[머신러닝] Decision Tree / scikit learn / 데이터 나누기(과적합, 데이터 나누기, zip과 언패킹) / 타이타닉 생존자분석
제로베이스 데이터스쿨

✍🏻 18일 공부이야기.
✍🏻 공부한 내용의 코드들은 아래 깃허브에 올려두었습니다 :)
https://github.com/castlemi99/ZeroBaseDataSchool/tree/main/Machine%20Learning
What is Machine Learning
머신러닝이란
명시적으로 프로그래밍하지 않고도 컴퓨터에 학습할 수 있는 능력을 부여하는 학문
예)
IRIS 데이터

꽃잎, 꽃받침의 길이/너비 정보를 이용해서 품종을 구분할 수 있을까?
데이터관찰
from sklearn.datasets import load_iris
iris = load_iris()
import pandas as pd
iris_pd = pd.DataFrame(iris.data, columns = iris.feature_names) # iris.keys()를 출력하여 원하는 데이터가 어느 컬럼에 있는지 확인할 수 있다.
# 품종을 구분하기 위한 분석이니, 품종 필드를 추가해보자
iris_pd['species'] = iris.target위 과정을 진행하면 iris 데이터가 들어간 데이터프레임을 얻을 수 있다.
머신러닝을 하기 전, 어떻게 하면 세 품종을 구분할 수 있을지 생각해보자.
먼저 데이터들에 대해 시각화를 해보았다.
boxplot
plt.figure(figsize=(12,6))
sns.boxplot(x = 'sepal length (cm)', y = 'species', data = iris_pd, orient='h')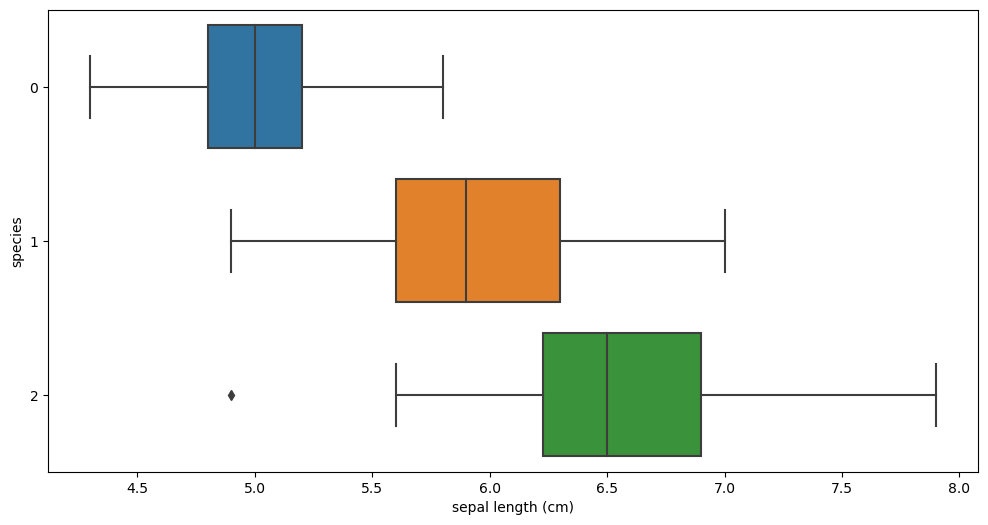 sepal length vs species sepal length vs species | 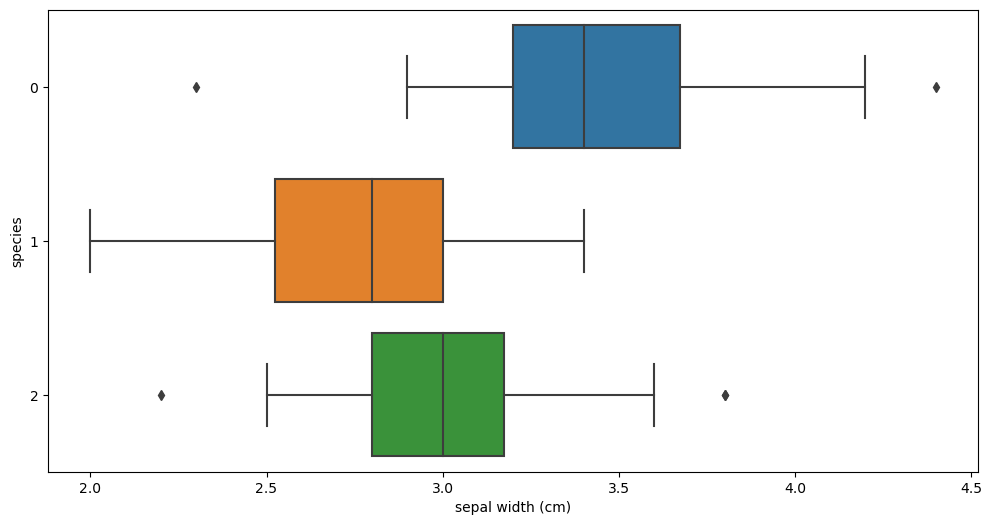 sepal width vs species sepal width vs species |
|---|---|
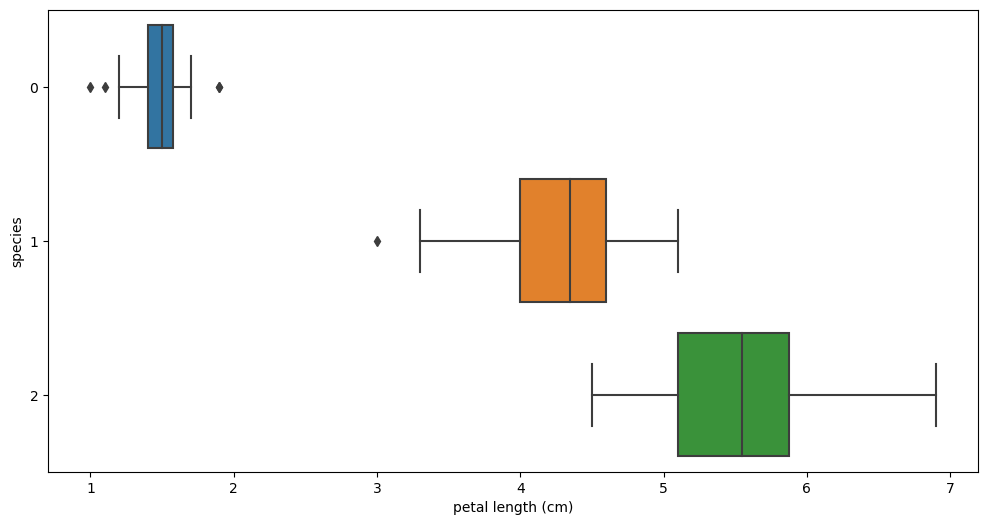 petal length vs species petal length vs species | 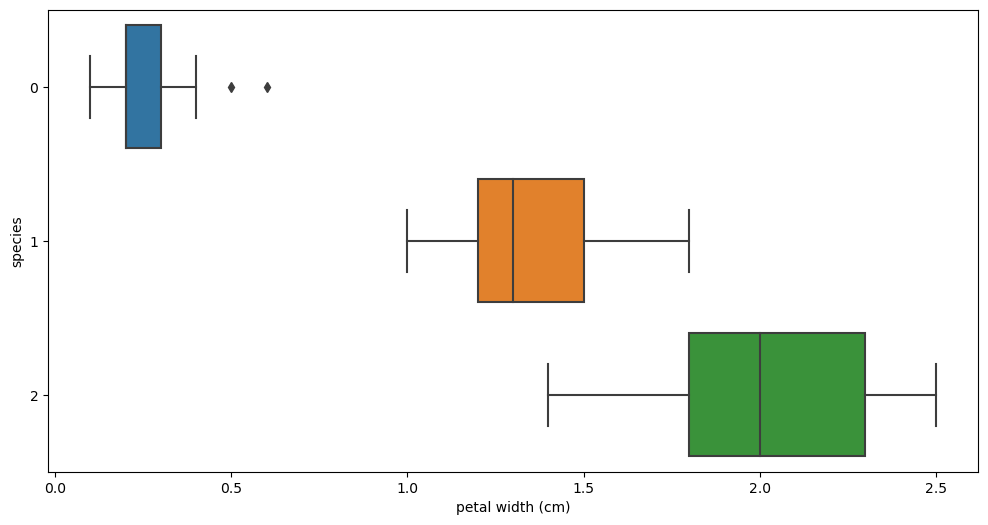 petal width vs species petal width vs species |
sepal 필드로는 세 품종의 구별이 확실하지 않지만, petal필드들의 시각화를 보았을 땐 'setosa'는 확실히 구분할 수 있을 것 같고 다른 두 품종도 어느정도 구분은 가능할 것 같다.
