
실제로 Entity Resolution을 할 때 사용하는 test, train set이 같은 도메인일 확률이 적기 때문에 cross-domain ER 문제를 LLM의 in-context learning 방식으로 해결하는 방법에 대해서 설명하는 논문이다. 논문에서는 새로운 프레임워크인 CiDER를 제안한다.
1️⃣ Introduction
Entity Resolution(Matching)은 동일한 의미를 갖지만 서로 다른 데이터 소스에서 다르게 표현된 entity를 인식하는 과정을 의미한다. 이 작업은 도메인과 관계없이 데이터 통합이 필요한 다양한 상황에서 중요하다. 일반적으로 ER에 많이 사용되는 기법은 DL 기반의 기법이나 BERT와 같이 사전 학습된 모델을 사용한 분류 방식이다. 이때 traning set을 통해서 학습한 모델을 평가하기 위한 test set은 동일한 도메인을 사용한다. 아래 이미지를 보면, 좌측의 Training data와 Testing data의 General ER인 경우는 동일한 속성(Pair, Title, Category, Modelno, Brand, Price)을 사용하고 있다.
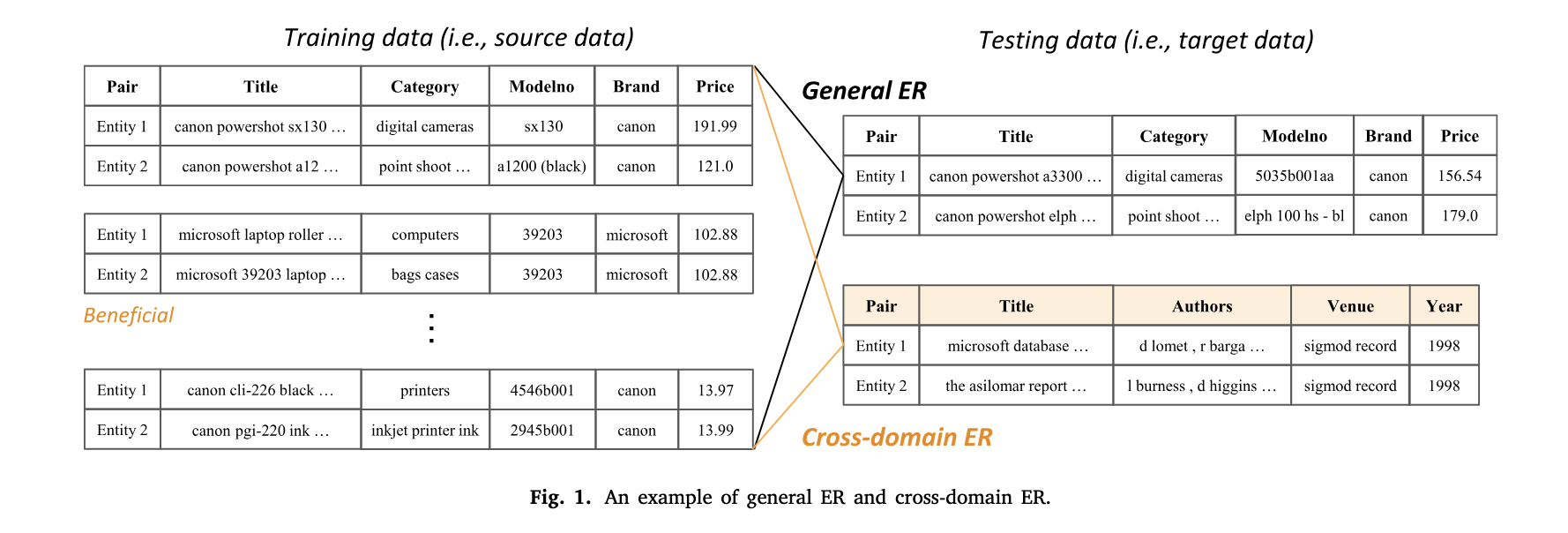
그러나, 현실 세계에서는 이 두 데이터의 도메인이 다른 경우가 많다. 위 이미지의 Cross-domain ER 의 Testing data와 같이 전혀 다른 속성(학술 인용 관련 도메인)을 사용한 데이터를 사용한다는 것이다.
Cross domain ER의 챌린지 중 하나는 domain shift(source;train와 target;test 데이터의 분포, 특성의 차이가 있기 때문)이다. 이를 해결 하기 위한 솔루션으로 feature extractor, matcher, feature aligner 등과 같이 두 도메인 간의 특징 차이를 줄이거나 매칭하기 위한 방법이 제안되었지만, 추가적인 계산 자원이 필요하거나 효과적인 fine-tuning 을 진행해야 한다는 한계가 있었다.
최근 LLM을 활용하면 앞서 DL등의 모델을 학습하는데 사용되는 막대한 훈련 비용을 완화할 수 있다. 즉, 특정 도메인을 위한 학습에 초점을 두는 것이 아닌, 프롬프트를 통한 in-context learning에 집중하면 된다는 것이다. 그러나, 이 방식에도 한계가 있는데 (1) 훈련 데이터의 예시들이 실제 테스트를 진행할 때 큰 도움이 되지 않을 가능성이 높고(도메인이 다르기 때문에) (2) 의미적, 구조적 유사성만 고려하므로 속성들의 이질성은 기존의 유사도 계산 방식을 적용하기 어렵다(이 부분에서는 속성의 개수가 다른 경우 벡터의 차원이 달라진다는 문제를 제기하는데, 차원은 맞춰줄 수 있는 문제가 아닌가..? 생각했는데 아래에서 추가로 설명한다).
