
LLM을 사용하여 KGs 구축을 schema-based와 schema-free 패러다임을 구분해서 검토하는 서베이 논문이다. 논문의 끝에는 LLM을 위한 KGs 기반 추론과 에이전트 시스템을 위한 다중 KGs 구성에 대한 내용도 다루고 있다.
✅ Introduction
일반적인 KGs 구축은 크게 다음 세 요소로 구성된다.
-
Ontology Engineering
OE는 도메인의 concepts(개념), relationships(관계), contrains(제약조건) 등을 정의하는 작업을 의미한다. 전통적으로는 인간 전문가의 수작업을 통해서 수행되었으며, 반자동 방식의 접근도 존재했으나, 모듈의 재사용이나 유연한 동적 적응에는 여전히 어려움이 존재했다. -
Knowledge Extraction
KE는 비정형 혹은 바정형 데이터에서 entity, relations, attributes을 식별하는 것을 목표로 한다. 이 방식 역시 패턴과 규칙 기반 혹은 딥러닝을 활용한 자동화가 시도되었으나, 데이터 부족, 일반화의 어려움 등의 제약이 존재했다. -
Knowledge Fusion
KF는 중복이나 일질성 문제를 해결하여 일관된 통합 그래프를 구축하는 작업으로, Entity Resolution을 포함한다. 기존의 접근 방식은 어휘와 구조적 유사성 기반이나 임베딩 벡터 가반의 유사도를 통해 수행되었으나, 의미론적 이질성이나 동적인 지식 업데이트 등의 챌린지를 갖고 있다.
전통적인 KGs를 구축할 때는 (1) Scalability and data sparsity: 지도학습 기반 시스템은 도메인별 적용이 어려움(범용적인 적용 불가능) (2) Expert dependency and rigidity: 온톨로지 디자인은 상당한 인간의 수작업이 필요함 (3) Pipeline fragmentation: 설계 단계의 오류가 전체에 큰 영향을 미침 등과 같은 어려움이 있다.
한편, LLM을 사용하면 비구조 텍스트에서 구조화된 표현을 구축할 수 있고 의미론적인 통일/통합이 가능하다. 또한 프롬프트 기반으로 복잡한 KGs를 보다 쉽게 구축할 수 있다는 장점이 있다. 이에 따라 LLM의 발전은 KGs 구축의 패러다임 자체를 바꿀 수 있으며, 본 논문은 이와 관련된 종합적인 서베이를 수행한다.
✅ LLM-Enhanced Ontology Construction
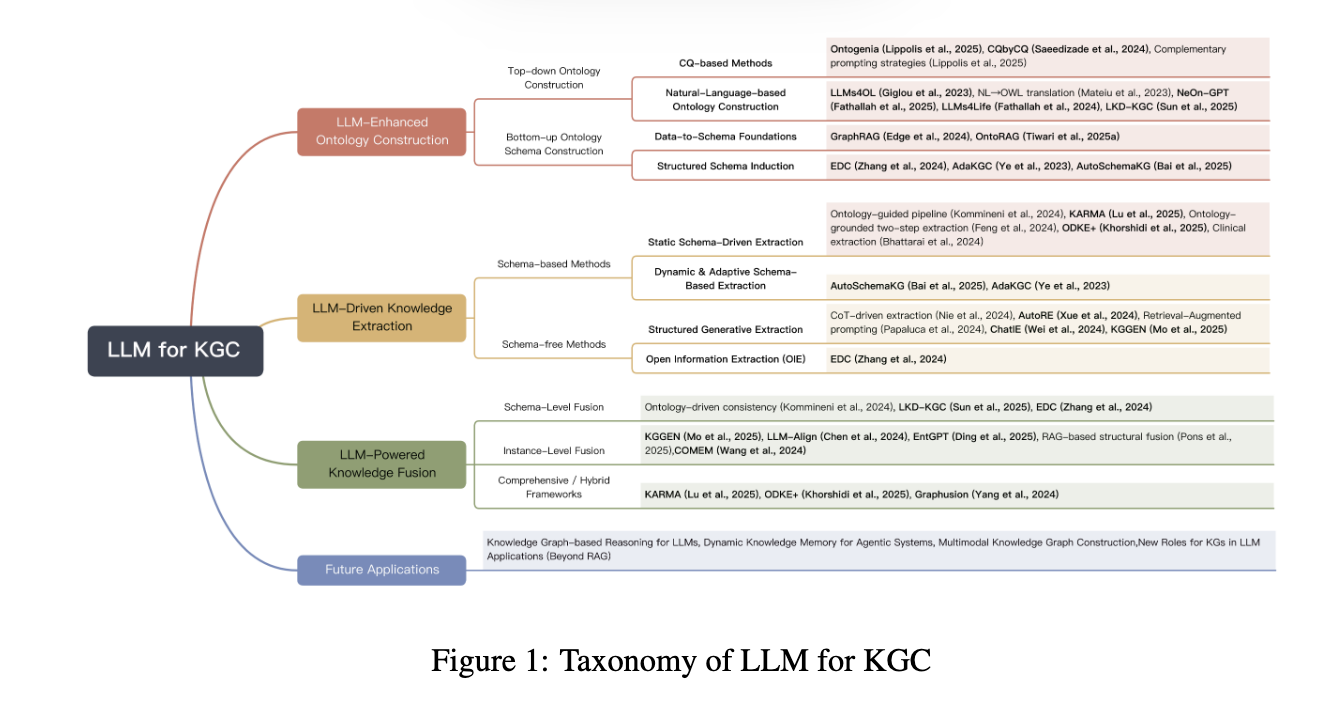
1️⃣ Top-Down Ontology Construction: LLMs AS Ontology Assistants
top-down 방식은 LLM을 온톨로지 모델링을 위한 지능형 보조자로 활용하는 접근법이다. 즉, LLM을 역량 질문(CQ; Competency Questions), 사용자 스토리 혹은 도메인 설명과 같은 자연어를 OWL이나 표준으로 변환할 때 인간 전문과와 공동 모델러 역할로 활용하는 것이다.
