
작년에 Reasoning 과제를 하면서 읽었는데, LLM 트렌드를 전체적으로 잘 정리해서 설명하고 있는 논문이라고 생각했다. 이번 기회에 다시 읽으면서 주요 개념들을 정리해보았다.
Reasoning
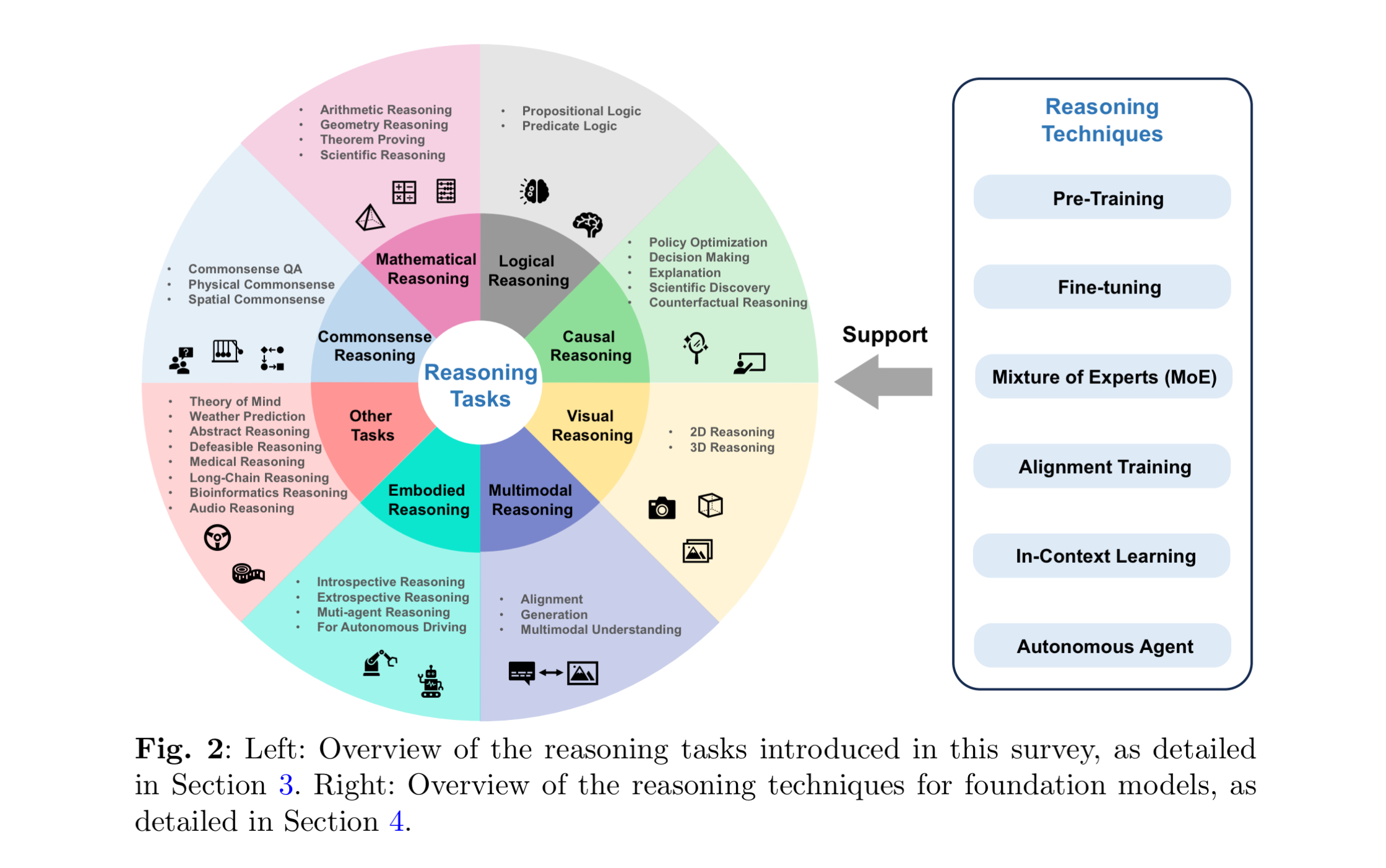
Reasoning Tasks를 8가지 분야로 구분하여 설명하고, Reasoning을 지원(support)하는 기술로 사전학습, 미세조정, 문맥 내 학습, 에어전트 등을 제시한다. 개인적으로 이해하기로는, 이러한 기술들을 모델에 적용함에 있어 Reasoning, 즉 추론은 기반이 되며 함께 수행되어야 한다는 것으로 이해된다. 예를 들어, 모델의 fine-tuning을 할 때에도 CoT와 같은 Reasoning을 적용해서 데이터셋을 마련한다면 성능이 더욱 향상될 수 있다는 것이다. Agent도 ReACT와 같은 Reasoning을 함께 사용할 수 있다.