따라서 본 연구에서는 최초로 In-Context Learning 기반의 Cross-Domain ER 프레임워크인 'CiDER'를 제안한다. CiDER는 이전에 학습된 데이터에서 타겟 데이터를 평가하는데 가장 적합한 후보 데이터를 능동적으로 선택하고, 도메인에 관계 없이 소스 데이터와 타겟 데이터 쌍 간의 유사도를 계산하는 접근법을 고안한다. 또한 CiDER를 기존의 LLM 기반의 방식이나 DL 기반의 SOTA 모델의 결과와도 비교하여 평가한다고 한다.
Traning data, Test data, Source, Target 이라는 용어들이 계속 혼재되고 반복되고 있는데, 의미를 다음 예시를 통해 정리할 수 있다.
- A, B: 현재 판단하려는 개체 쌍 (이것이 매치인지 비매치인지 알고 싶은 대상)
- C, D: 이미 라벨(매치/비매치)을 알고 있는 참조 데이터 (훈련/시연용)
→ Source Domain은 A, B의 도메인을 의미하고 Target Domain은 C, D의 도메인을 의미함
→ C, D가 Training data 될 수 있는데, In-Context Learning에서는 따로 학습을 하는게 아니라 프롬프트 안에 예시로 제시하는 것이므로 참조 데이터 정도로 볼 수 있다.
→ A, B는 Testing data로 볼 수 있다.
2️⃣ Related Work
Entity Resolution
: ER은 데이터 통합 과정에서 가장 기본적으로 쓰이는 방식이고, 일반적으로 BERT와 같은 사전 학습 모델 기반의 fine-tuning을 통한 분류 테스크로 접근되는 경우가 많다. Ditto나 HierGAT와 같은 모델들이 대표적이며, 지식그래프 분야에서도 Entity Alignment라고 불리는 기법이 많이 연구되어 왔다. 그러나 이러한 방법들은 모두 학습을 위한 방대한 양의 데이터가 필요하며, 동일/유사한 도메인 내에서만 효과적인 방법이라는 한계점이 있다.
Cross-Domain Entity Resolution
: Cross-Domain ER은 기존에 라벨링된 특정 도메인 데이터를 활용해서 다른 도메인의 ER 작업도 수행할 수 있도록 하는 방식을 의미한다. 이 작업의 목적은 새로운 대규모 라벨링 데이터를 구축하지 않는 것이다. DADER 프레임워크, KBQA, IR 등과 같은 예시가 존재하는데, 이 방식들 역시 상단한 계산 비용과 최적화를 위한 반복적인 fine-tuning이 필요하다는 한계가 있다.
In-Context Learning for General Entity Resolution
: ICL은 LLM의 발전 이후 다양한 분야에서 성능 향상을 위한 방법 중 하나로 많이 연구 되고 있으며 ER 분야에서도 프롬프팅, Jaccard 유사도를 기반으로 구한 참조데이터를 넣어주기 등의 다양한 시도들이 있었다. 그러나 이 방식들은 휴리스틱하거나(프롬프트를 인간이 계속 조금씩 바꿔가면서 테스트), 여전히 Cross-domain을 고려하지 않은 방법이라고 설명한다.
3️⃣ Preliminary
3.1 Problem formulation
일반적인 ER 파이프라인은 매칭되지 않는 엔티티를 삭제하는 blocking과 일치 여부를 결정하는 matching 두 단계로 구성된다. 매칭과 관련된 부분을 수식으로 내타낼 때 각 변수의 의미는 다음과 같다.
Dˢ: 소스 데이터의 모든 개체 쌍들의 집합Yˢ: 모든 개체 쌍들에 대한 라벨들의 집합(매치, 비매치)Dᵀ:타겟 데이터의 모든 개체 쌍들의 집합Yᵀ:판단해야 하는 라벨 정보(아직 모르는 정보)
즉, Cross-doamin ER은 Dˢ와 Yˢ를 사용해서 Dᵀ의 레이블값인 Yᵀ를 구하는 과정으로 정의된다.
3.2 In-Context learning
ICL의 목적은 LLM의 내부 구조의 조정없이 프롬프트 만으로 성능을 향상하는데 있으며, 유사성을 통해서 학습하는데 핵심 아이디어가 있다. 프롬프트에 질문과 함께 이 질문에 답변하기 위한 예시를 함께 넣어줘서 추론 결과를 얻는 방식을 의미한다. 최근 ICL이 ER 작업에도 효과적이라는 연구가 있는데, 사전에 target 엔티티쌍과 의미론적 혹은 구조적 유사성을 가진 예시 쌍을 가져온 뒤 프롬프트에 넣어주는 방법을 활용한다. 그러나 이 방식은 Cross-domain 분야에서는 적용하기 어렵다는 한계가 있으므로, 해당 연구에서는 이 부분을 완화할 수 있는 ER의 설계를 목표로 한다.
