
한 줄 요약:
기존 LLM의 수치, 통계적 부분의 할루시네이션 현상을 팩트 데이터(from Data Commons)를 기반으로 줄이는 Data Gemma를 소개하는 논문
이 논문은 2024년 9월에 발표된 Google에서 연구하고 있는 Data Commons, Data Gemma를 설명하고 있다. Data Gemma는 LLM의 한계점으로 지속적으로 Hallucination 현상을 줄이고자 하는 목표에서 부터 시작한다. 구체적인 방법으로는, 큰 규모의 단일의 외부 소스를 구축하고 그 소스에서부터 정확한 정보를 가져오는데, 이때의 외부 소스인 Data Commons는 지식그래프 기반으로 구축된다. 즉, RIG(Retrieval Interleaved Generation)과 RAG(Retrieval Augmented Generation) 기법을 적용하여 답변을 정확도를 높이는 방법이다.
구체적인 내용은 논문의 내용을 하나씩 살펴보며 알아보겠다.
🧩 Introduction
LLM을 데이터로 연결하고 해결해야 할 세 가지 문제를 제시하고 있다.
- 어떤 질문을 외부 소스에 어떻게 요청할지?
- 어떤 외부 소스를 쿼리할지? (이 논문에서는 사이즈가 큰 단일의 외부 소스를 사용한다고 명시함
- 하나 이상의 쿼리 생성을 universal API를 통해서 수행 (여러개의 외부 소스에서 지식을 가져올 필요가 없고, 단일 소스에서 가져온다는 의미)
여기서부터는 개인적인 생각인데, 우선 1번의 경우 사용자는 해당 모델에 다양한 목적의 쿼리를 할 수 있기 때문에 이 쿼리들을 분류할 필요가 있음을 의미한다고 이해했다. 예를 들어서, '1+2=?'와 같은 질문은 외부 소스가 필요 없는 질문이지만, '오늘 서울의 날씨는?'과 같은 질문은 검색 API가 필요하다. Data Commons에서 쿼리를 할 수 있는 질문들이 한정되어 있는 만큼(기존에 구축한 KG의 범위가 있을 것이므로) 어떤 질문을 어떤 방식으로 답변을 도출해낼 것인지에 대한 판단은 중요하다.
두번째 질문의 경우, 사용하는 외부 소스가 여러개인 경우에 해당 소스들에서 전부 참조 데이터를 쿼리할 것인지 혹은 일부만 선택해서 쿼리할 것인지에 대한 선택이 요구된다. 혹은 모든 외부 소스에서 검색을 한다고 해도, 도출된 참조 데이터들 간의 정보가 중복될 경우, 어떤 정보를 선택(rerank)할 지에 대한 문제 역시 남아 있다. Data Gemma의 경우, Data Commons라는 하나의 거대한 KG를 구축하고, 이 KG가 양질의 외부 소스라는 가정 하에 이루어진다.
마지막으로, Universal API는, 앞서 언급한 Data Commons에서 쿼리하는 것을 의미한다고 볼 수 있다. 여러개의 외부 소스의 정보들을 통합하고 정제하여 만든 DC라는 KG 하나만 있으면 여러개의 쿼리를 생성할 필요 없이 한 번의 쿼리로 정확한(fact) 정보를 얻을 수 있다는 것이다.
🧩 Related Works
Toolformer
LLM이 self-supervised learning을 통해 외부 도구를 활용할 수 있는 방법을 의미한다. 이 방법을 사용하면 모델이 언제, 어떤 외부 API를 호출할 것이며 최적의 통합 방법을 결정할 수 있다고 한다.
이 설명만으로는 자세한 내용을 잘 모르겠는데, 개념적으로는 Agent의 기능과도 굉장히 비슷하다고 생각했다.