- Setosa : petal length 가 2.5보다 작다
- Versicolor : petal length > 2.5 & petal width < 1.6
- Virginica : petal length > 2.5 & petal width > 1.6
대략 이런 식의 구분을 생각해볼 수 있는데
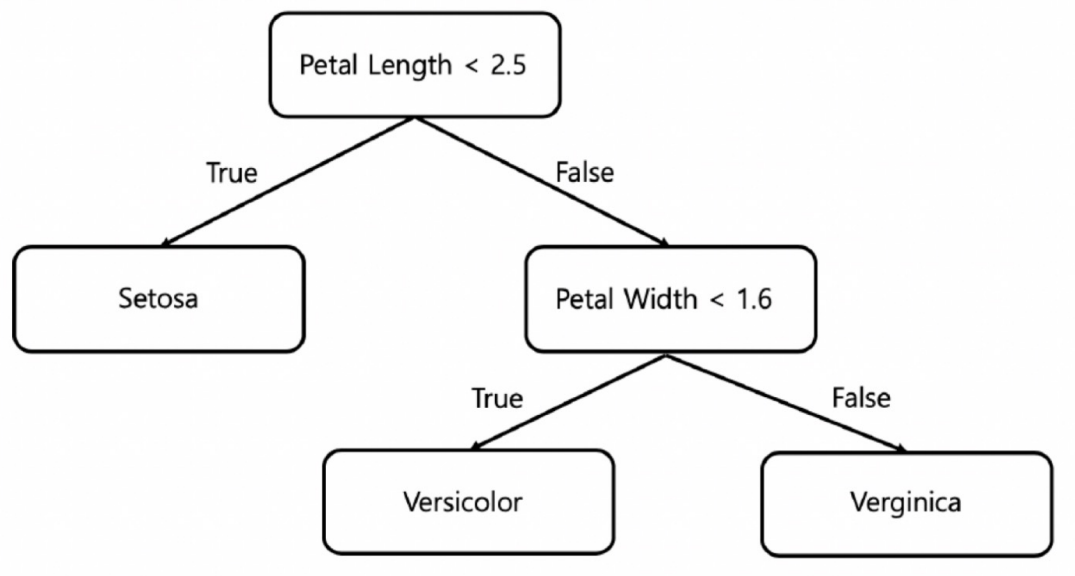
이렇게 표현되는 것을 Decision Tree라고 한다.
그러나 세 품종을 구분하기 전, petal width의 기준값은 어떻게 설정해야 최선일까?에 대한 고민은 더 해봐야할 것 같다.
Decision Tree
조건에 따라 분류되는 방식으로, 사람이 인식하기에 제일 직관적이다. 그리고 앙상블 기법들의 기초가 Decision Tree이므로 중요한 기초이기도 하다.
이전부터 우리의 고민은 'petal width의 기준값은 어떻게 설정해야 최선일까?' 이다.
우리는 분할기준(Split Criterion)을 통해 이 값을 설정할 수 있다.
분할기준에는 엔트로피, 지니계수 등이 있는데 자세한 기초적인 내용은 🖱️ 이 링크를 참고해보고
그래서 저들을 어떻게 이용하면 되는지에 대해 얘기해보겠다.
우리는 분할기준의 값이 최소가 되는 값을 petal width의 기준값으로 설정하면 된다.
그리고 "딱 봐도 그 값이 최선인 것 같아서 정했어요."가 아닌,
"엔트로피/지니계수를 통해 계산해본 결과 그 기준값이 최소값으로 나와 선택하게 되었습니다."라고 수치적인 근거를 내세워 데이터분석의 신뢰성을 높일 수 있다.
이전에는 기준값이 되고자 하는 범위의 모든 값들을 집어넣어 일일이 분할기준을 계산했었는데, Frame Work를 만나며 직접 코딩을 하지 않아도 계산할 수 있게 발전되었다.
scikit learn
직접 코딩을 하지 않아도 계산할 수 있는 수많은 Frame Work 중 scikit learn이 대표적이다.
scikit learn으로 iris 데이터를 학습시키고 예측시켜보자.
- DecisionTreeClassifier 학습기 생성
from sklearn.tree import DecisionTreeClassifier
iris_tree = DecisionTreeClassifier() # 괄호 안에 들어갈 옵션들과 하이퍼파라미터들이 많지만 지금은 생략- 학습시키기
.fit(학습시킬 데이터, 정답지)
# petal의 특성만 봐도 되니, petal 필드만 추출해서 학습시켜보자.
# .fit(학습시킬 데이터, 정답지)
iris_tree.fit(iris.data[:, 2:], iris.target)- 예측시키기
.predict(예측시킬 데이터)
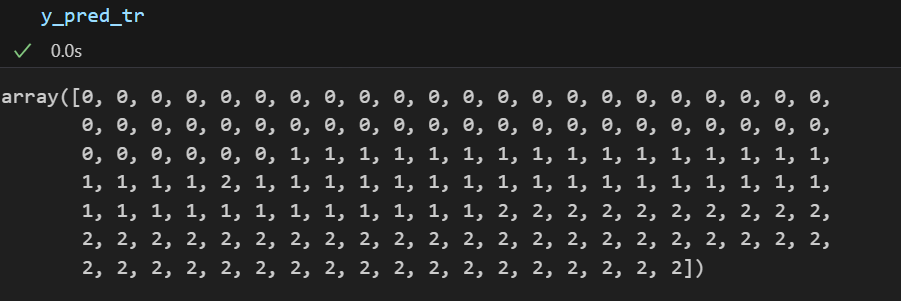
# 학습이 잘 되었는지 데이터를 다시 주고 예측시켜보자
# .predict(예측시킬 데이터)
y_pred_tr = iris_tree.predict(iris.data[:,2:])
y_pred_tr💻 출력
- 성능 평가하기
accuracy_score(실제값, 예측값)
# 정답률 추출
# accuracy_score(실제값, 예측값)
from sklearn.metrics import accuracy_score
accuracy_score(iris.target, y_pred_tr)💻 출력
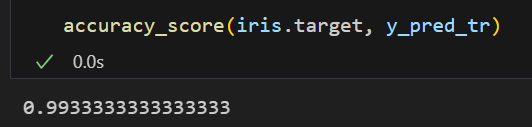
99%의 정답률을 갖는 학습기를 만들어냈다!
데이터 나누기
과적합(Overfitting)
우리가 지금까지 한 학습은 <지도 학습>에 속한다.
지도학습은 학습 대상이 되는 데이터에 정답을 붙여서 학습시키고 모델을 얻어서 완전히 새로운 데이터에 모델을 사용해서 답을 얻고자하는 학습을 말한다.
앞서 만든 모델을 좀 더 살펴보자.