Definition of Reasoning
- 철학(Philosophy)적 관점
인지 추론은 지식의 획득 및 업데이트부터 결론 도출까지의 모든 프로세스가 적절한 하드웨어에서 구현 가능하고 실행 가능해야 하는 지식의 표현과 관련된 불완전하고 일관성 없는 지식에도 불구하고 의미 있는 결론을 도출할 수 있는 인간 능력을 모델링하는 것을 의미합니다. - 논리Logic)적 관점
논리적 추론은 전제와 이러한 전제 간의 관계를 기반으로 결론을 체계적으로 도출하여 결론이 논리적으로 암시되거나 필연적이라는 것을 보장하는 사고 과정을 포함합니다. - NLP(자연어 처리)적 관점
자연어 추론은 여러 지식(예: 백과사전적 지식 및 상식적 지식)을 통합하여 (현실적이거나 가상적인) 세계에 대한 몇 가지 새로운 결론을 도출하는 프로세스입니다. 지식은 명시적이거나 암시적인 소스로부터 파생될 수 있습니다. 결론은 세상에서 참이라고 가정되는 주장이나 사건, 또는 실제적인 행동이다.
정리하면, '불완전한 지식에서 의미있는 결론을 체계적으로 도출하고 다양한 지식을 통합하여 새로운 결론을 이끌어내는 과정' 정도로 볼 수 있을 것 같다.
귀납적(Inductive), 연역적(Deductive), 귀추적(Abductive) Reasoning

연역적(Deductive) 추론은 일반 원칙이나 전제(Fact1)에 논리적 규칙(Rule)을 적용해서해서 구체적인 결론(Fact2)를 도출하는 논리적 과정이다.
귀납적(Inductive) 추론은 특정 관찰이나 증거를 바탕으로(Fact1 + Fact2) 일반적인 결론이나 패턴(Rule)을 도출하는 빙법이다.
귀추적(Abductive) 추론은 관찰된 사실이나 데이터(Fact2)를 설명하기 위해 그럴듯한 설명이나 가설(Fact1 + Rule)을 만드는 과정이다.
Foundation Model Techniques
Foundation Model, LLM, Multi-modal model, Vision-model 등등 현재 AI 모델들을 지칭하는 단어가 굉장히 다양하고 실제로 적절하지 않게 사용되고 있는 단어들도 많아서 혼란이 가중되는 것 같다. 이 논문에서는 Foundation model을 기본적으로 대규모 데이터셋으로 (pre)trained된 모델로 정의하고 이때 사용한 데이터셋의 유형과 처리할 수 있는 유형(범위) 따라서 다음과 같이 세가지로 분류한다.
- Language Foundation Models: 텍스트 기반
- 문장 완성, 번역, 요약 등 텍스트 기반의 작업을 수행할 수 있음
- e.g. GPT-3, PaLM, Bard, Llama2 etc.