Knowledge Graph
TBD
LIMA(Less is More for Alignment)
TBD
🧩 Data Commons
Data Commons는 Google에서 구축한 'the world's public datasets'으로, 광범위한 통계적인 공공데이터(인구, 질병, 환경, 경제 지표 등)를 다룬다. 논문의 시점에서는 2500억 개 이상의 data point(?)와 2.5조개 이상의 트리플 사이즈라고 한다. Data Commons 사이트에 들어가보면 해당 데이터들을 실제로 확인하고 다운받을 수도 있는데, 아직까지는 대부분 미국을 중심으로한 데이터가 많다는 것을 알 수 있다.
Data Commons를 구축하기 위해서 이들은 몇 년 동안 공공데이터 세트들을 수집하고, Schema.org를 통해서 정규화(메타데이터를 포함한 인스턴스 단위의 정규화까지 필요했을 듯)를 진행했다고 한다. 이 과정을 이렇게 한 두줄로 설명하지만, 사실 굉장히 지난한 과정이었을 것 같은데, 어떤 방식으로 했을 지 궁금하다. 또한 자연어 질의가 들어왔을 때 이를 DB에서 쿼리할 수 있는 NL Interface를 구축했다고 하는데, 아마도 Text2SPARQL과 같은 방식을 의미한다고 이해했다. 자연어 쿼리를 SPARQL 쿼리로 변환하는데, 이 과정에서 적절한 어휘를 넣어주는 과정을 학습한 모델일 것으로 추측된다.
🧩 LLMs with Data Commons
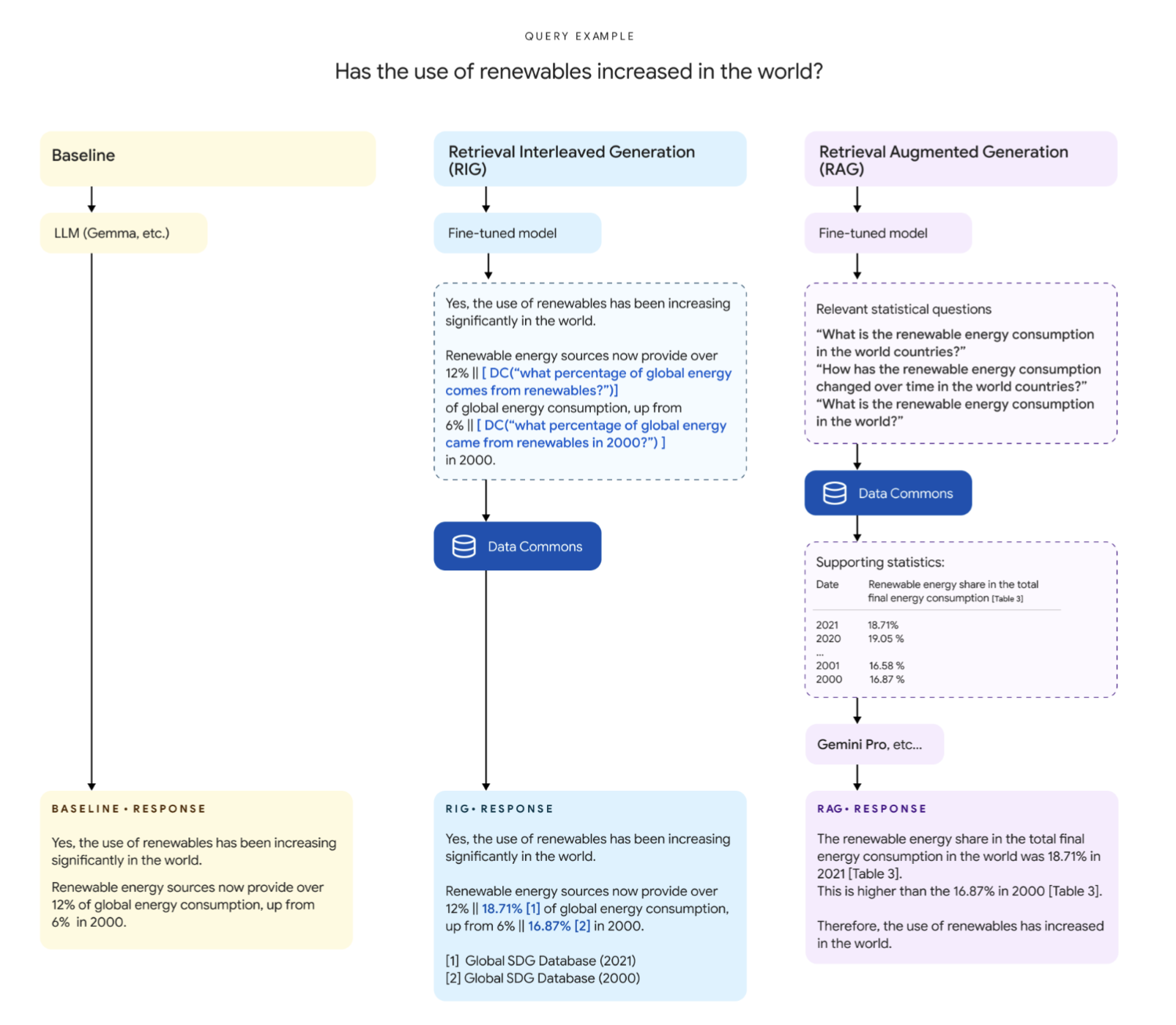
위 프로세스는 동일한 질문에 대하여 세 가지의 method의 차이에 대해서 설명하고 있다. 우선 Baseline의 경우, 일반적인 LLM을 통한 답변이다. 두, 세번째의 RIG과 RAG의 경우 모두 Fine-Tuned model을 기반으로 하는데, 최종 답변을 생성해내는 과정의 차이가 있다. RIG의 경우 사용자의 query의 답변을 일단 생성한 뒤, Data Commons에서 검색하여 통계적으로 보완할 수 있는 부분을 확인한 뒤, 자연어 쿼리를 만들어서 해당 부분만 보완한다. 