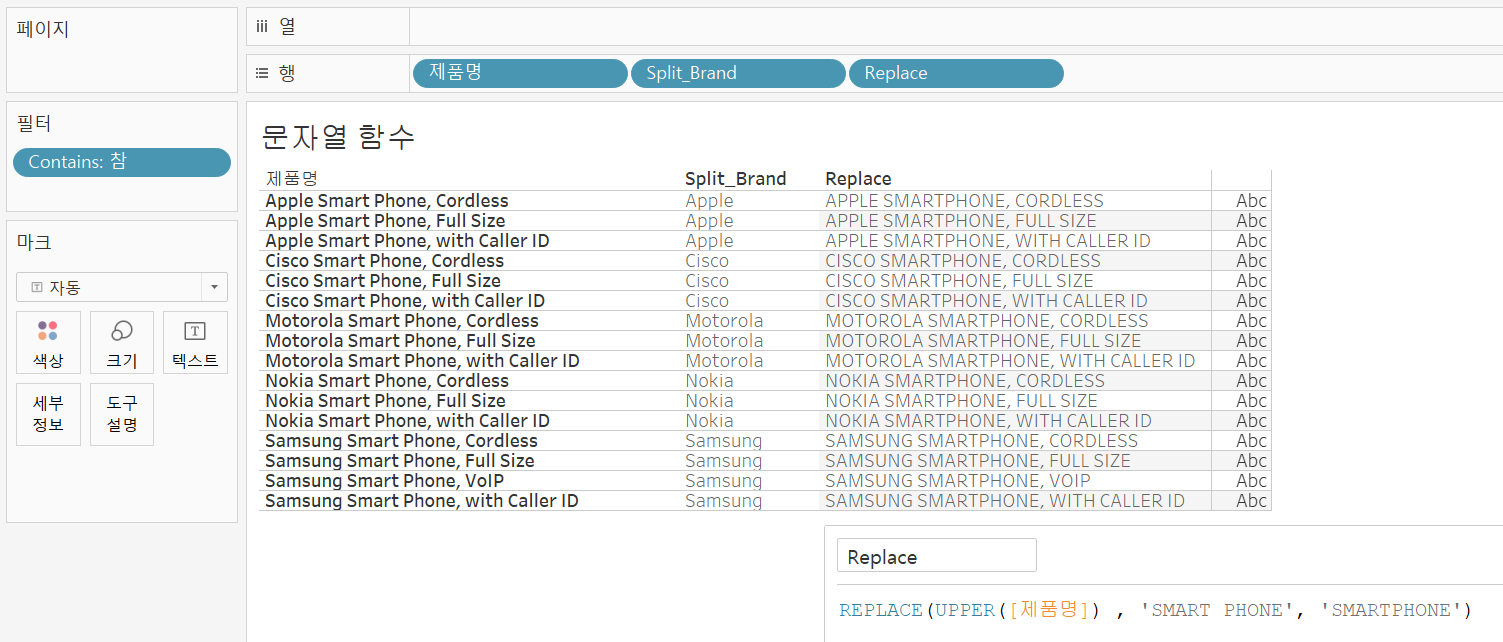
이번에도 역시 'Smart Phone'의 표현 방법이 다양할 수 있으므로 UPPER함수를 이용해 REPLACE 해주었다. 그러므로 반환값 또한 대문자 형태로 나온 것이다.
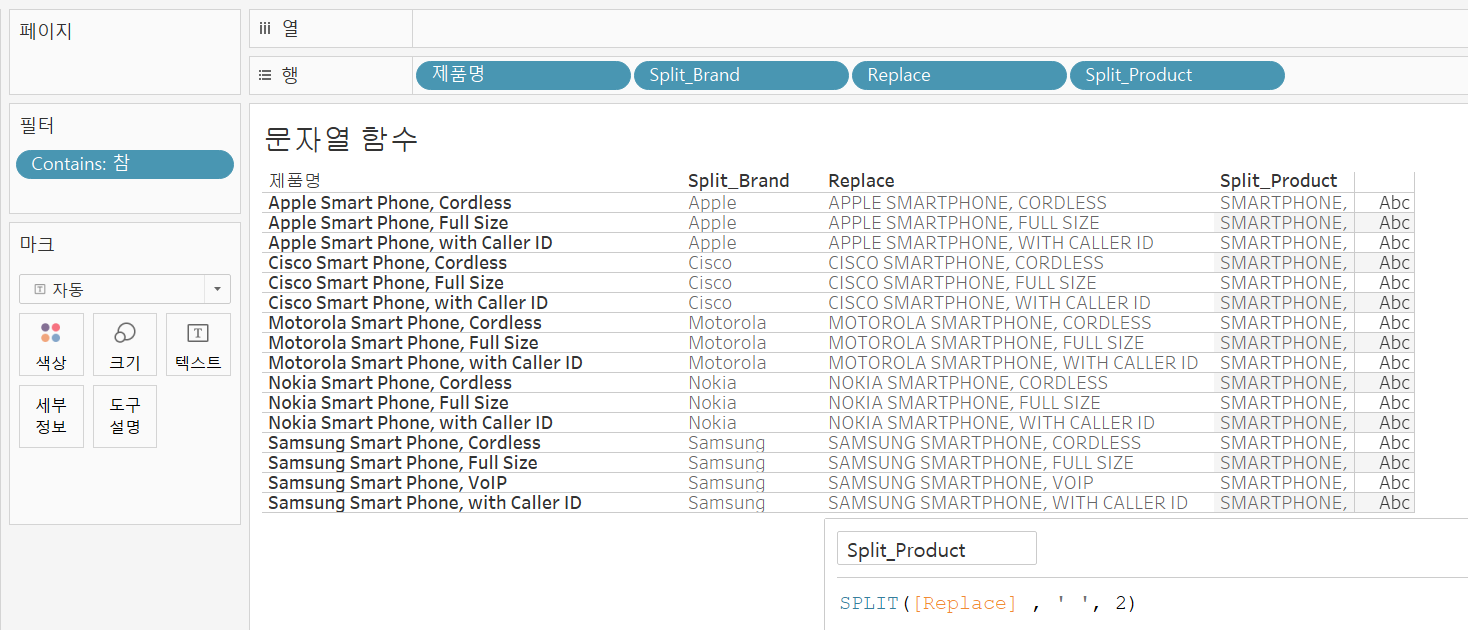
제품명인 'SMARTPHONE'이 잘 추출되었지만 데이터가 SMARTPHONE,으로 되어있어 쉼표까지 붙어있다.
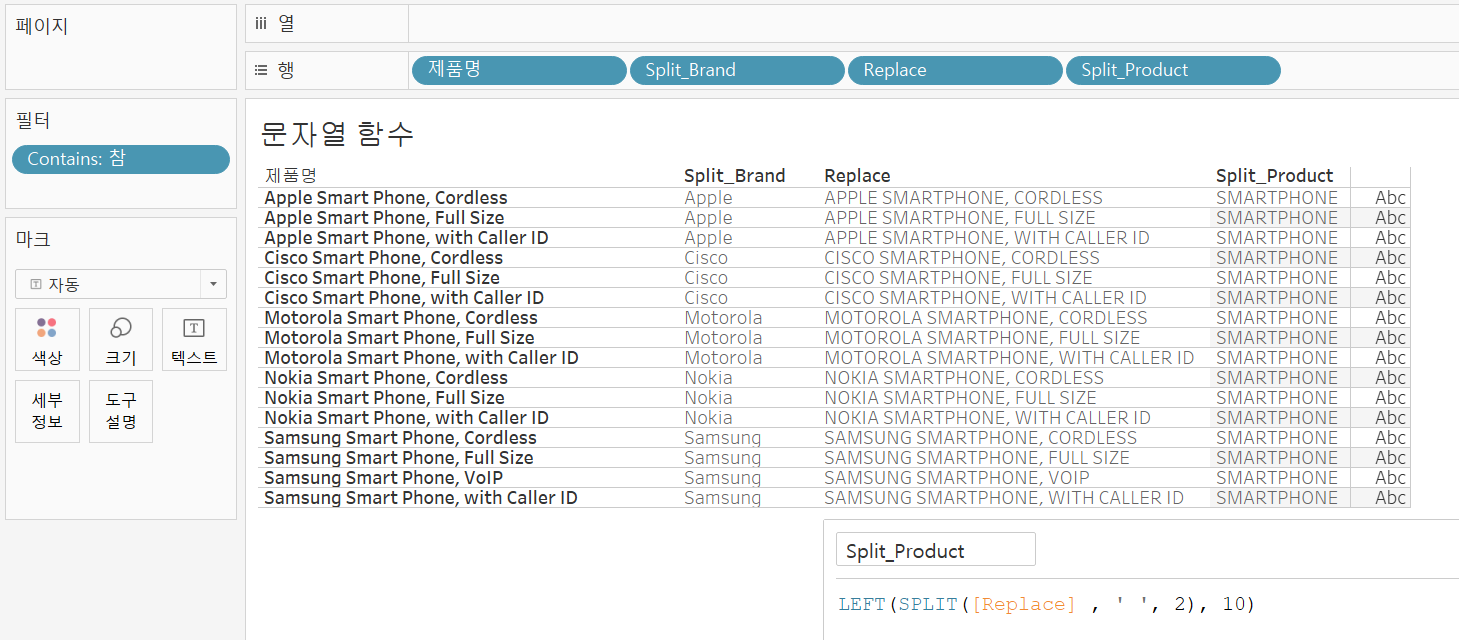
LEFT(문자열, 추출할 문자열 숫자) 함수를 이용해 쉼표를 없애주면 위와 같이 깔끔하게 제품명만 추출할 수 있다.