# 학습된 모델을 시각화하여 확인할 수 있음
from sklearn.tree import plot_tree
plt.figure(figsize=(12,8))
plot_tree(iris_tree, filled= True)#!pip install mlxtend
# 학습기의 경계면을 그려줌
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(14,8))
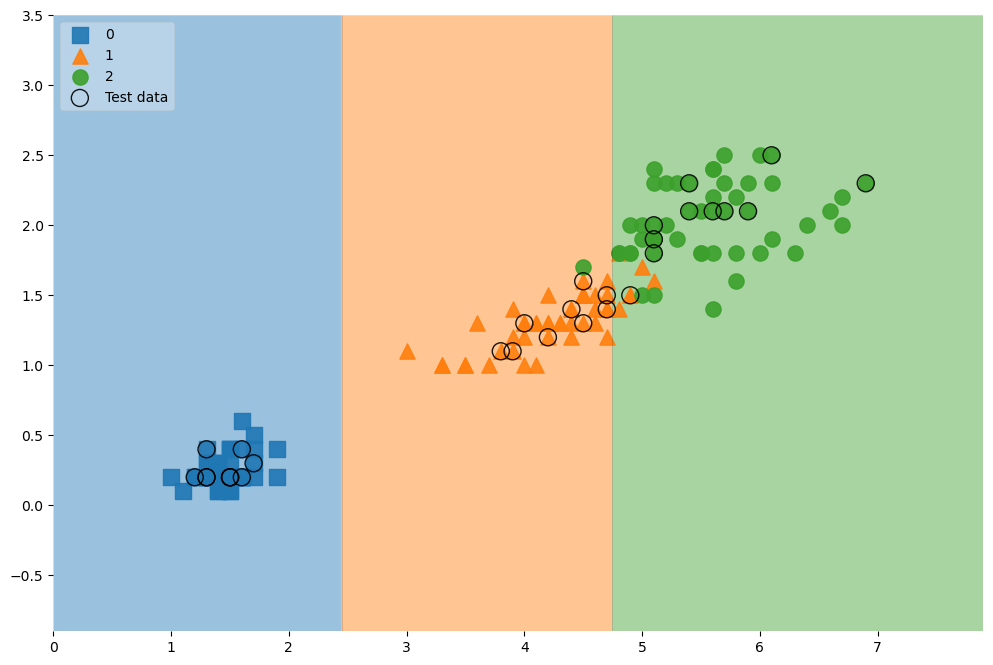
plot_decision_regions(X = iris.data[:,2:], y = iris.target, clf = iris_tree, legend =2)
plt.show()💻 출력
plot_tree
plot_decision_regions
위 코드를 통해 Decision Tree가 나눠진 기준과 경계면을 시각적으로 확인할 수 있다. 이때 Versicolor와 Virginica을 구분하기 위해 경계선이 복잡한 것을 볼 수 있는데 이 덕분에 99%의 정확도가 높은 모델이 만들어진 것이다.
하지만, 지금 가진 데이터가 이 세상의 모든 iris 데이터를 표현할 수 있을까?
만약 복잡한 경계선을 만들어낸 저 데이터들이 돌연변이였다면 위 모델은 성능이 나빠질 것이다.
즉 이렇듯 지도학습 모델에서의 복잡한 경계면은 오히려 모델의 성능을 나쁘게 만든다.
이렇게 내가 지금 가진 데이터에 너무 딱 맞게 모델을 만드는 것을 <과적합>이라 한다.
데이터 나누기
그럼 과적합을 방지하기 위해선 어떻게 해야할까?
바로 가지고 있는 데이터를 훈련용 / (검증용) / 평가용 데이터로 구분지어 사용하는 것이다.
보통 훈련용(8)/평가용(2) 또는 훈련용(7)/평가용(3) 정도의 비율을 많이 쓴다.
그럼 데이터를 나눈 후 다시 학습시켜보자.
# 학습에 이용할 데이터 준비
iris = load_iris()
features = iris.data[:, 2:]
labels = iris.target# 데이터 나누기
# train_test_split(데이터, 타켓 데이터, test_size = 테스트용 데이터 비중, random_state = 난수)
# random_state : 호출할 때마다 동일한 학습/테스트용 데이터 세트를 생성하기 위해 주어지는 난수 값
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=13)데이터를 나누었다면 X_train.shape, X_test.shape를 통해 데이터의 수를 확인할 수 있다.
데이터를 나눌 때 꼭 확인해야할 것이 있는데 좀 더 효과적인 학습과 검증을 위해 타겟 데이터의 클래스 비중을 맞춰 나눠주는 것이 중요하다.
np.unique(y_test, return_counts=True) 를 통해 클래스별 비중을 확인할 수 있고
데이터를 나눌 때 고른 비중으로 나눠주는 옵션 중 하나가 stratify이다.
X_train, X_test, y_train, y_test = train_test_split(features, labels,
test_size=0.2,
stratify=labels,
random_state=13
)이제 Train 데이터를 대상으로 다시 모델을 만들어보자.
# Decision Tree 의 과적합을 방지하기 위한 옵션
# max_depth : 가지의 깊이를 결정(숫자가 작을수록 모델이 단순해짐)
from sklearn.tree import DecisionTreeClassifier
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
iris_tree.fit(X_train, y_train)학습기를 만들 때 과적합을 방지하기 위한 또 다른 옵션이 있는데,
바로 max_depth이다. 이는 Decision Tree의 최대 가지수를 결정하며 숫자가 작을수록 모델이 단순해진다.
# 위 모델을 Test 데이터를 넣어 예측시켜보자
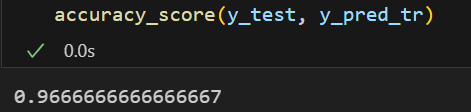
y_pred_tr = iris_tree.predict(X_test)
accuracy_score(y_test, y_pred_tr)💻 출력
 |  |
|---|
모델이 훨씬 단순해졌다.
지금까지는 'petal'필드만 사용했는데, feature 4개를 모두 사용해보면 어떨까?
# 데이터 준비
features = iris.data
labels = iris.target
# 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(features, labels , test_size=0.2,
stratify=labels, random_state=13)
# 학습기 생성
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
# 학습
iris_tree.fit(X_train, y_train)
# 예측
y_pred_tr = iris_tree.predict(X_test)
# 평가
accuracy_score(y_test, y_pred_tr)4가지 feature를 모두 사용했지만

그래도 petal 필드를 주로 사용한 것을 볼 수 있다.
이렇게 학습시킨 모델은 아래와 같이 사용할 수 있다.
test_data = [[4.3,2.,1.2,1.]]-
새로운 데이터의 예측값 확인
모델명.predict(새로운 데이터): 해당하는 클래스 번호 반환
데이터프레임명.target_names[모델명.predict(새로운 데이터)]: 해당하는 클래스명 반환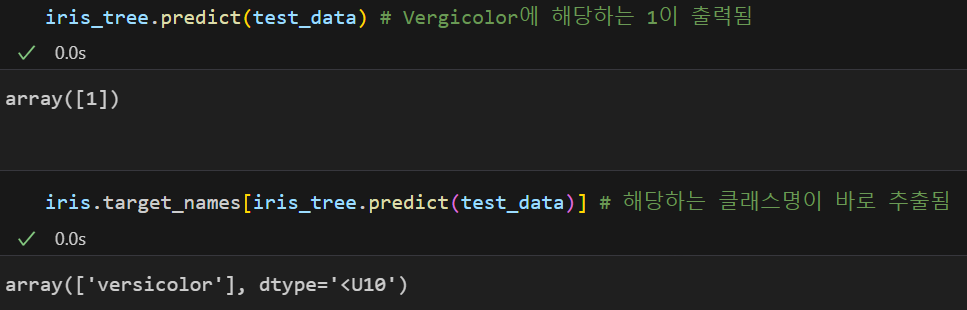
-
새로운 데이터가 각 클래스에 해당할 확률
모델명. predict_proba(새로운 데이터)

zip과 언패킹
모델을 결정하는데 필요한 중요 features은 모델명.features_importances_를 통해 구할 수 있다.
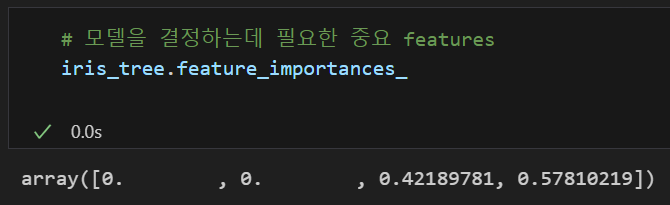
위에서 학습시킨 iris_tree 모델은 3, 4번째 필드가 중요하게 사용된 것을 볼 수 있다.
이를 좀 더 보기 쉽게 출력되도록 하기 위해 아래와 같은 코드를 작성할 수 있다.