- Vision Foundation Models: 이미지(영상 포함) 기반
- 이미지 생성, 분류, 캡셔닝, 객체 참지, 영상 이해 등의 작업을 수행할
수 있음 - e.g. SAM, Vision Transformer
- 이미지 생성, 분류, 캡셔닝, 객체 참지, 영상 이해 등의 작업을 수행할
- Multimodal Foundation Models: 텍스트 + 이미지 기반
- text-to-image, text-to-code, speech-to-text 등 텍스트와 이미지를 같이(align)처리할 수 있음
- e.g. CLIP, GPT-4v, Text2Seg
이 논문이 쓰여진 당시에는 GPT-4 Vision모델이 있었지만, 현재는 GPT-4o나 그 이상 모델, Claude3.5 Sonnet과 같은 모델들은 대부분 multi-modal로 학습되며 오픈소스 모델 중에서도 이미지를 처리할 수 있는 모델들이 많이 공개되고 있다. 사실 더 이상 이러한 구분이 크게 중요하지 않다고도 생각된다.
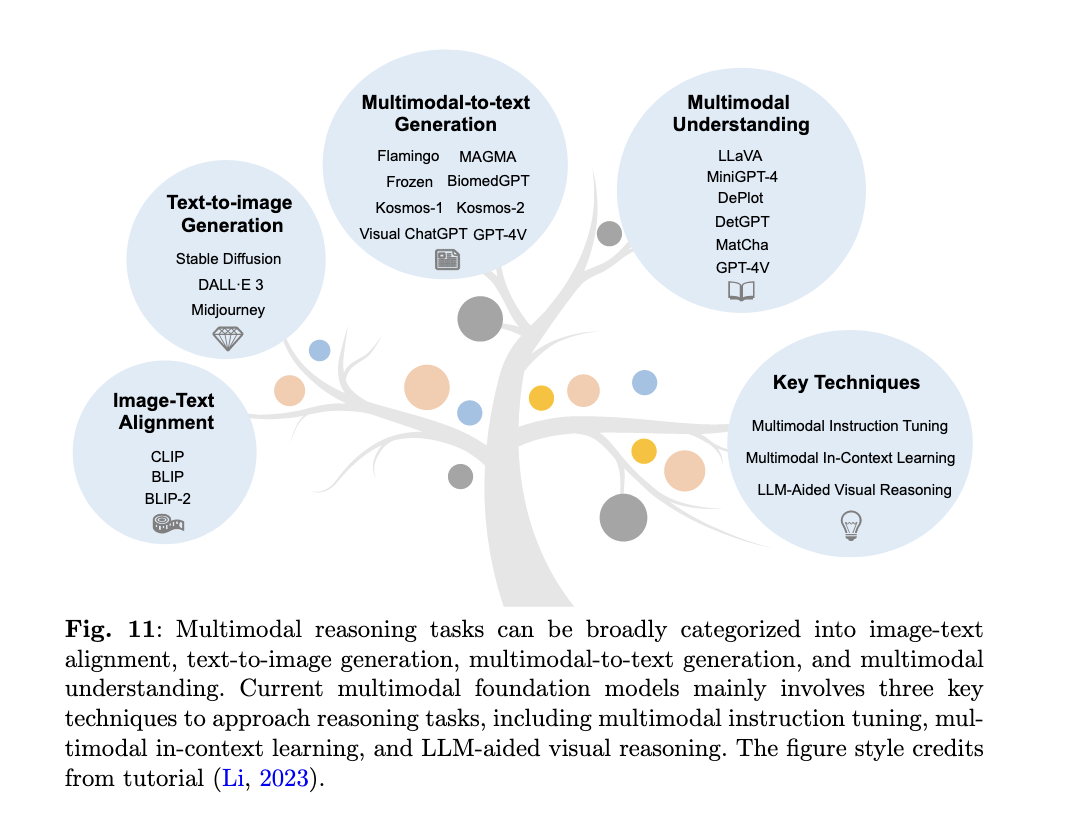
Multimodal reasoning은 다양한 형식의 정보를 통합하고 추론하는 인지 과정을 의미한다. 이는 인간이 세상을 인식하는 방법과 유사하기 때문에(사람은 오감을 통해서 인식하고 이를 기반으로 추론을 할 수 있음) 이러한 접근이 모델의 성능을 높여줄 수 있다는 것은 자명한 사실이 될 수 있다.
