[논문리뷰] KARMA: Leveraging Multi-Agent LLMs for Automated Knowledge Graph Enrichment
Paper Review

본 논문은 기존에 존재하는 지식그래프에 새로운 소스의 정보를 추가하여 지식을 확장하는, Knowledge Graph Enrichment를 수행하기 위한 Multi-agents 기반 프레임워크인 KARMA를 소개한다. 개별 에이전트들은 지식을 추출하고, 검증하며 개념적 충돌을 없애는 등을 작업을 수행하고, 모듈형으로 설계되어 확장적이고 동적인 활용이 가능하다는 특징을 장점으로 설명한다.
System Overview
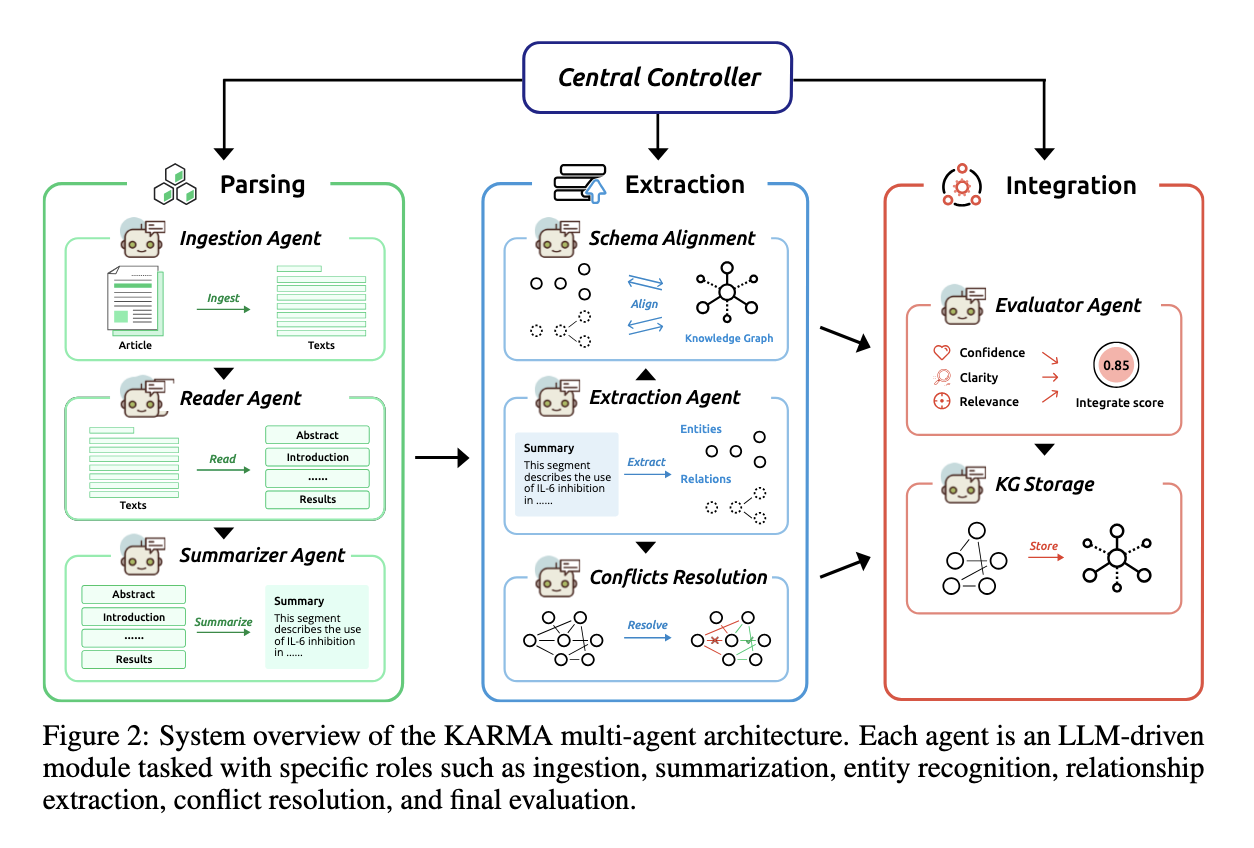
KARMA는 병렬적인 여러개의 에이전트들로 구성되며, 하나의 Central Controller가 전체 프로세스를 Orchestration하고 관리한다. 개별 에이전트는 특정 기능에 특화되어 최적화된 상태이다.