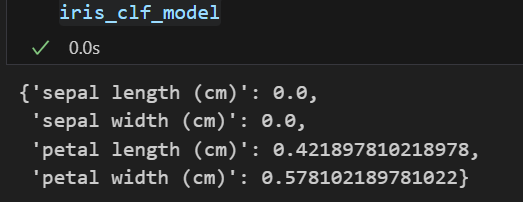
iris_clf_model = dict(zip(iris.feature_names, iris_tree.feature_importances_))
iris_clf_model💻 출력
dict(zip(리스트 1, 리스트2)))
: zip은 두 리스트를 튜플로 엮어주고 dict 를 통해 딕셔너리 형태로 변환시켜준다.
엮어준 이들을 다시 개개인으로 풀고 싶다면 아래와 같이 언패킹해주면 된다.
변수명1, 변수명2 = zip(*zip(리스트 1, 리스트2))
# 튜플 형태로 반환되므로 리스트 형태로 반환하고 싶다면 list() 해줄 것
list(변수명1), list(변수명2)타이타닉 생존자 예측
과연 디카프리오가 실존 인물이었다면 생존율은 얼마나 될까?
에 대한 답변을 내릴 수 있는 모델을 생성해보자.
타이타닉 데이터는 🖱️ 깃허브 링크를 통해 읽어들였다.
import pandas as pd
titanic_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/titanic.xls'
titanic = pd.read_excel(titanic_url)컬럼의 의미
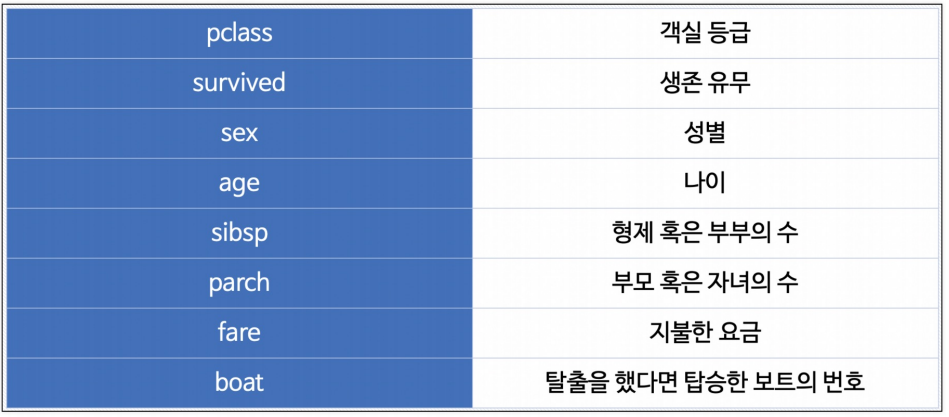
EDA
먼저, 생존 상황에 대한 시각화를 해보자.
import matplotlib.pyplot as plt
import seaborn as sns
f, ax = plt.subplots(1,2, figsize = (16,8))
#첫번째 차트
titanic['survived'].value_counts().plot.pie(ax = ax[0], # 첫번째 필드에 pi차트를 그려라
autopct = '%1.1f',# 비율
shadow = True, # 그림자
explode = [0,0.05] # pie가 떨어질 크기
)
ax[0].set_title('Pie plot - Survived')
ax[0].set_ylabel('')
#두번째 차트
sns.countplot(x = 'survived', data = titanic, ax = ax[1])
ax[1].set_title('Count plot - Survived')
plt.show()💻 출력
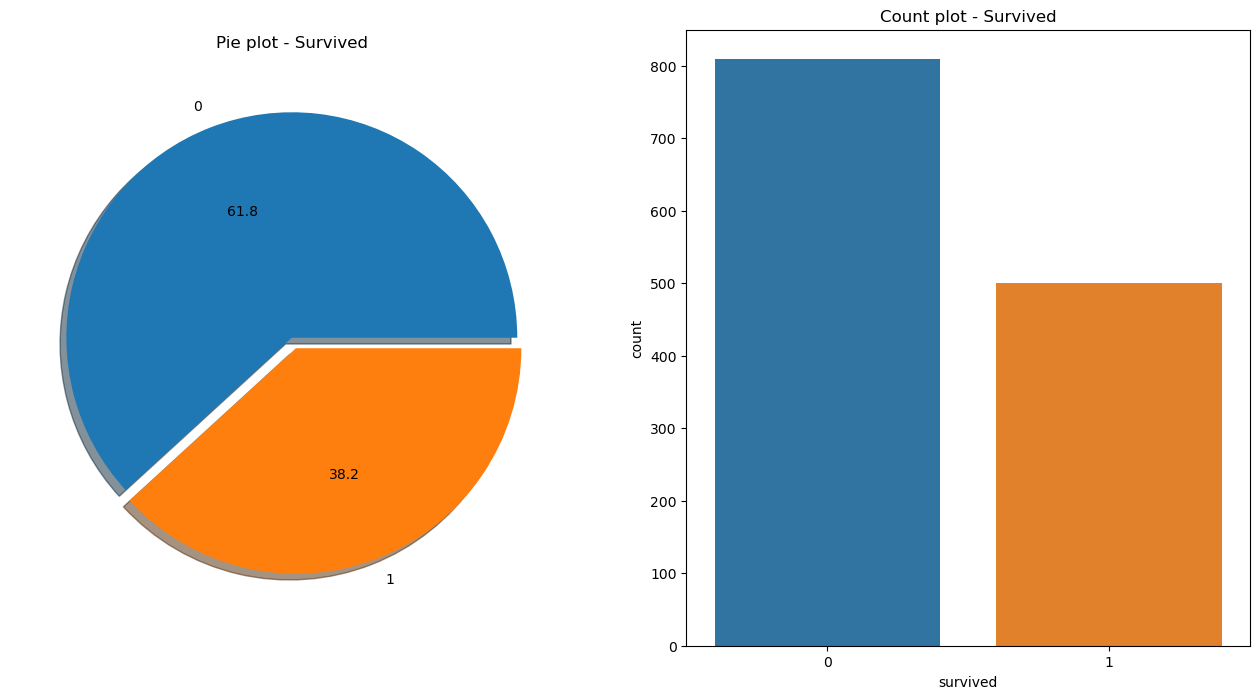
위 차트를 보아, 800명에 가까운(61.8%) 사람들이 생존하지 못한 것으로 보인다.
sex vs survived
혹시 성별(sex)과 관련이 있을까?
f, ax = plt.subplots(1,2, figsize = (16,8))
#첫번째 차트
sns.countplot(x = 'sex', data = titanic, ax = ax[0])
ax[0].set_title('Count of passengers of sex')
ax[0].set_ylabel('')
#두번째 차트
sns.countplot(x = 'sex', data = titanic, hue = 'survived', ax = ax[1])
ax[1].set_title('Sex : survived')
plt.show()💻 출력
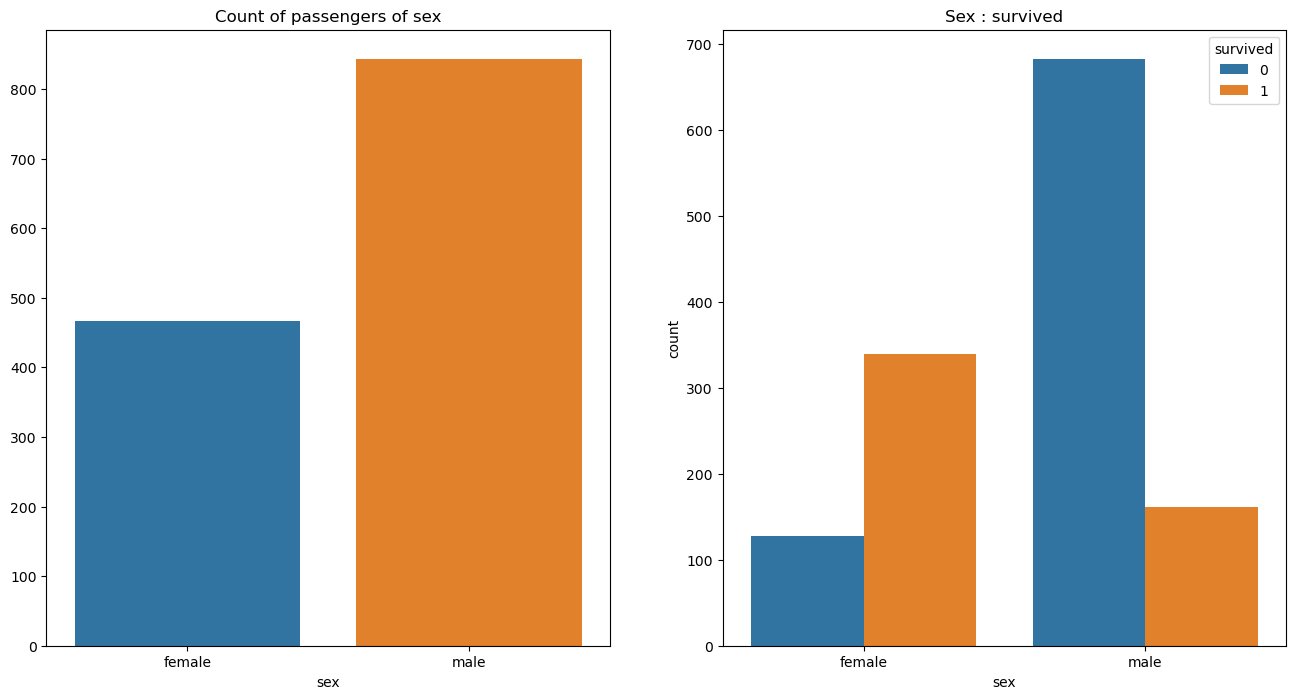
두 그래프의 색상이 같이 헷갈릴 수도 있겠지만,
왼쪽 그래프는 성별에 따른 탑승객들의 수 그래프이고
오른쪽 그래프는 성별에 따른 탑승객들의 생존 상황 그래프이다.
