
Chapter4에서는 앞서 Text matching에 이어서 확률론적 매칭과 관련된 내용을 다룬다. 확률 기반의 접근 방식은 여러 비교 속성 중에 중요한 속성은 유사하지만, 중요도가 낮은 속성은 유사하지 않을 때 일치 항목을 선언할 수 있으며, 일치 항목별로 신뢰도를 등급화하고 threshold를 적용할 수 있는 방법이다. 이런 기법을 적용한 모델은 Fellegi-Sunter (FS) 이고, 확률론적 entity resolution 프레임워크는 Splink를 상ㅇ한다고 한다.
실습은 Chapter2에서 정제한 영국의 하원의원 정보인 위키데이터와 TheyWorkForYou 데이터를 계속 활용한다. corss merge를 활용하여 650*650 = 422500 행을 만든 뒤, Firstname이 매칭되거나 Lastname이 매칭되면서 동시에 Constituency가 매칭되는 행만 추출한다.
match = cross[cross['Cmatch'] & (cross['Fmatch'] | cross['Lmatch'])]또한 Constituency가 다르거나, 같더라도 Firstname과 Lastname이 모두 다른 경우는 다음과 같은 조건으로 필터링할 수 있이다.
notmatch=cross[(~cross['Cmatch']) | (~cross['Fmatch'] & ~cross['Lmatch'])]Single Attribute Match Probability
First Name Match Probability
우선 Fistname을 기준으로 비교해보면, Constituency가 일치하는 것 중에 Firstname이 일치하지 않는 경우는 14행이다. 이전 챕터에서 확인했듯이 성을 약어로 표기한 경우들이 해당한다.
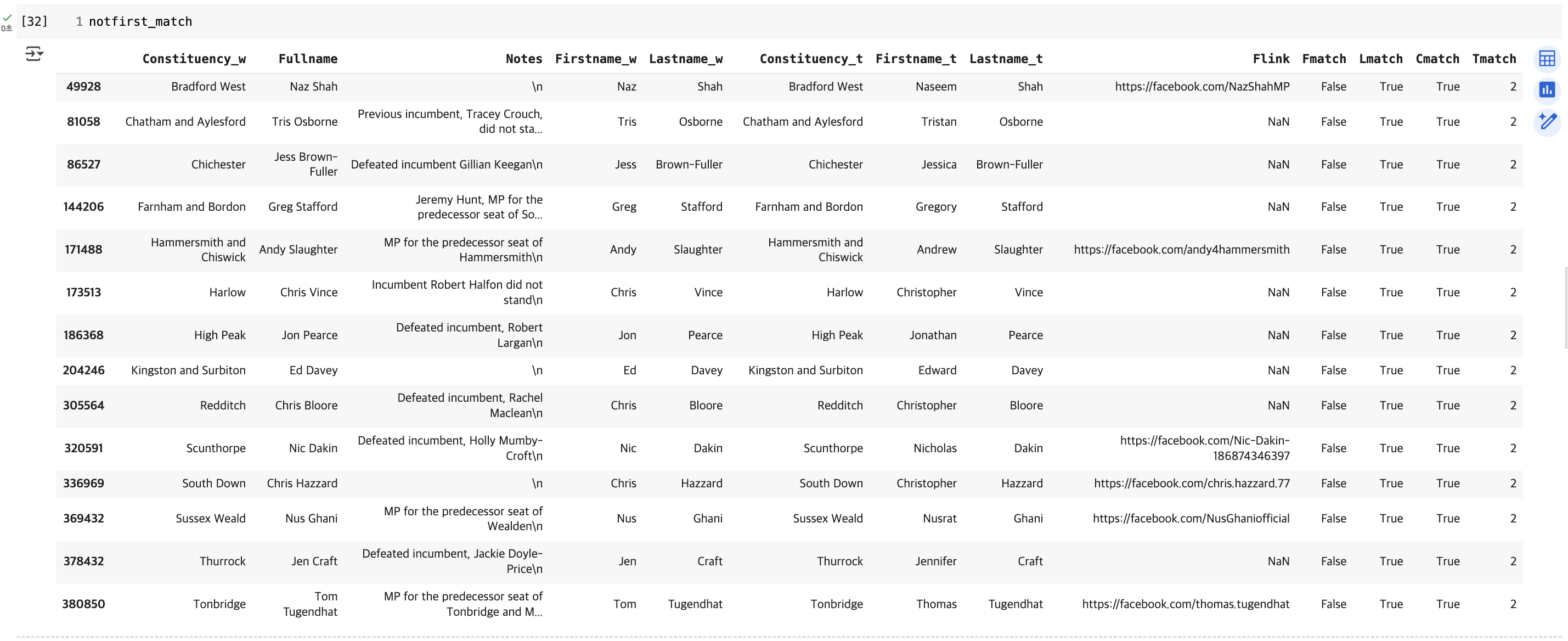
Constituency와 Firstname이 모두 일치하는 경우를 TP, Constituency는 일치하지만 Firsname은 일치하지 않는 경우를 FN(이름이 다르다고 예측했는데, 이게 틀렸으므로), Firstname이 같지만 Constituency는 다른 경우를 FP(실제로 다른 사람인데 같은 사람이라고 예측했으므로 틀렸으므로), 마지막으로 Constituency는 일치하지 않으므로 실제로 다른 인물인데 Firstname만 일치하지 않는 경우를 TN(이름이 다르다고 예측했고, 실제로도 다르므로)라고 보고 다음과 같이 계산된다.
