
추가 참고 자료
- LLM과 KG를 결합하고 상호 보완적으로 활용할 수 있다는 유사한 관점의 참고 논문: Unifying Large Language Models and Knowledge Graphs: A Roadmap(2024)
- LLM의 pre-training, inference, post-generation 부분에서 KG의 적용 가능성을 정리한 논문: Knowledge Graphs, Large Language Models, and Hallucinations: An NLP Perspective(2024), 리뷰 블로그
Knowledge Graph의 시간에 따른 발전 양상과 유형의 변화, 그리고 현 시점에서 KG와 LLM을 어떻게 융합하여 활용할 수 있을 지에 대한 전반적인 내용을 다룬다. 내용이 굉장히 길고 자세해서 읽기 쉬운 논문은 아니었다. 그래도 읽고 나니 어느 정도 개념들이 정리되는 느낌이 있었고, 지식그래프에 한 층 가까워진 느낌이랄까?ㅎㅎ
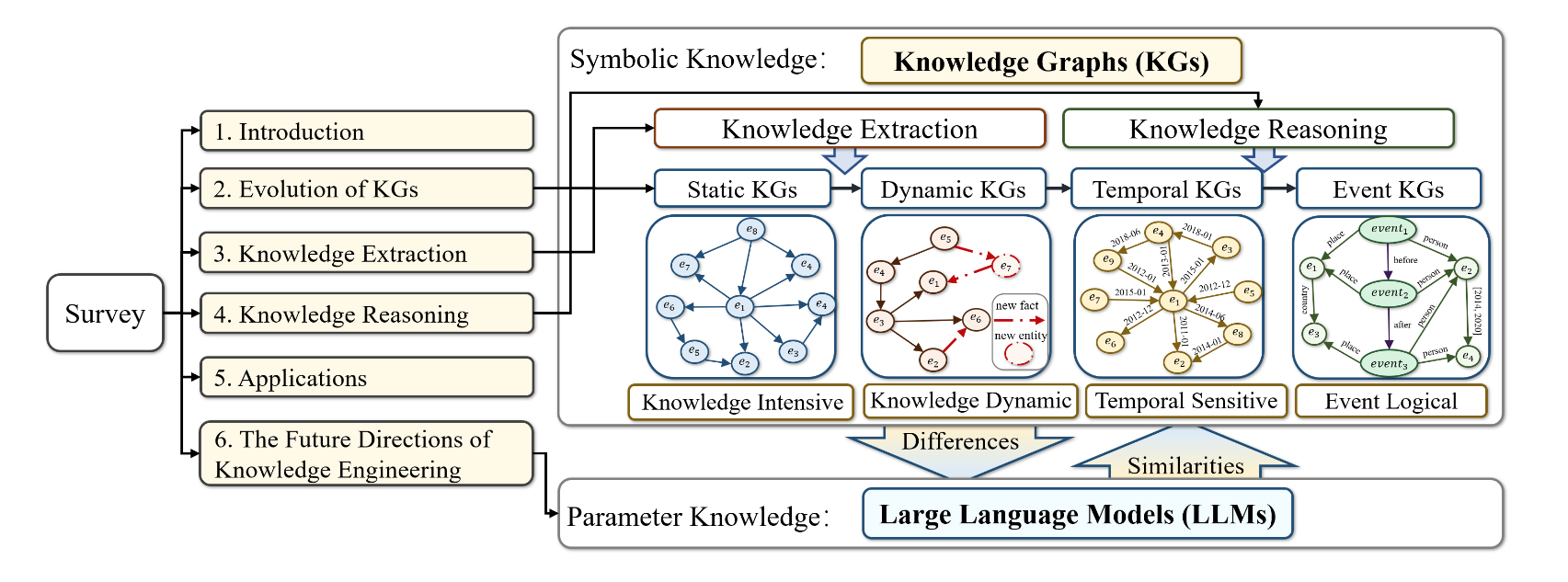
위 그림을 논문의 전체 구조를 정리한 내용을 담고 있다. 개인적으로 논문을 읽으면서 구조가 정말 깔끔하고 이해하기 쉽게 정리되어 있다고 생각했고, 이렇게 하나로 정리한 것도 좋은 레퍼런스였다.
📌 Evolution of Knowledge Graphs
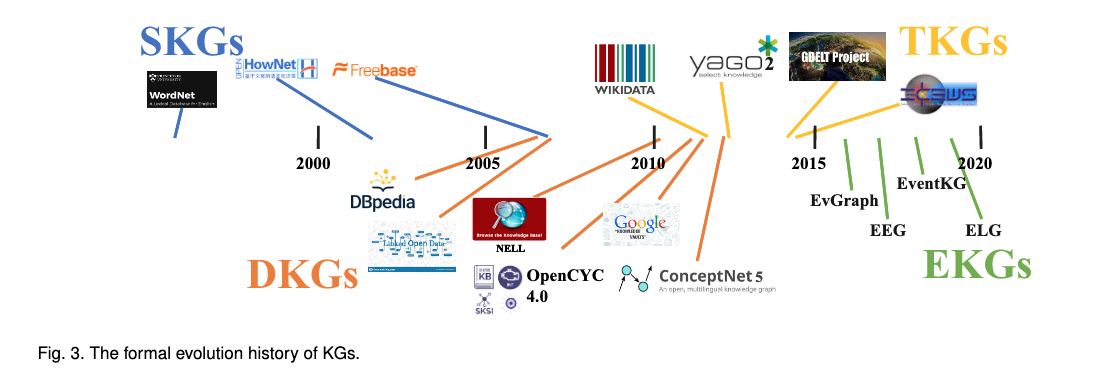
이 논문에서는 KGs의 발전 과정을 Static, Dynamic, Temperal, Event KGs로 구분하여 정리하고 있다. 위 이미지에서 보면, 시간 순서대로 각 시기에 KGs가 사용된 지식그래프 예시들이 적혀있고 익숙한 것들이 몇 개 보인다(Wikidata는 Temperal KGs라고 한다).
(1) Static KGs
Static KGs의 가장 큰 특징은 'not updated after their creation'이라는 것이다. SKGs의 예시로는 HowNew, WordNet, Freebase 등이 있다. SKGs는 정보를 검색해서 QA에 사용하는데 유용하게 사용될 수 있으나, 신문기사나 소셜미디아 같은 최신 정보가 요구되는 분야에서는 적용되지 어렵다는 특징이 있다.