반면 RAG는 답변을 생성하기 이전에 Data Commons에서 검색할 자연어 쿼리 리스트를 생성하고, reference data를 가져온 뒤, Gemini Pro 등과 같은 모델에 사용자의 질문, reference data를 모두 넣어서 최종 답변을 생성한다.
두 방법에 대해서 보다 자세히 살펴보고, 각 기법이 사용된 Fine-tuning model은 어떤 학습되는지 살펴보겠다. RIG와 RAG에서 사용되는 Fine-tuning된 모델이 같은 모델을 사용한건지 다른걸 사용한건지 명확한 언급이 없어서 살짝 헷갈렸는데, 각 역할이 다른점으로 보아 각각 학습된 모델이라는 결론을 내렸다.
1️⃣ RIG
1. Fine-tuning
RIG의 경우, 답변을 생성할 때 추가 쿼리가 필요한 부분을 인식하여 표시하고, 쿼리를 생성한뒤 찾아서 나온 값(DV-SV)을 LLM이 생성한 수치(LLM-SV)와 비교해서 최종적으로 수정한다. 데이터세트는 프롬프팅을 통해서 Gemini 1.5 Pro를 통해서 생성한다. 형식은 아래(Appendix A 참고)와 같다.

답변의 길이나 fluency 등은 해치지 않으면서 수치가 있는 부분에서는 위와 같이 [] 안에 쿼리를 넣어주는 형식이다. 이후 매뉴얼하게 수정, 검토 과정을 거쳐서 만든 데이터셋으로 학습을 진행했다고 한다.
2. Post-processor
자연어 쿼리를 Data Commons 데이터베이스에서 검색할 수 있는 쿼리로 변환하는 부분으로, 질문을 유형화해서 쿼리를 작성한다. 우선 사용자들의 질문을 통계적 정보에 따라서 주제적으로 분리하고, 장소나 속성(순위, 비교, 변화율 등)을 파악한다. 이후 분해된 변수와 각 컴포넌트들을 Data Commons에 있는 ID들과 맵핑하는데, 통계적 변수는 임베딩 기반의 시멘틱 서치 인덱스를 사용하고 장소 변수는 NER tagging을, 속성은 정규식 기반 휴리스틱 집합을 사용한다고 한다.