- True Positive: 636
- False Negative: 14
- False Positive: 1925
- True Negative: 419925
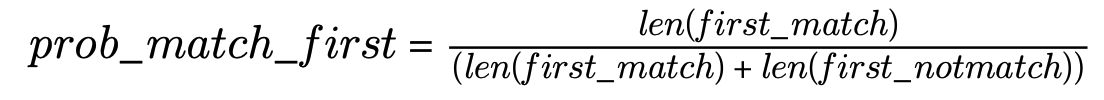
따라서 이 매칭값을 기준으로 Firstname이 같다고 매칭된 것 중에 실제로 같은 사람인 경우의 확률을 계산하면, 636/(636+1925) = 0.248 이 된다. 즉, Firstname이 일치하는 경우에 실제로 사람이 일치하는 확률이 약 24%가 된다는 의미로, 다시 말하면 Firstname 만으로는 일치하는 사람을 판단하기 어렵다는 것을 알 수 있다.
Last Name Match Probability
이번에는 동일한 방법으로 Lastname을 계산한 결과 다음과 같다.
- True Positive: 648
- False Negative: 2
- False Positive: 336
- True Negative: 412514
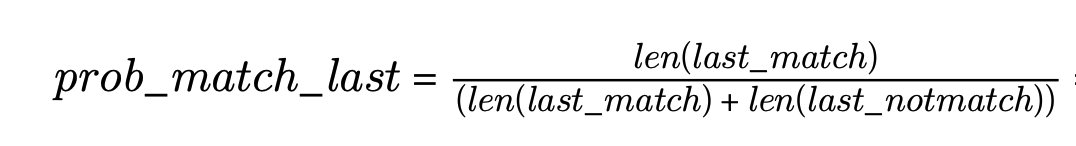
이제 Lastname이 매칭된 경우 실제로 같은 사람일 확률을 계산해보면, 648/(648+336) = 0.658 이 도출된다. 즉, Lastname이 일치하는 경우에 실제로 동일한 사람일 확률이 약 65%가 된다는 의미로, Firstname보다 매칭 과정에서 더 중요한 조건이 될 수 있다는 것을 알 수 있다.
Multiple Attribute Match Probability
이제 Firstname과 Lastname을 모두 고려하여 계산하려면, first_match 중에서 'Lmatch'행이 True, False인 것을 기준으로 필터링해서 계산하면 된다.
- True Positive: 634
- False Negative: 2
- False Positive: 1925
- True Negative: 419589
이 결과, Firstname보다 Lastname이 일치할 때 더 많은 가중치를 부여할 수 있다는 것을 확인할 수 있고 exact matching보다 개선된 방식을 적용할 수 있다.