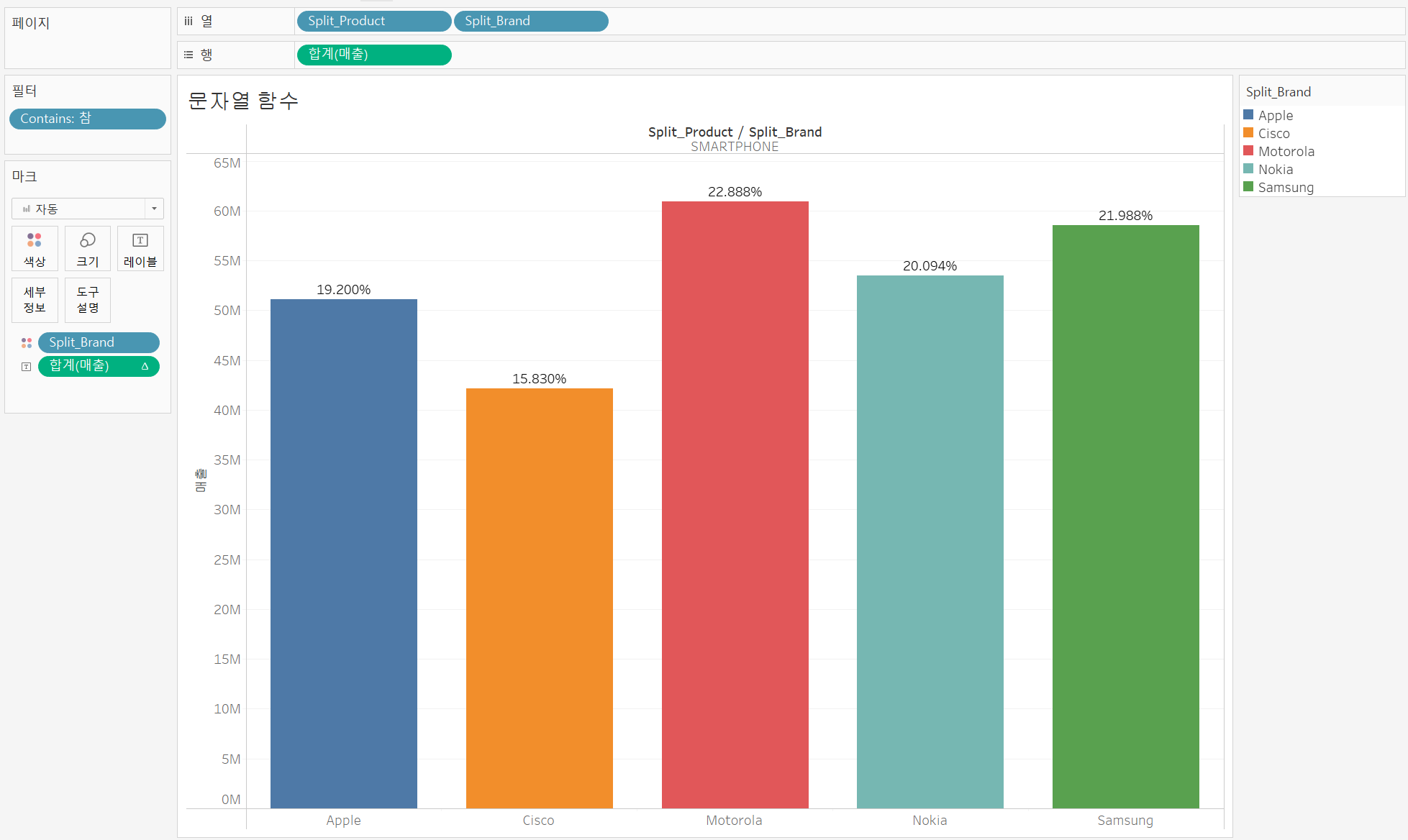
그럼 이제 데이터 추출을 했으니, 브랜드별 제품명의 매출을 확인해보자.
매출을 [퀵 테이블 계산] - 구성 비율로 설정하고 Split_Brand를 마크 색상에 넣어주면 아래와 같은 차트를 얻을 수 있다.
DATE 함수
시계열 분석을 할 때 유용하게 사용된다.
날짜_부분 옵션은 반드시 소문자로 작성해주어야 한다.
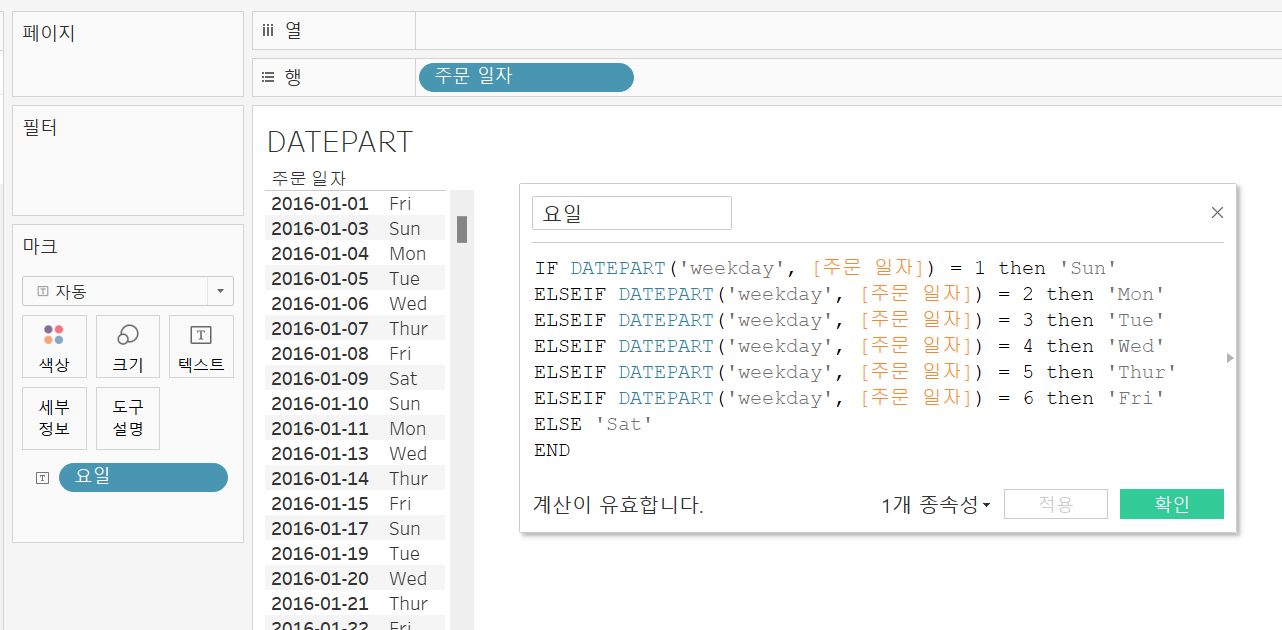
DATEPART
DATEPART('날짜_부분', 날짜 데이터)
지정한 날짜의 부분을 정수로 반환시켜준다.
지금껏 사용한 주문 일자 필드를 더블 클릭하면 DATEPART('year', [주문 일자])와 같이 나온다. 일상에서 잘 사용하고 있던 함수였던 것이다.
이 함수를 통해 요일을 반환해주는 필드를 만들면 아래와 같다.
DATETRUNC
DATETRUNC('날짜_부분', 날짜 데이터)
DATEPART는 특정 날짜의 값을 반환해주는 반면, 지정한 날짜 부분을 기준으로 잘라낸 후 새 날짜를 반환한다. 즉 DATETRUNC는 날짜 형태를 유지하며 반환해준다.
아래 시트를 보며 두 차이점을 한 번 더 살펴보자.