이 부분이 bottle-neck일 것 같다는 생각을 했는데, 아래 RAG에서도 동일한 작업이 진행되는 부분에서 한계와 향후 연구점들을 언급한다.
3. Querying Mechanism (Fullfillment)
위 쿼리로 Data Commons에서 통계적 수치를 가져온 뒤, 기존의 답변에서 수치 부분을 비교해서 정확한 값으로 수정해준다. 또한 쿼리 부분을 삭제하고 footnote 형식으로 출처를 명시해서 사용자가 팩트 체크를 할 수 있도록 한다.
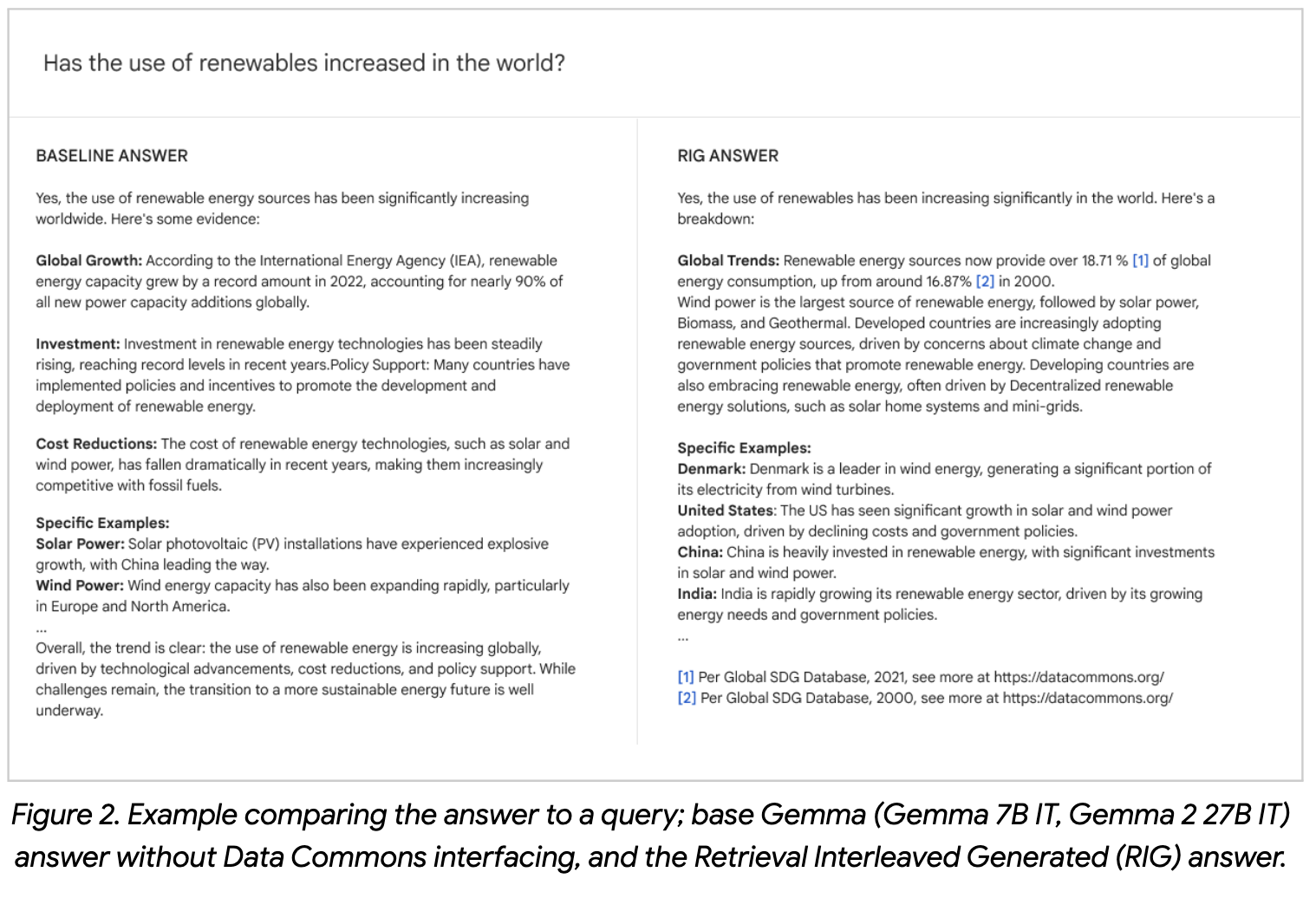
2️⃣ RAG
1. Fine-tuning
RAG의 경우, 사용자의 질문에서 통계적인 검색이 필요한 부분이 있는 지 검토해서 각 통계값을 쿼리할 수 있는 자연어 질문을 만드는 모델이 필요하다. Gemma2 9B IT 모델과 Gemma2 27B IT를 각각 학습해봤다고 한다. 개인적으로는, 이 정도는 프롬프팅 정도로도 커버할 수 있지 않을까 생각했다(sub-query를 생성하는 프롬프팅 기법과 관련해서 이미 많이 언급되었음). Appendix에 보면 traning을 위한 데이터를 생성하는데 사용된 프롬프트가 있는데, 이 내용을 few-shot으로 하면 충분히 sub-query를 생성할 수 있을 것 같은데, 아마도 작은 사이즈의 오픈소스 모델을 사용하기 위해서인 것 같다. 여기서 사용한 Gemini 1.5 Pro와 같이 큰 모델에서는 잘 작동하겠지만, 9B나 27B정도에서는 프롬프팅이 안정적인 성능을 주지 않을 것 같다.