Probabilistic Models
지금까지 계산한 방식들은 현재 사용한 데이터가 Constituency라는 정답을 명확하게 알 수 있는 matching 조건이 있기 때문에 적용할 수 있었다. 그러나 현실 세계의 데이터는 대부분이 이러한 조건이 주어지지 않는다. 아래는 여러가지 확률론적 기법의 개념들을 설명하고, 이를 entity resolution에 적용하는 방법을 다룬다.
1️⃣ Bayes’ Theorem
우선 베이즈 정리를 통해 두 레코드가 동일 인물인지 판단하는 과정을 살펴보겠다. Firstname이 같다는 정보만 있을 때, 실제로 두 인물이 동일인물인지 판단할 수 있는 확률은 P(match|first)로 표현된다.
베이즈 정리는 기본적으로 좌측과 같은 형태인데, 이를 이름 예시에 적용하면, A는 우리가 알고 싶은 사건, 즉 실제로 동일인물일 확률을 의미하고, B는 우리가 관측한 증거로 firstname 이 된다.

이때 P(first)는 동일인물인데 이름이 같을 확률과 동일인물이 아닌데 이름이 같을 확률을 더한 값으로 계산할 수 있다.

따라서 이를 우리가 구하고자 하는 P(match|first) 수식에 대입하면 다음과 같다.

즉, 베이즈 정리를 활용하면 실제로 동일한 인물의 이름이 같을 확률, 다른 사람인데 이름이 같을 확률, 기본적으로 같은 사람일 확률 등의 정보들을 조합해서 우리가 구하고자 하는 조건의 확률을 추측할 수 있다는 것이다.
2️⃣ m Value
m Value는 매칭된 레코드 중에서 특정 속성이 같을 확률로, P(first|match)를 의미한다. 같은 사람이라면 이름이 같을 확률도 높기 때문에 m의 값은 높아지고, m이 1에 가까울 수록 데이터의 품질이 높다는 것을 의미한다.
3️⃣ u Value
u Value는 매칭되지 않는데 속성이 같을 확률을 나타내며 P(first|notmatch)를 의미한다. 즉, 동일 인물이 아니더라도 이름은 같은 동명이인이 존재할 수 있기 때문에 u값이 존재하며, 이 값이 높다는 것은 해당 속성이 개체를 구분하는데 유용한 정보가 아니라는 것을 의미한다.
4️⃣ Lambda (λ) Value
람다 Value는 데이터셋에서 무작위로 두 레코드를 뽑았을 때, 그 둘이 동일할 확률로 P(match)를 의미한다. m, u Value와 달리, 속성과 관계 없이 전체 매치 확률을 나타낸다. 즉, 데이터셋에 중보이 얼마나 있는지를 나타내며, 중복 레코드가 거의 없으면 람다 값은 작아진다. 또한 두 레코드가 서로 다를 확률은 1 - λ = P(not match)로 구할 수 있다.
5️⃣ Bayes Factor
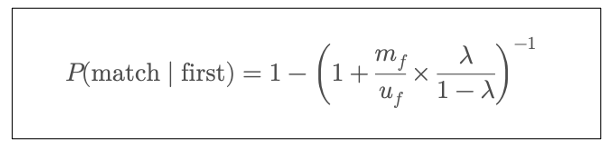
베이즈 팩터값은 m, u, λ값을 활용하여, 이름이 같을 때 실제 동일인물일 확률을 계산할 수 있다. 이때 베이즈 팩터는 m/u이며, 이 값이 클 수록 이름이 같다면 동일 인물일 확률이 높아진다.
6️⃣ Fellegi-Sunter Model
Fellegi-Sunter 모델은 베이즈 기반 접근을 여러 속성에 적용해서 전체 매칭 확률을 계산하는 방법이다. 이 모델은 속성들이 서로 독립적이라고 가정하는 naive Bayes를 기반으로 하며, 각 속성의 베이즈 팩터(m/u)를 곱해서 판단 근거를 만든다.