위 그래프에서는 여성보다 남성 탑승객이 많다는 것과
남성의 생존 가능성이 더 낮은 것을 볼 수 있다.
pclass vs survived
그렇다면 객실 등급별(pclass) 생존 상황은 어떠할까?
pd.crosstab(범주형 데이터 1, 범주형 데이터2, margins = True)
를 사용하면 각 범주형 데이터의 개수를 행과 열로 cross해놓은 표를 얻을 수 있다.
# pclass vs survived
pd.crosstab(titanic['pclass'], titanic['survived'], margins = True)💻 출력
이때 margins = True 옵션을 주면 행/열의 소계값을 함께 반환한다.
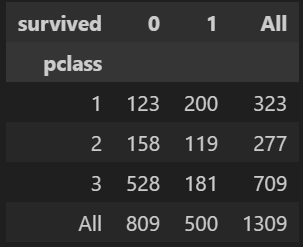
위 crosstab을 보아, 1등실의 생존 가능성이 아주 높은 것으로 보인다. 앞서 여성의 생존 비율이 높았는데, 객실 등급별 성별 비율은 어떻게 될까?
pclass vs sex
FaceGrid는 다양한 범주형 값을 가지는 데이터를 시각화하기 좋은 방법이다. 행, 열 방향으로 서로 다른 조건을 적용하여 여러 개의 서브 플롯을 제작해주는데 이를 통해 객실 등급 및 나이별 성별 분포를 살펴보자.
# 객실 등급 및 나이별 성별 분포
grid = sns.FacetGrid(titanic, row = 'pclass', col = 'sex', height = 4, aspect = 2)
grid.map(plt.hist, 'age', alpha = 0.8, bins = 20)
grid.add_legend()💻 출력
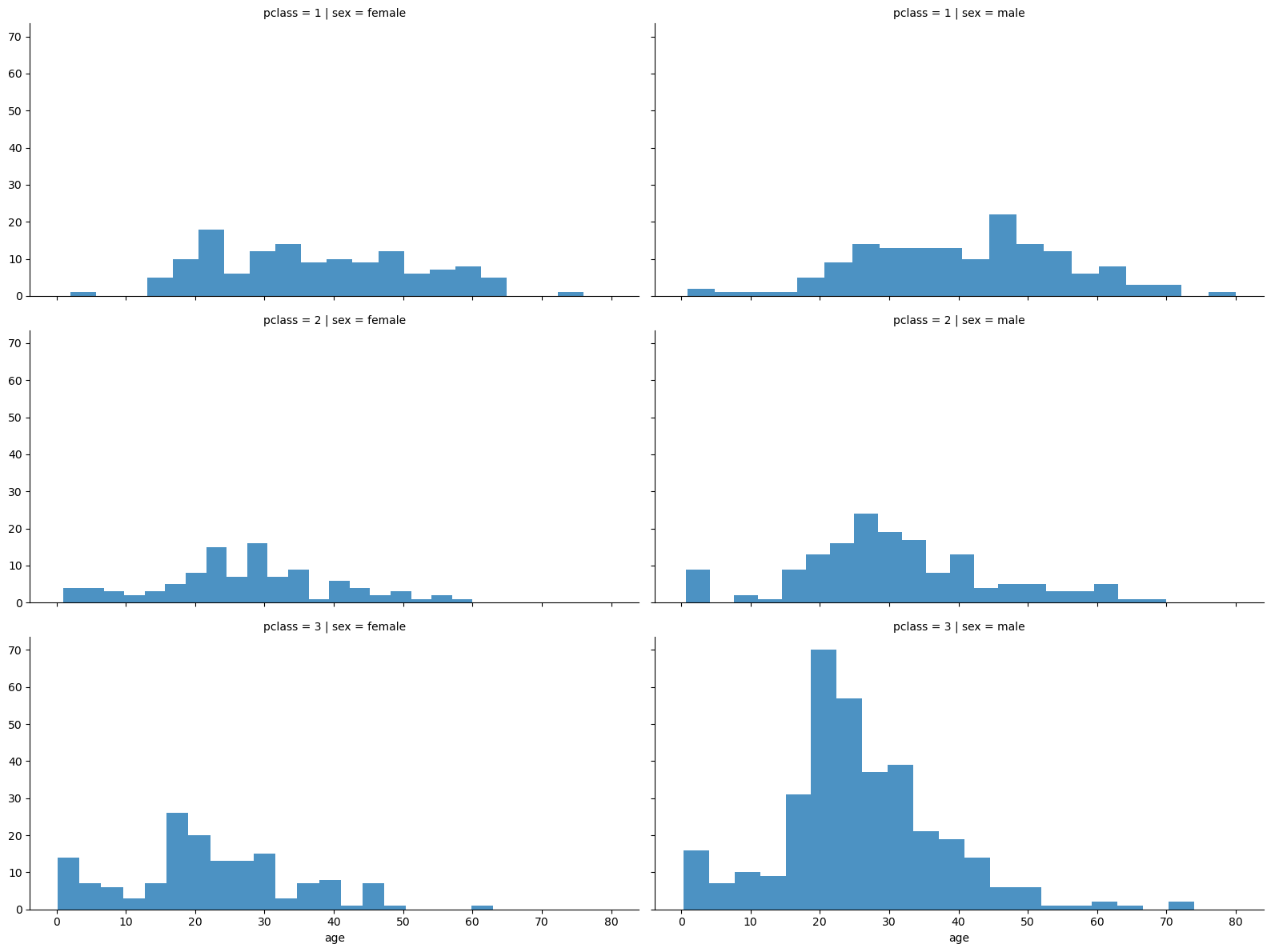
연령별 데이터가 비교적 고르게 분포해있는데 특이하게 3등실에는 20대 남성의 분포가 많은 것을 볼 수 있다.
그렇다면 연령별 탑승 현황이 어떠할까?
age
#!pip install plotly_express
import plotly.express as ps # 마우스오버하면 해당 데이터의 내용을 보여주는 효과가 있음이번에는 다른 그래프 도구를 사용해보자.
plotly.express는 그래프 위에 마우스 오버하면 해당 데이터의 내용을 보여주는 효과가 있다.