(2) Dynamic KGs
DKGs는 변화와 업데이트 개념을 도입하여 지식의 적시성과 확장성을 보장한다고 한다. DKGs의 예시로는 DBpedia, Wikipedia, GoogleKnowledge Graph, NELL, Linked Open Data, OpenCyc, ConceptNet, UMLS 등 있으며, 지속적으고 실시간으로 업데이트 된 지식을 데이터에 반영한다. 이는 SKGs에 비해서 유연하고 적용가능성이 있다는 장점이 있다. DKGs는 검색 엔진이나 추천 시스템, 챗봇 등에 적용될 수 있으나 historical data가 소실된다는 특징에 따라서 트렌드 분석이나 미래 전망 예측 등과 같은 분석에는 적합하지 않다.
여기서 말하는 historical data는 업데이트 버전별로 데이터를 기록하지 않는다는 의미로 해석했다.
(3) Temporal KGs
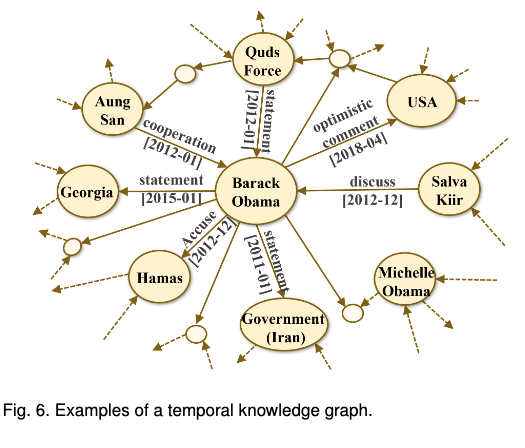
TKGs는 시간의 흐름에 따라 변화하는 데이터를 기록할 수 있는 지식그래프이다. figure6와 같이 업데이트 날짜를 함께 기록하는 방식이며, Wikidata, YAGO 등의 예시가 있다. DKGs는 포괄적인 데이터의 시점을 제공한다는 점에서 temporal QA나 예측 분석 등에 적용될 수 있다. 그러나 일부 TKGs는 이벤트 뉴스에서 추출되지만, 엔티티 중심 표현으로 인해 이벤트 정보를 효과적으로 나타내진 않는다.
여기서 말하는 entity-centric represent에 대해서는 각 개체 간의 관계에 집중해서 표현을 함에 따라서 뉴스와 같이 이벤트의 중요성이나 인과관계, 연관성 등을 표현하고자 하는 분야에서의 한계점이 있다는 것으로 이해할 수 있다.
(4) Event KGs
EKGs는 복수의 개체와 관계를 포함하여 더 복잡하고, 다양한 시점의 관계를 표현할 수 있는 지식그래프이다. EKGs는 비교적 최근에 많이 언급되고 있는 만큼, 여러 논문에서 다양하게 표현되고 있는 것 같은데, 언급된 내용들을 정리하면 다음과 같다. 이들은 모두 EKGs와 동일한 개념으로 설명되는 것 같다.
- EEG: 이벤트 노드가 추상적이고 일반화되며 의미적으로 완전한 동사 문구와 엣지가 그들 사이의 시간적, 인과적 관계를 표현함
- EventKG: 다국어 이벤트 중심의 TKG로, 역사적 및 현대 사건에 대한 이벤트 중심 정보와 시간적 관계를 다룸
- ELG: schema 수준의 이벤트 지식에 중점을 둠
- EvGraph: 뉴스 기사를 EKG로 자동으로 구성하는 파이프 라인
EKGs는 이벤트 예측, 타임라인 생성과 귀납적 추론 등에서 사용될 수 있고, 특히 금융 분야의 양적 투자(financial quantitative investments)과 텍스트 생성 등과 같은 이벤트와 관련된 다운스트림 테스트에 적용될 수 있다고 한다.
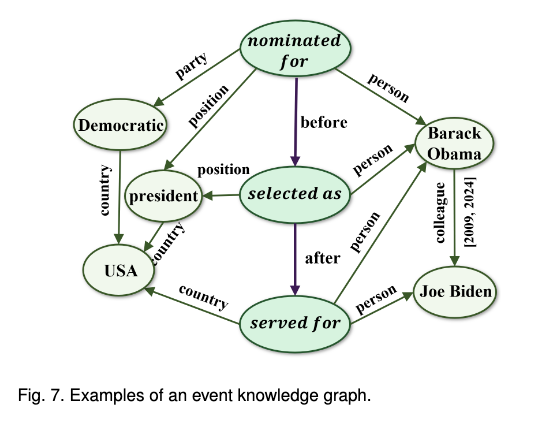
이해가 될락말락해서 추가적으로 찾아보니, 기존의 KGs는 개체(entity)에 초점을 맞췄다. 예를 들어 '버락 오바마는 대통령으로 당선되었다.'라는 문장에서 중점을 두는 정보는 '버락 오바마', '대통령'이 된다. 반면, EKGs에서의 초점은 '당선되었다'에 초점을 맞춰서 당선 이전과 이후의 'Event'를 중심으로 다시 구성한다.
위 그래프를 보면 'selected as'의 before에는 'nominated for'가 있고 after에는 'served for'가 연결되며, 이를 수행한person이 '버락 오바마'라고 표현된다. 즉, 사건의 시간 순서를 반영할 수 있는 것이다.다만, 이벤트와 개체, 그리고 이들을 구체화하는 property해당하는 값을 구분하는 것이 다소 모호할 수 있다고 생각했는데, 위 예시와 같이 한 이벤트에 연결되는 인물이나 사건이 한정적이고 연결되면 저렇게 표현할 수 있지만 만약
selected as라는 이벤트에 연결되는 값이 president 뿐만 아니라 시장, 국회의원 등으로 범위가 더 넓어져도 이렇게 표현할 수 있을까? 복잡성이 매우 증가할 수 있을 것 같다.
📌 Knowledge Extraction
각 KGs별로 추출해야 하는 지식의 종류나 형태도 상이한데, SKGs의 경우, 텍스트에서 사실적인 트리플을 추출해야 하므로 NER와 같은 작업이 필요하고, DKGs의 경우, 현실세계의 동적인 정보를 추출해야 한다. TKGs와 EKGs의 경우 여기에 추가적으로 이벤트 정보와 시간 정보를 추출해야 한다.
또한 KGs의 관계 사이의 논리적 규칙은 단순한 사실적 (factual knowledge)외에도 특별한 형태의 지식(?)으로 볼 수 있고, 서로 다른 유형의 KGs에서 규칙을 발견하는 과정에서는 다양한 규칙 추출 기법이 필요하다. 최근에는 이러한 추출을 LLM을 적용하는 기법들이 많이 제시되고 있다고 한다.