예를 들어, 속성 2개가 모두 일치하는 경우, mf/uf는 Firstname이 같을 때의 베이즈 팩터이고, ml/ul은 Lastname이 같을 때의 베이즈 팩터로, 이들을 곱해서 전체 매치 확률을 계산할 수 있다.
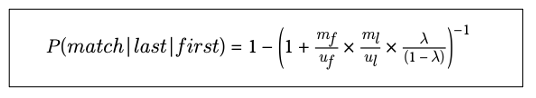
만약, 일부 속성이 불일치할 경우, 해당 속성의 베이즈 팩터를 반대로 놓고 곱해주면 된다.
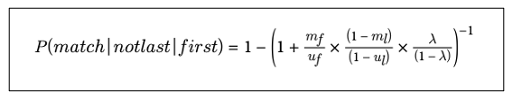
7️⃣ Match Weight
매치 가중치는 여러 속성의 정보를 덧셈 방식으로 계산할 수 있도록 로그 변환을 진행한다. 베이즈 팩터는 곱셉으로 계산하기 때문에 여러 속성값을 조합하면 복잡도가 높아지는데, 로그를 취하면 곱셈이 덧셈으로 바뀌기 때문에 복잡도가 낮아진다.
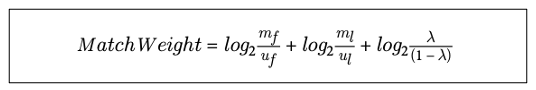
매치 가중치를 확률로 바꾸면 아래와 같으며, MatchWeight가 높을 수록 확률도 1에 가까워진다.
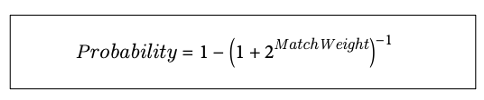
Expectation-Maximization Algorithm
EM 알고리즘은 매치된 레코드 쌍이 정확히 무엇인지 모르는 상황에서 λ, m, u 값을 확률적으로 추정할 수 있게 한다. 이 알고리즘은 반복적인 수행을 통해 최종 값에 추렴된다.
Iteration1
초기 가정으로, Tmatch가 2이상인 것(성, 이름, 선거구 중 2개 이상 매칭되는 것)을 match라고 가정한다. 이를 통해 람다를 계산하면 lmbda1 = len(it1_match)/len(cross) 0.15가 도출된다.

m, u value도 각각의 속성에 따라서 계산하면 위와 같은데, Constituency의 경우 정답 속성이기 때문에 m value는 1이되고(match 중에 실제로 Constituency가 같을 확률은 1이므로) u value는 0이 된다(match 중에 실제로 Constituency가 다를 확률은 0이므로).
# Helper function to calculate probability based on match features
def match_prb(Fmatch,Lmatch,Cmatch,mf1,ml1,mc1,uf1,ul1,uc1, lmbda):
if (Fmatch==1):
mf = mf1
uf = uf1
else:
mf = (1-mf1)
uf = (1-uf1)
if (Lmatch==1):
ml = ml1
ul = ul1
else:
ml = (1-ml1)
ul = (1-ul1)
if (Cmatch==1):
mc = mc1
uc = uc1
else:
mc = (1-mc1)
uc = (1-uc1)
prob = (lmbda * ml * mf * mc) / (lmbda * ml * mf * mc + (1-lmbda) * ul * uf * uc)
return(prob)이후 각 레코드 쌍에 대해 실제 match 확률을 추정하기 위해 다음과 위 함수를 통해 'prob' 컬럼의 값을 계산해준다.
Iteration2
위에서 계산한 'prob'에서 이제 확률이 0.99 이상인 행은 match라고 분류한다. 현재 실습 데이터의 경우, 매칭되지 않는 행은 14행이고 이들은 Firstname만 다른 상태이다. 그러나 Firstname은 매칭 과정에서 중요한 속성이 아니므로 가중치가 적게 계산되고, 이에 따라 매치 확률에 미치는 영향이 크지 않다. 따라서 교안과 달리, 2025년 기준으로 실습한 자료에서는 100%매치가 이루어졌다.