간단하게만 각 기술들을 정리하면 우선, Image-Text Alignment의 예시로 CLIP이 제시된다. CLIP은 텍스트 라벨링이된 이미지가 학습된 모델로 이미지의 벡터를 생성하고 이 벡터와 텍스트 벡터와의 유사도를 계산해서 가장 유사도가 높은 텍스트 벡터를 찾는 방식을 의미한다. Generation 부분에서는 text로 image를 생성하는 Diffusion 모델이나, 이미지 혹은 영상에서 텍스트를 생성하는 등의 접근이 이뤄진다. Multi-modal understanding은 현재 gpt-4o 기반의 ChatGPT에 이미지 혹은 문서를 넣고 이와 관련된 설명을 해달라는 요청을 했을 때 처리할 수 있는 것을 의미한다.
🐬 Pre-Training
Pre-Training은 text, image, multimodality data 등 대량의 데이터를 기반으로 기본적인 언어 이해와 생성을 가능하도록 하게 한다.
최근 개발되는 모델들은 기본적으로 Transformer를 기반으로 구성되는데, Pre-Training 아키텍쳐를 어떻게 구성하는 지에 따라 Encoder-decoder 구조, Encoder 혹은 Decoder-only 등으로 구분한다.
🐬 Fine-Tuning
Fine-Tuning은 대규모 데이터로 학습된 LVM 혹은 VLM을 그보다는 적은 규모의 데이터를 활용해 세부 목적, 즉 다운스트림 태스크에 적합하도록 파라미터를 업데이트 하는 방법이다. Fine-Tuning은 파운데이션 모델의 대부분의 파라미터를 조정해야 하므로 많은 컴퓨팅 리소스가 사용된다는 한계가 있으며, 데이터 양이 적을 경우 과적합(Overfitting)의 위험이 존재한다. 이의 대안으로, 모델의 일부 파라미터만 조정하는 ETL(Efficient Transfer Learning)이 제안되었고, 현재 활발하게 적용되고 있다.
Synthesis Data
모델을 학습하는 데이터를 크롤링과 같은 방법으로 수집할 수 있으나, 원하는 방향으로의 학습(Instruction Tuning, Reasoning 기반, 기타 domain-specific fine-tuning 등)을 하기 위해서는 데이터를 생성해야 한다. 이때 LLM을 통해서 데이터를 생성하는'데이터 합성(data synthesis)'을 적용할 수 있으며, 효과적이고 고품질의 데이터를 생성하기 위해 다양한 방법으로 접근한 연구들이 많이 이뤄지고 있다.