(1) Named Entity Recognition
NER은 텍스트에서 PERSON, ORG, LOC와 같은 특정 개체들을 추출하고 해당 개체의 클래스를 판단(부여)하는 기법이다. 과거에는 BIO 태깅과 같이 sequence tagging 기법을 많이 사용했는데, 딥러닝이 등장한 이후로는 DNN(Deep Neural Network)기반의 방식들이 제안되었다. RNN, CNN, LSTM, Word2Vec, BERT등 기존의 적용함에 이어 최근에는 LM(Language Model)을 활용해서 NER 방식이 많이 적용되고 있다. LM은 일반적으로 단어와 분류의 확률을 예측하는 목적인discriminative models과 새로운 시퀀스를 생성하는데 초점을 맞춘 generatibe models로 구분된다. 또한 임베딩 모델은 static-embeddings-based methods와 contextualized embeddings-based methods로 구분된다.
이렇게만 읽으면 정확히 어떤 의미인지 잘 이해되지 않는데, 아래 LM과 임베딩 모델의 조합에 따른 설명을 통해서 더 자세히 설명하고 있다.
Static and discriminative LM-based Method
여기서 말하는 'Static'이란, 문맥에 따라서 같은 단어의 임베딩 벡터를 다르게 계산하지 않는다는 의미이다. 즉, 먹는 '배'와 타는 '배', 사람의 '배'가 모두 같은 임베딩 벡터 값을 갖게되어 문맥에 따른 의미를 반영하지 못하게 된다. Word2Vec, GloVe, FastText 등의 방법들은 모두 static한 embedding model에 해당한다. 이 방법들로도 NER 테스트를 수행할 수 있었으나, 특정 코퍼스에서 미리 학습된 후 고정된 단어 목록을 사용하므로, 다양한 문맥에 따른 의미 변화를 반영하기 어렵다는 한계가 있다.
Contextualized and discriminative LM-based Method
맥락의 반영하는 임베딩 모델의 경우 다시 'Character-level'과 'word-level'의 임베딩으로 구분된다. Character-level은 개별 문자(character) 단위로 분석하여, 해당 문자들의 분포적 특징을 학습하는 방식이다. 주로 단어의 철자 구조와 형태학적 정보를 효과적으로 반영하는 데 유리하며, Flair가 이에 해당한다. 반면, Word-level 임베딩 모델은 전체적인 접근 방식으로, 단어를 하나의 단위로 처리하며, 문맥 속에서 해당 단어의 의미를 학습하는 방식이다. 단어가 사용되는 문맥에 따라 벡터 표현이 달라지므로, 동음이의어 등을 구별하는데 장점이 있으며, BERT나 ELMo가 이에 해당한다.
맥락을 반영한 임베딩 모델을 활용하여 NER을 진행하는 경우, 더욱 정교한 분류가 가능하여 성능이 향상되지만, 계산량이 많다는 특징이 있다.
Contextualized and generative LM-based Method
discriminative 모델은 encoder-only 모델이라고 볼 수 있는 반면, generative 모델은 encoder and decoder 혹은 decoder-only 모델이라고 이해하면 된다. 즉, 사전에 텍스트에서 학습한 확률 분포에 따라서 입력(prompt)에 따라 다음 단어의 가능성을 예측하여 자연스럽고 일관된 새로운 텍스트를 생성하는 모델을 의미한다. generative 모델의 대표적인 예시로는 GPT나 BART가 있다.
예시를 통해 보다 자세히 살펴보겠다. “Apple Inc. was founded by Steve Jobs in Cupertino.” 라는 문장이 있을 때, 기존의 discreminative 방식의 모델은 다음과 같이 NER을 진행한다. 이때의 B는 Begins이고, I는 Inside, O는 Outside를 의미한다.
Apple(B-ORG) Inc.(I-ORG)was(O)founded(O)by(O)Steve(B-PER)Jobs(I-PER)in(O)Cupertino(B-LOC).(O)
이 방식에서는 새로운 개체를 생성하는 것이 아니라, 이미 존재하는 단어들 중에서 개체를 인식하는 것이 핵심이다. 따라서 Apple과 같이 사전에 ORG로 분류된 기업이 아닌, 최근에 설립된 회사나 학습 코퍼스에 없는 기업이 문장에 포함되는 경우 이를 ORG로 인식하지 못한다.
반면, generative 모델의 경우 Apple Inc. [ORG] was founded by Steve Jobs [PER] in Cupertino [LOC]. 와 같이 입력 문장을 변형하여 개체를 포함한 새로운 문장을 생성하는 방식이다. 이에 따라 훈련 데이터에 없는 정보가 포함되어도 개체로 인식할 수 있으므로, 학습 데이터가 적어도 활용이 가능하다. 다만, 유연성이 증가한 만큼 계산량이 많아 속도가 느리고, 잘못된 개체를 생성(인식)하여 오류 발생 가능성이 높은 성능적 한계가 존재한다.
(2) Relation Extraction
RE는 엔티티 간의 관계를 텍스트 상에서 추출하는 것으로, NER 작업과의 상호작용에 따라서 'Pipeline-based Method'와 'Joint-based Method'로 구분될 수 있다.
Pipeline-based Method
Pipeline-based 기법은 순차적으로 엔티티를 인식하고 관계를 추출하는 방식을 사용한다. 이때 두 작업은 상호 독립적으로 진행되며, 관계 추출은 주어진 엔터티 쌍 간의 특정 관계를 식별하는 Multi-calss classification) 문제로 간주된다.
이에 대한 접근법으로는 feature-based(e.g. 어휘적, 의미적 특징을 결합하여 SVM 분류기를 활용하는 방법)나 kernel-based(e.g. 문자열의 특정 서브시퀀스(subsequence patterns)를 비교하여 관계를 분류), 그리고 딥러닝의 신경망을 활용하여 관계를 추출하는 방법(e.g. CNN 기반의 기법 등) 등이 있다. 최근에는 LLM을 활용하여 RE를 진행하는 접근(e.g. BERT, BART 등 transformer 기반의 pre-trained model 기반)도 시도되고 있다.
한편, 이 방법은 엔티티와 관계를 따로 추출한다는 점에서 엔터티 정보가 관계 추출 과정에서 충분히 활용되지 않을 가능성이 있다. 이를 보완한 방법이 다음 Joint-based 기법이다.
Joint-based Method
Joint-based 기법은 엔티티와 관계를 '동시에' 추출하는 방법이다. 이를 위한 접근법으로는 우선, 딥러닝 기반의 방식은 RNN, LSTM 기반으로 엔티티와 관계를 동시에 추출하는 방식이 사용되며, attention 모델을 활용해서 성능을 더욱 높인 여러 연구들이 있었다. 언어모델 기반의 방식으로는 BERT 등 사전 훈련된 모델을 인코더로 사용하여 문장에서 triple을 추출할 수 있으며, 생성 모델(generation model)기반에서는 장기 의존성 문제와 오류를 해결하기 위해 contrastive learning(대조 학습) 기법을 적용하거나 관계 추출을 탬플릿 생성 문제로 변환하여 cross attention copy mechanism을 적용한 사례도 존재한다.