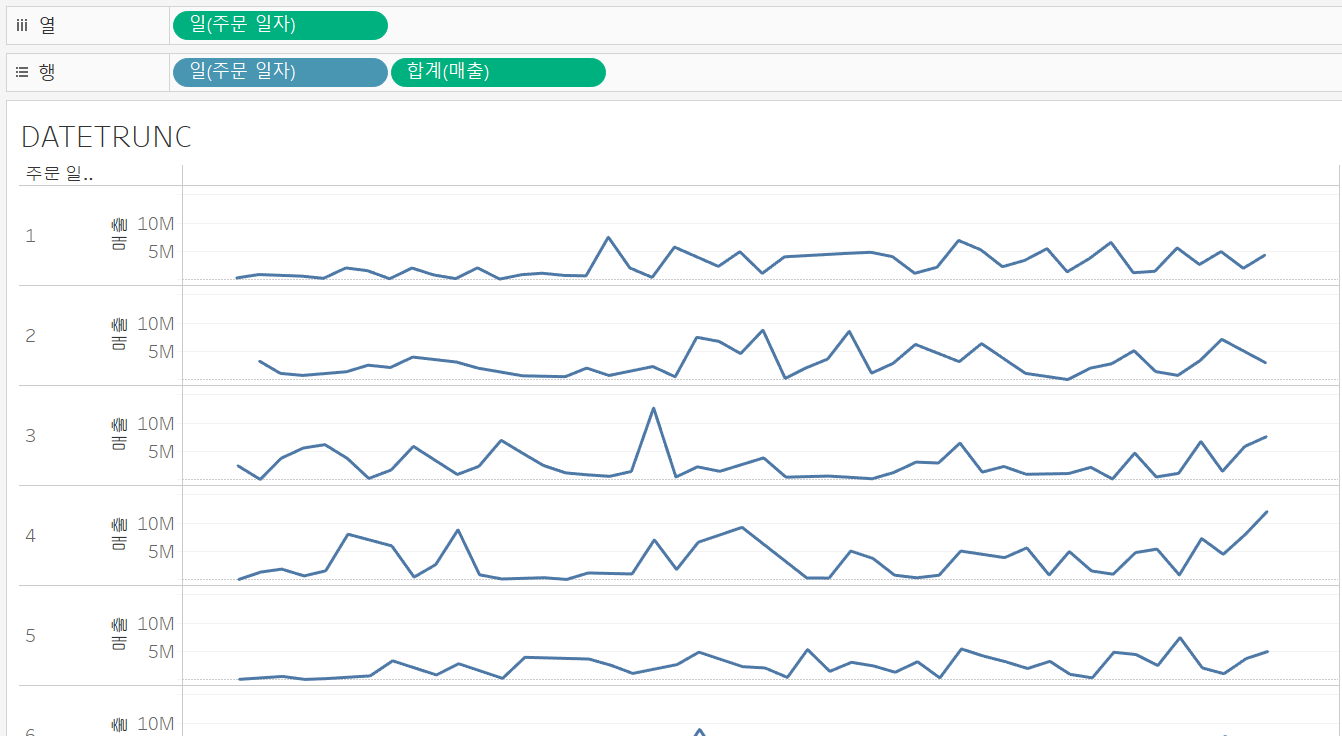
열 선반에는 DATETRUNC('day', [주문 일자])로 작성된 연속형 일(주문 일자) 필드이고, 행 선반에는 DATEPART('day', [주문 일자])로 작성된 불연속형 일(주문 일자) 필드이다.
차트를 보면, 행은 1,2,3,...과 같이 정수 값으로 떨어지지만 열에 마우스 오버를 해보면 2016년 1월 1일, 2016년 2월 1일, ... 과 같이 날짜 형태를 유지한 연속형 값이 나온 것을 볼 수 있다.
DATEDIFF
DATEDIFF('날짜_부분', 날짜 데이터)
날짜의 차이를 반환해준다.
이 함수를 통해 각 제품별 배송까지 걸린 기간을 알아내보자.
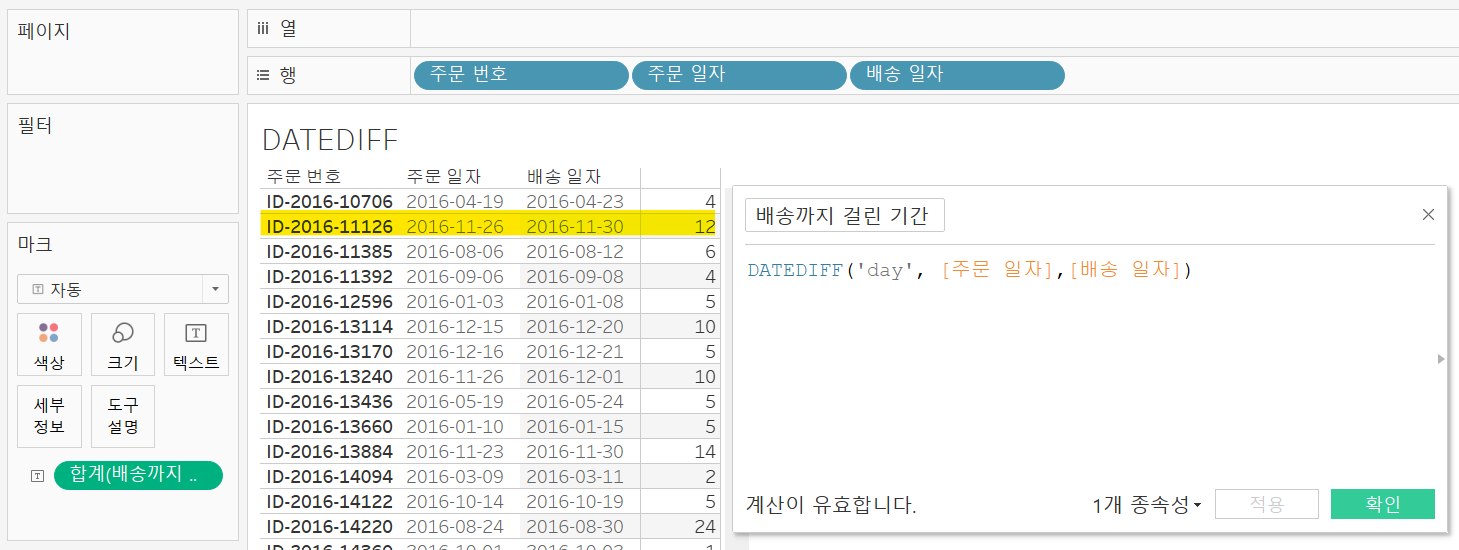
두번째 행을 보면 2016-11-26에 주문하고 2016-11-30에 배송이 되었다면 배송까지 걸린 기간은 4가 되어야할 것 같은데 12로 표시되고 있다.
이는 주문 번호가 하나의 고유값으로 표시되고 있지 않기 때문이다. 고유값이 아닌 주문 번호는 같은 주문번호로 여러 제품을 구매한 경우(= 주문 번호 하나에 여러 제품이 들어감) 제품 별 배송 기간이 다를 수 있기 때문에 위와 같이 오차가 생길 수 있다.
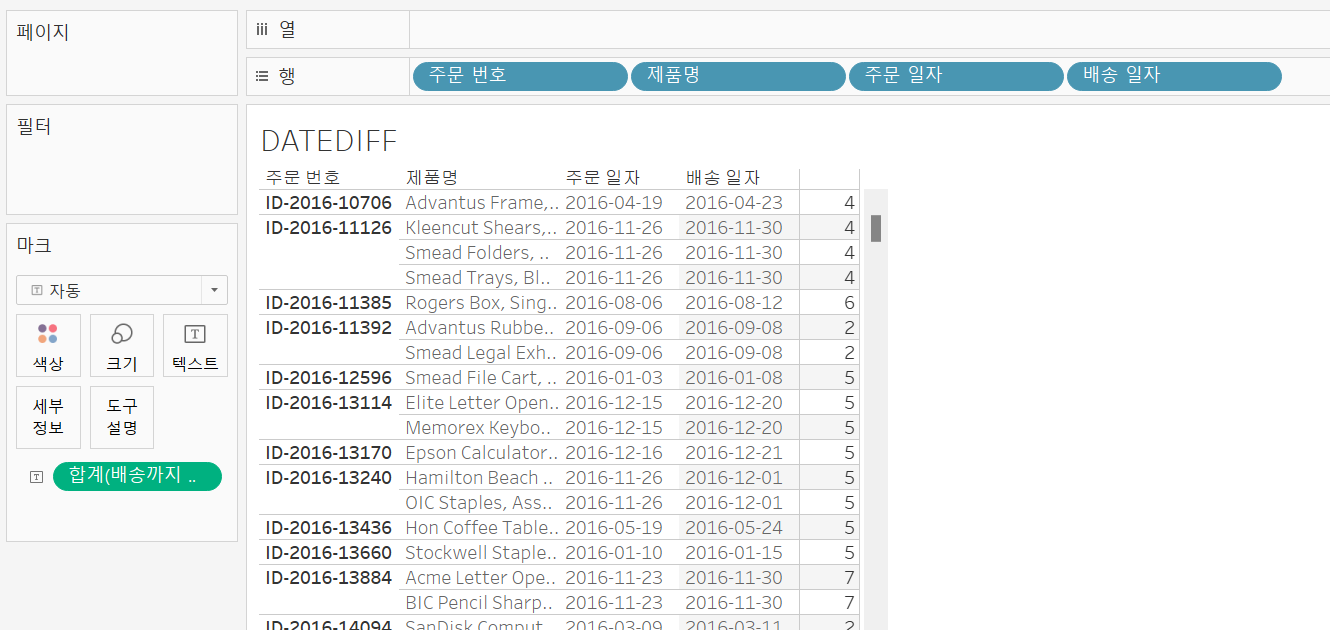
따라서 우리의 목적에 맞는 배송까지 걸린 기간을 살펴보려면 제품명 필드를 추가해주면 아래와 같이 나타난다. ([모든 멤버 추가] 클릭)
MTD, QTD, YTD
MTD(Month to Date : 해당 월 첫날부터 기준일까지), QTD(Quarter to Date : 해당 분기 첫날부터 기준일까지), YTD(Year to Date : 해당 년도 첫날 또는 회계연도 첫날부터 기준일까지) 라는 외국계 기업의 약어이다.