PEFT (Parameter Efficient Fine Tuning)
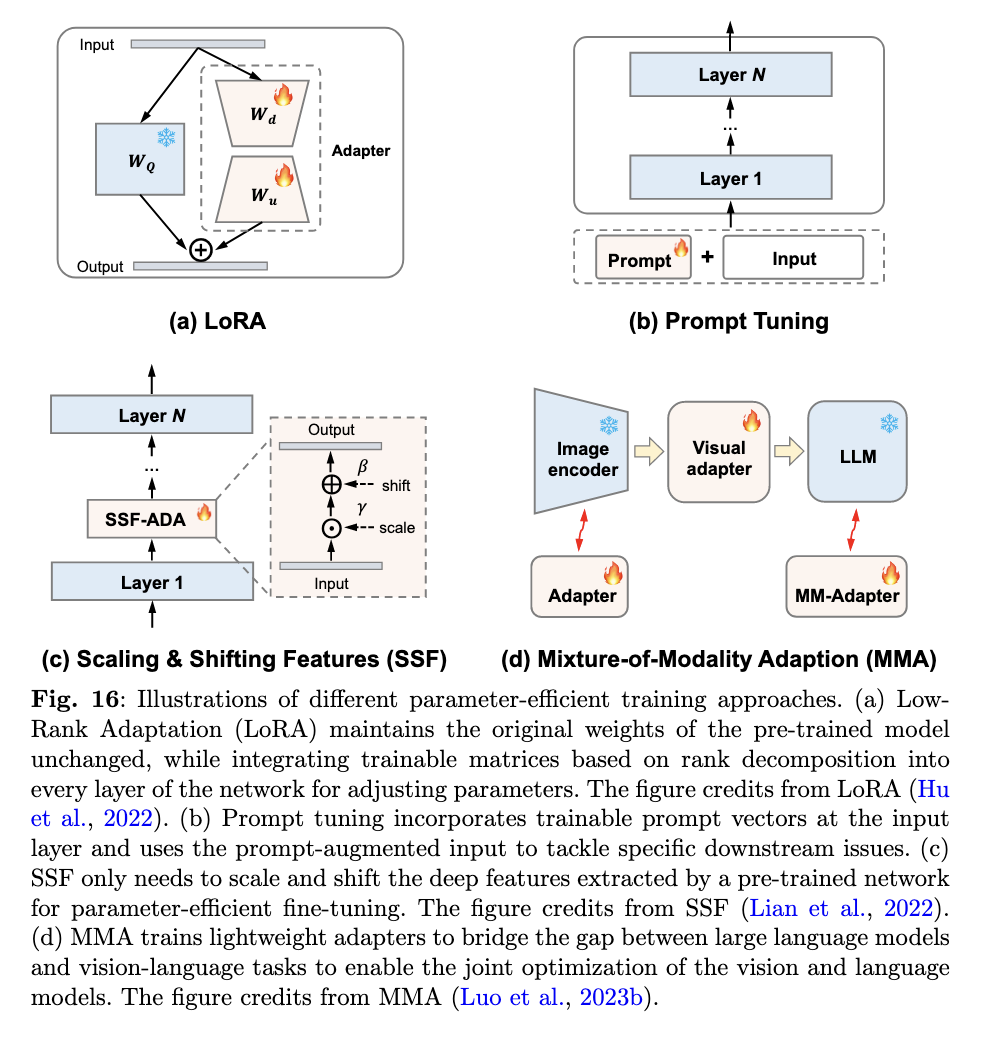
ETL은 크게 프롬프트 튜닝과 어댑터(Adapter) 스타일로 구분된다. 프롬프트 튜닝은 자연어 처리 분야에서 시작된 방법으로 입력 프롬프트에 템플릿을 통해 다양한 작업을 정형화한다. 예를 들어, Zero-shot CLIP은 "a photo of a Class"와 같은 간단한 수동 프롬프트 템플릿을 도입하여 높은 성능을 달성했다. CoOp은 최초로 학습 가능한 프롬프트를 도입하여 few-shot 작업에 특화된 지식을 전이하였으며, 이후 일반화, 지식 프로토타입, 증강, 다양성 등 여러 관점에서 프롬프트 튜닝이 개선되었다. 어댑터 스타일 튜닝은 텍스트와 시각적 특징을 조정하는 층(layer)를 추가하여 일부 파라미터만 업데이트 하는 방식으로 작동한다. 대표적으로 CLIP-Adapter는 하나의 병목 층을 사용하여 few-shot 분류의 성능을 향상시켰고, TaskRes는 사전 학습된 모델의 사전 지식과 작업별 지식을 분리하기 위해 작업 독립적인 어댑터를 도입했다.
ETL은 적은 양의 데이터로도 효과적인 학습이 가능하며, 컴퓨팅 리소스를 적게 사용하면서도 뛰어난 성능을 낼 수 있다는 점에서 매우 유용한 접근 방식으로 평가받고 있다.
Adapter Tuning
기존 모델의 파라미터는 업데이트 하지 않고, 일부 파라미터만 조정하는 'adapter'를 붙여서 성능을 높이는 방법이다. LoRA(Low-Rank Adaptation) 이 개념을 기반으로, 학습 가능한 rank decomposition 매트릭을 Transformer 구조의 각 계층에 도입하는 작업이 포함된다.
Prompt Tuning
Prompt Tuning은 모델의 입력으로 주어지는 프롬프트 벡터를 학습 가능한 형태로 만들어서(hard prompting, soft prompting) 특정 작업에 맞게 최적화 하는 기법이다 .