3.3 Model overview
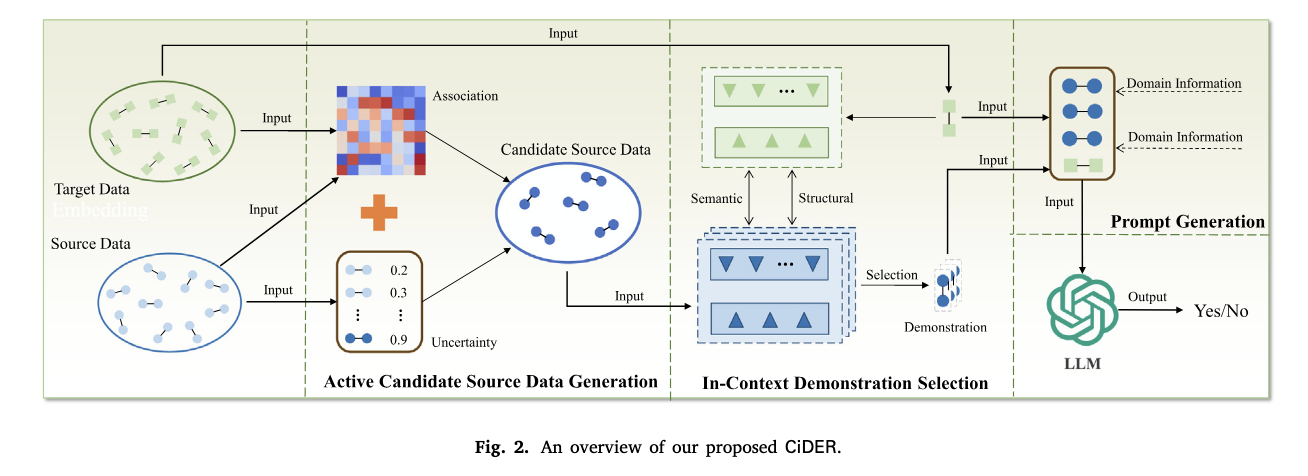
위 그림은 CiDER의 전체 프레임워크를 나타내고, 이는 세 파트로 구성된다.
-
Active Candidate Source Data Generation
Target data와의 관련성을 기반으로 Source data에서 ICL에 참조데이터로 넣어줄 후보 데이터를 선정하는 파트이다. 이를 위해 각 레코드의 불확실성과 연광성을 종합적으로 고려해서 가장 유용한 레코드를 필터링한다. -
In-Context Demonstration Selection
1단계에서 추린 후보 데이터에서 타겟 데이터와의 구조적(structural), 의미적(semantic)을 모두 고려해서 최종 예시(논문에서는 demo라고 표현)를 선택한다. -
Prompt Generation
사전에 정의한 포맷에 2단에서 선정한 정보를 넣어주고 LLM의 답변을 도출하는 과정이다.
4️⃣ Methodology
CiDER의 세 파트의 방법론을 하나씩 살펴보겠다.
4.1 Active candidate source data generation
모든 Source data가 Target data의 추론 과정에 유용한 것은 아니므로 후보 데이터를 필터링해서 추리는 과정이 필요함을 설명한다. 후보 데이터를 선정하는 방법은 AL(Active Learning)에 기반을 두고 있으며, 참고한 선행연구가 있다고 한다. 구현 방법은 AL의 고전적인 쿼리 전략인 '불확실성 샘플링'을 단일 반복 문제로 사용하는 것을 공식화했다고 하는데, 구체적인 내용은 아래에서 다룬다.
4.1.1 Uncertainty sampling
불확실성 샘플링을 위한 일반적인 전략은 confident(확실성이 낮은 것을 선택), margin sampling(두 분류의 마진이 작을수록 분류가 불확실함)이 낮은 것과, 엔트로피(불확실성의 정도)가 높은 것을 선택하는 것이다. 엔트로피는 다음과 같은 수식으로 계산되며, 이때 v는 엔티티쌍 (A, B)의 벡터값이고 P(1|v)는 두 엔티티의 일치 확률(P(0|v) = 1 − P (1|v))이다. 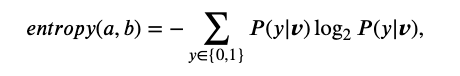
y=1(매칭), y=0(비매칭)인 이진 분류 상황일때, P(1|v)는 매칭확률이고, P(0|v)는 비매칭 확률로 표현된다. 따라서 엔트로피 계산은 entropy = -P(1|v)×log₂P(1|v) - P(0|v)×log₂P(0|v)와 같이 할 수 있고 매칭, 비매칭 확률값을 대입하여 계산할 수 있다. 엔트로피는 1에 가까울수록 더 불확실하고 0에 가까울 수록 확실한 예측을 의미한다.
레코드의 일치 확률P를 계산하기 위해서 우선 Source data를 K 폴드로 균등하게 나눈다(데이터를 K개로 분할한다는 의미). 이후 각 폴드에서 Naive Bayes(P(1|v) = P(v|1) × P(1) / P(v))를 활용해서 분류기 F를 만들며(Ki가 있을 때 이를 제외한 K-1개의 폴더 데이터를 학습데이터로 사용한뒤 Ki의 매칭 확률을 예측하는 것) 매칭되는 확률에 대한 수식은 다음과 같다.
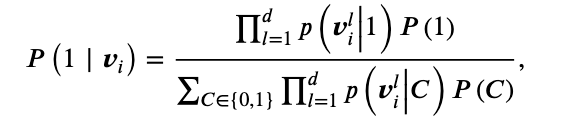
분자에서 P(1)은 K-1개의 폴더에서 파악한 매칭 확률을 의미하고, 엔티티 백터 들의 매칭 클래스(1)일 때 벡터의 각 차원에 대한 조건부 확률의 곱을 의미한다. 예를 들어, 엔티티 쌍의 벡터가 v1 = [0.2, -0.1, 0.5], v2 = [0.3, -0.2, 0.4]일 때, 첫번째 차원값들은 [0.2, 0.3]이다. 평균이 0.25이고, 분산은 (-0.05^2 + 0.05^2) = 0.005, 표준편차는 √0.005가 된다. 이런식으로 2번째, 3번째 차원의 값도 계산한뒤, 각 차원의 확률밀도를 계산하고, 이들의 곱을 계산하는 방식이다.