- Ingestion Agents(IA)
: PDF, HTML 등과 같은 raw puclications에서 텍스트를 읽어서 정규화하고(OCR 오류 수정 등), 저자, 저널, 출판일 등의 메타데이터를 추출하는 에이전트 - Reader Agents(RA)
: 정규화된 문서를 섹션별로 분할하고(논문의 경우 abstract, methods, results 등) 각 세그먼트가 지식 추출에 얼마나 중요한지 관련성 점수를 매기며, acknowledgrments와 같은 불필요한 내용은 필터링하는 에이전트 - Summarizer Agents(SA)
: 관련성이 높은 텍스트 세그먼트를 간결하게 요약하는 에이전트로, 이후 단계에서 관계 정보를 추출할 때 계산 부하를 줄이기 위해서 개체 간의 관계 정보는 그대로 유지함 - Entity Extraction Agetns(EEA)
: 요약된 텍스트에서 프롬프트를 기반으로 엔티티를 식별하고(LLM-Based NER), 이를 온톨로지에 기반한 표준화된 식별자로 정규화(Entity Normalization; 임베딩 벡터로 유사도 측정하여 판단하는 방식)하는 에이전트 - Relationship Extraction Agents(REA)
: 식별된 엔티티들의 관계를 추출하는 에이전트로, n개의 관계(multi-label)도 식별할 수 있음 - Schema Alignment Agents(SAA)
: 새로 추출된 개체나 관계가 기존 지식 그래프의 스키마 유형에 맞는지 확인하고 매핑하며, 일치하는 유형이 없으면 온톨로지 확장을 위해 표시하는 에이전트 - Conflict Resolution Agents(CRA)
: 새로 발견된 정보가 기존 지식과 논리적으로 모순되는지 감지하고, LLM 기반 토론을 통해(프롬프팅으로 debate하도록 설정) 해결 방안을 결정하는 에이전트 - Evaluator Agents(EA)
: 추출된 트리플들의 신뢰도(Confidence), 명확성(Clarity), 관련성(Relevance)을 종합적으로 평가하여 최종적으로 지식 그래프에 통합할지 여부를 결정하는 에이전트
개별 에이전트의 프롬프트는 Appendix에서 확인할 수 있다.
Experimental Setup
Data Collection
테스트를 위한 데이터는 PubMed에서 'Genomics'를 주제로한 720개의 논문, 'Protemics'를 주제로한 360개의 논문, 그리고 'Metabolomics'를 주제로한 120개의 논문으로 했다. 모든 논문은 PDF 포맷이다.
LLM Backbones
KARMA는 GLM-4(오픈소스 모델; 9B), GPT-4o, DeepSeek-v3(오픈소스 모델; 37B MoE 모델) 총 세 개의 모델로 테스트 되었으며, 한 번의 테스트에는 모든 에이전트를 동일한 백본 모델을 사용했다고 한다.
각 에이전트 별로 역할이 다른데, 특정 역할에 최적화된 모델도 있을까? 예를 들어 엔티티 추출을 월등히 잘하는 모델이나, 요약을 특별하게 잘하는 모델 들... 비교를 위해서 동일한 모델을 사용했겠지만, 이러한 차이가 있는지 검토하면 더욱 정교한 에이전트 시스템을 만들 수도 있을 것 같다.