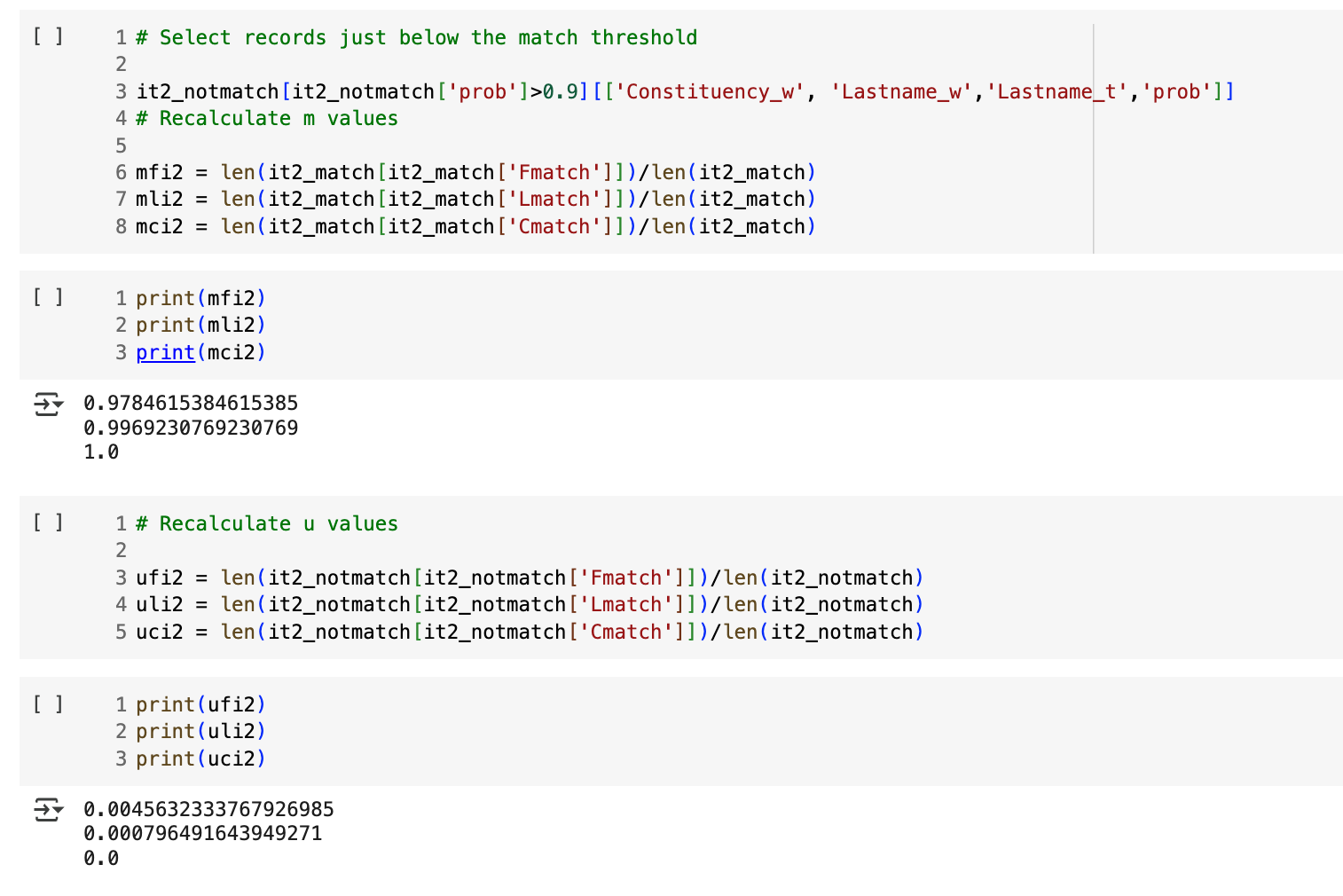
m, u, λ 값도 이전과 크게 다르지 않다.