분모에서 P(C)는 사전확률로 P(1)은 '매칭 쌍의 개수/훈련데이터 내 전체 쌍의 개수'로 계산되고, 전체 식을 풀어서 표기하면 다음과 같다: P(vⱼ|매칭) × P(매칭) + P(vⱼ|비매칭) × P(비매칭) = P(vⱼ|1) × P(1) + P(vⱼ|0) × P(0). 즉, 모든 클래스의 (likelihood × prior) 합을 의미하는 것이다.
엔티티 쌍 (a, b)를 벡터화하는 방법은 dictionary와 같은 형태의 key-value 형태를 문장 형식과 같이 직렬화를 하고 pre-trainined 모델을 활용하여 벡터화한다. 해당 연구에서는 SBERT를 사용하고, [SEP]을 각 엔티티 쌍 사이에 넣어서 분리했다고 한다.
✅ 왜 불확실성이 높은 걸 샘플링할까?
Active Learning은 모델이 원하는 데이터만 선택하고 학습하는 방식이다. 이때 불확실성이 높은 데이터를 선택함으로써 이미 잘 알고 있는 것이 아닌, 헷갈리는 것을 다시 확인한다는 점에서 학습 효과가 극대화된다는 의미가 있다.
4.1.2 Selection
단순히 불확실성이 높은 샘플들만 선택하는 것은 크로스 도메인 환경에서 부적절할 수 있으므로, 불확실성 점수에 Target data와의 의미적 유사도 값을 더하여 도출한다. 즉, 두 엔티티쌍의 벡터 사이의 유사도를 계산하는 것이며, 1/Dist(v, v*)를 통해 나타난다. 이때 v*는 모든 Target data 엔티티 벡터의 평균값을 사용하여 전반적으로 유사한 도메인 데이터를 도출할 수 있도록 한다.
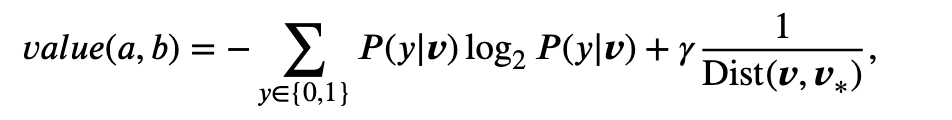
최종적으로 계산된 값의 상위 h개가 후보 데이터가 되는 것이다.
4.2 In-context demonstration selection
ICL의 목표는 후보 데이터 D^C에서 Target data Dᵀ의 레이블을 도출하기 위한 프롬프트에 넣어줄 가장 유용한 예시 데이터를 선택하는 것이다. 기존에는 엔티티 쌍의 벡터 값을 통한 의미론적 유사도나 구조적 차이(속성 수의 차이 비교)를 기반으로 하는데, 본 연구에서는 Cross-domain에서 적용할 수 있는 domain-invariant(도메인 불변) 벡터 구조를 제안한다.

우선 구조적 유사성을 계산하기 위한 최종 벡터값은 좌측과 같이 세 개의 유사도 매트릭 결과를 3차원으로 표현한 값이 된다. 각각의 매트릭은 우측의 수식으로 계산되는데, Φ는 구조적 유사성을 계산하기 위한 메트릭을 의미하고, 연구에서 사용한 메트릭은 Jaccard similarity(교집합을 합집합으로 나눈 값), Levenshtein 거리(편집 횟수 기반), Jaro-Wrinkler 거리(매칭 문자 기반)이다. 즉, 비교하고자 하는 엔티티의 도메인이 달라서 속성의 수가 다른 경우에도 항상 3차원 벡터로 표현되기 때문에 벡터간 유사도를 계산할 수 있는 것이다.
의미적 유사도를 계산할 때는 동일한 임베딩 모델로 벡터화하면 문제가 없지만, 구조적 유사도를 계산할 때는 속성의 개수가 같아야 하기 때문에 이런 방식을 사용하는 것이다. 구 엔티티 쌍을 비교할 때 속성값까지 세밀하게 비교하기 위해서는 적합한 방식으로 이해할 수 있다.
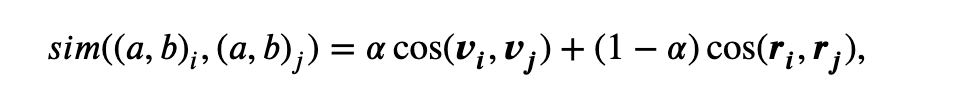
최종적으로 의미론적 유사도와 구조적 유사도에 가중치를 부여해서 합해준 값을 도출하고, 이 값이 가장 높은 값이 ICL에 데모 데이터로 들어간다.
4.3 Prompt generation

각 엔티티 쌍별로 넣어줄 데모를 정했으므로, 이 값들을 사전에 만들어둔 프롬프트 포맷에 넣어준다. 프롬프트 예시는 위와 같다.
4.4 Overall algorithm

전체 알고리즘은 위 슈도 코드로 나타낼 수 있다. 앞에서 설명한 내용을 하나씩 담고 있어서 차례로 읽어보면 쉽게 이해할 수 있다.
5️⃣ Experiments
5.1 Experimental settings
논문에서는 CiDER 프레임워크를 평가를 통해 다음 질문들의 답을 도출하고자 한다.
- Q1: CiDER가 기존의 DL기반, LLM 기반 기법들보다 얼마나 효과적인지?
- Q2: Source data에서 바로 참조데이터를 뽑는 것보다 후보 데이터로 한번 필터링하는게 정말 더 효과적일지?
- Q3: 최종 참조데이터를 선택할 때 유사도 계산(의미+구조적 고려)을 통해서 나온 값을 넣어주는 방식이 LLM의 판단에 도움이 될지?
- Q4: 프롬프트를 생성할 때, 참조데이터 엔티티쌍의 도메인 정보를 함께 넣어주는게 효과적인게 맞을지?