논문에서는 이렇게 Fine-tuning을 했을 때, 실제로 Data Commons에서 검색할 수 있는 쿼리를 생성하지 못할 수 있다는 것을 언급하는데, 이는 쿼리해야 하는 데이터의 컬럼명과 일치하지 않아서 생기는 문제점 등으로 이해할 수 있다. 예를 들어서 서울특별시의 인구수를 쿼리한다고 해도 '인구수'를 의미하는 컬러명(KG의 경우 Property)이 다를 수 있고, '서울특별시'도 '서울', '서울시' 등으로 다양하게 표현될 수 있기 때문이다.
이를 보완할 수 있는 방법으로 Data Commons의 변수와 측정 항목의 전체 목록을 포함해서 실제로 사용되는 용어로만 호출을 생성하는 시도를 했는데, 결론적으로는 성능이 떨어졌다고 한다. 이와 관련해서 자연어 쿼리를 생성할 때는 보다 자유도 높게 생성하고, SPARQL 쿼리를 생성할 때 한정된 값을 사용하는 방법은 가능할까에 대한 의문이 있었는데, 유사어 사전과 같은 걸 만들지 않는 한 이 방법 역시 동일한 이유로 쉽지 않을 것 같다.
논문에서는 'We review the generated Data Commons calls produced and manually rewrite certain questions.'라고 설명하는데, 이 과정이 Fine-tuning하는 데이터셋을 수동으로 수정했다는 의미로 이해했다. 그럼에도 해당 모델로 생성한 쿼리의 오류는 여전히 남아있을 순 있을 것 같다.
2. Natural Query to SPARQL
이 방법은 RIG에서 사용한 방법과 동일하다. 궁금한 점은, tables를 도출한다고 하는데, KG 기반으로 인덱싱을 하고 실제 데이터 수준은 RDB로 관리하는 건지 모르겠다.