Iteration3
교안에서는 Iteration3까지 진행하지만, 사실상 실습 과정에서는 이미 값이 수렴된 것 같다. 이 과정을 다시 정리해보면 다음과 같다.
- Firstname, Lastname, Constituency만 활용해서 두 레코드가 같은 사람인지 판단하고 싶음
- 실제 정답은 모르므로 EM 알고리즘을 활용해서 확률적으로 매칭을 수행
- 초기에 exact match를 통해 Total Match값을 구하고 2이상이면 match로 판단, 나머지는 notmatch로 분류
- match, notmatch 집합으로부터 m, u, λ값을 계산
- 이 값들을 활용해서 match 확률 계산
- 계산한 확률값으로 다시 match, notmatch 분류
- 동일한 작업을 결과값이 수렵할 때까지 n 번 반복
Introducing Splink
Splink는 확률론적 entity resolution을 위한 Python 라이브러리이며, Fellegi-Sunter 모델과 다양한 시각화 등을 지원한다. Splink는 DuckDB, SQL 등과 같은 연산을 위한 다양한 백엔드 엔진을 지원한다.
Splink Setting과 관련된 내용은 다음 챕터에서 좀 더 자세히 다루도록 하고, 여기서는 결과 해석을 위주로 살펴보겠다.
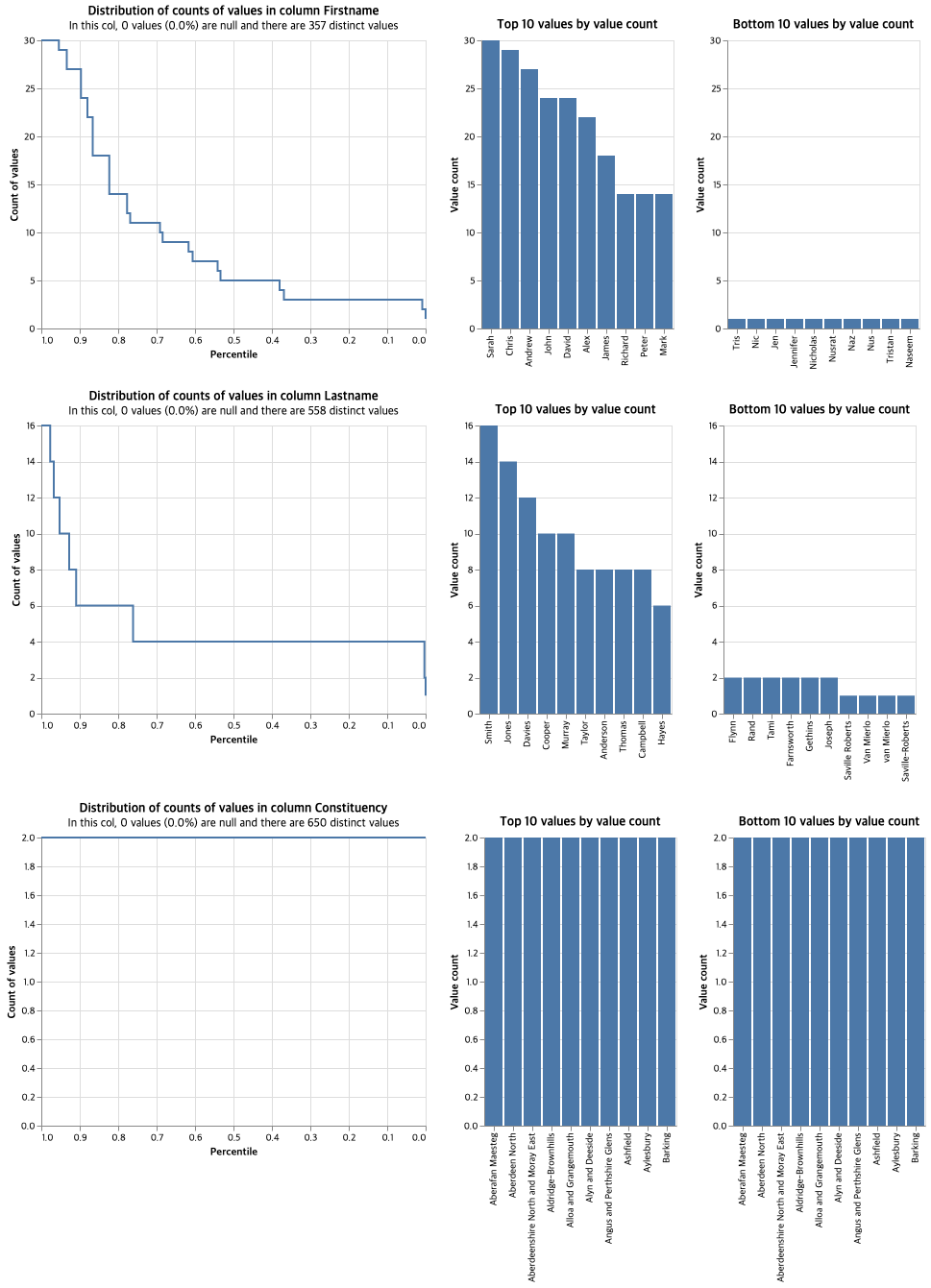
Firstname 컬럼의 경우 null은 0이고 357개의 서로 다른 값이 있다. 650행의 레코드를 매칭할 때 이 속성 하나만으로는 부족하다는 것을 확인할 수 있다. Lastname의 경우 574개의 유니크 값이 있고, 약 80% 정도가 두번만 반복되는 양상을 보여 매칭에 더 중요한 속성이 된다는 것을 알 수 있다. Constituency는 알고 있듯이 모두 고유한 값이다.
em_session = linker.estimate_parameters_using_expectation_maximisation(
'True',
fix_u_probabilities=False,