5.1.1 Datasets
실험에서는 아래와 같은 다양한 도메인의 데이터를 사용한다. 첫번째 카테고리는 제품, 인용, 레스토랑 등 완전히 다른 도메인으로 구성된다. 두번째 카테고리는 같은 제품 도메인 내에서 세부 분야의 차이가 있는 것으로 구성된다. 각각의 데이터세트는 복수의 속성을 갖는 관계형 테이블로 구성되고, 매칭/비매칭의 정답값이 라벨링되어 있다. 그리고 서로 다른 도메인 데이터를 Source와 Target 데이터로 구성되도록 묶어준다.
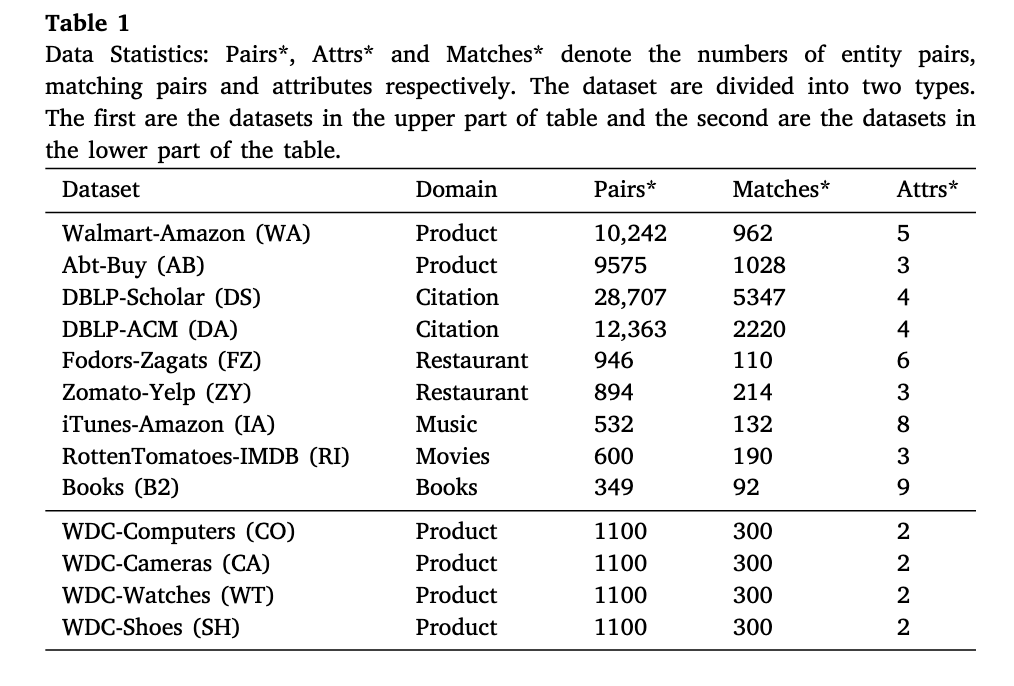
5.1.2 Evaluation metric
기존의 연구들과 같이 F1-score를 사용해서 각 기법들을 평가한다.
- Precision = TP/(TP+FP)
- Recall = TP(TP+FN)
- F1-score = 2*Presion*Recall/(Precision+Recall)
5.1.3 Baselines
CiDER의 성능을 평가하기 위한 방법은 PLM(Pre-trained Language Model)기반 방법과 LLM기반 방법으로 구분해서 진행한다.
- PLM based
- NoDA: domain-shift를 고려하지 않는 알고리즘
- DADER:Cross-domain ER의 SOTA 기법. 특성을 추출하고 매칭을 수행하며, 소스-타겟 도메인의 분포를 전렬하는 3개 모듈로 구성됨
- LLM based
- Zero-Shot: 예시 없이 프롬프트 만으로 수행
- SDR-S(Source Data Random): 랜덤으로 예시를 선택해서 넣어주는 방법
- KATE: 의미론적 유사성만으로 예시를 선택하는 방법
- JAC: 자카드 유사도(구조적)만으로 예시를 선택하는 방법
5.1.4 Implementation details
CiDER는 후보 데이터는 50개로 설정하고, 최적의 하이퍼 파라미터를 고정해서 사용하며, Target data의 10%는 validation data로, 90%는 test data로 사용한다. 또한 LLM은 GPT-3.5-Turbo-1106을 사용했고, temperature는 0.01 사용하며, 모든 실험은 3번을 반복한 뒤 평균값을 도출했다.
사용한 프레임워크는 Python의 PyTorch 2.0.1이고, GPU는 RAM 16GB의 GeForce GTX 1660Ti를 사용했다.