Partial Parameter Tuning
adapter를 붙이는 방식이 아닌 특정 파라미터만 선택해서 조정해주는 방식이다.
Mixture-of-Modality Adaption
🐬 Alignment Training
Alignment Training은 human feedback을 기반으로 모델을 최적화하는 방법이다. (순서 상 Post-training에 해당하며, RLHF, DPO 등을 의미한다고 생각했는데, 넓게는 SFT에도 포함되긴 한다. 이 부분은 더 알아보고 정리해야 할 것 같다.)
🐬 Mixture of Experts (MoE)
MoE는 LLM을 더 작은 하위 모델로 분해해서 각각을 fine-tuning해서 하나의 전문가들로 만드는 방법이다(Multi-Agent와 비슷한 개념인데, 각각을 FT하는 것으로 이해했다).
🐬 In-Context Learning
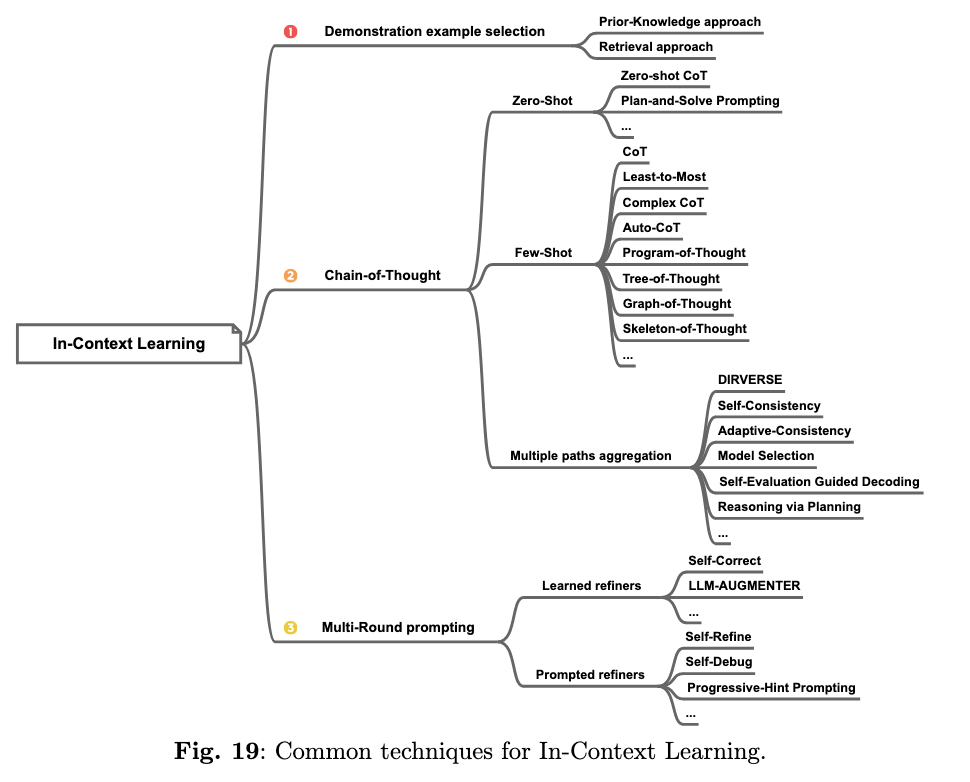
In-context learning은 파라미터를 수정하지 않고 태스크에 대한 설명이나 일부 예시를 프롬프트를 통해 제시해서 성능을 향상하는 방법을 의미한다.
Instruction Tuning과 ICL은 모두 자연어를 활용한다는 점에서 연관성이 있지만, IT는 파라미터를 수정한다는 점에서 fine-tuning에 해당하므로 차이가 있다.