DATEDIFF함수와 매개변수를 이용해 MTD, QTD, YTD 를 살펴보자.
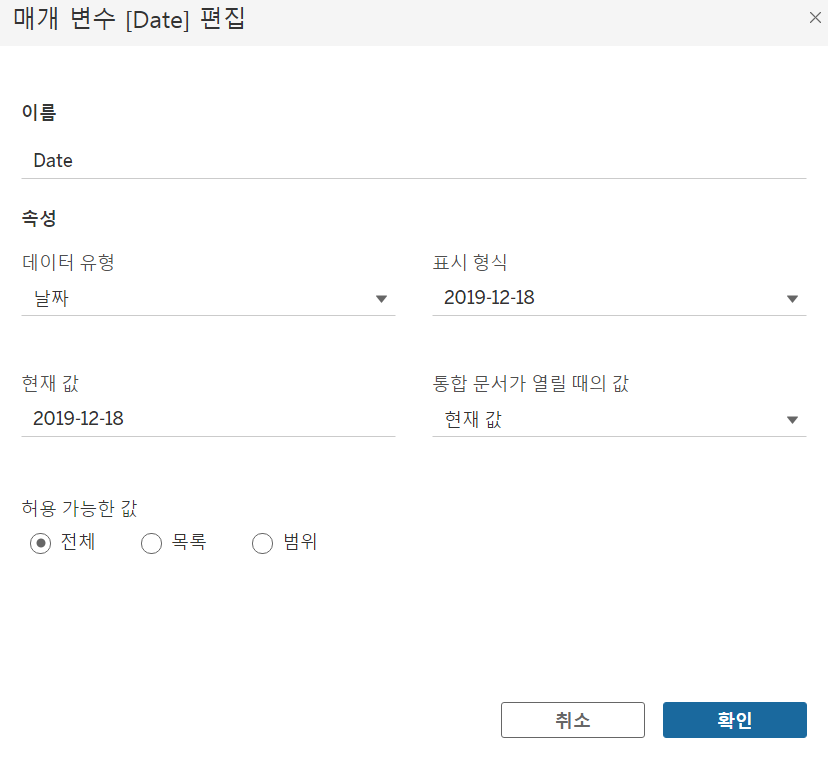
먼저 위와 같이 기준일을 입력할 매개변수를 만들어준다.
그리고 MTD, QTD, YTD의 계산식을 만들어 필터에 넣어주면 2019-12-18의 기준일에 맞는
MTD, QTD, YTD가 생성된다.
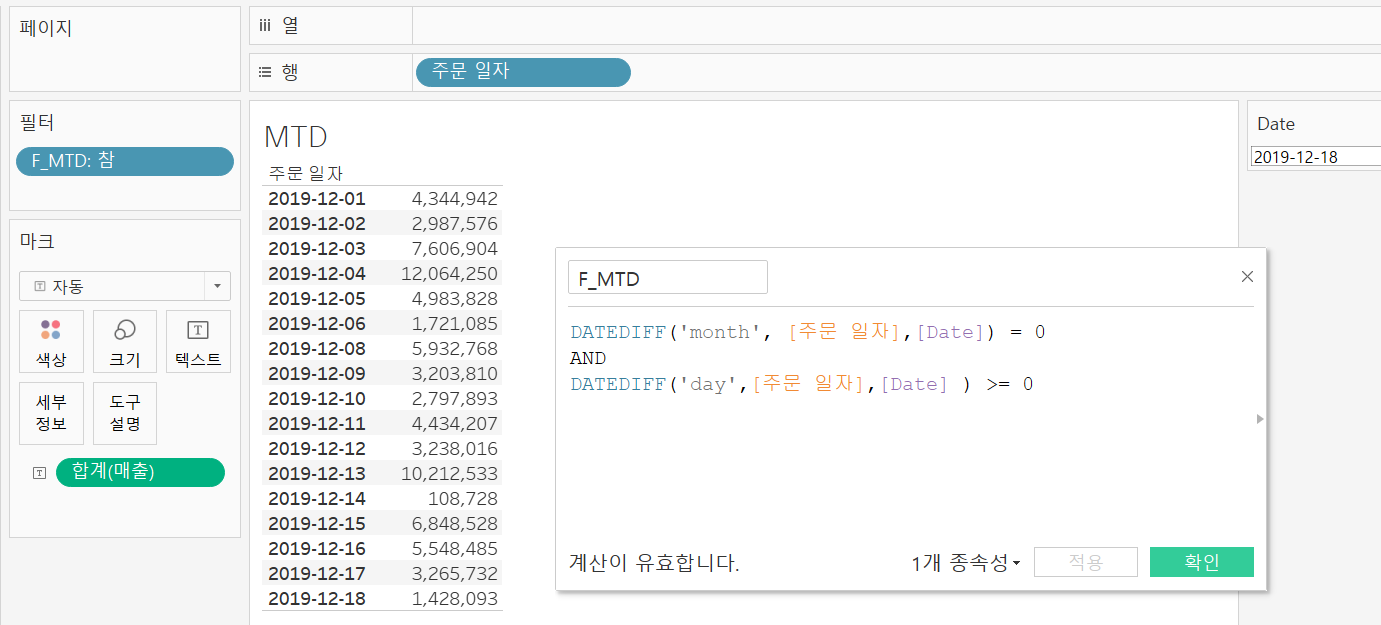 MTD(2019-12-01 ~ 2019-12-18) MTD(2019-12-01 ~ 2019-12-18) | 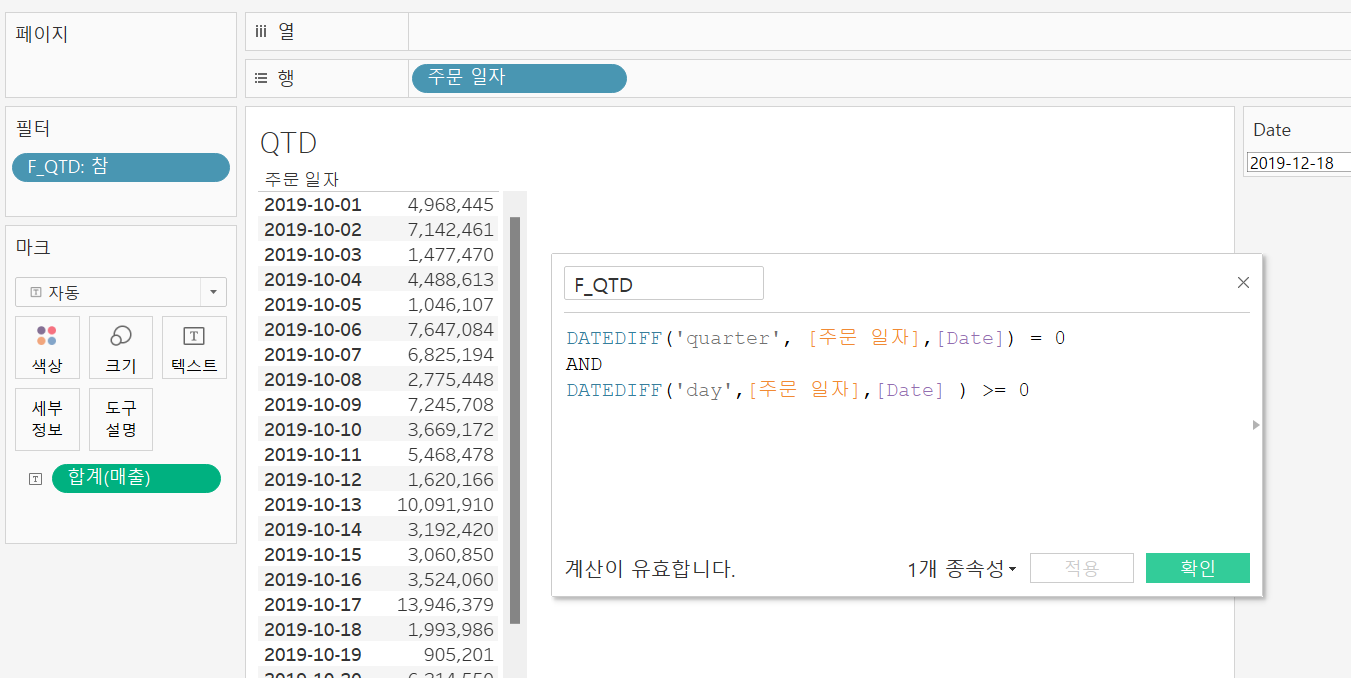 QTD(2019-10-01 ~ 2019-12-18) QTD(2019-10-01 ~ 2019-12-18) | 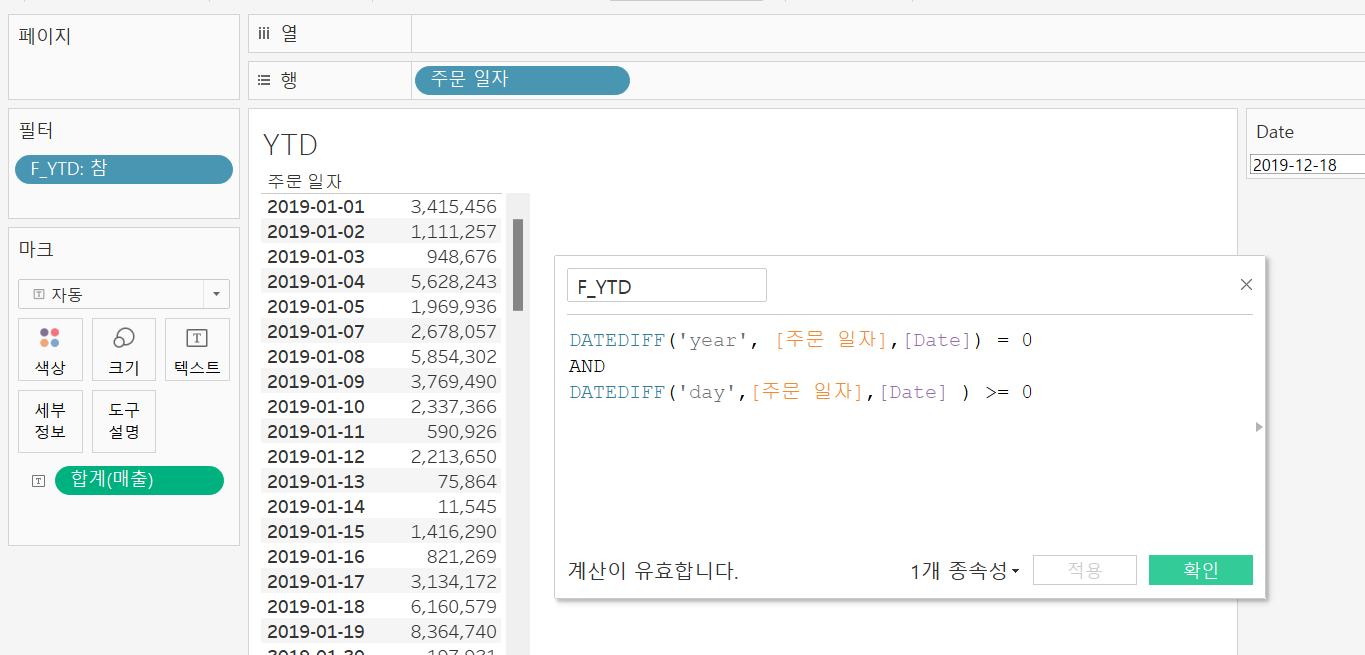 YTD(2019-01-01 ~ 2019-12-18) YTD(2019-01-01 ~ 2019-12-18) |
|---|
LOD 표현식
LOD(Level of Detail)은 세부 수준식으로 데이터 분석에서 자주 사용된다.
세부 수준에서 데이터의 깊이를 정하고 데이터를 집계하여 계산하는 방식으로 특정 차원을 포함하거나(INCLUDE), 제외하거나(EXCLUDE), 고정하여(FIXED) 사용할 수 있다.
형식은 아래와 같이 반드시 {}안에 사용되어야 하며 차원과 집계 함수 사이에는 :이 있어야 한다.
{INCLUDE [차원1], [차원2] : SUM([측정값])}
