이전 챕터에서는 통계, 분석 분야의 알고리즘에 대해서 다뤘는데, Chapter7은 머신러닝 기반의 알고리즘을 그래프에서 어떻게 사용하는지 알아본다.
ML in a Nutshell
머신러닝(ML)은 데이터를 기반으로 프로그램을 자동으로 만들어 내는 과정으로, 지식그래프는 ML에 매우 적합한 데이터 소스로 활용될 수 있다. 전통적인 소프트웨어는 입력을 받고 사람이 작성한 함수를 통해 출력을 낸다. 이 과정은 유지보수와 품질 관리에 많은 시간과 자원이 소모된다. 반면, ML은 입력 데이터와 이전 출력 데이터를 학습하여 자동으로 새로운 함수나 규칙을 생성하고, 새로운 데이터가 들어오면 모델을 재학습시켜 출력 품질을 유지한다.
ML이 만들어내는 프로그램은 문제의 성격과 전문가의 선택에 따라 통계적 회귀(regression), 신경망(neural network; 딥러닝), 그래프 기반 기하학 학습(geometric learning) 등 다양한 형태를 보일 수 있으며, 지식그래프를 활용하면 모델의 성능과 품질을 높일 수 있다.
지식그래프와 ML을 결합하는 방식에는 그래프 자체에서 시간에 따른 변화를 예측하는 In-Graph Machine Learning과, 그래프에서 특징을 추출해서 외부 예측 모델을 학습하는 Graph Feature Engineering이 있다. 이 과정에서 ML 모델과 지식그래프는 상호 강화되는 피드백 루프를 형성하여, 모델은 그래프를 풍부하게 만들고, 풍부해진 그래프는 다시 모델 성능을 향상시키며, 반복적으로 서로를 개선해 나간다.
Topological ML
In-Graph Machine Learning은 지식그래프의 누락된 노드나 관계, 속성들을 찾고 추가하는 과정을 통해 스스로 풍부하게 만드는 기술이다. 현실 세계의 지식그래프는 일부 정보가 누락되어 있거나 잘못 표현되어 있는 등 완전하지 않은 경우가 많은데, 이때 그래프의 구조를 활용한 알고리즘을 통해서 데이터 품질을 높일 수 있다. 예제에서는 gds.alpha.linkprediction.preferentialAttachment와 같은 알고리즘을 활용해서 그래프 구조를 기반으로 노드의 연결 가능성을 계산한다.
❓ 이 알고리즘의 정확한 원리에 대해서는 설명하지 않는데, 이후 설명들을 종합해서 이해해보면 이 알고리즘은 규칙 기으로 작동하는 것 같다. '키아누 리브스'의 연결 노드들과 'The matrix'의 구조를 기반으로
ACTED_IN이라는 관계로 연결될 확률을 통계적으로 예측하는 방식으로 추측된다. 즉, 사전에 그래프 구조들을 통해서 관계를 예측하도록 학습하고 새로운 노드들의 관계를 예측하는 알고리즘은 아닌 것으로 추측... 했다.
Graph-Native ML Pipelines
graph-native ML 파이프라인은 그래프에서 데이터를 뽑아서 ML 학습에 필요한 특징(features)를 만들고, 이를 기반으로 예측 모델을 학습하는 과정으로 진행된다. 학습된 모델을 통해 연결되는 링크 예측 뿐만 아니라 노드 레이블이나 속성도 ML을 통해서 예측할 수 있다.
이때 말하는 graph feature engineering은 일반적으로 ML 학습할 때 어떤 feature들을 어떻게 적용할지 테스트하고 적용하는 것과 유사하다. 그래프는 지식그래프의 topology, 즉 연결 구조를 활용하는데, 예를 들어 각 노드의 pagerank, 연결 커뮤니티, 노드의 임베딩 등은 모두 feature가 될 수 있다. 이런 feature 수가 늘어날수록, 예측할 때 쓸 수 있는 정보가 늘어나 결과적으로 성능이 향상된다.
연결되는 링크를 예측하는 파이프라인을 구축하는 과정은 다음과 같다.
- 지식 그래프에서 graph projection 생성
- ML 파이프라인 선언
- 노드 속성 추가: 그래프 알고리즘 결과 기반
- 링크 특징 생성: 노드 쌍(feature vector) 계산
- 데이터 분할: train, test, feature 집합
- 모델 후보 추가: 로지스틱 회귀(Logistic Regression)같은 ML 모델
- 학습 단계의 메모리/연산 요구 추정
- 모델 학습 및 평가
- 평가 기준 만족 시 모델을 프로덕션에 배포
Neo4j에서는 대부분 기능이 이미 구현되어 있어, 직접 구현할 필요는 없고 파이프라인 구성만 선언하면 실행이 가능하다.