fix_probability_two_random_records_match=False,
populate_probability_two_random_records_match_from_trained_values=True
)이후 EM 알고리즘을 통해 계산하는 코드는 위와 같다. True는 Blocking 없이 전체 레코드 쌍을 비교하는 파라미터이고, fix_u_probabilities=False는 매 iteration 마다 u값을 다시 계산하고, fix_probability_two_random_records_match=False 은 람다값도 매 iteration 마다 갱신한다는 의미이다. 마지막으로 populate_probability_two_random_records_match_from_trained_values=True는 계산된 람다를 확률 계산에 실제로 적용한다.

결과를 보면, iteration3에서 수렴해서 더 이상 match/nomatch 분류가 크게 변하지 않는다는 것을 알 수 있다.
결과를 시각화 하면 다음과 같다.
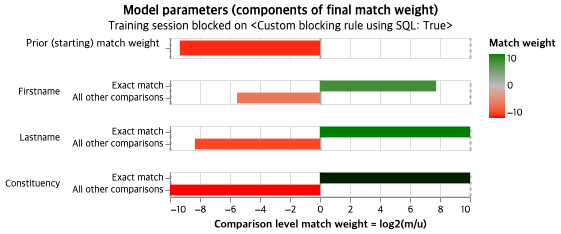
iteration 횟수에 따른 차이를 비교할 수 있는 동적인 시각화인데, 위에서 언급했듯 iteration2에서 이미 수렴했기 때문에 2와 3의 차이는 나타나지 않았다. 또한 어떤 속성의 weight가 높은 지 확인할 수 있다.
.
.
.
지금까지 두 데이터세의 레코드를 조합해서 전체 비교쌍을 생성하고 exact match를 통해 Firstname, Lastname, Constituency의 일치 여부를 계산했다. 이후 m, u, 람다 값을 기반으로 베이즈 팩터를 계산하고, 속성별 가중치를 곱해서 전체 match 확률을 계산했다. 또한 EM 알고리즘을 Splink 라이브러리를 사용하여 반복적으로 계산한 뒤 수렴값을 구하는 작업을 진행했다. 이 과정들은 정답 레이블이 없어도 속성 일치율을 기반으로 Entity resolution을 확률적으로 진행하는 시스템이다.