Joint-based 기법은 오류를 완화하고 엔티티와 관계의 정보를 상호 보완적으로 활용할 수 있다는 장점이 있으나, 모델이 복잡하고 학습 난이도나 높다는 한계점도 존재한다.
(3) Dynamic Knowledge Extraction
정보는 시시각각 변화하며 이에 따라 온라인 상을 포함하여 유동성있는 정보를 추출하는 전략적 방법은 매우 중요한 문제이다. dynamic한 지식을 추출하는 방법으로 'automatic extraction'과 'never-ending learning' 방식을 소개한다.
automatic extraction은 말 그대로 자동으로 공개된 web text에서 사전에 정의된 지식 베이스를 기반으로 추출하는 방법이다. never-ending learning은 한 번 학습하고 끝나는 것이 아니라, 계속해서 학습을 반복하면서 정보를 추출하고 성능을 향상시키는 방법이다. 이때의 학습은 단어의 벡터를 계산하는 과정을 의미한다.
(4) Event Extraction
이벤트 추출은 구조화되지 않은 데이터에서 이벤트와 관련 정보를 식별하는데 중점을 둔 작업이다. 이 작업은 이벤트의 trigger가 되는 단어나 구를 식별하고(규칙기반, 지도학습 기반의 모델 혹은 둘을 결합한 방식), 이벤트에 대한 엔티티를 식별하며(구분 문석, 시멘틱 라벨링, NER), 이를 연결하는 과정으로 복잡한 과정으로 구성된다.
이벤트를 추출하는 작업은 언어의 구조와 의미에 대한 이해를 기반으로 진행되어야 한다는 점에서 도전적인 태스크이다. 또한 Time mining과 같이 시계열 데이터에서 의미있는 패턴을 추출하는 작업 등과 결합하여 보다 복잡한 이벤트를 분석할 수도 있다. Event 추출 기법은 위의 다른 추출 분야와 같이 CNN, RNN 기반의 딥러닝 모델을 활용하는 것에서 부터 BERT 등의 언어모델 기반의 기법을 활용하는 것 까지 발전했으며, 최근에는 프롬프트 기반으로 이벤트 추출의 유연성을 더욱 높일 수 있다고 한다.
(5) Rule Extraction
지식 그래프는 지식을 기호(symbolic) 형태로 표현할 수 있으며, 이를 활용한 규칙 기반(Symbolic Reasoning) 방법이 강력한 가능성을 가지고 있다. Rule mining은 주어진 데이터셋, 즉 KGs로 표현된 데이터의 패턴과 규칙에서부터 유용한 지식을 추출하는 프로세스를 의미한다. KG의 장점은 블랙박스와도 같은 딥러닝 모델과 달리 규칙이 명시적이므로 인간이 이해하기 쉽다는 것이다. 이에 따라 규칙과 모순되는 사실은 오류일 가능성이 높으므로 오류 검출에도 활용 가능성이 높다.
현재 LLM의 가장 한계라고 언급되는 Explainable(설명 가능성)이 KG에는 있다는 점이 인상적이다.
2014년 이후 논리적 규칙을 활용하여 지식 기반을 탐색하는 연구가 활발히 진행되었으며, 대규모의 복잡한 KG에서도 설명 가능하고 효율적인 추론이 가능하다고 한다. 향후 연구에서는 LLM과 결합하여 KG의 지속적인 자동 구축과 보완이 가능할 수 있으며, LLM과 결합한 하이브리드 방식이 더욱 발전할 가능성이 높다고 설명한다.
📌 Knowledge Reasoning
KGs를 구축하기 위해 수집한 데이터적인 한계에 의해서 지식을 '추출'하는 것만으로는 전반적인 지식을 다루는 데 부족할 수 있다. 따라서 지식을 '추론'하는 과정이 필요하며, 위에서 설명한 각 특성의 KGs에 따른 추론 방법을 구분해서 설명할 수 있다.
🤯 Reasoning 부분이 가장 읽기 힘들었다. 부분적으로 LLM을 활용하여 요약을 진행했다는 점을 밝힌다.
(1) SKGR
Matrix Decomposition-based Method
매트릭스 분해 기반의 방법은 엔티티 간의 관계를 저차원(latent)에서 표현하는 방법이다. 대표적으로 RESCAL 모델이 있는데, 3차원 텐서 분해를 통해 다중 관계 데이터를 모델링한다고 한다. 또한 계산 비용을 줄인 DistMult 모델의 경우, 대각 행렬로 표현해서 파라미터의 수를 줄여서 대규모 지식그래프에 적합하며, 여기서 확장된 ComplEx는 비대칭 관계를 제대로 표현하기 위해 복소수 임베딩을 활용하여 관계를 표현하는 모델이다. SimpleE는 bilinear form을 활용한 간단한 행렬 분해 모델이다.
매트릭스 분해 기반의 방법은 엔티티 및 관계 간의 복잡한 상호작용을 효과적으로 모델링한다는 점에서 잠재적인 의미나 패턴을 학습할 수 있다. 이에 따라 유사도를 계산하고 관계를 예측하는데 효율적인 방법이다. 다만, 행렬의 크기가 커지면 계산량이 급격히 증가하며, 희소성 문제가 있으며, 복잡한 관계를 표현하기 어렵다는 한계가 있다.
희소성문제: 하나의 지식그래프에는 수많은 엔티티가 존재할 수 있으며, 각 엔티티 간의 가능한 모든 조합의 관계는 거대한 행렬이 됨. 그러나 실제로 존재하는, 실제로 가능한 관계는 전체에 비해 극소수 이기 때문에 행렬의 많은 부분이 0으로 채워지므로 희소행렬 형태가 되는 것임
복잡한 관계를 표현하기 어려운 문제: 지식그래프의 대칭관계란
A-B->C의 관계가 있을 때C-B->A의 관계도 성립하는, 방향성이 없는 관계를 의미함. 반면, 비대칭 관계란 방향성이 있어서 역관계는 성립하지 않는 상황을 의미함. 따라서 위에서 설명한 행렬 분해 기반 모델 중 대칭 행렬만 사용하는 경우 비대칭 관계를 표현하지 못하므로 복잡한 관계를 표현하기 어렵다는 문제가 발생하는 것임
Translation-based Method
번역 기반의 기법은 연속 공간에서 벡터로 엔티티와 관계를 나타내며, 관계 벡터를 따라 엔티티 벡터를 번역(변환)하여 추론을 수행한다. 번연 기반의 기법 중에는 TransE(각 트리플의 관계 임베딩을 학습하는 알고리즘),TransH(보다 복잡한 관계-1:N을 모델링할 수 있음), TransR, RotatE 등이 있다.