Recommending Complementary Actors
이 파트는 Movie 예시 데이터를 활용해서 이전에 같이 연기한 배우 관계를 예측하는 모델 예제를 보여준다.
projection, pipeline 생성
우선, 같은 영화에서 ACTED_IN이라는 관계로 연결되어 있다면 두 배우 노드를 ACTED_WITH라는 새로운 관계로 연결해준다.
MATCH (a:Person)-[:ACTED_IN]->(:Movie)<-[:ACTED_IN]-(b:Person)
MERGE (a)-[:ACTED_WITH]->(b)이후 'actors-graph'라는 projection graph를 생성하고, 사용할 pipeline을 생성해준다.
CALL gds.graph.project(
'actors-graph',
{Person: {}},
{ACTED_WITH: {orientation: 'UNDIRECTED'}}
)CALL gds.beta.pipeline.linkPrediction.create('actor-pipeline')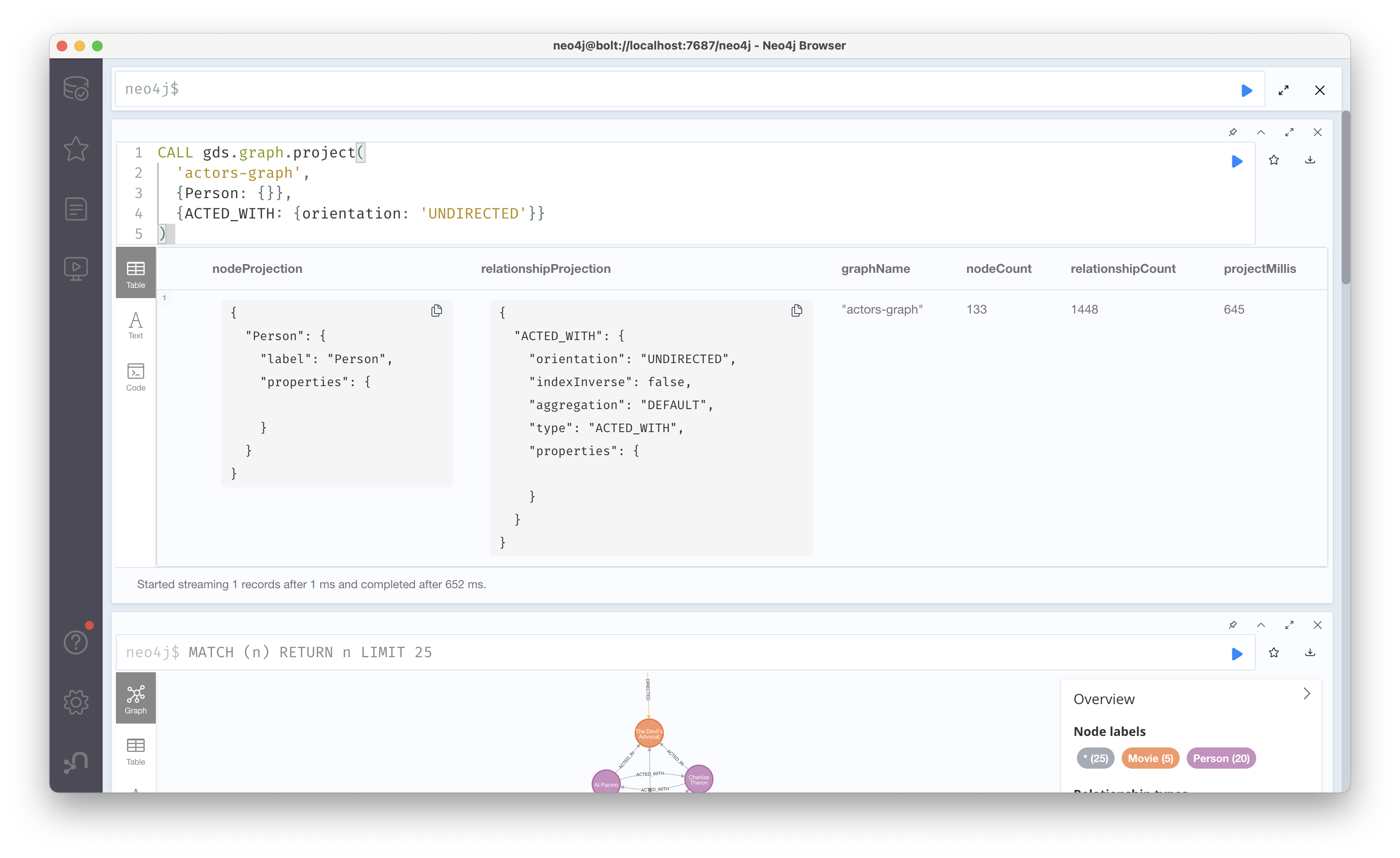
feature 준비
ML학습을 하기 위한 feature는 기존의 노드 속성을 사용하거나 필요한 새로운 속성을 추가할 수 있다. 이 경우에는 같이 작업을 한 배우들의 유사성을 새로운 속성을 추가해주는데, 각 노드를 임베딩 한뒤, 임베딩 벡터를 통해 consine similarity 값은 관계의 속성으로 추가해준다. 우선 노드 임베딩은 FastRP라는 모델을 사용하고, 256차원의 벡터를 randomSeed 42(다시 실행해도 동일한 결과를 얻기 위해서)로 실행한다.