Metrics
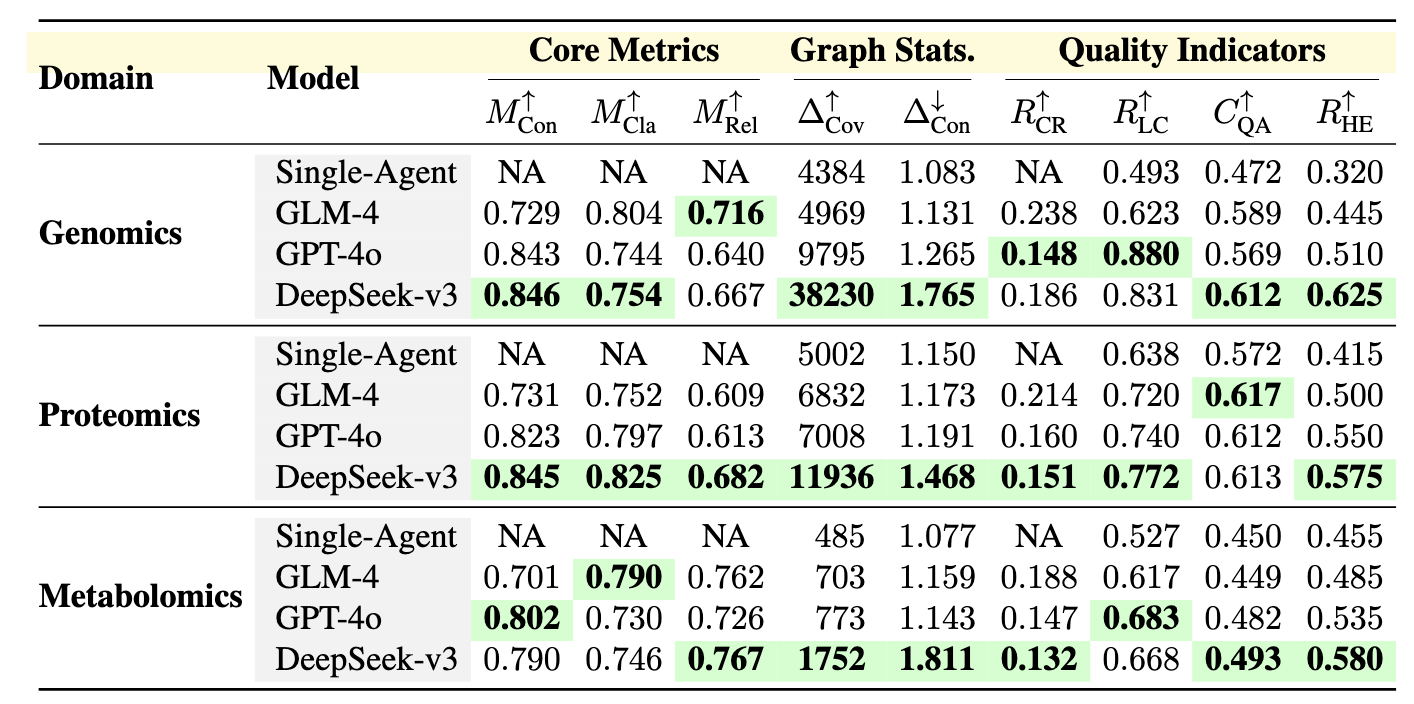
정답이 없는 환경에서 enrichment KG의 품질을 다각도로 평가하기 위해 (1) Core Metrics (2) Graph Statistics (3) Quality Indicators 세 가지 카테고리로 구성된 평가 프레임워크를 사용한다.
- Core Metrics
추출한 트리프의 자체의 내재적 품질을 측정한다.
- 평균 신뢰도: 새로운 트리플들이 얼마나 신뢰할 수 있는지에 대한 평균 점수
- 평균 명확성: 관계가 얼마나 모호하지 않고 직접적으로 표현되었는지를 측정
- 평균 관련성: 추출된 지식이 해당 도메인에서 얼마나 중요한지를 평가
- Graph Statistics
지식그래프가 구조적으로 얼마나 확장되었는지 측정한다.
- 커버리지 이득: 기존 지식 그래프에 없던 새로운 개체가 추가된 수를 의미하며, 지식의 범위가 얼마나 넓어졌는지 보여줌
- 연결성 이득: 노드 차수(degree)의 순 증가량을 측정하여, 그래프 내의 개체들이 얼마나 더 촘촘하게 연결되었는지를 나타냄
- Quality Indicators
신뢰성과 실용성을 다양한 관점에서 검증한다.
- 충돌 비율: 내부적 또는 외부적 모순으로 인해 충돌 해결 에이전트(CRA)에 의해 제거된 엣지의 비율. 이 수치가 낮을수록 데이터의 일관성이 높음을 의미함
- LLM 기반 정확도: 별도의 LLM(Hold-out LLM)이 추출된 트리플을 '정확함', '불확실함', '부정확함'으로 판정하여 계산한 정확도 점수
- QA 일관성: 지식 그래프를 탐색하여 도메인 관련 질문에 답할 수 있는 비율을 측정하여, 구축된 지식의 실용적 활용 가능성을 평가
- 인간 평가 점수: 두 명의 전문가가 0에서 1 사이의 척도로 정확성과 유용성을 직접 평가한 결과
.
.
.
(의문점)
순차적으로 수행되는 작업들을 각각의 프롬프팅 된 LLM을 사용하고 있는데, 이 각각을 Agents라고 할 수 있는걸까? 물론 Agents의 정의와 범위, 수준은 다양하지만, 자율성이 강조되는 특성을 기준으로 봤을 때, 이건 workflow에 가까울 수 있지 않을까 라는 생각을 했다.
