
기업 단위에서는 다양한 형태, 품질의 데이터를 활용하기 위해 데이터가 어디에 있고 어떻게 처리하는지, 누가 사용하는지에 대해서 파악하는 것이 중요하다. 큰 조직에서는 각 부서별로 분산된 어플리케이션 관리 시스템을 갖고 있으며, 이에 따라 중복되는 데이터가 발생될 가능성이 높아 데이터 통합 관리의 필요성이 더욱 두드러진다.
이때 바로 '메타데이터 지식그래프'를 활용할 수 있다. 메타데이터 지식그래프는 기업 전반의 데이터를 지도처럼 펼쳐서 보여주는 역할을 한다. 이 그래프는 데이터의 구조와 위치, 처리 시스템과 활용하는 소비자 등의 정보를 함께 모아서 통합 탐색, 관리, 나아가 감사 등의 목적으로도 활용될 수 있다.
이러한 활용법을 메타데이터 허브(hub)라고 하는데, 이는 2017년 Airbnb에서 실시한 데이터 포털 플랫폼에서부터 시작되어, Lyft의 메타데이터 엔진 Amundsen, LinkedIn의 Datahub 등 다양한 기업들이 메타데이터 관리에 지식그래프를 결합한 상용 솔루션들을 선보였다고 한다.
Metadata Knowledge Graphs
메타데이터 지식그래프의 엔티티에는 데이터셋, 작업(task)와 파이프라인, 데이터 싱크(data sinks)등이 포함된다. 각 요소를 하나씩 살펴보겠다.
1️⃣ Datasets Connected to Data Platforms
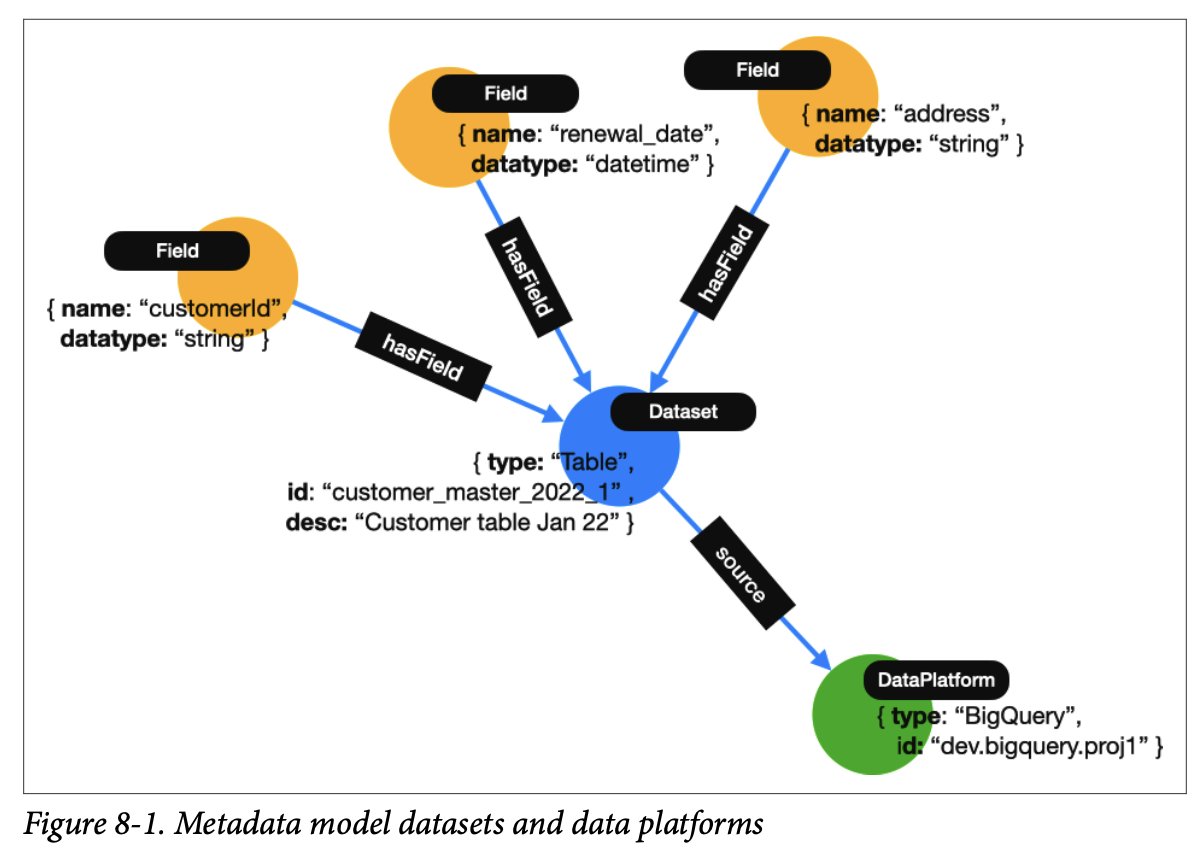
데이터셋은 테이블, 문서 등과 같이 모든 형태의 데이터 모음을 의미한다. 위 그래프는 Google BigQuery에 저장된 고객 정보 테이블을 서브 그래프로 표현한 것이다. Dataset 노드는 DataPlatform 노드와 source라는 관계로 연결되어 있으며, 3개의 Field 노드를 갖는다. 즉, 파란색 노드로 표현된 데이터셋에는 노란색 노드로 표현된 3개의 컬럼을 갖는다고 이해할 수 있다. 이와 같은 표현으로 시스템 내부의 데이터맵을 구축할 수 있고, 이를 통해 시스템 간의 논리적으로 공통 레코드를 연결하거나 연결 관계를 파악할 수 있다.