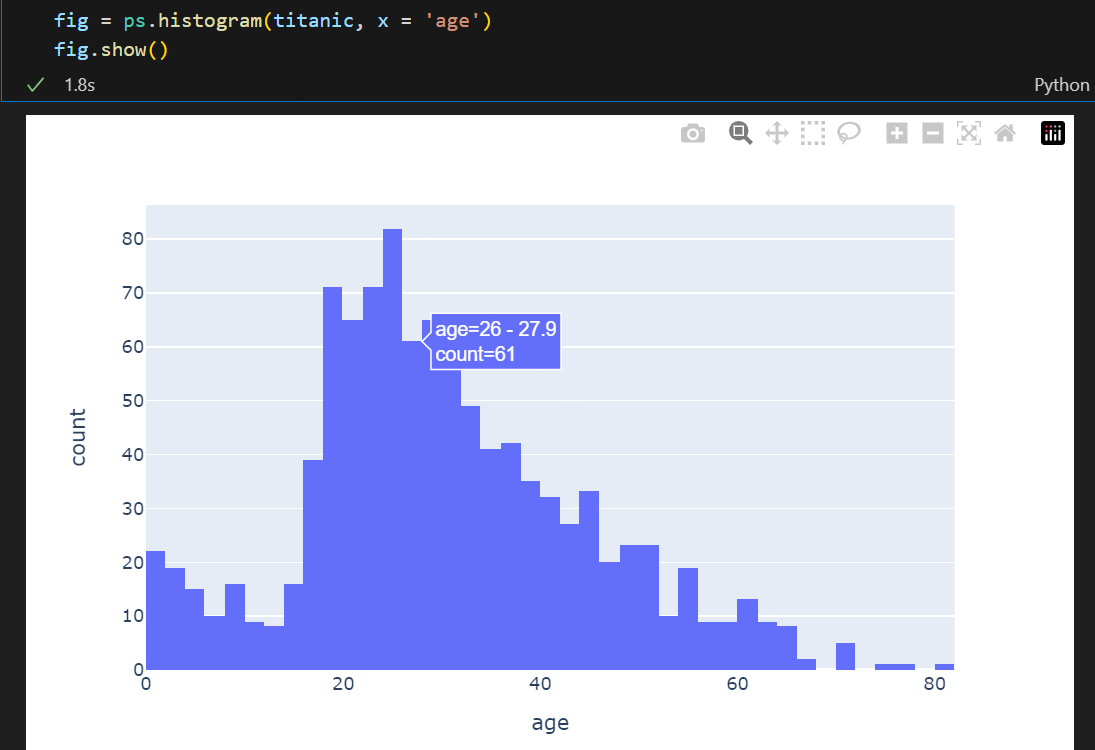
위 사진처럼 데이터의 결과를 보여주는데,
이 그래프에서도 20 - 30대의 사람들이 많이 탑승한 것을 알 수 있다.
이어서 등실별 생존 현황을 살펴보자.
pclass vs survived
grid = sns.FacetGrid(titanic, row = 'pclass', col='survived', height = 4, aspect = 2)
grid.map(plt.hist, 'age', alpha = 0.8, bins = 20)
grid.add_legend()💻 출력
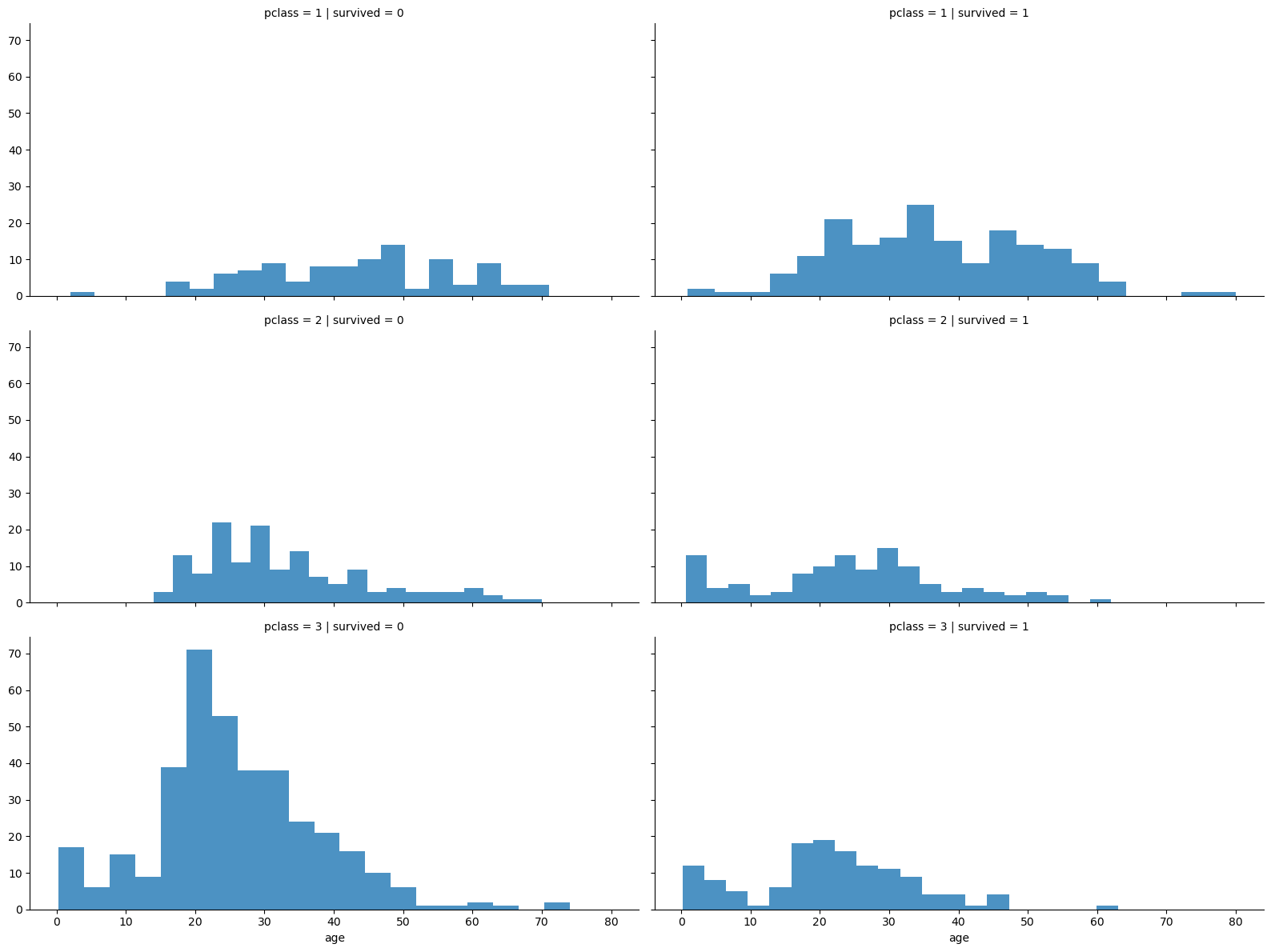
1, 2등실 승객들은 생존 상황이 비교적 고르게 분포되어있는 반면,
3등실은 20-30대 승객들이 대부분 살아남지 못한 것으로 보인다.
지금까지 본 내용을 정리하자면,
생존 상황과 연령, 등실이 관련있어 보인다.
연령을 카테고리화하여 좀 더 들여다보자.
연령 카테고리화
pd.cut(카테고리화 할 데이터, bins = [범위], labels = [라벨링할 이름들])
# 범위를 지정하여 라벨링할 수 있는 기능
titanic['age_cat'] = pd.cut(titanic['age'], bins = [0,7,15,30,60,100],
include_lowest=True, labels=['baby', 'teen', 'young', 'adult', 'old'])💻 출력
임의로 정한 연령 범위가 카테고리화되었다.