INCLUDE
눈에 보이진 않지만 화면에서 보이는 것보다 더 깊은 차원에서 집계를 해서 값을 가지고 있고 지금과 같이 화면에서 재집계를 할 경우 그 값을 다시 가져온다. 즉 현재 화면에서 보여주고 있는 차원보다 더 깊은 차원이 있고, 현재 화면에서 그 값을 보여주고자 할 때 사용한다.
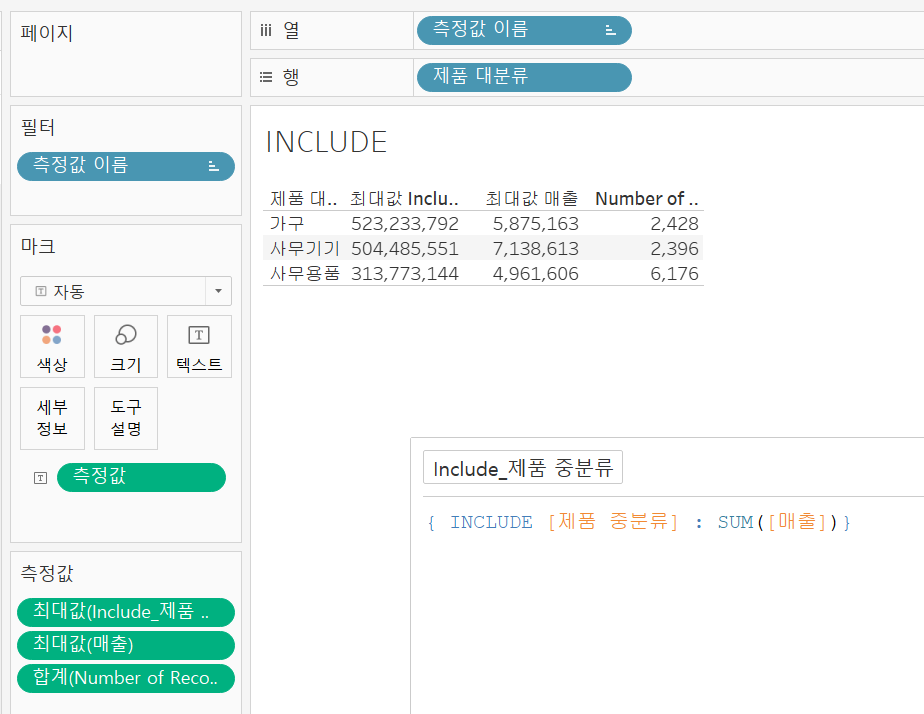
Include_제품 중분류를 위와 같이 생성해주고 INCLUDE함수의 의미를 파악하기 위해 Include_제품 중분류와 매출 필드를 최대값으로 변환하여 측정값에 올려주었다.
 Include_제품 중분류 Include_제품 중분류 |  Sum Sum |
|---|
먼저 매출의 최대값을 살펴보면, 매출을 내림차순으로 정렬해보았을 때 원하얀 고객님의 데이터가 5,875,163이었다. 주문 번호와 제품 코드 필드를 더 추가해서 살펴보면 2017년에 구매한 첫 번째 제품의 매출이 5,875,163이고 이 값이 가구 중에서 가장 커서 해당 값이 산출된 것을 볼 수 있다.
반면 Include_제품 중분류는 단순히 제품 대분류의 하위 차원인 제품 중분류에서의 매출의 합계 중 최대값인 의자의 523,233,792의 값이 반환된 것을 볼 수 있다.
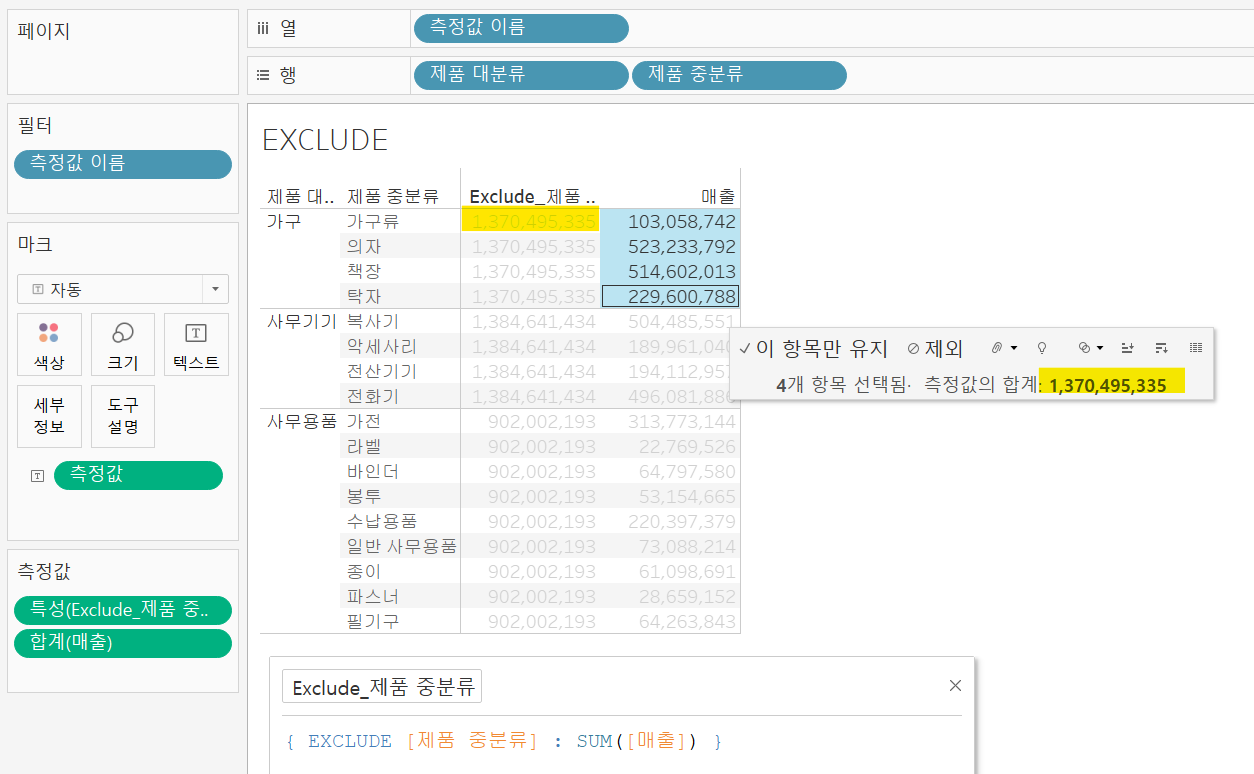
EXCLUDE
현재 화면의 차원을 무시하고 집계를 낼 수 있기 때문에 현재 차원을 제외하고 재집계하고 싶을 때 사용할 수 있다.