2️⃣ Tasks and Data Pipelines
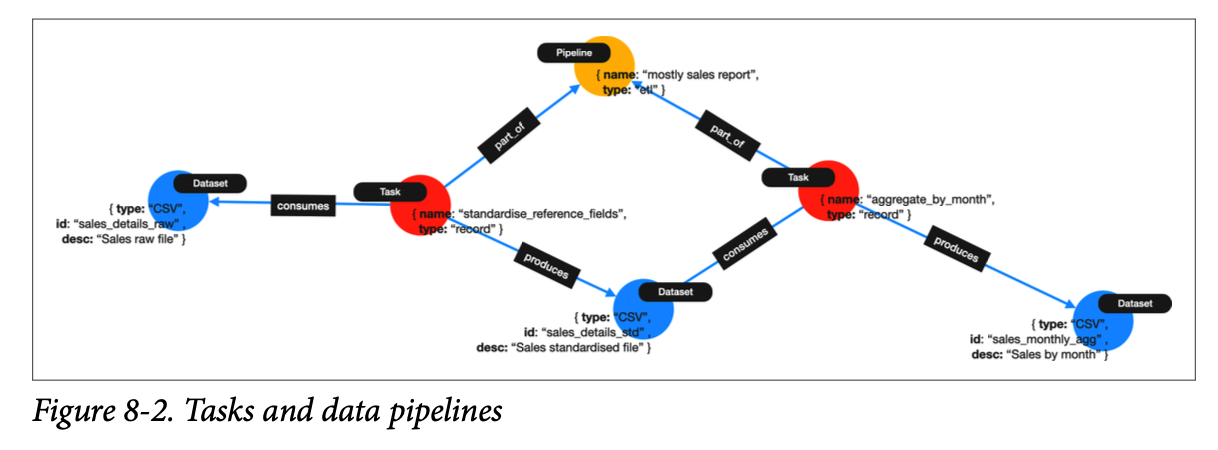
task는 데이터 자산을 처리하는 모든 작업을 의미한다. 예를 들어, csv에서 country라는 컬럼을 정제하는 ETL 작업이 있을 때, 작업들은 데이터 파이프라인이나 흐름을 형성하는 chain으로 그룹화될 수 있다. 이 체인은 작업의 실행 순서를 결정하고 작업 간의 의존성을 명시적으로 보여준다.
figure 8-2는 하나의 파이프라인(노란색 노드)에 두 개의 task(빨간색 노드)가 있으며, task에는 각각의 데이터셋과 수행작업으로 연결된다. 이 과정에서 데이터는 사용될 수도 있고, 새로 생성될 수도 있다. 이를 통해 어떤 시스템과 어떤 사용자가 데이터를 활용하는지 파악할 수 있고, 데이터의 출처를 파악하기도 용이하다.
3️⃣ Data Sinks
data sinks는 데이터 시각화부터 ML 학습용 데이터셋까지 데이터를 최종적으로 소비하는 모든 종류의 작업을 의미한다. 이 과정에서는 새로운 데이터가 생성되지 않고 사용만 된다는 특징이 있다. 데이터 싱크와 데이터를 연결하면, 어떤 사용자와 시스템이 어떤 데이터를 소비하는지 파악할 수 있어서 데이터의 가치 등을 이해하는데 도움이 된다.