CQ기반 온톨로지 구축법은 요구사항 중심(requirements-driven) 온톨로지 구축 접근법으로, LLM이 CQ 또는 사용자 스토리를 분석하여 도메인 개념, 속성, 관계를 식별/분류/형식화한다. Ontegenia(Lippolis et al., 2025)는 메타인지 프롬프팅을 활용하여 온톨로지 생성과정에서 self-reflection과 구조적 오류 수정을 가능하게 하고 OLPs(온톨로지 설계 패턴)을 통해서 생성된 온톨로지의 일관성과 표현 복잡성을 향상시켰다. 즉, 온톨로지 전체 생명주기를 포괄하는 반자동 구축 파이프라인을 LLM을 통해 구성하고, 인간 전문가는 핵심 검증 지점에서는 개입하게 된다.
이전에 읽은 다른 논문에서 CQ와 관련된 내용을 정리한 적이 있어서 가져왔다.
CQ기반보다 확장된 방식인 자연어 기반 온톨로지 구축법은 명시적으로 정의된 질문에 의존하지 않고 비정형 혹은 반정형 텍스트 코퍼스 자체로부터 의미 구조를 직접 유도하는 것을 목표로 한다. 즉, LLM이 직접 텍스트를 분석하여 개념 계층과 관계 패턴을 발견하고 OWL과 같은 형식 논리에 직접 매핑하는 것이다. LLMs4Life(Fathallah et al., 2024) 시스템에서는 프롬프트 기반의 엔드투엔드 시스템을 통해 생명과학과 같은 도메인에서 깊이 있고 일관된 온톨로지 구축을 수행하였으며, LKD-KGC(Sun et al., 2025)는 문서 요약으로부터 추출된 엔티티 유형을 군집화하여 오픈 도메인 지식그래프 구축을 테스트하였다고 한다.
2️⃣ Bottom-up Ontology Schemna Construction: KGs for LLMs
bottom-up 방식은 온톨로지 구성을 사용하여 LLM 자체의 추론과 표현 기능을 향상시키는 접근법이다. 이 방식은 KGs를 정적으로 구조화된 지식 저장소로만 사용하는 것이 아니라 LLM의 사실적 근거를 제공할 수 있는 실질적인 동적 인프라로 사용하는 것을 목표로 한다. 따라서 개념적 스키마를 구축하고 인스턴스를 변환하는 top-down 방식과 달리, 비/반정형 데이터에서 인스턴스를 추출하고 그래프를 생성하여 스키마와 온톨로지를 자동으로 유도하는 방식으로 접근한다.
대표적인 예시인 GraphRAG와 OntoRAG는 우선 텍스트에서 인스턴스 수준의 그래프를 생성하고, 이후 클러스터링과 일반화를 통해 개념과 관계를 추상화한다. EDC(Extract-Define-Canonicalize; Zhang & Soh, 2024) 프레임워크는 3단계 구조를 통해 자동으로 유도된 스키마를 기존의 온톨로지와 alignment하거나, 새로운 온톨로지를 생성할 수 있게 한다. AdaKGC(Ye et al., 2023)은 재학습 없잉도 새로운 엔티티와 관계를 표현할 수 있는 동적 스키마를 통해 continuous adaptation 중심의 패러다임으로 전환할 수 있음을 보였다.
최근 연구에서는 실제 배포 가능한 지식시스템 구축을 시도하고 있는데, AutoSchemaKG(Bai et al., 2025)는 schema-based와 schema-free 접근을 통합한 구조를 제안하여 엔터프라이즈 규모 지식그래프의 실시간 생성과 진화를 지원한다. 이 단계에서 지식그래프는 LLM을 위한 외부 지식 메모리로 기능하며, 순수한 의미적 완전성보다는 사실 포괄성, 확장성, 유지관리성이 핵심 설계 목표이다. 이는 온톨로지 구축이 LLM의 추론과 해석 가능성을 지원하는 실용적 인프라로 재지향되고 있음을 의미한다.