지식그래프 추론을 위한 번역 기법 방법은 간단하고 효율적인 계산이 가능하며 확장 가능하다는 점에서 광범위한 활용이 가능하지만, 복잡한 관계를 모델링하고 노이즈가 많거나 불완전한 데이터를 처리하는데 어려움이 있다.
GNN-based Method
지식그래프의 추론을 위해 그래프 신경망(GNN)을 활용하는 방법으로, 인접 노드의 정보를 수집하고 통합하여 추론을 수행한다. GCN은 GNN기반의 기본 모델이지만 다중 관계 데이터를 모델링하는 기능이 부족하고, R-GCN은 지식그래프 추론을 위한 선구적인 방법으로 알려져 있으며, CompGCN은 지시그래프에서 관계 구성을 명시적으로 모델링한다.
GNN 기반의 지식그래프 추론을 위한 방법은 로컬 그래프 구조와 복잡한 관계를 파악하고 다양한 응용 프로그램에 적용될 수 있지만, 확장성이나 계산 복잡성, 매개 변수 튜닝 등과 관련된 문제가 있을 수 있다.
Large language models-based Method
LLM 기반의 지식그래프 추론은 트리플 경로를 일관성 있는 텍스트 시퀀스로 변환한 뒤, 사전 훈련된 LLM을 활용해서 추론 작업을 수행하는 방식이다. pre-training이라는 개념을 기반으로 진행되며, 대표적인 모델은 BERT가 있다. KG-BERT는 엔티티와 관계를 나타내는 텍스트를 인코딩 하여 트리플의 문맥을 표현된 임베딩 벡터를 얻는 모델이다.
지식그래프 정보를 통합한 대규모 언어모델은 풍부한 의미 정보를 표현할 수 있고 사전 훈련된 지식을 활용한다는 그래프 추론의 가능성을 보여주지만, 확장성이나 메모리 제한, 계산 복잡성 등과 같은 한계가 있을 수 있다고 한다.
최근 언급되는 LLM 기반으로는 프롬프팅 만으로도 텍스트 문서에서 엔티티와 관계를 추출할 수 있다. 보다 확장성이 높아졌고, 계산 복잡성의 문제도 어느 정도는 해소되지 않았을까 생각했다.
Neural-Symbolic Method
위의 NN 기반의 모델들을 활용하면 설명가능성과 신뢰성 등의 문제로 의료, 금융, 군사 분야에서는 적용하기 어려울 수 있다. 이에 대안으로, Neural-Symbolic 기법의 경우 신경망과 기호적 지식 추론 방식을 결합하는 시도가 있었다. 이 기법은 다시 'Symbolic-driven neural reasoning methods'와 'Neural-driven symbolic reasoning methods'로 구분하여 설명한다.
Symbolic-driven neural reasoning 방식은 신경망의 학습 과정을 안내하고 향상시키기 위해 기호(symbol) 추론을 활용한다. 이를 적용한 모델로는 KALE(논리 규칙을 소프트 제약 조건으로 변환한 임베딩을 신경 임베딩에 통합하는 방식), RUGE(규칙을 사용하여 임베딩을 진행) 등이 있다.
Neural-driven symbolic reasoning 기법은 신경망이 데이터의 불확실성과 모호성을 처리하고 기호 추론에서 검색 공간을 줄이는데 통합되는 논리 규칙을 도출하는 것을 목표로 한다. PRA(엔티티 간의 경로를 탐색하여 지식그래프를 추론하는 방법을 학습하는 방법), MINERVA(강화학습기반 접근 방식을 사용), GraIL(신경망을 사용하여 지식그래프 추론을 위한 1차 논리 규칙을 학습하는 방법)등의 방법이 있다.
사실 정확히 잘 모르겠다. symbolic에 대한 설명을 Gemini를 통해 생성하니 다음과 같이 답변했다.
이 문서에서 symbolic 방법은 지식 그래프에서 논리적 규칙을 추출하는 rule mining을 의미합니다. 구체적인 예시와 함께 symbolic 방법에 대해 자세히 설명해 보겠습니다.
- A는 B의 아버지이다.
- B는 C의 어머니이다.
이러한 정보로부터 다음과 같은 논리적 규칙을 추출할 수 있습니다.
IF X는 Y의 아버지이고, Y는 Z의 어머니이다 THEN X는 Z의 할아버지이다.이 규칙을 통해 새로운 사실을 추론할 수 있습니다. 예를 들어, A가 C의 할아버지라는 사실을 추론할 수 있습니다.
지식그래프 추론을 위한 neural-symbolic 기법은 보다 해석 가능하고 설명 가능한 추론 방법을 사용한다는 점에서 다양한 응용 분야에서 적용가능하다는 장점이 있다. 그러나 확장성, 계산 복잡성, 구현 복잡성, 데이터 품질에 대한 민감성 등에 대한 측면은 여전히 도전해야 하는 문제이다.
기존의 NN 모델들도 계산 복잡성, 확장성의 문제가 똑같이 언급되었다. 개인적으로 생각하기에는 추론을 위한 지식그래프 구축의 단계나 활용 과정의 복잡성, 어려움은 neural-symbolic 쪽이 더 높을 것 같은데, 이를 통해 생상된 결과의 투명성과 해석 가능성 측면에서 더 신뢰할 수 있을 것 같다. 즉, 정확성이 요구되는 도메인 분야에 적합한 방법일 수 있으며, 이를 실용적 측면에서 활용하는 방법이 챌린지라는 것이다.
(2) DKGR
동적인 그래프에서 새로운 엔티티와 관계가 추가되는 케이스를 고려한 방식을 설명한다.
GNN-based Method
inductive 능력의 원천에 따라 네 가지로 세분화할 수 있다.
gemini를 활용하여 요약함
- 그래프 구조에 의한 Inductive 능력: DKG에서 특정 triplet의 로컬 neighborhood로 구성된 서브 그래프는 target 노드 간의 관계를 추론하는 데 필요한 논리적 증거를 포함하고 있다.
- 관계 규칙에 의한 Inductive 능력: Rule mining은 KG에서 빈번한 패턴의 관측된 동시 발생을 사용하여 논리 규칙을 결정하고, 이는 보이지 않는 사실로 추론을 전달할 수 있다.