INCLUDE와 달리 값이 중복해서 들어간 것을 볼 수 있다. 제품 중분류의 차원을 제외했기 때문에 이 값은 제품 대분류 안에 있는 모든 제품 중분류 매출의 합계로 표현된다.
특정 차원을 제외한 집계값을 하위 차원에서 가지고 있고 이를 현재 화면에서 보여주고자 할 경우 대분류 별 합계값을 하나만 가지고 있으므로 값이 중복해서 들어간다.
따라서 EXCLUDE함수의 측정값을 평균, 최대, 최소와 같이 변경해도 값은 변하지 않는다.
INCLUDE 와 EXCLUDE는 특정 차원에서의 집계를 해주기 때문에 다양한 계산이 가능하지만 활용도는 높지 않다. 화면에 연계해서 결과값을 만들어내므로 사용자가 화면에 어떤 값을 추가하느냐에 따라 값의 변동성이 크기 때문이다.
그에 반해 FIXED는 사용자가 값을 정할 수 있으므로 활용도가 높다.
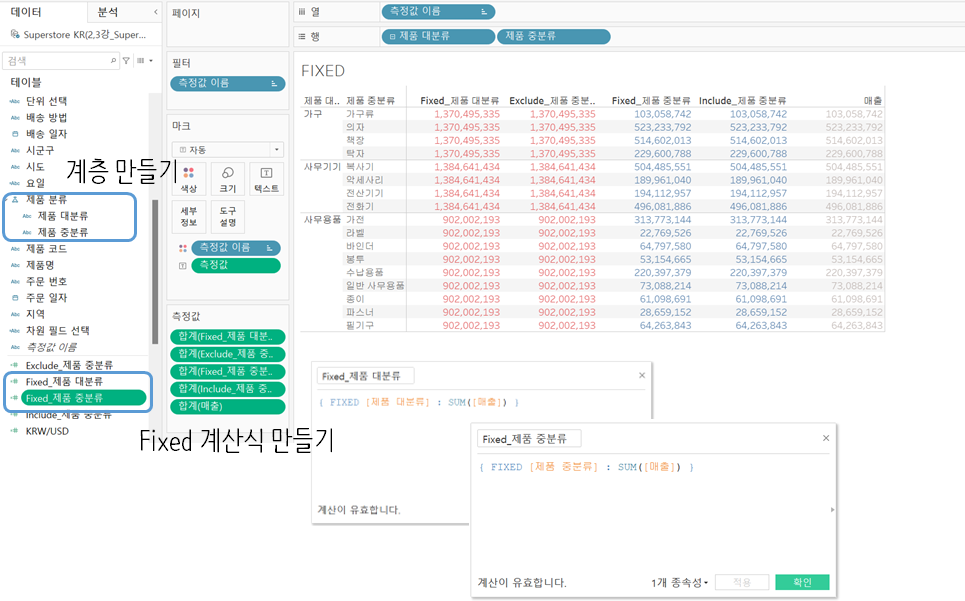
FIXED
먼저, INCLUDE 와 EXCLUDE를 FIXED로도 표현할 수 있다.
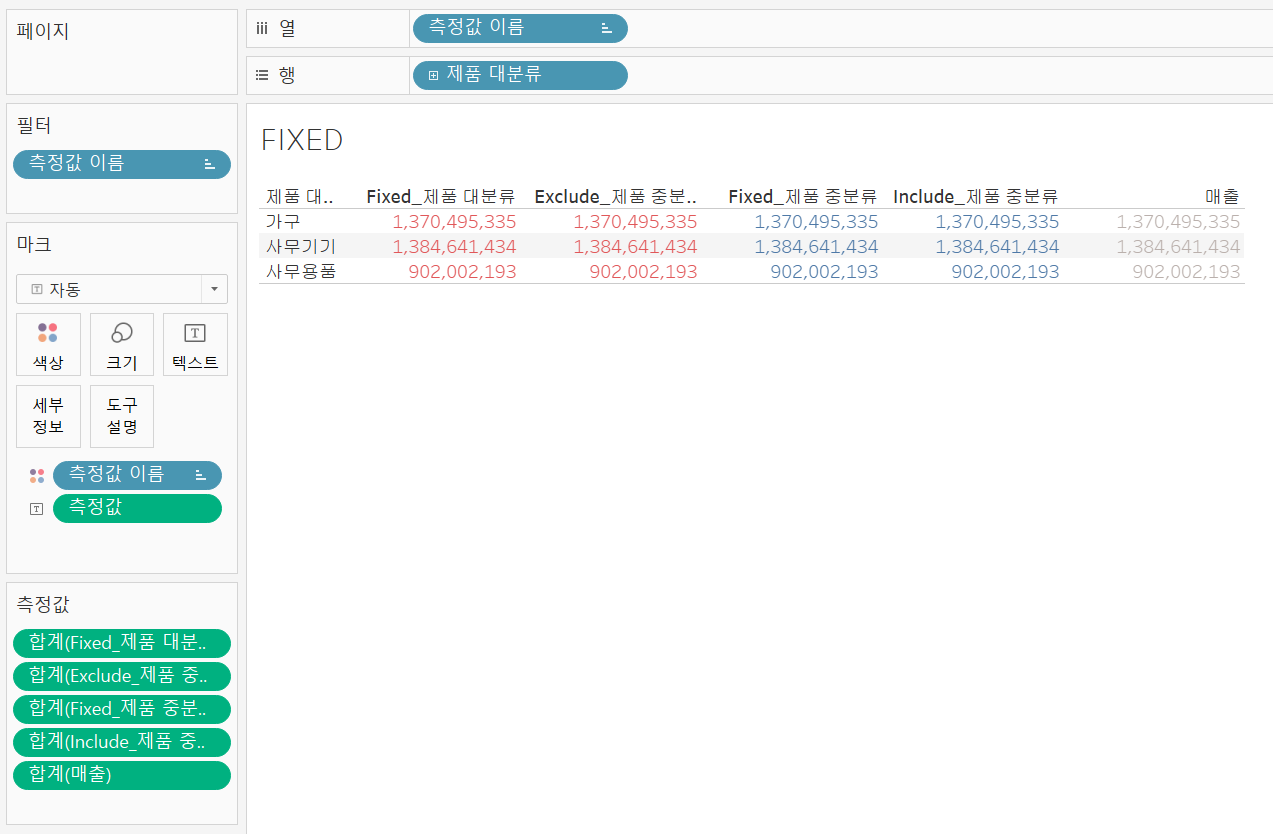 제품 대분류 차원 제품 대분류 차원 | 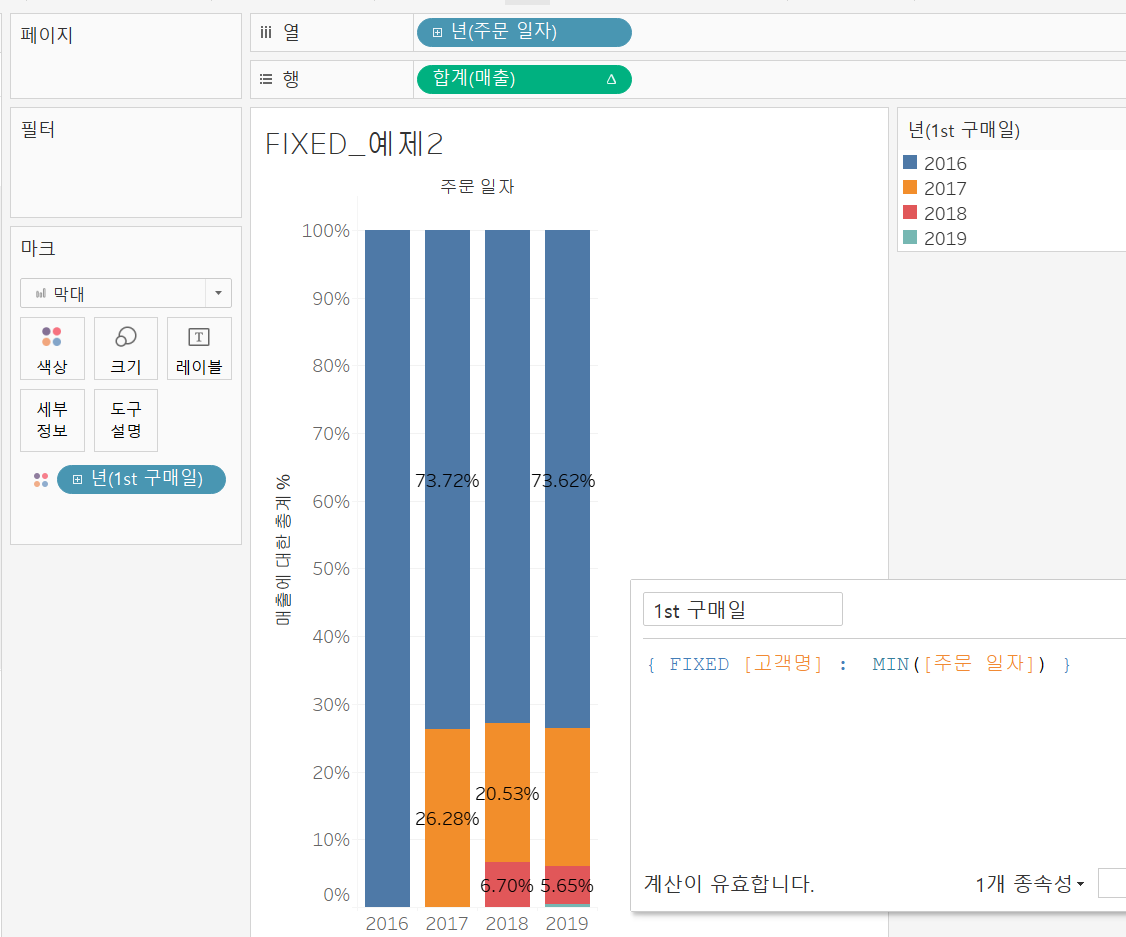 |
|---|
더 나아가 FIXED는 실무에서도 많이 사용되고 있으므로 연습을 더 해보자.