25.12
논문을 다시 읽어봤을 때, SPARQL로 쿼리한다는 내용은 언급된 적이 없었다. single-source를 생성하고, 이를 지식그래프로 표현한다고 해서 당연히 그래프 검색을 생각했는데, 대규모 데이터의 스키마를 지식그래프로 표현했을 순 있겠지만, 실제 관리 수준에서는 RDB 등 다른 형태의 DB를 사용했을 가능성이 충분히 존재한다. 즉, SQL, Cypher등 DB 형태에 따른 다른 쿼리 언어를 사용했을 수도 있다는 것이다.
3. Generation
검색한 참조 데이터와 쿼리를 최종적으로 Gemini 1.5 Pro에 넣어서 답변을 생성한다.
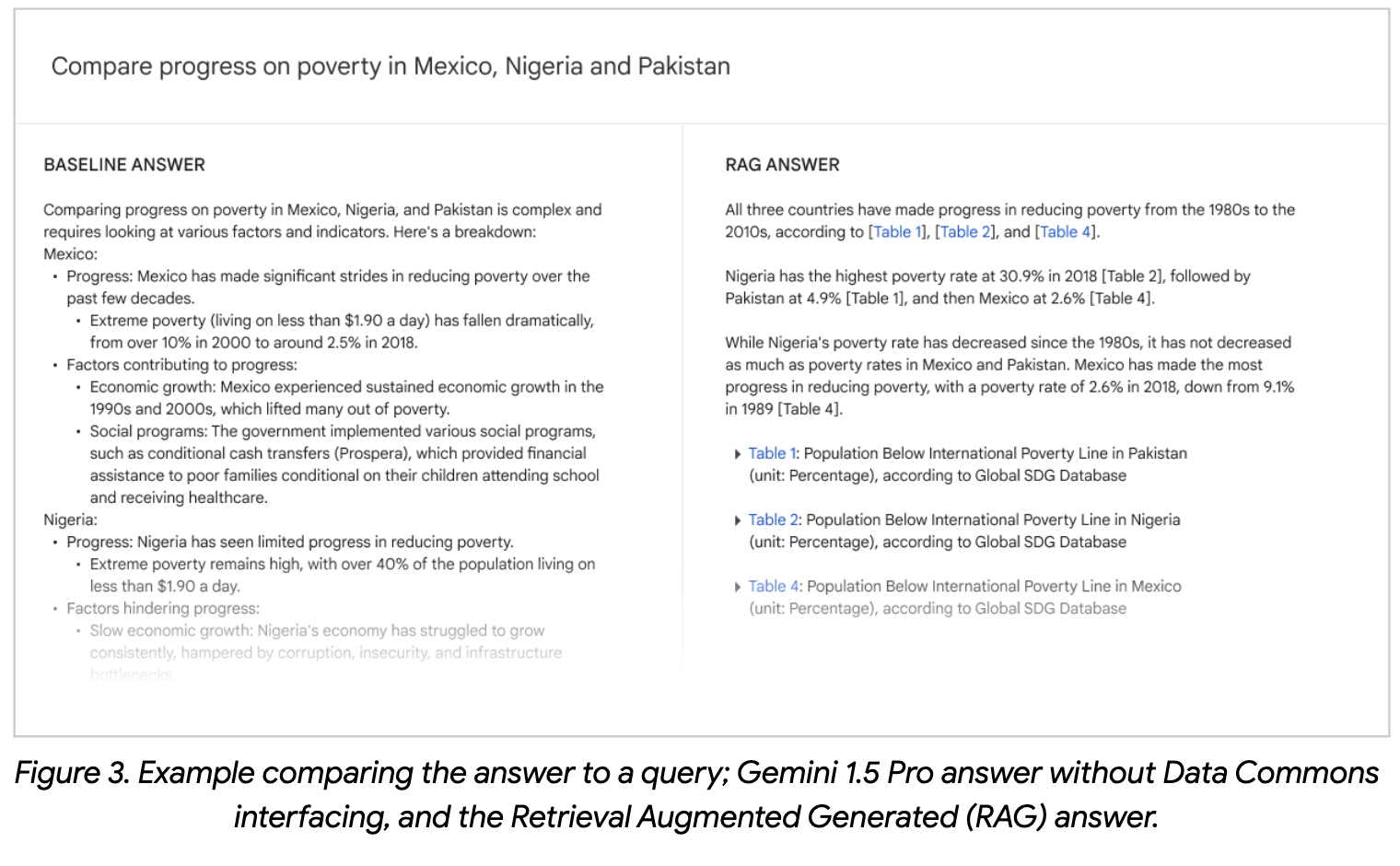
🧩 Evaluation, Results
평가는 101개의 쿼리에 대해서 RIG와 RAG를 각각 진행한다. 101개의 질문은 주제적 카테고리별로 분류해서 간단한 질문 96개와 복잡한 질문 22개, 통계적으로 관련없는 쿼리 5개를 생성한 뒤 중복되는 쿼리들을 제거한다.