그러면 다시 한 번 객실, 카테고리화된 연령, 성별에 따른 생존률을 한 번 살펴보자.
pclass, age_cat, sex 별 생존율
plt.figure(figsize=(12,4))
# 객실별 생존율
plt.subplot(131) # 1행 3열 중 첫 번째
sns.barplot(x = 'pclass', y = 'survived', data = titanic)
# age_cat별 생존율
plt.subplot(132) # 1행 3열 중 두 번째
sns.barplot(x = 'age_cat', y = 'survived', data = titanic)
# 성별 생존율
plt.subplot(133) # 1행 3열 중 세 번째
sns.barplot(x = 'sex', y = 'survived', data = titanic)
plt.show()💻 출력
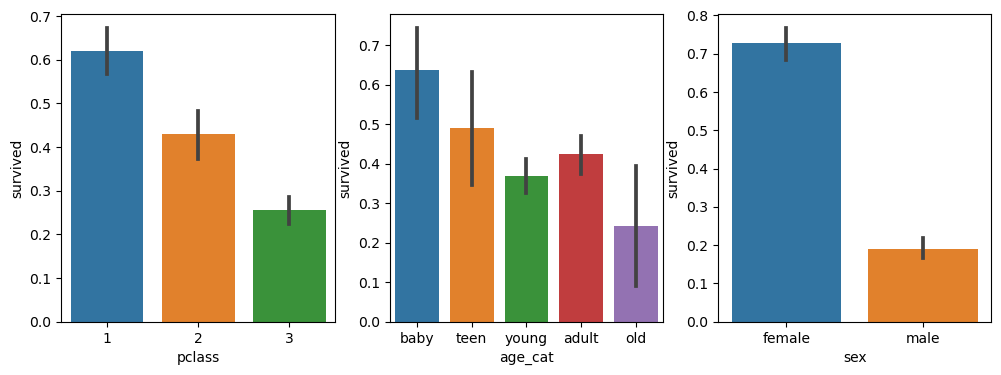
survived 필드는 사망이 0, 생존이 1로 표기되고 있다.

또한, barplot의 기본 측정값은 <평균>이므로 해당 차트 y축이 1에 가까울수록 생존율이 높고 반대로 0에 가까울수록 생존율이 낮다고 보면 된다.
그렇다면 위 그래프를 보아
1등실에 탑승하며, 나이가 어리고 여성일수록 생존하기 유리했다고 말할 수 있을까?
성별 및 나이별 생존 상황을 다시 한 번 살펴보자.
sex, age_cat 별 생존율
fig, axes = plt.subplots(nrows = 1, ncols = 2, figsize = (14,6))
women = titanic[titanic['sex'] == 'female']
men = titanic[titanic['sex'] == 'male']
# 여성
ax = sns.distplot(women[women['survived'] == 1]['age'], bins = 20, label = 'survived', ax = axes[0], kde = False)
ax = sns.distplot(women[women['survived'] == 0]['age'], bins = 40, label = 'not_survived', ax = axes[0], kde = False)
ax.legend()
ax.set_title("Female")
# 남성
ax = sns.distplot(men[men['survived'] == 1]['age'], bins = 20, label = 'survived', ax = axes[1], kde = False)
ax = sns.distplot(men[men['survived'] == 0]['age'], bins = 40, label = 'not_survived', ax = axes[1], kde = False)
ax.legend()
ax.set_title("Male")💻 출력
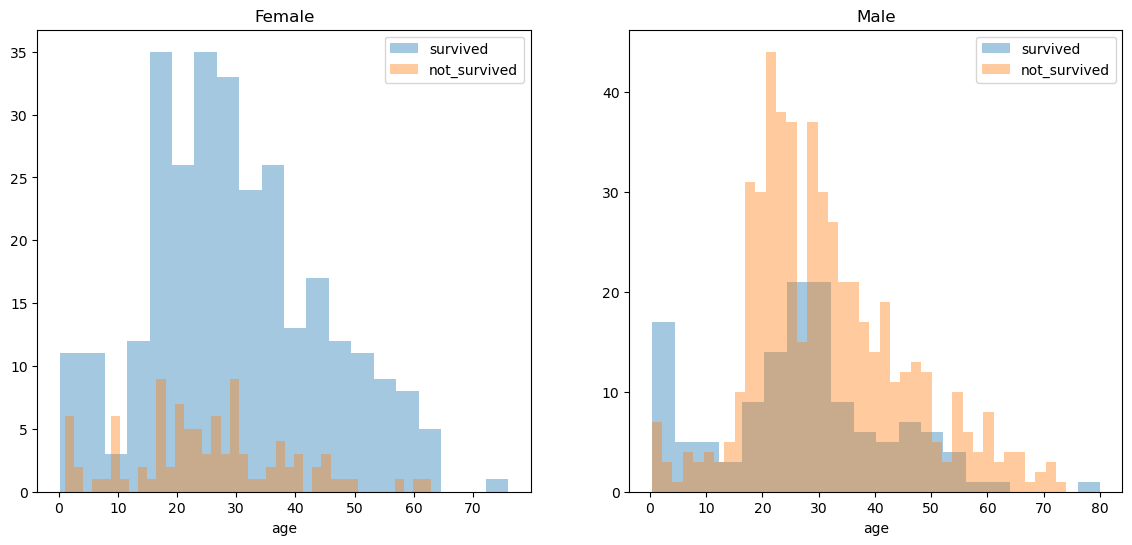
20-30대만 보았을 때 여성은 대부분 살아남은 반면, 남성은 그렇지 않은 것을 볼 수 있다.
그리고 특이하게 이 데이터에서 탑승객 이름('name') 필드를 통해 신분을 알아낼 수 있다.
for idx, dataset in titanic.iterrows():
print(dataset['name'])
# '성, 사회적신분. 이름' 형태로 출력되고 있음💻 출력

name 필드 데이터들이 '성, 사회적신분. 이름' 형태처럼 보인다.
여기서 가운데 부분만 쇽-! 추출해서 title(신분) 필드로 만들어보자.
## 정규표현식 이용
import re
title = []
for idx, dataset in titanic.iterrows():
tmp = dataset['name']
title.append(re.search('\,\s\w+(\s\w+)?\.', tmp).group()[2:-1])
## 문자열 나누기 이용
# data = []
# for idx, dataset in titanic.iterrows():
# tmp = dataset['name']
# data.append(tmp.split(' ')[1][:-1])
titanic['title'] = title title 데이터 title 데이터 |  데이터프레임에 title 필드 추가 데이터프레임에 title 필드 추가 |
|---|
강의에서는 정규표현식을 이용했는데 나는 아직도 정규표현식이 익숙하지 않다 😭 얼른 익숙해져야할텐데....
여튼..! 문자열 나누기를 이용해서도 데이터를 추출할 수 있어서 한 번 코드를 끄적여보았다.
이렇게 만들어진 데이터프레임을 이용해 사회적신분에 따른 생존 상황도 살펴보자.
title vs survived
먼저 사회적 신분의 범위가 너무 많으니, 좀 줄여보았다.
# 잘 모르는 title도 있으니 새로 값을 만들어주자
titanic['title'] = titanic['title'].replace('Mlle', 'Miss')
titanic['title'] = titanic['title'].replace('Ms', 'Miss')
titanic['title'] = titanic['title'].replace('Mme', 'Mrs')
Rare_f = ['Dona', 'Lady', 'the Countess'] # 귀족 여성
Rare_m = ['Capt', 'Col', 'Don', 'Major', 'Rev', 'Sir', 'Dr', 'Master', 'Jonkheer'] # 귀족 남성
for each in Rare_f:
titanic['title'] = titanic['title'].replace(each, 'Rare_f')
for each in Rare_m:
titanic['title'] = titanic['title'].replace(each, 'Rare_m')💻 출력

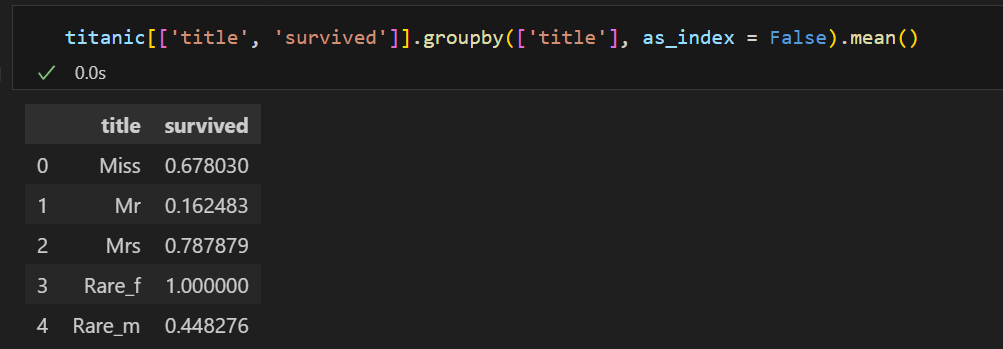
사회적 신분에 따른 생존율을 살펴보면
평민 남성(Mr) < 귀족 남성(Rare_m) < 평민 여성(Miss, Mrs) < 귀족 여성(Rare_f) 순으로 생존율이 높아보인다.