5.2 Main results (Q1)
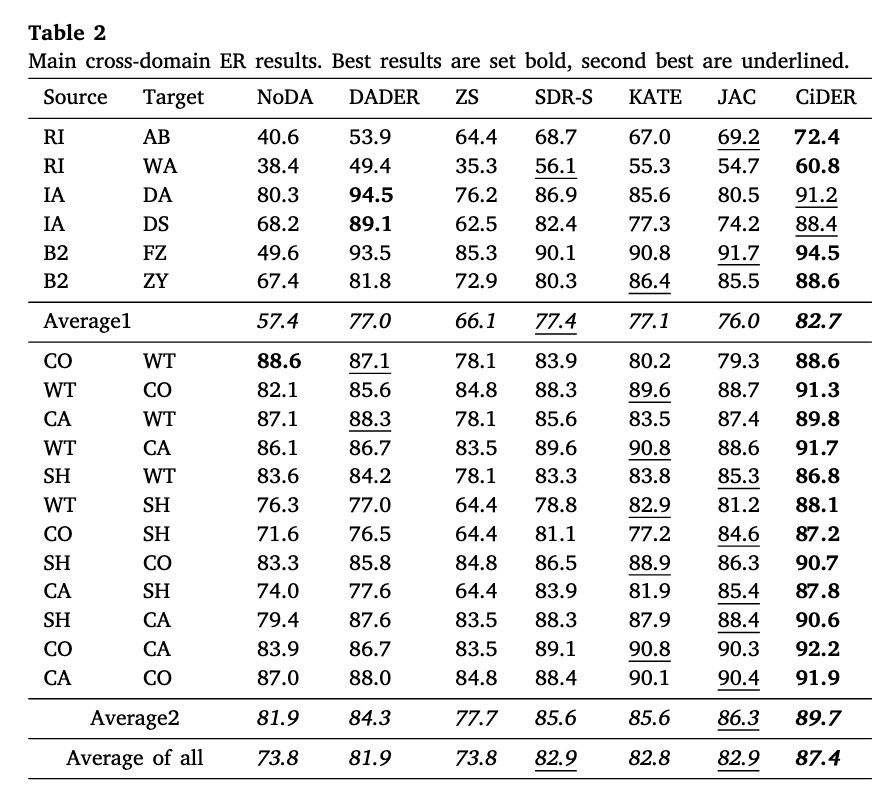
위 결과 테이블을 보면, 모든 평가 기법과 데이터셋 조합에서 CiDER의 성능이 가장 뛰어남을 알 수 있다. 도메인 유형별로 분류한 카테고리별로 살펴보면, 도메인을 완전히 섞은 카테고리1의 Average1이 도메인이 비교적 유사한 Average2보다 약 5% 정도 낮은 것으로 보아 더 어려운 시나리오라는 것을 확인할 수 있다.
LLM의 ER 처리 능력
Cross-Domain ER의 SOTA인 DADER과 CiDER를 비교해보면, 거의 모든 부분에서 CiDER의 평가 점수가 높았다. IA(iTines-Amazon)-DA(DBLP-ACM), IA-DS(DBLP-Scholar) 조합에서만 CiDER의 점수가 낮았는데, 이를 위해 MMD(Maximum Mean Discrepancy; 최대 평균 불일치) 메트릭을 활용해서 두 데이터셋 분포를 확인해봤다고 한다. 그 결과 MMD 점수가 굉장히 높았는데, 이는 LLM이 할 수 있는 도메인 일반화 능력을 초과할 정도로 두 데이터셋의 분포 차이가 매우 크다는 것을 의미한다.
그럼에도 여전히 CiDER의 평균 평가 점수가 가장 높으며, 특히 Zero-Shot인 경우에도 평균 73.8%로 비교적 높다는 것으로 보아 LLM을 활용한 ER 처리가 효과적이라는 결론을 내릴 수 있다. 이는 관계 없는 도메인의 예시임에도 문제 해결을 위한 규칙을 파악하는데 도움을 줄 수 있기 때문이다.
ICL의 효과
랜덤으로 예시를 뽑아서 프롬프트에 추가하는 SDR-S 방식이 Zero-Shot보다 높은 성능을 보이고(약 7.9%), 이 결과는 DADER보다도 약간 높다. 또한 참조 데이터를 뽑는 방식에 있어서는 단일 유사도 기반으로 추출하는 방식보다 랜점으로 뽑는 방식이 오히려 점수가 높다는 점에서 Source data를 필터링하는 것의 중요성을 다시 확인할 수 있었다.
5.3 Ablation study (Q2&Q3&Q4)
ablation study는 CiDER에서 주요한 구성 요소를 확인하기 위해서 일부를 제거한 평가 결과들을 비교하는 방식이다. 비교군은 다음과 같다: (1) CiDER w/o AC: 후보데이터 생성 부분 제외. Source data에서 바로 유사도 계산해서 넣어주는 방식 (2) CiDER w/o DS: ICL에 넣어주는 최종 데모 선택하는 계산 제외하고, 후보 데이터에서 랜덤으로 선택 (3) CiDER w/o PG: 프롬프트에 넣어주는 데모의 도메인 데이터 정보 제외.
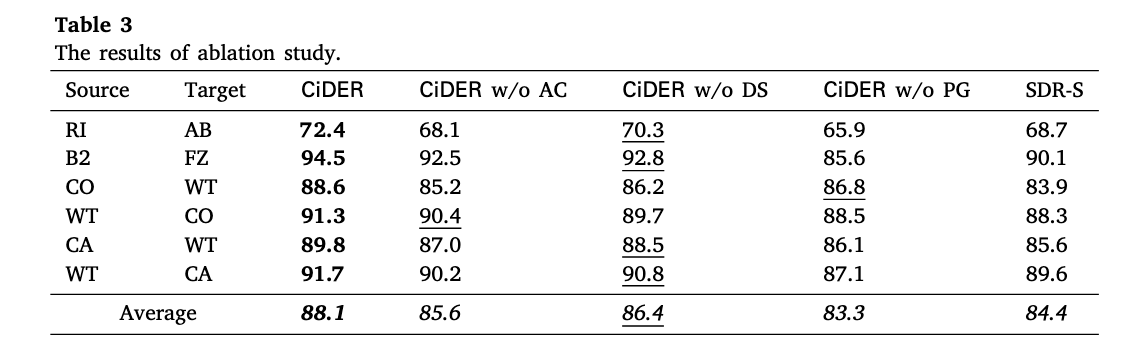
결과를 보면, CiDER > w/o DS > w/o AC > w/o PG 순으로 평가 점수가 높다. 해당 요소를 뺐을 때 평가 점수가 낮아진다는 것은 뺀 요소가 결과에 큰 영향을 미친다고 볼 수 있으므로, 후보 데이터에서 최종 데모를 선택하는 부분은 계산, 후보데이터 생성, 도메인 정보 순으로 영향력이 크다. 특히 RI-AB와 같이 도메인의 차이가 큰 경우에 점수가 가장 낮다는 점에서 Source data의 도메인 정보를 프롬프트에 넣어주는 것의 중요성을 다시 확인할 수 있다.
