[논문리뷰] OG-RAG: Ontology-grounded retrieval-augmented generation for large language models
Paper Review

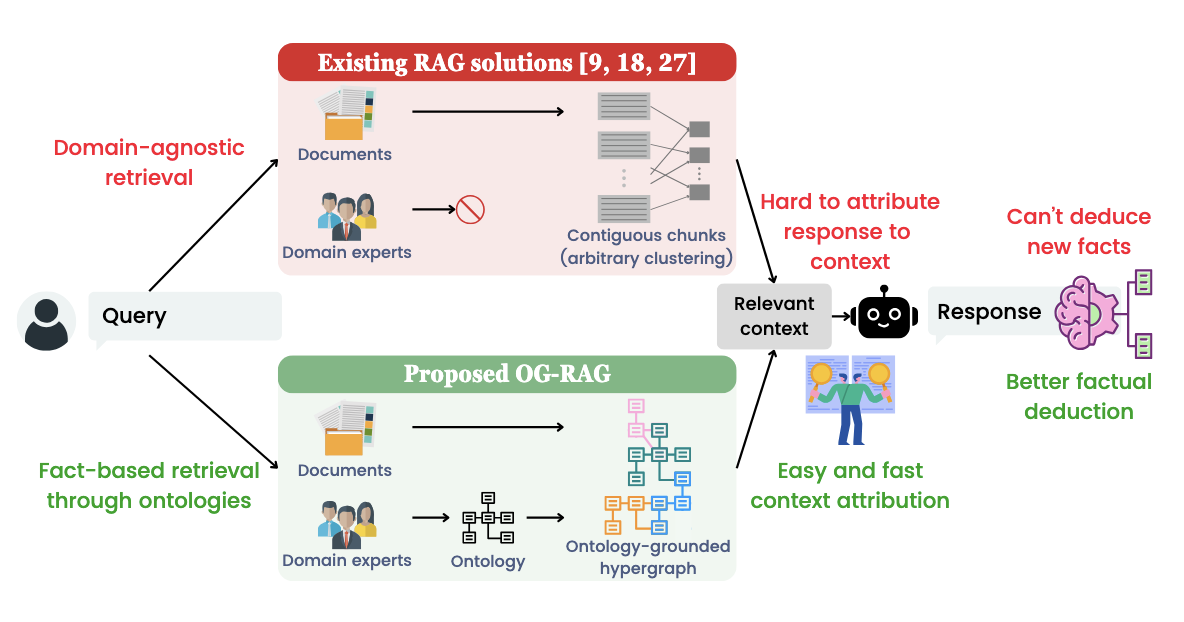
이 논문은 MS에서 연구한 OG-RAG를 소개한다. OG-RAG는 기존의 LLM이 갖는 도메인 특화 답변의 한계와 일반적인 RAG의 비구조적이고 정교함이 떨어지는 문제를 보완하기 위해 객체들의 관계를 구조적으로 정의한 온톨로지를 활용하여 augemnted하는 기법이다. 사실 이런 접근법은 다른 논문에서도 많이 소개되어서 큰 차별점까지는 아니라고 생각했지만, 여전히 갖고 명확하게 풀리지 않는 두 궁금증을 위주로 논문을 읽었다: (1) 지식그래프/온톨로지를 어떤식으로 구축했는지? 일반적으로 '반자동화방식+전문가 검토'이 방식이 정답이라고 여겨지는데, 여기서도 이 방식을 취하는지? (2) 구축한 그래프를 어떤식으로 검색해서 LLM에게 전달하는지? Text2Query를 수행하는지, 임베딩을 하는지, or something else?
Definition of Ontology
논문에서 정의한 온톨로지는 '특정 도메인에서 핵심개체(entity)와 그들 사이의 관계(relationship)를 형식적으로 표현한 구조'이다. 예를 들어, 농업 도메인에서는 작물(crop), 토양(soil), 기후(weather)와 같은 개체들이 정의되며, '작물은 특정 지역에서 재배된다', '토양은 수분 수준을 가진다' 등과 같은 관계가 형성된다. 온톨로지는 텍소노미나 단순한 계층적 분류와 달리, 개체 간의 비계층적이고 풍부한 관계를 표현할 수 있다는 점에서 차별성을 가진다.