Metadata Graph Example
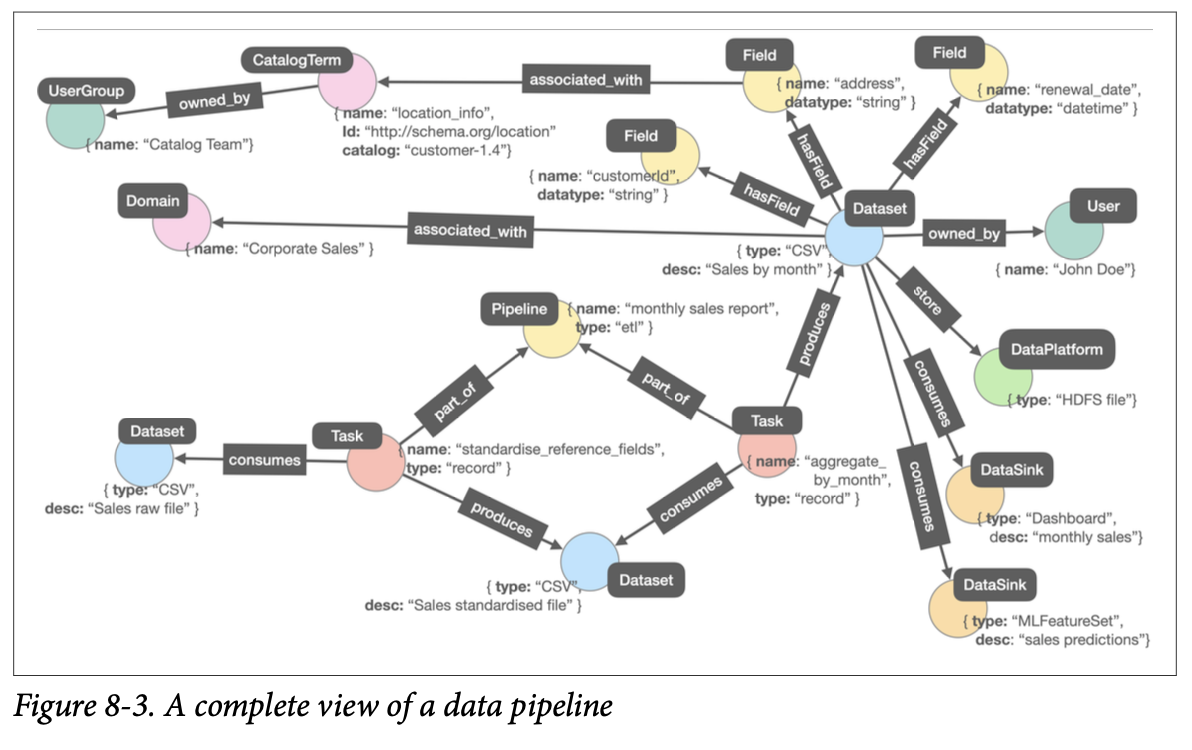
figure 8-3은 원본 판매데이터, 일부 참조 필드를 표준화한 판매데이터, 표준화한 데이터를 다시 월별로 합계/집계한 데이터 총 세가지 데이터를 합친 예시 메타데이터 그래프이다. 집계된 데이터 세트에는 세 개의 필드(customerId, address, renewal_date)가 노드로 포함되는데, 이 중 address 필드는 location_info라는 카탈로그 용어와 연결되어 있다. 즉, 이 필드는 지리적 위치 정보를 나타낸다는 의미이다. 또한 owned_by를 통해 소유자를 표현하고 있고, 두 개의 데이터 싱크로 연결된 것으로 보아 dashboard와 MLfeatureSet에서 활용하고 있다는 것을 알 수 있다.
Querying the Metadata Graph Model
위 그래프를 통해 '지리 정보를 포함하고 있는 데이터셋 중 가장 활용도가 높은 기업 매출 데이터가 무엇인가?'와 같은 질의의 답을 얻을 수 있다. 이때 활용도가 높다는 것은 연결된 data sink의 개수로 파악할 수 있다. 이와 관련된 Cypher 쿼리는 다음과 같다.
MATCH (d:Dataset)
WHERE (d)-[:associated_with]->(:Domain { name: 'Corporate Sales'}) AND
(d)-[:has_field]->(:Field)-[:associated_with]->
(:CatalogTerm {name:'location_info'})
RETURN d.id AS dataset_id,
d.desc AS dataset_desc,
d.type AS dataset_type,
count{ (d)<-[:consumes]-(d:DataSink) } AS dataset_usage_count이와 유사하게 만약 특정 태스크가 실패하면 어떤 데이터 소비자와 소유자가 영향을 받는지 확인하기 위해 메타데이터 그래프를 사용하면 추적이 가능하다.