- 유입 시점 별 매출 기여도를 알아보자.
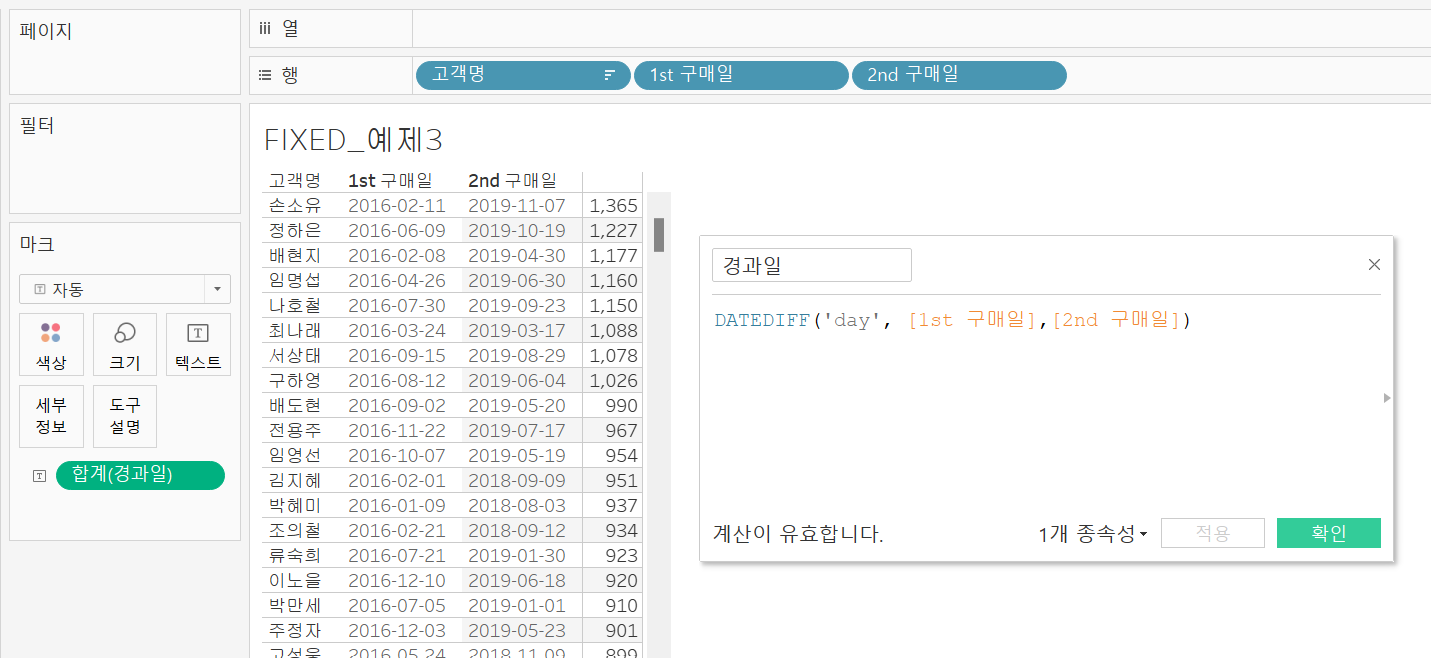
처음 구매한 시점을 알아내기 위해 1st 구매일 필드를 생성해줘야 하는데 이때 고객별 첫 구매 시점을 알아내야 하므로 FIXED가 필요하다.
1st 구매일 필드를 마크 색상에 넣어주고
구매 시점이 같은 고객들이 다음 해에 차지하는 매출 비중을 쉽게 보기 위해 행 선반에 있는 매출 필드를 [퀵 테이블 계산] - 구성 비율, [다음을 사용하여 계산] - 테이블(아래로)를 설정해주면 위와 같은 시트를 볼 수 있다.
- 고객별 첫 번째 구매 시점과 두 번째 구매 시점 사이의 기간을 알아보자.
첫 번째 구매 시점은 1st 구매일 필드를 사용하면 되고, 두 번째 구매 시점은 1st 구매일 필드 계산에서 날짜를 첫 번째 구매 시점은 제외시킨 날짜로 변경해주면 된다.
1st 구매일 제외필드( = 첫 번째 구매 시점은 제외시킨 날짜)는 IIF([주문 일자] > [1st 구매일] ,[주문 일자], NULL )로 생성해준다면
2nd 구매일 필드(= 두 번째 구매 시점)는 { FIXED [고객명] : MIN([1st 구매일 제외]) } 로 표현될 수 있다.
그리고 두 구매 시점 사이의 기간을 계산하기 위해 DATEDIFF함수를 사용해주면 아래와 같이 고객별 첫 번째 구매 시점과 두 번째 구매 시점 사이의 기간을 파악할 수 있다.