정리하면, top-down 접근이 의미 모델링, 논리적 일관성, 전문가 중심 정합성을 강조하며 LLM을 온톨로지 설계 보조자로 위치시킨다면, bottom-up 접근은 자동 추출, 스키마 유도, 동적 진화를 중시하며 자기 갱신적이고 확장 가능한 지식 생태계를 지향한다. 이러한 흐름을 통해 LLM의 사실 기반 추론 능력과 해석 가능성을 강화하는 방향으로 나아가고 있음을 확인할 수 있다.
✅ LLM-Driven Knowledge Extraction
1️⃣ Schema-based methods
스키마 베이스 기법은 지식그래프를 구축하기 위해서 데이터에서 추출(extraction)하는 과정에서 명시적인 구조적 가이드와 제약조건을 기반으로 하는 방법이다. 이때의 스키마는 다시 정적인 형태와 동적인 형태로 구분된다.
우선, 정적인 스키마를 활용하는 방법은 사전에 정의된 청사진과도 같은 의미적 백본을 기반으로 LLM이 지식베이스를 생성하도록 한다. 앞서 언급됐듯, CQs와 같은 지식 범위를 한정짓는 질문들을 생성하여 완전한 TBox를 구성한뒤, 인스턴스 기반의 ABox를 채우는 방식으로 수행되기도 하고(e.g. KARMA(2025)와 같은 프레임워크는 멀티 에이전트 구조를 적용하여 이러한 과정을 수행함), 단계적 프롬프팅을 통해 엔티티나 태스크에 따라 선택적으로 온톨로지를 구성하는 방식도 존재한다(e.g. ODKE+) 이런 방식은 비교적 높은 정확도와 일관성을 갖지만 유연성이 떨어지고 도메인 일반화에 한계가 있다는 특징이 있다.
반면, 최근 연구들은 스키마를 고정된 제약 조건으로 두지 않고, 지식 추출 과정과 함께 진화하는(co-evolution) 동적 구성 요소로 정의하기도 한다. AutoSchemaKG(2025)는 대규모 코퍼스에서 비지도 클러스터링을 통해 스키마를 자동 유도하고, 관계 유형별 다단계 프롬프팅을 통해 스키마를 반복적으로 갱신하는 방식을 사용하고 AdaKGC(2023)는 스키마 정보를 반영한 프롬프트 설계와 재학습 없이 스키마를 반영하고 동적 디코딩을 결합하여 상황에 맞는 스키마 적응을 가능하게 했다고 한다.
여기서 언급되는 연구 논문들은 모두 각각 다시 확인해볼 필요가 있는 것 같다.
2️⃣ Schema-free methods
스키마 프리 기법은 사전에 정의된 템플릿 형태 제약 없이 지식그래프를 구축하는 방법으로, LLM을 엔티티와 관계를 식별할 수 있는 autonomous extractors로써 사용하겠다는 기본 아이디어를 갖고 있다.
이 중 구조화된 생성 추출 방식은 외부 스키마를 제공하지 않고 LLM의 프롬프트를 활용한 CoT, RHF(Relation-Head-Facts) 등으로 암묵적, 즉석 스키마를 구성하도록 한다. 이는,명시적인 스키마 없이도 LLM이 잠재적인 관계 구조를 파악하고, 추론 기반으로 지식 생성을 수행할 수 있음을 보여준다. 이와 달리, OIE(Open Information Extraction)는 스키마 유도 자체를 목표로 하지 않고, 모든 트리플을 가능한 많이 뽑은 뒤 구조적 정제(중복 제거, 정규화, 스키마 유도 등)는 후처리로 미루는 방식이다.
개인적으로 schema-free는 넥스트 레벨이다. 보수적으로 접근해서 스키마 프리까지는 나아가지 못했으므로 간단하게 정리하고 추후 돌아오겠다.
✅ LLM-powered Knolwedge Fusion
Knowledge Fusion은 서로 다른 출처에서 생성/추출된 이질적 지식을 정렬, 통합하여 중복없이 하나의 일관된 지식그래프로 결합하는 과정을 의미한다. 즉, 이미 추출된 지식을 대상으로 Entity Resolution 등을 통해 같은 의미면 묶고, 다른 의미면 구분하여 하나의 canonical relation으로 통합한다는 것이다. 기존에는 규칙기반이나 문자열 유사도, 임베딩 기반으로 수행했지만, 이는 확성성과 의미 이해에 한계가 있었다. 반면 LLM기반으로 수행할 경우 extraction이 훨씬 수행해졌기 때문에, LLM으로 추출하고 다시 맞추는 과정이 훨씬 수월해진 것이다. 이는 스키마 수준과 인스턴스 수준 모두에서 작업의 효율성을 높였고, 최근에는 이 둘을 구분하지 않는 hybrid 형식의 프레임워킄도 많이 제안되고 있는 상황이다.