평가툴은 사람 평가자들(data expertise)에게 답변과 관련된 종합적인 평가를 할 수 있는 몇 가지의 질문들을 하고 선지를 선택하도록 하는 웹페이지로 구성된다. stage1에서는 답변이 틀렸는지, 맞았는지를 간단하게 분류하고, stage2에서는 각각의 통계적 답변에 대한 평가를 진행한다.
RIG의 Accuracy는 (7B와 27B 모델 각각 평가) Data Commons가 맞은 경우가 약 58%이다. LLM의 정확도는 4~16%라는 점에서 실제로 통계값이 수정된 경우가 꽤 많았음을 의미한다. 또한 Data Commons의 통계값이 틀린 경우도 약 30%정도 존재하는데 이는 질문 자체가 잘못 생성되었거나 데이터베이스에 관련 데이터가 없어서 가장 근사값(most similar)을 두출했기 때문이다. 이는 추후 데이터의 양을 늘려서 보완할 수 있다고 한다.
RAG의 경우, stage1에서는 데이터를 검색하는 쿼리와 응답을 평가하고 stage2에서는 최종 응답의 통계값을 평가한다. Data Commons의 통계값을 인용할 때 거의 99%의 정확도를 보이고, 이외의 추론 부분에서는 약 20~30% 정도는 부족하거나 잘못된 정보를 포함한다. 한편, 평가 데이터셋의 약 30% 정도만 Data Commons의 통계값을 활용하는데, 이 이유는 RIG와 같이 질문 생성 모델의 한계점이나 데이터 부족 등이 원인이다.
마지막으로는 동일한 질문에 대해서 Basic LLM의 답변과 RIG 혹은 RAG 중 어느 것이 더 유용한 것 같은지를 선택하는 평가를 진행한다. RIG와 RAG 모두 Fine-tuning 이후의 답변이 더 선호도가 높으며, 작은모델(7B혹은 9B)보다 큰 모델(27B)의 선호도가 더 높았다.
.
.
.
LLM의 성능을 끌어올리기 위해 KG를 어떻게 사용할 수 있을지에 대한 많은 사람들의 궁금증에 대한 하나의 답변이 될 수 있는 논문이라고 생각했다. 특히 Google의 수행 결과라서 더 믿음이 가기도 했고. 또한 최근에는 대부분 LPG 위주(Neo4J 등을 사용하는)의 KG가 많이 언급되는데, RDF 기반의 KG를 사용해서 더 인상깊기도 했다.
RDF KG는 구축하기도 어렵지만, 일단 구축되었다고 가정하더라도 쿼리하기는 여전히 어려운 것 같다. 최근에 그래프 자체를 임베딩해서 VectorDB와 같은 형식으로 유사도 기반 참조 데이터를 검색하는 방식도 있는 것 같은데, 그래프를 임베딩 하면 텍스트를 임베딩 하는 것보다 어떤 장점이 있는지도 궁금하다. Data Gemma처럼 Text2SPARQL(정확히 SPARQL인지는 모르겠지만)방식을 효과적으로 할 수 있는 방법도 추가적으로 알아보고 싶다.