지금까지의 EDA를 통해 생존 상황과 관련된 컬럼인 'pclass', 'age', 'sibsp', 'parch', 'fare', 'gender'을 사용해서 생존 상황을 예측해볼 수 있을 것 같다.
머신러닝을 이용한 생존자 예측
모델 만들기 전 사전 점검
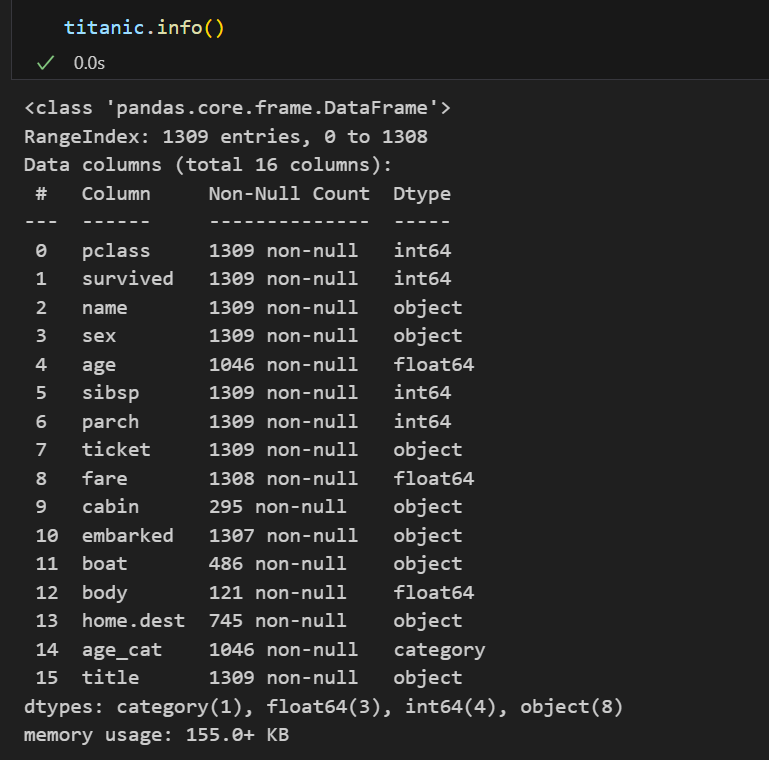
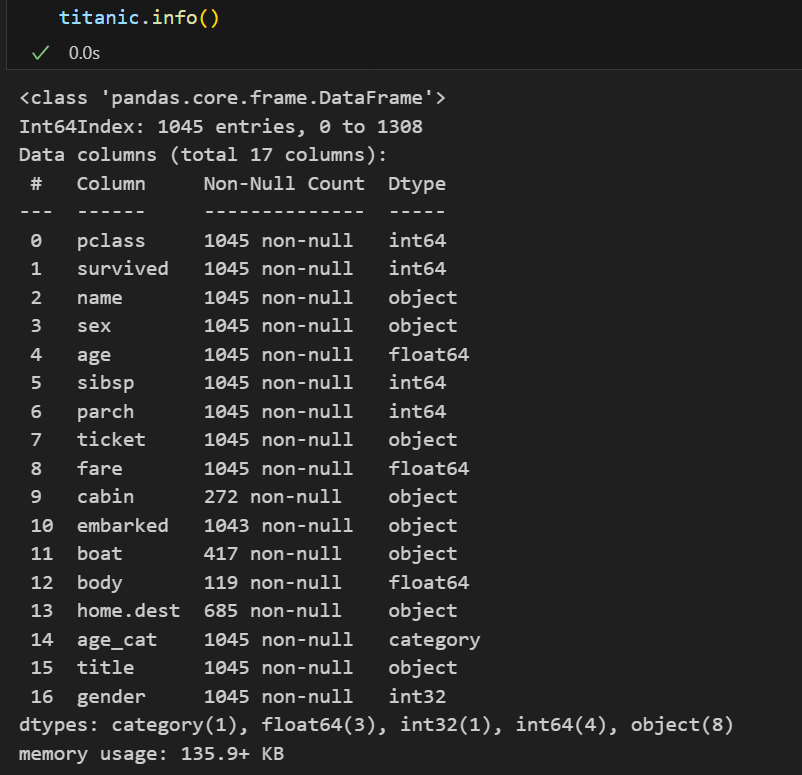
📌 데이터 타입 확인
먼저 학습을 시키기 위해선 사용할 데이터가 모두 숫자 형태여야한다.
사용할 필드 중 sex필드만 숫자 형태가 아니니 숫자 형태로 변경해보자.
데이터 타입을 변환해주는 많은 도구가 있는데 그 중 Label Encoder를 사용해볼 것이다.
# Label Encoder를 통해 문자열을 숫자로 바꿔보자.
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder() # 문자열을 숫자로 변환시켜주는 도구
le.fit(titanic['sex']) # 변환시킬 데이터 fit
titanic['gender'] = le.transform(titanic['sex']) # 데이터 변환💻 출력
그러면 sex필드가 숫자 형태로 변환된 gender 필드가 생성된다.
📌 결측치 확인
그리고 또 하나, 결측치를 처리해주어야 한다.
결측치를 처리하는 방법은 다양하지만 지금은 그냥 결측치가 있는 행은 삭제하고 진행했다.
titanic = titanic[titanic['age'].notnull()]
titanic = titanic[titanic['fare'].notnull()]💻 출력
모델링
# 모델에 사용할 데이터 추출 및 과적합 방지를 위한 데이터 분리
from sklearn.model_selection import train_test_split
X = titanic[['pclass', 'age', 'sibsp', 'parch', 'fare', 'gender']]
y = titanic['survived']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
# 모델 학습기 생성 및 학습
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
dt = DecisionTreeClassifier(max_depth=4, random_state=13)
dt.fit(X_train, y_train)
# 예측 및 성능 검사
pred = dt.predict(X_test)
accuracy_score(y_test, pred)💻 출력
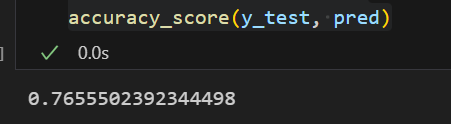
앞서 과적합 방지를 위해 데이터를 분리하고 모델을 학습시키고 예측하여 성능을 평가한 방식을 적용하면 타이타닉 데이터에서 DecisionTree 모델의 성능은 76% 정도가 나왔다.
(물론 다른 옵션들을 적용하지 않은 상태지만 😊 )
타이타닉의 생존율을 예측하는 모델을 생성했다면
우리의 ❓sub question이었던
디카프리오가 실존인물이었다면 그는 살아남을 수 있었을까?
에 대한 질문의 답을 구해볼 차례이다.
모델에 데이터를 집어넣기 위해
디카프리오라는 인물의 데이터를 특정지어야한다.
모델에 입력되어야하는 필드는 ['pclass', 'age', 'sibsp', 'parch', 'fare', 'gender'] 이니,
영화 줄거리를 통해 예상되는 디카프리오의 데이터를 특정짓고 모델에 집어넣으면 아래와 같은 결과를 얻을 수 있다.
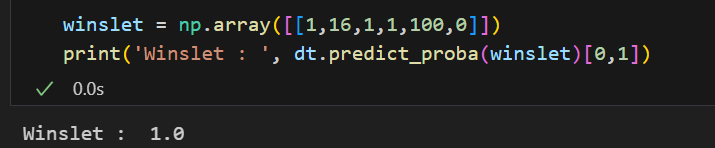
import numpy as np
dicaprio = np.array([[3 ,18 ,0 ,0 ,5 , 1]]) # 디카프리오의 데이터를 특정 짓기
print('Dicaprio : ', dt.predict_proba(dicaprio)[0,1])
# dt.predict_proba(dicaprio) 는 생존X 확률과 생존 확률을 모두 보여주므로
# 생존 확률만 추출하려면 [0,1]을 해주어야한다.💻 출력

우리가 만든 모델에 대해서 디카프리오는 16% 확률로 살아남을 수 있다.
반면, 여주인공의 데이터도 특정지어 모델을 돌려보면 아래와 같은 결과를 얻을 수 있다.