한편, 문서에서는 동일한 온톨로지 개체에 대해 서로 다른 문맥에서 서로 다른 값이 등장할 수 있다. 이를 해결하기 위해 논문에서는 Factual Block 개념을 도입하는데, 동일한 온톨로지 개체라도 서로 다른 문서 혹은 문맥에서 나온 정보는 s-p-o 관계 묶음을 각각 처리한다는 것이다.
또한 이런 factual block들의 집합은 온톨로지 매핑 데이터(Ontology-mapped data)로 정의한다. 예를 들어, 문서에서 LLM을 사용해서 Seed-of crop->Soybean, Seed-is grown in-> Crop Region, Crop Region-has name-> Northwest Region 이런 트리플들을 추출하고, 이런 개체 간의 관계가 표현되면서 중첩된 속성 구조를 갖는 factual block들이 모여 온톨로지 매핑 데이터를 형성하는 것이다.
OG-RAG: Hyphergraph Construction
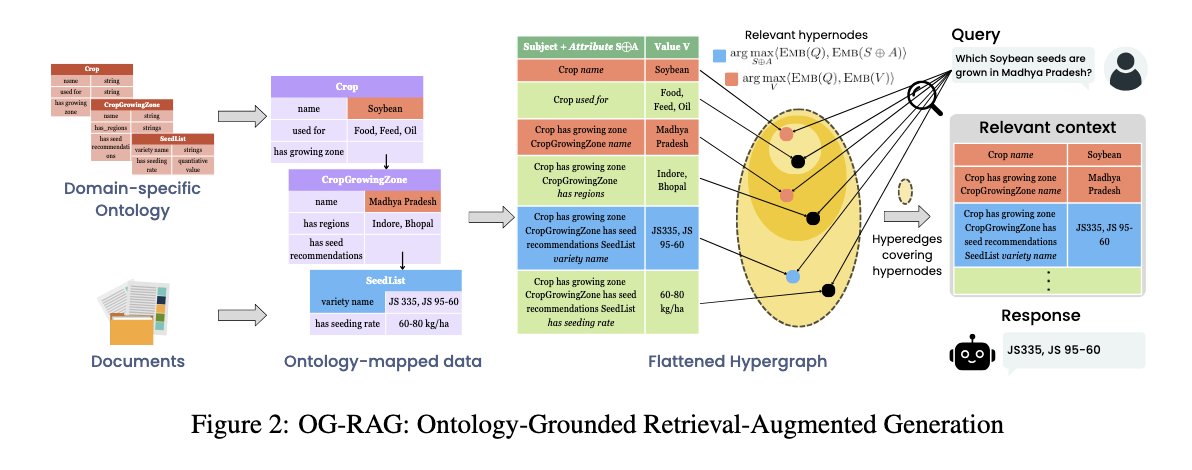
하이퍼그래프 구성의 목적은 비정형 도메인 문서를 온톨로지에 기반한 구조화된 검색 단위로 변환하는 것이다. 이를 위해 우선 도메인 문서를 일정 길이로 분할하고, LLM(gpt-4o)를 사용해서 문서 내용을 온톨로지 구조에 맞게 매핑했다고 한다. 사용한 프롬프트는 appendix C2와 같다.
C.2 Ontology Mapping Prompt
Here is a context definition for a crop cultivation ontology. Context Definition: {context_definition}
—————
Generate a JSON-LD using the following data and the above context definition for crop cultivation ontology. Use ’@graph’ object namespace for the data in JSON-LD.
Be comprehensive and make sure to fill all of the data. Keep nesting to the minimum and still be able to disambiguate.
If there are multiple subfields enumerated in a ’List’ namespace then do not combine them in a single subfield, keep them as separate subfields to disambiguate.
Ensure that you populate all items in the ’List’ namespace, do not leave any item. Do not include any explanations or apologies in your response. Do not add any other text other than the generated JSON-LD in your response. Generate in Json format.