- Embedding Aggregator에 의한 Inductive 능력: 기존 GNN과 같은 neighborhood aggregator를 학습하면 기존 이웃을 통해 새로운 엔터티를 inductive하게 임베딩하는 데 도움이 될 수 있다.
- Meta-Learning에 의한 Inductive 능력: Meta-learning은 "학습하는 법을 배우는" 능력에서 영감을 받아, emerging KG에서 링크 예측 작업을 모방하기 위해 support triples와 query triples로 구성된 작업 집합을 구성하고, GNN을 사용하여 각 작업에서 보이지 않는 구성 요소를 임베딩한다.
LLM-based Method
LLM 기반의 기법은 KG의 edge에 있는 엔티티와 관계를 자연어 형태로 변환하여 입력으로 사용한다.
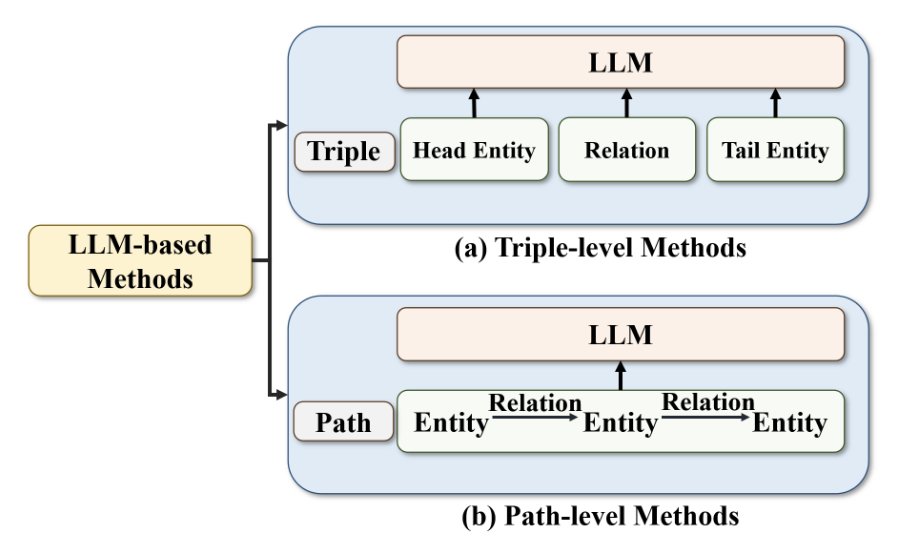
- Triple-level 방법: KG-BERT, StAR, CKBC와 같은 이전의 LLM 기반 모델은 DKGR에도 사용될 수 있었다. KEPLER는 엔터티 설명을 BERT로 인코딩하고 KG의 기호 공간에 정렬한 다음, 지식 임베딩 목표와 masked language modeling (MLM) 목표를 공동으로 최적화한다.
- Path-level 방법: BERTRL은 구성된 triple로 이루어진 경로를 텍스트 정보로 연결하고 사전 훈련된 prior knowledge와 결합하여 rule-like 추론 증거를 형성한다. Bi-Link는 BERT를 통해 학습된 구문 패턴에 따라 관계 프롬프트를 검색하고, forward 예측과 backward 예측 사이의 양방향 연결을 위한 대조 학습을 통해 대칭 관계를 표현한다.
Few-shot Knwoledge Graph Reasoning
지식그래프에서 새로운 관계에 대해 적은 수의 예시를 주고 추론을 하도록 하는 방식이다. 기존에 많은 양의 데이터로 학습을 해야 하는 방식과 달리, 적은 양의 데이터만으로도 추론을 통해 관계를 예측하게 할 수 있다는 장점이 있다.
Meta-learning 기반의 few-shot learning 방법도 있는데, 전달 가능한 관계별 메타 정보를 캡처하는 것을 목표로 하며, 새로운 관계가 일반적으로 링크가 적기 때문에 동적 지식그래프에 적합하고 성능이 좋다고 한다. 이 외에도 GEN, P-INT, ADK-KG 등 새로운 few-shot learning 방법들이 있다.
(3) TKGR
SKG와 DKG는 모두 특정 시점의 상태나 가장 최신 상태의 정보만 표현할 수 있는 반면, TKG는 엔티티와 관계의 변화 과정(프로세스)를 표현할 수 있다는 특징이 있다.
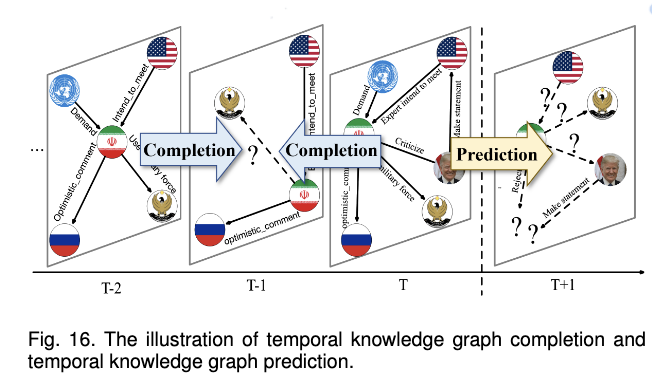
TKGR은 과거의 TKG를 설명하는 시간적 지식 그래프 완성(Completion)과 주어진 미래 시간에 TKG의 상태를 예측하는 시간적 지식 그래프 예측(Prediction) 방법이 있다.
Temporal Knowledge Graph Completion
시간적 지식 그래프의 완성(completion)은 시간 정보를 이해하고 이를 지식 그래프의 의미 및 구조 정보와 통합하는 것을 목표로 한다. 아래 이미지를 통해서 보다 간단하게 이해해보면, Completion은 T-2, T시점의 정보를 통해서 T-1 시점의 정보를 완성할 수 있다는 것을 의미하고, Prediction은 T시점까지의 정보를 통해서 T+1 시점의 정보를 예측할 수 있다는 것을 의미한다.
- Tensor Decomposition-based Completion Methods
: 시간적 지식그래프를 일련의 정적 스냅샷으로 표현하고, 이를 행렬 또는 고차원 텐서 시퀀스로 모델링하는 방법. CP, Tucker 방법 등이 있음. 텐서 분해 기반 방법들은 시간적 지식 그래프의 진화 패턴을 포착하여 누락된 지식을 추론하고 미래의 관계를 예측하는 데 사용됨.
- Translation-based Completion Methods
: 지식 그래프의 스냅샷에서 분해된 것이 아니라 벡터나 다른 표현 형태로 학습된 엔티티, 관계, 시간 정보의 표현을 사용한다. 이러한 방법은 크게 '명시적으로 표현된 시간 정보를 사용한 추론'과 '암묵적으로 표현된 시간 정보를 사용한 추론'으로 구분할 수 있다.