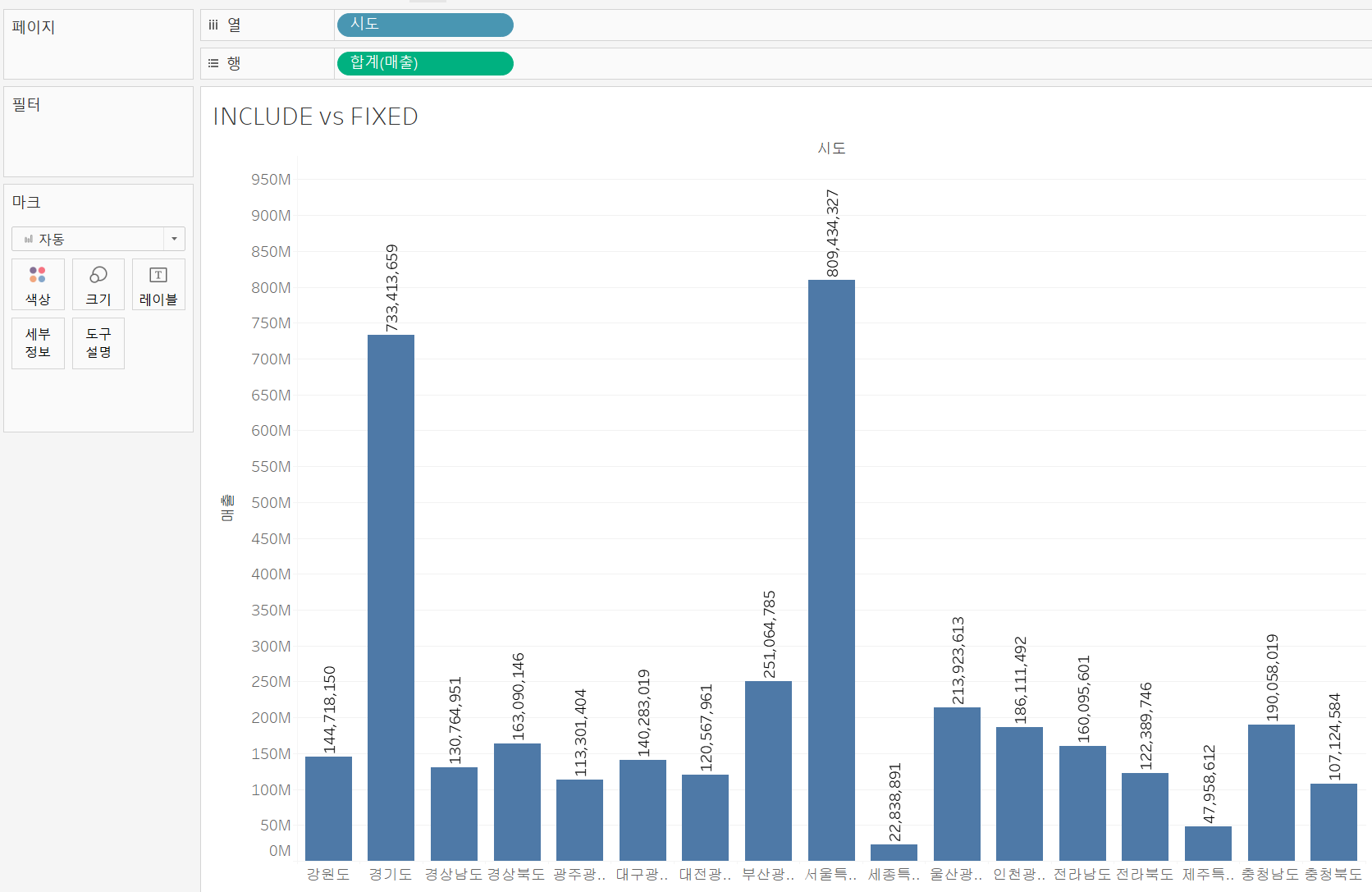
INCLUDE vs FIXED
INCLUDE 와 FIXED의 차이를 이해해보기 위해 위와 같은 시도 차원에서의 매출 차트에서 각 지자체 별 시군구 매출의 평균을 표시해보도록 하자.
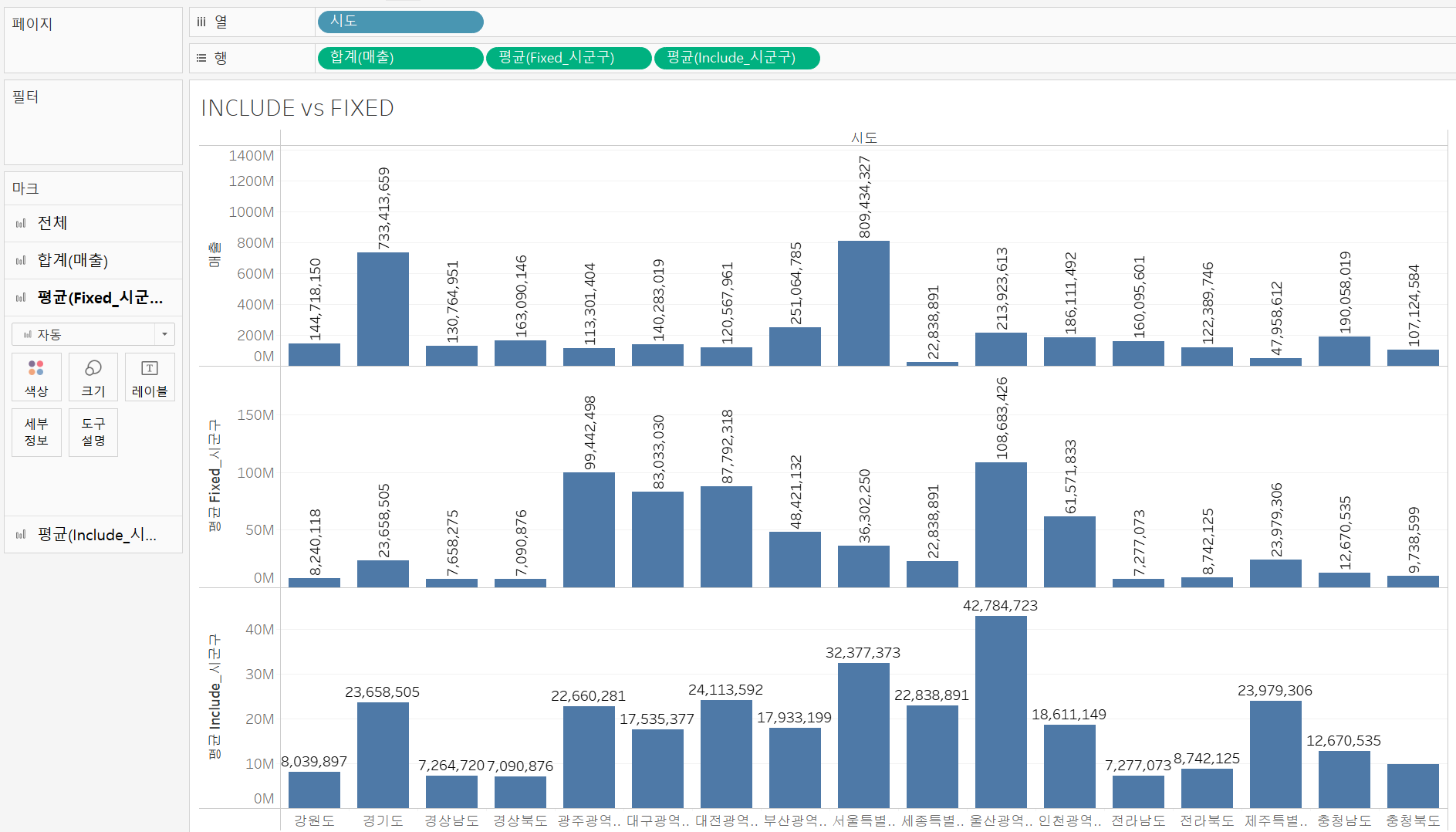
INCLUDE를 이용해서 만든 { INCLUDE [시군구] : SUM([매출]) } 는 Include_시군구필드,
FIXED를 이용해서 만든 { FIXED [시군구] : SUM([매출]) }는 Fixed_시군구필드이다.
이들을 행 선반에 올려둘 때 평균으로 재집계되도록 설정하면 아래와 같은 차트를 얻을 수 있다.
언뜻 보면 둘의 차이가 없어보이지만, 중간중간 값이 같은 부분도 다른 부분도 있다.
INCLUDE 와 FIXED의 큰 차이는 현재 차트의 차원 값을 고려하는지 아닌지이다.
지금 보이는 차트를 예로 들면 INCLUDE는 매출의 합계를 구할 때 화면에 있는 차트 즉, 시도 차원을 함께 고려하여 계산해준다. 다시 말해 화면에 있는 시도와 계산식에 있는 시군구 필드를 함께 고려하여 매출의 합계를 만들어준다.
반면 FIXED는 화면의 차원과 상관없이 우선적으로 시군구 차원에서만 매출의 합계를 구해주고 화면에 표시될 때 다시 집계되면서 결과값을 만들어낸다.
다시 집계될 때 각 지자체 별 시군구의 이름이 고유한 값이 아니란 점이 차이를 발생시킨다.
따라서 시군구 차원만 생각하여 시도 차원은 생각해주지 않은 계산이 되므로 우리의 목적에 맞는 계산식은 { INCLUDE [시군구] : SUM([매출]) } 이다.
만약 FIXED를 이용해 INCLUDE와 같은 결과값을 만들고 싶다면, 시군구와 시도를 모두 고려한 { FIXED [시도], [시군구] : SUM([매출]) } 계산식으로 사용해주어야 한다.
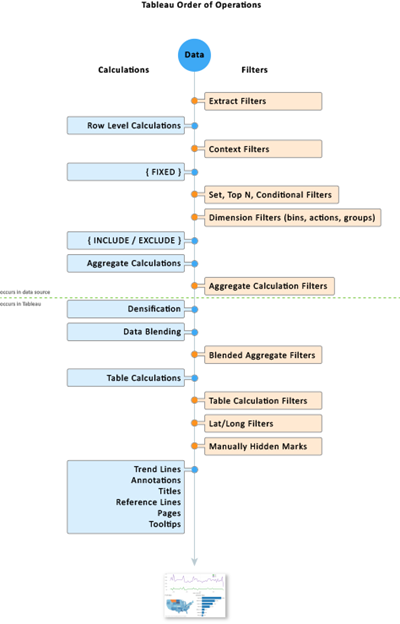
태블로 작동 순서(Order of Operations)
태블로에서 작동하는 계산과 필터 순서를 정리한 것이다.
모든 값을 제대로 입력했는데, 원하는대로 작동하지 않는다면 이를 한 번 고려해보면 좋다.