추가로 확인할 수 있는 내용은 다음과 같다.
- 후보데이터 추가의 중요성: CiDER - w/o DS - SDR-S 비교를 통해 확인 가능. 그냥 랜덤으로 참조 데이터를 뽑는 것 보다 후보 데이터를 한번 핉터링 한 다음에 뽑는 방식이 더 낫고, 가장 나은 방법은 CiDER와 같이 후보 데이터에서 최적의 데이터를 찾아서 넣어주는 방식
- 범위에 따른 비교: SDR_S와 w/o DC는 전체 범위 혹은 후보 데이터 범위에서 랜덤으로 뽑는 방식. w/o DC의 결과가 2% 더 높다는 점에서 범위를 좁혀주는 것이 이점이 있음을 알 수 있음
- 방식에 따른 비교: SDR-S와 w/o AC는 후보 데이터를 만들지 않고 전체 데이터를 사용하지만, 각각 랜덤으로 선정하거나 유사도 기반으로 선택한다는 방식의 차이가 있음. 유사도 기반의 선정 방식이 약 1%도 높게 나타남
5.4 Hyper-parameter analysis
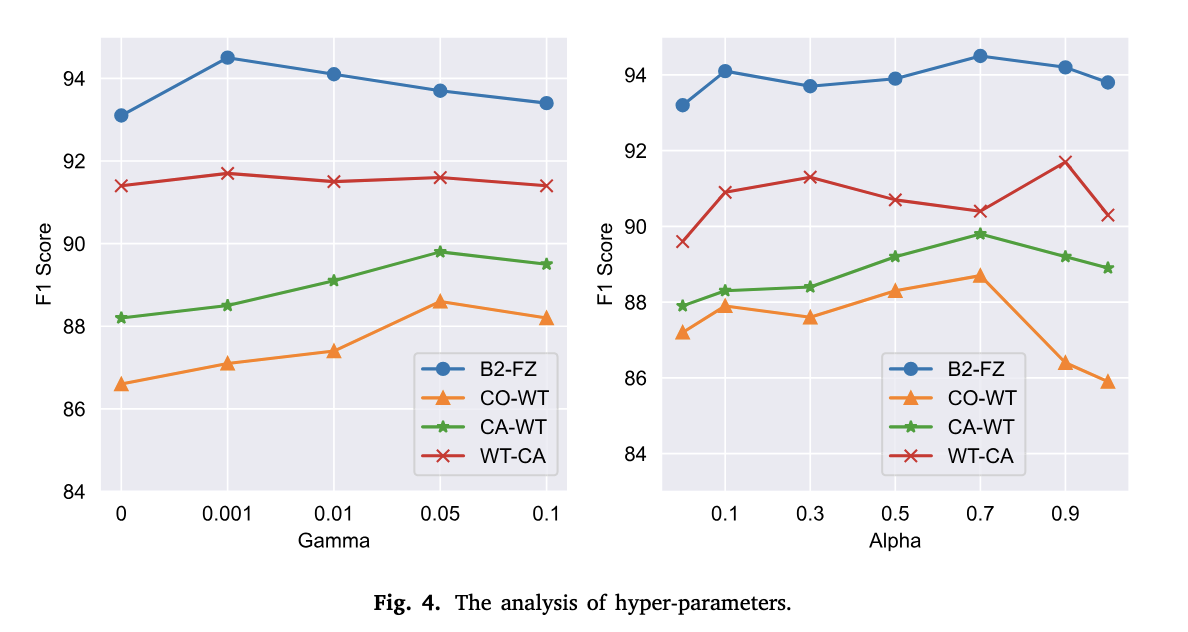
CiDER은 후보샘플링을 선택하는 수식에서 사용되는 γ와 최종 데모 데이터를 선정하는 유사도 수식에서 쓰이는 α 라는 하이퍼파라미터를 갖는다. 우선 γ를 [0, 0.001, 0.01, 0.05, 0.1]로 바꿔가면서 테스트를 진행해봤는데, 0은 불확실 샘플링을 통해서만 후보 데이터를 구축한다는 의미이다. 위 그래프를 보면 0일때, 즉 불확실 샘플링만을 할 때보다 유사도 거리값을 추가했을때 F1-Score가 더 높게 나타났다.
α는 [0,0.1,0.3,0.5,0.7,0.9,1] 값으로 테스트 해봤는데, 1은 의미론적 유사도만을 사용하여 데모를 선정하는 것이고 0은 구조적 유사성만을 사용한다는 의미이다. 위 그래프에 따르면, 1과 0같이 극단적으로 하나만 사용할 때 보다 둘을 적절히 사용했을 때 점수가 더 높다는 것을 알 수 있다.