프롬프트에 넣는 예시는 모델의 성능에 큰 영향을 미치므로 신중하게 선택되어야 하는데, 이때 예시를 선택하는 방법은 크게 (1) Prior-Knowledge approach 와 (2) Retrieval approach로 구분하여 설명한다. Prior-Knowledge approach는 휴리스틱하게 예제를 선택하는 방법이며, Retrieval approach는 LLM에 넣어주는 예제를 또다른 LLM으로 선정하고 확률에 따른 랭킹을 통해 선정하는 방식을 의미한다.
Chain-of-Thought는 Google이 처음 제시한 방법으로, 'let's think step by step'과 같이 태스크의 진행 과정을 순차적으로 생각하고 처리할 수 있도록 하는 방법이다. 이때 위와 같은 문구만 넣어주고 예시를 제시하지 않으면 Zero-shot CoT, 몇 가지 추론 프로세스 예시를 포함하면 Few-Shot CoT라고 한다. Multi paths Aggregation은 여러가지 추론 프로세를 거친 결과들을 종합하여 최종 결론을 생성하는 방식이다.
마지막으로 Multi-Round Prompting은 여러 단계를 거쳐 답변을 생산하는 등 한 번의 답변 프로세스가 아닌, 여러번의 답변을 점진적으로 개선해나가는 방식을 의미한다. (답변-피드백-수정/개선-재답변 반복 or 이전 답변 기반의 자체 개선 프로세스)
🐬 Autonomous Agent
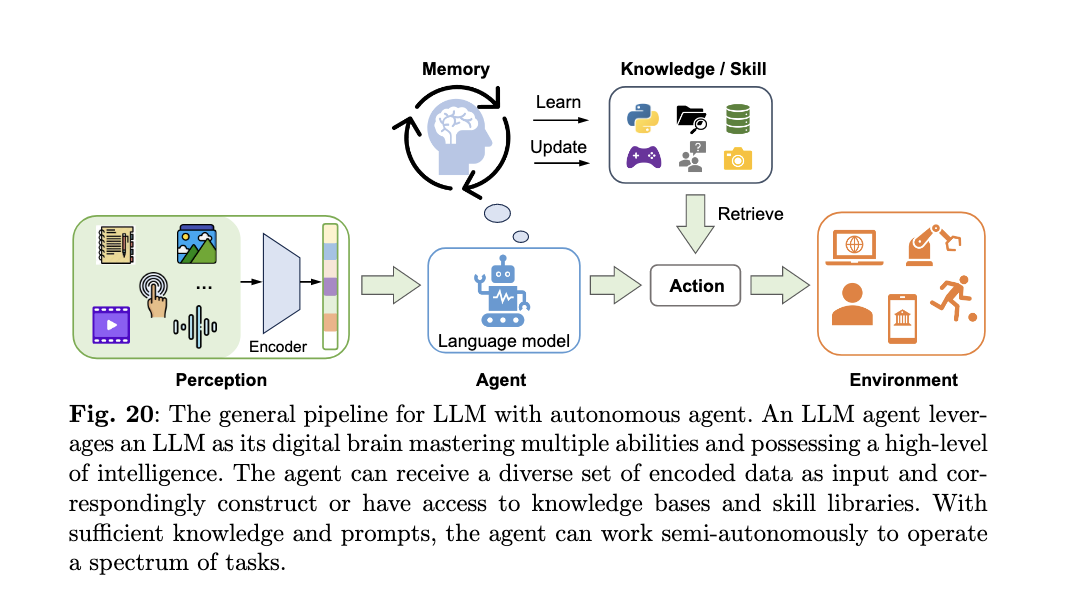
최근 가장 이슈인 Agent의 핵심은 '자율성(Autonomous)'이다. Agent의 정의와 범위에 대해서 여전히 많은 주장과 논의가 이루어지고 있지만, 해당 논문에서는 LLM을 활용해서 광범위한 지식, 추론 기술 및 방대한 정보 리소스를 활용하여 자율적으로 작업을 수행하는 것으로 설명하며 비교적 그 범위를 넓게 보고 있는 것 같다.
Agent와 관련된 설명은 이전 포스트에서 자세히 다뤘다.
[추가]
Agent에 대한 다양한 설명들(관점들이 조금씩 다름)