CALL gds.beta.pipeline.linkPrediction.addNodeProperty('actor-pipeline','fastRP', {
mutateProperty: 'embedding',
embeddingDimension: 256,
randomSeed: 42
})이후 임베딩 벡터 간의 consine similarity를 계산해서 embedding이라는 속성을 추가해준다.
CALL gds.beta.pipeline.linkPrediction.addFeature('actor-pipeline','cosine'
, {nodeProperties: ['embedding']
}) YIELD featureStepstrain, test, valid 데이터 준비
최종적으로 학습을 위해 train, test, valid를 0.6, 0.25, 0.15 비율로 분할하고, 3회 교차검증을 수행한다.
CALL gds.beta.pipeline.linkPrediction.configureSplit('actor-pipeline', {
testFraction: 0.25,
trainFraction: 0.6,
validationFolds: 3
})학습에 사용할 모델 알고리즘 후보 추가할 수 있는데, 여기서는 로지스틱 회귀만 추가했다.
CALL gds.beta.pipeline.linkPrediction.addLogisticRegression('actor-pipeline')학습에 사용되는 메모리를 우선적으로 확인해서 내가 가진 리소스가 충분한지 검토하는 과정이 필요하다. "[411 KiB ... 4332 KiB]"가 출력되어 최대 4.3mb가 소요된다는 것을 추측할 수 있다.
CALL gds.beta.pipeline.linkPrediction.train.estimate('actors-graph', {
pipeline: 'actor-pipeline', modelName: 'actors-model'
,targetRelationshipType: 'ACTED_WITH'
})
YIELD requiredMemory모델 학습
이후 실제 학습을 진행하는데, 성능평가는 AUCPR(AUC-Precision-Recall)로 진행하고 ACTED_WITH라는 관계를 예측하게 된다.
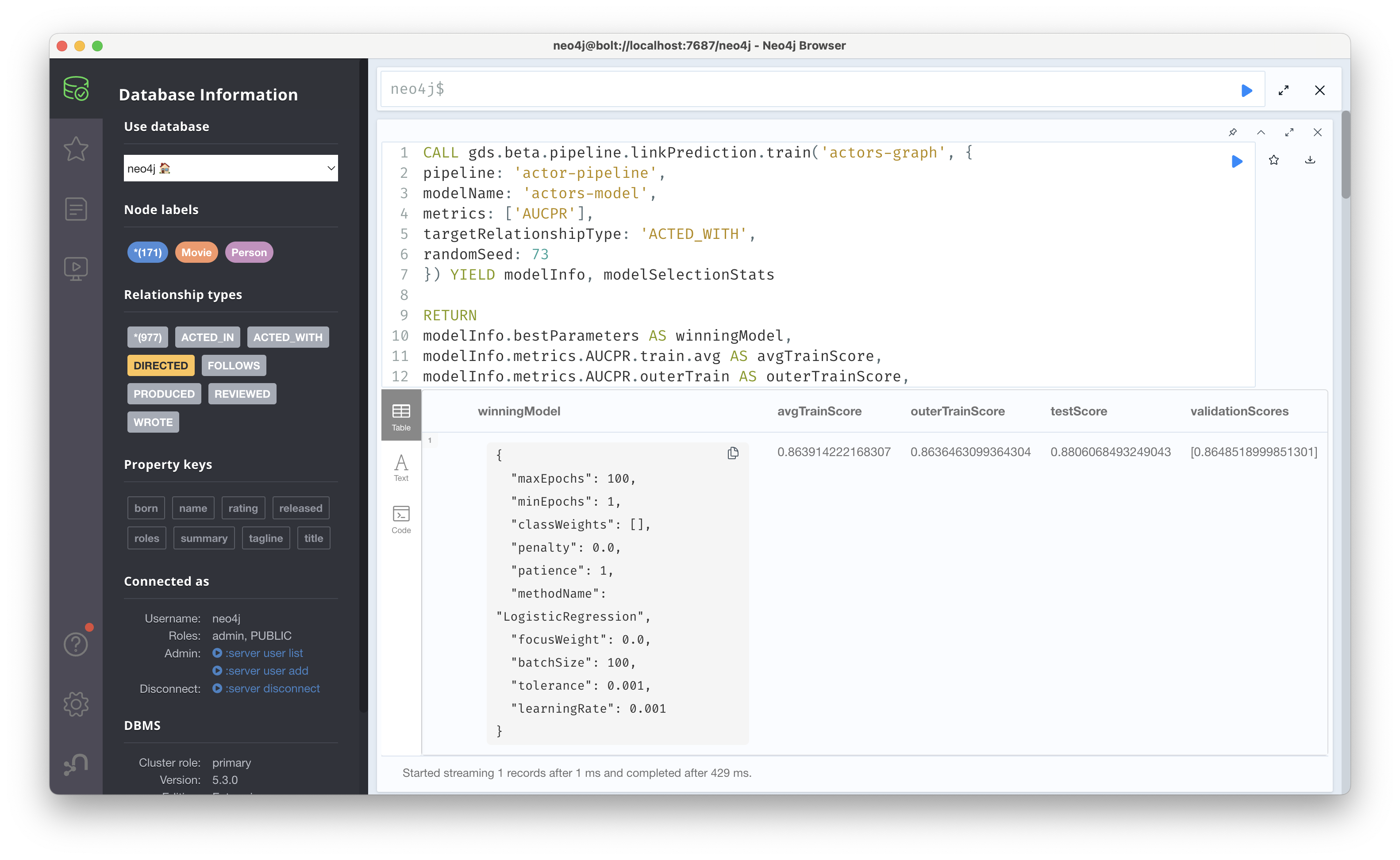
CALL gds.beta.pipeline.linkPrediction.train('actors-graph', {
pipeline: 'actor-pipeline',
modelName: 'actors-model',
metrics: ['AUCPR'],