Temproal Knowledge Graph Prediction
시간적 지식 그래프 예측(Prediction) 방법은 미래 상태를 예측하기 위해 TKG 역사 정보의 진화 패턴을 배우는 것을 목표로 한다.
- Path-based Prediction Methods
: 경로 기반 예측 방법 - Temporal Point Process-based Prediction Methods
: 미래 이벤트를 예측하는 확률적 방법 - Sequence Neural Network-based Prediction Methods
: 시쿼스 신경망 네트워크 기반 예측 방법(스냅샷 인코더와 시간적 인코더로 구성)
📌 The Future Directions of Knowledge Engineering
(1) Knowledge Representation
현재 KG가 직면한 지식 표현과 관련된 과제는 다음과 같다.
- 고차원(higher-order)의 논리 지식을 직접적이고 정확하게 모델링할 수 없으면 지식 추론으로 적용할 수 없다는 점
- KG를 통한 효과적인 처리 및 직접적인 수치 지식 계산의 어려움
- 지식 관리 관점에서, 조합 폭발(?)과 중복 구성을 효과적으로 방지하면서 비즈니스 반복을 지원하는 표현에 대하나 요구는 다양한 세분성 및 유형의 지식을 통합하고 상호 작용을 모델링하는 데 있어 기존 KG에 어려움을 주며, RDF/OWL 기반 지식 모델링은 빠르게 진화하는 시나리오에서 지나치게 복잡하고 중복이 발생하기 쉽다
복잡성이 있다는 사실은 이해되는데, 중복 발생 가능성은 어떤 의미에서 있는 걸까?
- 매개변수를 통해 지식을 저장하고 추론하는 LLM과 달리, KG에서는 지식 저장과 추론의 분리는 대규모 지식 저장과 효율적인 지식 추론을 통합하는 통일된 프레임워크가 부족하여 지식을 최대로 활용하는 것이 저하됨
(2) Knowledge Extraction
비정형의 텍스트에서 지식을 추출하는 방법은 기존에 라벨 기반의 지도학습으로 학습된 모델들이 많이 활용됐는데, 이 모델들을 학습하기 위해서는 대량의 라벨링 데이터가 필요하다는 어려움이 있었다. 최근 LLM의 경우 Few-shot이나 Zero-Shot로도 지식을 잘 추출해낸다는 장점이 있으나, 여전히 정확도 측면에서는 약간의 한계를 갖는다. 향후에는 이러한 generation 기반의 모델을 활용해서 지식을 잘 추출할 수 있도록 하는 기술적 보완이 필요하다고 언급한다.
정확히 어떤 방법인지는 잘 모르겠지만, 다음과 같은 예시를 생각해볼 수 있다.
- 기존: '이 두 개체의 관계를 선택하세요'
- 생성 기반: "이 두 개체 사이의 관계를 자연어로 설명해주세요"
혹은 텍스트에서 개체와 관계를 직접 추출하는 대신, 전체 지식 그래프를 자연어 텍스트로 생성하도록 하는 방식을 통해서 구축하는 것이다.
(3) Knolwedge Reasoning
DKG, TKG가 발전하면서 이에 대한 추론 기술이 주목받고 있지만 아직 개선할 사항이 많으며, EKG에 대한 추론은 거의 연구되지 않았다고 한다. 또한 신경망-기호적 지식 추론도 더 탐구해야 할 영역이다.
EKGR은 개체와 사건 간 기존 관계를 기반으로 잠재적 미래 사건을 예측할 수 있으며, 이는 많은 실제 응용 시나리오에서 매우 중요하다. 그러나 새로운 종류의 지식 요소인 사건을 모델링하기 위한 EKG 임베딩 모델을 개발하는 방법은 이전 연구에서 논의된 적이 없다. 또한 EKG가 사건 간 많은 논리적 관계와 텍스트 설명을 포함하므로 EKGR 작업을 위한 사건 논리와 LLM의 유용성을 탐색하는 것도 흥미로울 것이다.
최근 신경망적 또는 기호적 추론의 발전은 다양한 지식 그래프에서 추론을 향상시키기 위해 신경망의 데이터 기반 학습과 기호적 추론의 구조화된 논리를 통합하는 잠재력을 강조했다. 이러한 융합은 특히 DKG와 TKG에서 실제 세계 지식의 동적이고 시간에 따라 변하는 특성을 표현하는 데 있어 독점적으로 신경망적 또는 기호적 접근법이 가진 한계를 극복하는 것을 목표로 한다. 사실적 지식 외에도, 지식 그래프에는 관계와 사건 간의 많은 일차 또는 시간적 논리 규칙을 포함하는 상당한 양의 논리적 지식이 함축되어 있다. 이러한 논리 규칙의 적용은 다양한 지식 그래프 임베딩 모델과 결합될 때 이들 모델의 성능과 해석 가능성을 크게 향상시킬 수 있다. 또한 LLM의 출현은 지식에 내재된 패턴을 발견하여 추론 작업을 지원할 기회를 제공한다. 신경망-기호적 패러다임과 LLM의 패턴 인식 능력의 결합은 다양한 유형의 지식 그래프에서 지식의 진화하는 특성에 맞춘 더 효과적이고 해석 가능한 지식 그래프 추론 기술을 개발하는 길을 열 수 있다.
✅ 그래서, LLM와 KG를 어떻게 결합해서 사용할까?

그래서, LLM과 KG를 어떻게 결합해서 각각의 장점을 극대화할 수 있을까? 최근에 가장 관심을 갖고 흥미가 있는 질문이다. 본 논문에서는 LLM과 KG의 공통점과 차이점을 설명하고, 이 둘을 결합했을 때의 확장 가능성을 언급한다.
공통점
LLM과 KG의 공통점은 다음과 같다.
- 두 데이터 소스는 모두 대량의 구조화되지 않은 데이터에서 나온다.
: LLM과 KG는 모두 CommonCrawl나 Wikipedia 등과 같은 대량의 open text data를 통해 구축될 수 있다.KG는 도메인에 따라서 반드시 Open 데이터만 사용하진 않는다. LLM 역시 fine-tuning할 때는 domain-specific 데이터를 사용할 수 있지만, 일정 수준의 언어 표현력을 위해서 반드시 대량의 오픈된(학습에 사용되는 데이터의 윤리적 측면도 중요하기 때문에)텍스트 데이터가 필요하다.
- 둘 다 entity semantic을 표현하며, entity 간의 상관 관계를 저장할 수 있다.
: LLM은 학습 과정에서 각 엔티티 혹은 단어 단위의 관계를 기반으로 임베딩 벡터를 형성한다는 점에서 의미론적으로 엔티티의 관계를 표현하는 KG와 유사성을 갖는다. - 둘 다 QA와 같은 다운 스트림 응용 프로그램의 knowledge resource(원천 지식)으로 사용될 수 있다.