———————
Data: {data}
——————
JSON-LD json:온톨로지 구조에 맞게 매핑했다는 말이 잘 이해되지 않았는데, 위 프롬프트와 깃헙 코드를 보니, 사전에 정의한 도메인별 온톨로지 스키마(T-Box)를 기반으로 비정형 문서에서 트리플을 추출해서 인스턴스 단위의 지식그래프를 생성한다는 거 같다. 다만 이때의 결과물은 전통적인 A-Box와는 달리, factual block을 모은 집합 수준으로만 볼 수 있다(URI를 부여한다거나 entity-resolution을 수행하지 않으므로).
앞서 정의된 factual block은 기본적으로 중첩된 구조를 갖는다. 이때 중첩된다는 건 s-p-o 구조에서 다시 o가 속성과 연결되는 value를 갖는다는 것이다.
Crop
└─ has growing zone → CropGrowingZone
└─ has seed recommendations → SeedList
└─ variety name → JS335
└─ seeding rate → 60–80 kg/ha이런 중첩된 구조는 검색과 그래프 연산에 비효율적이기 때문에 논문에서는 이를 평탄화(flattening)된 형태로 변환하는 작업을 거친다. 각 속성 경로–값 쌍을 하이퍼노드로 표현하고, 이들 하이퍼노드를 하나의 문맥적 사실 단위로 묶어 하이퍼엣지로 구성함으로써 다차원 관계를 보존하는 하이퍼그래프를 생성하는 것이다. 예시를 보면, n₁ = (Crop has name, Soybean), n₂ = (Crop has growing zone CropGrowingZone with name, Northwest) 이런 두 개의 하이퍼노드가 있을 때, 하이퍼엣지는 여러 하이퍼노드를 동시에 연결해서 fact인 'hasGrowingZone(Crop has name = Soybean) = Northwest`를 만들어낸다.
Soybean의 Type이 Crop이라고 두면 S 자리에 Crop이 올 일이 없으닊 바로
Soybean-hasGrowingZone->Northwest이렇게 되는게 아닌가 싶긴 했는데, 일단 넘어갔다.
OG-RAG: Hyphergraph-based retrieval
retrieval은 두 단계로 구성된다: (1) Relevant Hypernodes - 질문과 직접적으로 연관된 정보 단위 찾기 (2) Relevant Hyperedges - 정보들이 속한 사실(fact)묶음을 최소 개수로 가져오기
논문에서 아주 중요한 정제는 '사용자의 질문은 속성이 중심이 되는 질문일 수도 있고(e.g. Soybean의 growing zone은?) 값이 중심이 되는 질문일 수도 있다(Northwest 지역에서 재배되는 작물은?). 따라서 두 방향을 모두 고려한 검색이 필요하다.
- Ns(Q): 구조 기반 유사도. 질문 Q와 하이퍼노드의 속성 경로를 임베딩 공간에서 비교하여 질문이 어떤 하이퍼노드에 대한 것인지 찾아낸다.
- Q: What is the recommended seeding rate for soybean?
- high similarity:
(Crop ⊕ has seed recommendation ⊕ seeding rate)
- Nv(Q): 값 기반 유사도. 질문 Q와 하이퍼노드의 값 자체를 비교해서 어떤 값을 언급했는지를 알아낸다.
- Q: Which crops are grown in the Northwest region?
- high similarity:
v = "Northwest"
두 개의 하이퍼노드는 부분적인 정보를 의미하며, 사실 단위는 아니다. 따라서 이 정보들의 맥락을 부여하여 LLM이 이해할 수 있도록 하이퍼엣지를 통해 서로 논리적으로 연결하는 과정이 필요하다. 즉, 여러 하이퍼노드를 연결하는 하이퍼엣지를 통해 하나의 검증 가능한 fact를 생성하는 것이다. 이때의 하이퍼엣지는 새로 만드는게 아니라, 기존에 만들어져 있는 factual block 묶음에서 평탄화 과정을 통해 만들어진 fact에서 찾으면 된다.
.
.
.
구조가 굉장히 복잡하고 직관적으로 이해되진 않았다. 다만, 확실히 fact를 생성하는 과정에서 Hallucination이 발생할 가능성은 적어보인다. 추후 코드를 살펴볼 필요가 있을 것 같다.
- improved response accuracy
- flexible fact-based adaptation
- enabling verifiable context attribution