MATCH (t:Task)-[:produces|consumes*2..]-(:Dataset)
<-[:consumes]-(s:DataSink)-[:owned_by]->(o)
WHERE t.name =
'standardise_reference_fields'
RETURN s.id AS affectedDataConsumerID,
s.type AS affectedDataConsumerType,
s.desc AS affectedDataConsumerDesc,
o.id AS ownerID,
o.name AS ownerName또한 'Dashboard X'에 쓰이는 데이터는 어떤 플랫폼에서 왔을까?' 에대한 질문 쿼리는 다음과 같이 표현할 수 있다.
MATCH (s:DataSink)-[:consumes]->(:Dataset)-[:produces|consumes*2..]->(raw:Dataset)
-[:source]->(dp:DataPlatform)
WHERE s.type =
'Dashboard' AND s.id =
'X'
RETURN raw.id AS sourceDatasetID,
raw.type AS sourceDatasetType,
dp.id AS sourcePlatformID,
dp.type AS sourcePlatformTypeUsing Relationships to Connect Data and Metadata
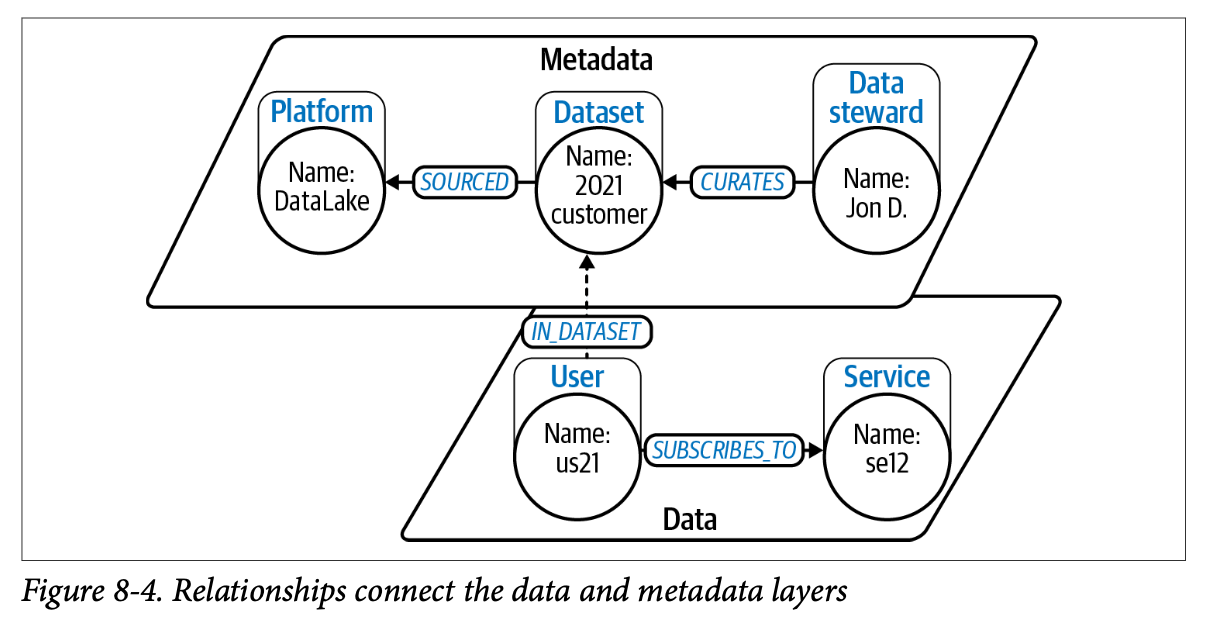
figure 8-4에 있는 아래층 레이어는 고객과 서비스 같은 실제 데이터를 의미한다. 이는 SUBSCRIBES_TO라는 관계로 표현되어 있다. 위층 레이어는 이 데이터가 어디서 왔는지 설명하는 정보로, 고객 정보는 외부 시스템에서 가져온 데이터셋 일부라는 것을 알 수 있다. 즉, 데이터 레이어와 메타데이터 레이어를 연결하면 단순히 고객A가 서비스X를 구독한다는 사실 뿐만 아니라 데이터의 출처와 관리 주체를 추적할 수 있다는 것이다.
이러한 구조의 장점은 원본 시스템을 직접 바꾸지 않고 새로운 레이어를 추가해서 정보를 확장할 수 있다는 점이다. 또한 여러 시스템에 흩어져서 관리되는 정보들을 연결해서 고객의 행동 패턴을 파악하거나 맞춤형 서비스를 제공하는데도 유용하며, 나아가 소유권이나 관리 정보를 통해 데이터 거버넌스를 강화할 수도 있다. 결론적으로, 메타데이터 그래프를 통한 통합 뷰는 시멘틱 검색을 포함한 여러 활용의 기반을 마련한다.