: LLM이나 KG는 모두 그 자체로도 활용될 수 있지만, 이를 활용하여 수많은 추가 테스크를 진행할 수 있다.
차이점
반면, LLM과 KG는 명확한 차이도 갖는다. KG는 가장 대표적인 symbolic representation 형식을 취하며, 이는 구조화 된 정보를 통한 해석 가능성을 제공하지만 유연성이 부족할 수 있다. LLM은 가장 강력한 parameter knowledge 형식으로, 다양한 작업을 처리하고 있어 일반성과 적응성이 뛰어나지만, 의사 결정의 과정이 불투명 할 수 있다.
차이점을 설명하기 위해 논의되는 KGs의 한계점은 다음과 같다.
- 높은 구축 비용
지식그래프를 구축하기 위해서는 텍스트의 전처리와 그 관계를 정확히 표현하는 과정에서의 복잡성이 수반된다. 이 과정은 여전히 사람의 수잡업이 많이 요구된다. - 데이터 희소성
구축하는 것이 어렵기 때문에 KG가 다루는 도메인이나 데이터 사이즈는 제한되어서 실제로 사용하는 단계에서 누락되는 데이터가 발생할 수 있다. - 부족한 유연성
KG의 스토리지 구조와 쿼리 방식은 비교적 static하기 때문에 다양한 데이터 구조와 질의를 반영하기 쉽지 않아 다양한 요구 사항에 유연하고 확장적으로 적용하기 어렵다.
LLM과 각 유형의 KG를 비교하면 다음과 같다.
| 비교 항목 | LLM (Large Language Model) | SKG (Static Knowledge Graph) | DKG (Dynamic Knowledge Graph) | TKG (Temporal Knowledge Graph) | EKG (Event Knowledge Graph) |
|---|---|---|---|---|---|
| 설명 가능성 | 응답의 근거와 추론 과정을 알기 어려움 (black box) | 명확한 추론 과정 제공 | 명확한 추론 과정 제공 | 명확한 추론 과정 제공 | 명확한 추론 과정 제공 |
| 일관성 | 동일한 질문에도 응답이 달라질 수 있음 | 동일한 질문에 대해 항상 같은 답변 제공 | 동일한 질문에 대해 항상 같은 답변 제공 | 동일한 질문에 대해 항상 같은 답변 제공 | 동일한 질문에 대해 항상 같은 답변 제공 |
| 지식 갱신 및 수정 | 비용이 높고 어려움 (재훈련 필요) | 정적 구조로 갱신 어려움 | 쉽게 갱신 및 수정 가능 | 시간 변화에 따라 지식 갱신 가능 | 사건 발생 시 지속적으로 지식 갱신 가능 |
| 지식 신뢰성 | 훈련 데이터가 노이즈를 포함할 가능성 있음, 잘못된 지식을 학습할 위험 존재 | 품질 평가를 거친 신뢰성 있는 지식 제공 | 지속적인 업데이트를 통해 높은 신뢰성 유지 | 최신 시점의 신뢰성 있는 정보 제공 | 사건 중심으로 검증된 지식 제공 |
| 시간 정보 처리 | 시간 개념이 부족하여 최신 정보 반영이 어려움 | 정적 지식만 포함 (시간 개념 없음) | 최신 지식을 반영할 수 있음 | 시간에 따른 변화 추적 가능 | 사건 발생 순서와 관계를 반영 가능 |
| 사건 중심 지식 | 사건 간의 관계를 명확히 학습하기 어려움 | 사건 정보 포함 가능하나, 동적 변화 반영 어려움 | 사건 정보를 반영 가능 | 시간 흐름에 따른 사건 정보 관리 가능 | 사건 간 인과 관계와 연속성 학습 가능 |
| 사실적 지식 탐색 | 특정 도메인 및 복잡한 질문에 대해 신뢰성이 낮을 수 있음 | 정적 정보 탐색에는 강점이 있으나, 최신 정보 반영 어려움 | 최신 정보까지 포함하여 탐색 가능 | 특정 시점의 사실을 정확히 탐색 가능 | 사건 기반으로 사실 탐색 가능 |
✅ Combination!!
LLM이 KG의 구축을 돕는 관점:
- 비지도 학습 기반 지식 추출: LLM의 텍스트 처리 능력을 활용하여 KG의 자동 구축 및 편집이 더욱 효율적으로 이루어질 수 있음
- 품질 관리 및 유지보수: LLM을 활용한 비지도 품질 관리로 KG의 지식 정확성과 신뢰성을 유지 가능
- 지식 추론 강화: LLM의 패턴 유도 기능을 활용하여 신경-기호적 추론(Neural-Symbolic Reasoning)의 새로운 기회를 창출
KG를 구축하는데 LLM을 활용할 수 있다는 것은 분명한 것 같고, 실제로 Neo4J와 같은 회사에서는 LLM을 활용하여 LPG 그래프를 생성한다. 다만, RDF 기반의 그래프, 즉 표준 어휘를 사용하여 관계를 표현하고자 할 때, 해당 어휘의 domain과 range를 모두 고려하여 적절한 표현을 하는 부분에서는 아직 미흡한 점이 있는 것 같다. 실제로 많이 사용되는 DCTerms나 SKOS, Schema.org 등과 같은 경우에는 잘 되더라도, 사용성이 낮은 어휘들은 LLM이 학습하지 못했을 가능성이 높기 때문이다.
KG가 LLM의 추론을 돕는 관점:
- 구조화된 정보 제공: KG는 논리적, 사실적 지식을 포함하는 저장소 역할을 하여 LLM이 보다 풍부한 정보를 활용할 수 있도록 함
- 훈련 단계에서의 활용: 그래프 신경망(GNN) 등 지식 인코딩 기법을 통해 구조화된 고품질 지식을 LLM에 통합하는 연구가 활발히 진행될 전망
- 추론 단계에서의 활용: KG를 LLM과 결합하여 hallucination을 탐지하여 줄일 수 있으며, 모델의 신뢰성과 정확도를 향상하는 관점에서 적용될 수 있음
RAG 관점의 augmentation을 하거나 오류를 감지하는 (RIG;Retrieval Interleaved Generation)방식으로의 적용 가능성이다. 이 역시 많이 언급되고 있으며 DataGemma 등에서 활용되는 방식이다. 이때의 전제는 KG의 정확성이 보장되어야 한다는 것이며, bottle-neck은 KG에서 어떻게 적절한 정보를 driven(search)할 것이냐가 될 것 같다.