targetRelationshipType: 'ACTED_WITH',
randomSeed: 73
}) YIELD modelInfo, modelSelectionStats
RETURN
modelInfo.bestParameters AS winningModel,
modelInfo.metrics.AUCPR.train.avg AS avgTrainScore,
modelInfo.metrics.AUCPR.outerTrain AS outerTrainScore,
modelInfo.metrics.AUCPR.test AS testScore,
[cand IN modelSelectionStats.modelCandidates |
cand.metrics.AUCPR.validation.avg] AS validationScores학습 결과를 보면 testScore가 0.88, validationScores도 0.86으로 비교적 높은 성능으로 학습이 된 것을 볼 수 있다.
prediction
다음은 학습을 모델을 활용해서 예측을 진행하는 과정이며, 우선 새로운 projection을 생성한다.
CALL gds.graph.project(
'actors-input-graph-for-prediction',
{Person: {}},
{ACTED_WITH: {orientation: 'UNDIRECTED'}}
)이후 학습된 'actors-model'을 사용해서 ACTED_WITH관계를 예측하고, 예측된 관계를 SHOULD_ACT_WITH라고 projection에 표현한다. topN: 20이라고 설정한 부분은 각 노드마다 최대 20개의 추천 관계만 생성하도록 하는 것이고, 확률이 0.4 이상일 때만 생성하도록 threshold를 설정했다.
CALL gds.beta.pipeline.linkPrediction.predict.mutate(
'actors-input-graph-for-prediction', {
modelName: 'actors-model',
relationshipTypes: ['ACTED_WITH'],
mutateRelationshipType: 'SHOULD_ACT_WITH',
topN: 20,
threshold: 0.4
})
YIELD relationshipsWritten, samplingStatsmutate 대산 stream을 사용하면 바로 결과(노드 쌍 + 예측 확률)를 반환해서 확인할 수도 있다고 한다.
원본DB에 반영
지금까지의 결과는 projection에만 존재하고, 원본 DB에는 반영되지 않은 상태인데, 이를 반영해주려면 gds.util.asNode를 사용해서 원본 노드에 매핑해주어야 한다. 이후 MERGE를 통해서 그래프에 저장해준다.