5.5 Robustness analysis
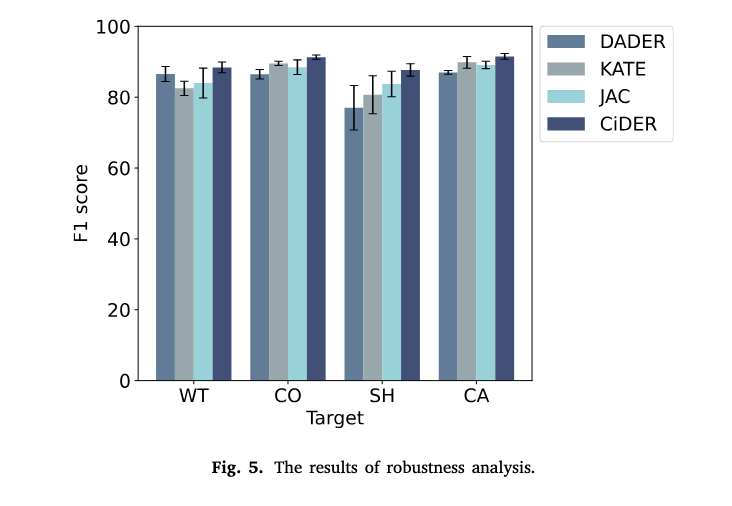
Source data가 변경될 때마다 CiDER의 robustness을 측정했다. Target Data는 고정하고, Source data만 바꿔가면서 4개의 기법으로 평가한 결과, CiDER는 대부분 높은 F1 점수를 달성했고, 변동성이 낮다(error bar가 짧음)는 점에서 안정적인 성능을 보였다.
5.6 Efficiency analysis
실행 시간에 대한 비교로, CiDER가 가장 복잡한 방법임에도 불구하고, 실행 시간이 크게 차이나지 않아 효율성이 높다. 이는 후보 데이터를 통해 선택 범위를 축소하여 계산량을 줄였기 때문이라고 이해할 수 있다.

5.7 Case study
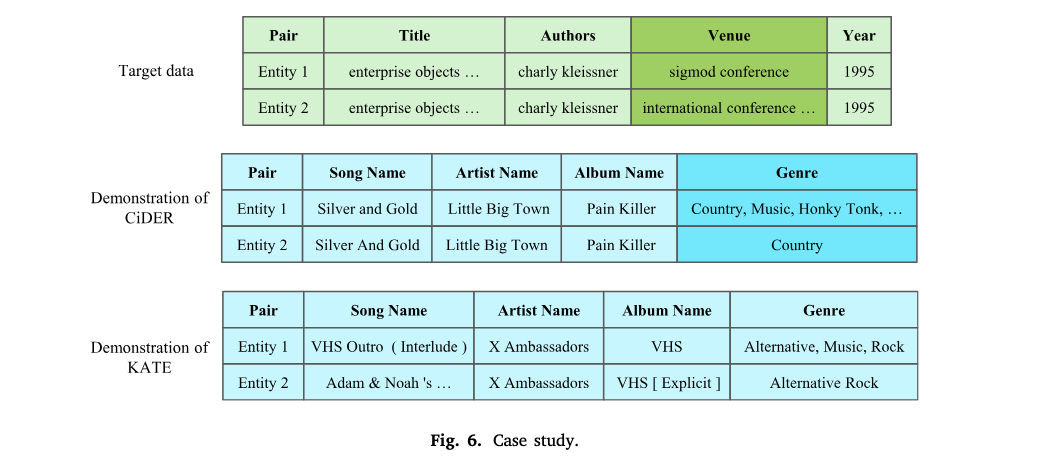
CiDER가 LLM에 더 유용한 데모를 선택하는 방법을 시각적으로 보여주기 위한 예시이다. 우선 Target data의 entity1과 entity2에 대해서 CiDER는 매칭된다고 답변하고 KATE는 매칭되지 않는다고 답변했다. 이를 판단하기 위해서 선택한 데모는 CiDER는 음악 도메인의 데이터였는데, '주요 속성(Title, Author, Year)이 같으면 동일한 개체로 분류'라는 것을 인식할 수 있는 유용한 참조 데이터였다. 반면, KATE의 경우, 예시 자체가 비매칭 엔티티 쌍으로, 모델의 판단에 유용하지 않았다. 즉, Target data 상황과 맞지 않는 참조데이터를 썼기 때문에 답변이 제대로 도출되지 않은 것이다.
Target data가 매칭인 상황에는 참조 데이터도 매칭인 엔티티쌍을, 반대의 경우에는 비매칭 엔티티쌍을 넣어주는 것이 효과적일 듯
5.8 Further experiments
추가로 오픈소스 모델을 사용해서 모델 크기에 따른 성능 차이를 비교하고 있다. 사용한 모델은 LLaMA3-8b 모델이고, 하드웨어는 GeForce GTX 4090, 64GB RAM을 사용하며, 이외의 조건은 이전 실험과 동일하게 설정한다. Table5에 따르면 전체 성능을 비교했을 때 CiDER의 점수가 가장 높으며, Ablation Study를 동일하게 진행했을 때도 GPT를 사용했을 때와 동일하게 후보 데이터의 필요성이 드러났다고 한다. 한편, 전반적인 성능은 GPT-3.5를 사용했을 때 더 높았는데, 이를 통해 모델의 사이즈가 클 수록 복잡한 도메인 간 패턴 학습이 용이하고 도메인 간 비교도 더 잘 한다는 것을 알 수 있다. 또한 CiDER와 같은 기법은 특히 작은 모델을 사용할 때 도메인 간의 차이를 모델이 잘 인식할 수 있도록 돕는다는 점에서 효과적이라고 설명한다.
6️⃣ Conclusion
이 연구는 Cross-domain ER 작업에서 ICL기반 LLM의 적용 가능성을 탐구했다. 그 결과, 도메인이 다르더라도 LLM의 판단에 source data는 유용하다는 것을 확인했다. 향후 연구에서는 CiDER에 Blocking 단계를 추가해서 완전한 ER 시스템을 구축할 계획이라고 한다.