CALL gds.beta.graph.relationships.stream(
'actors-input-graph-for-prediction', ['SHOULD_ACT_WITH']
)
YIELD sourceNodeId, targetNodeId
WITH gds.util.asNode(sourceNodeId) AS source, gds.util.asNode(targetNodeId) AS target
MERGE (source)-[:SHOULD_ACT_WITH]->(target)현재 SHOULD_ACT_WITH는 대칭 관계(a->b == b->a)이므로 중복을 제거해준다.
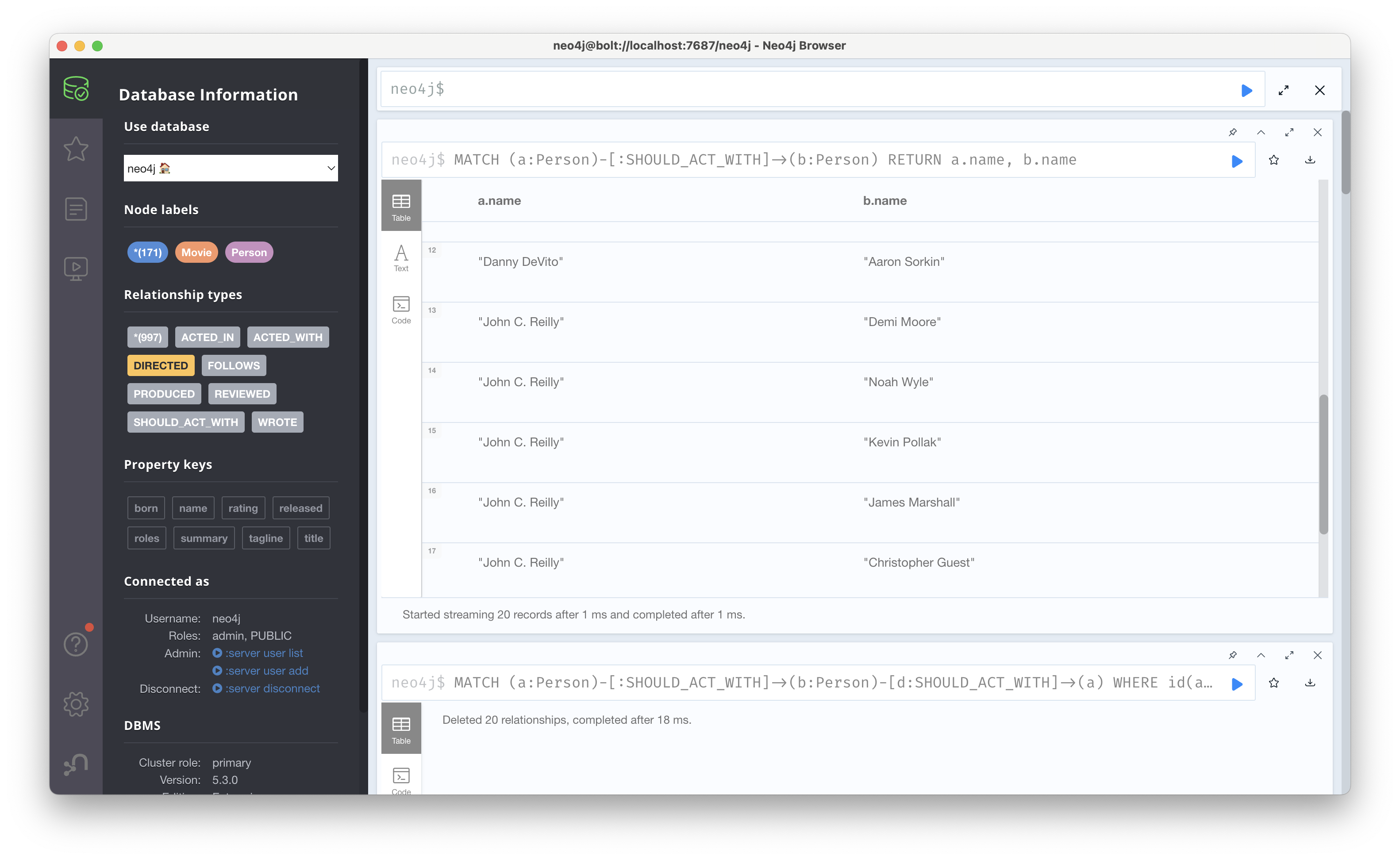
MATCH (a:Person)-[:SHOULD_ACT_WITH]->(b:Person)-[d:SHOULD_ACT_WITH]->(a)
WHERE id(a) > id(b)
DELETE dMATCH (a:Person)-[:SHOULD_ACT_WITH]->(b:Person) RETURN a.name, b.name 로 질의한 결과를 보면 아래와 같이 예측된 관계들이 나온다.