서로 다른 시스템의 데이터를 통합할 때, 두 개의 레코드가 동일한 객체를 나타낸다는 것을 판단하는 것은 중요하다. 이 챕터에서는 지식그래프가 어떻게 동일 객체 식별 문제를 해결할 수 있는지, Entity Resolution 혹은 MDM(Master Data Management) 등과 같은 기법을 위주로 설명한다.
Knowing Your Customer
은행에서는 동일한 인물을 식별하는 것이 중요한 포인트가 된다. 예를 들어 Jane 'Coleman'이 결혼을 해서 Jane 'Downe'라고 성을 바꾼 경우, 이 둘이 동일한 사람이라는 것을 인식해야 은행 업무 처리에 혼선이 없다. 만약 개별 고객이 유니크한 식별자를 갖고 있는 경우, 이 식별자에 두 이름을 매칭만 해주면 이 문제는 간단하게 해결된다. 그러나 모든 데이터에서 공통으로 사용되는 하나의 식별자가 존재할 가능성은 낮다.
rowid, Source, AccountNo, Name, Passport, DriversLic, DOB
1, "Credit", 9918475, "Pete Downe", "VX83041",, 1987-03-12
2, "Current", 2436930, "Peter J. Downe", "VX83041",, 1987-03-12
3, "Credit", , "Jane Coleman", ,"49587640", 1989-10-28
4, "Current", 2436930, "Jane Downe", "RA14958", , 1989-10-28예를 들어, 위 예시 데이터에서 1행과 2행은 여권 번호를 통해 쉽게 연결할 수 있지만, 3행과 4행은 여권번호와 운전면허 번호가 각각 한 곳에만 기입되어 있어 연결의 어려움이 있다. 이 데이터만으로는 결국 Jane Coleman과 Jane Downe를 다른 사람이라고 판단할 수 밖에 없는 것이다. 이와 같이 서로 다르게 표현된 동일 개체를 파악해야 하는 상황은 다음과 같은 케이스가 있다.
1. Data integration: 서로 다른 시스템의 데이터를 통합할 때
2. Anonymous activity: 시간, 쿠키ID, 탐색 정보 등을 기반으로 패턴을 파악하고 사용자와 세션을 식별해야 하는 경우
3. Intentional/fraudulent duplicates: 악의적으로 시스템을 속여서 여러 계정을 만들거나 가입하려는 경우
Graph-Based Entity Resolution Step by Step
Entity Resolution은 (1) Data preparation (2) Entity matching (3) Curation of persisted record of master entities 의 순서로 진행된다. 아래 예시 데이터를 활용해서 이 과정이 어떻게 이뤄지는지 하나씩 살펴보도록 하겠다.
1️⃣ Data preparation
데이터 준비 과정에서는 한 개 이상 출처의 데이터들의 품질을 정제하고 맞춰주는 작업을 수행한다. 예를 들어, 표현된 수치의 단위를 맞춘다거나 정규화, 타입 변환, 결측치 정제 등의 기본적인 전처리가 포함된다. 이 과정은 Python을 통해서 사전에 csv 파일을 정제해서 그래프로 변환해도 되고, Cypher 쿼리를 통해 그래프 DB에 임포트 한 뒤 정제를 해주는 방법이 있다. 이 교안에서는 후자의 방법을 소개한다.
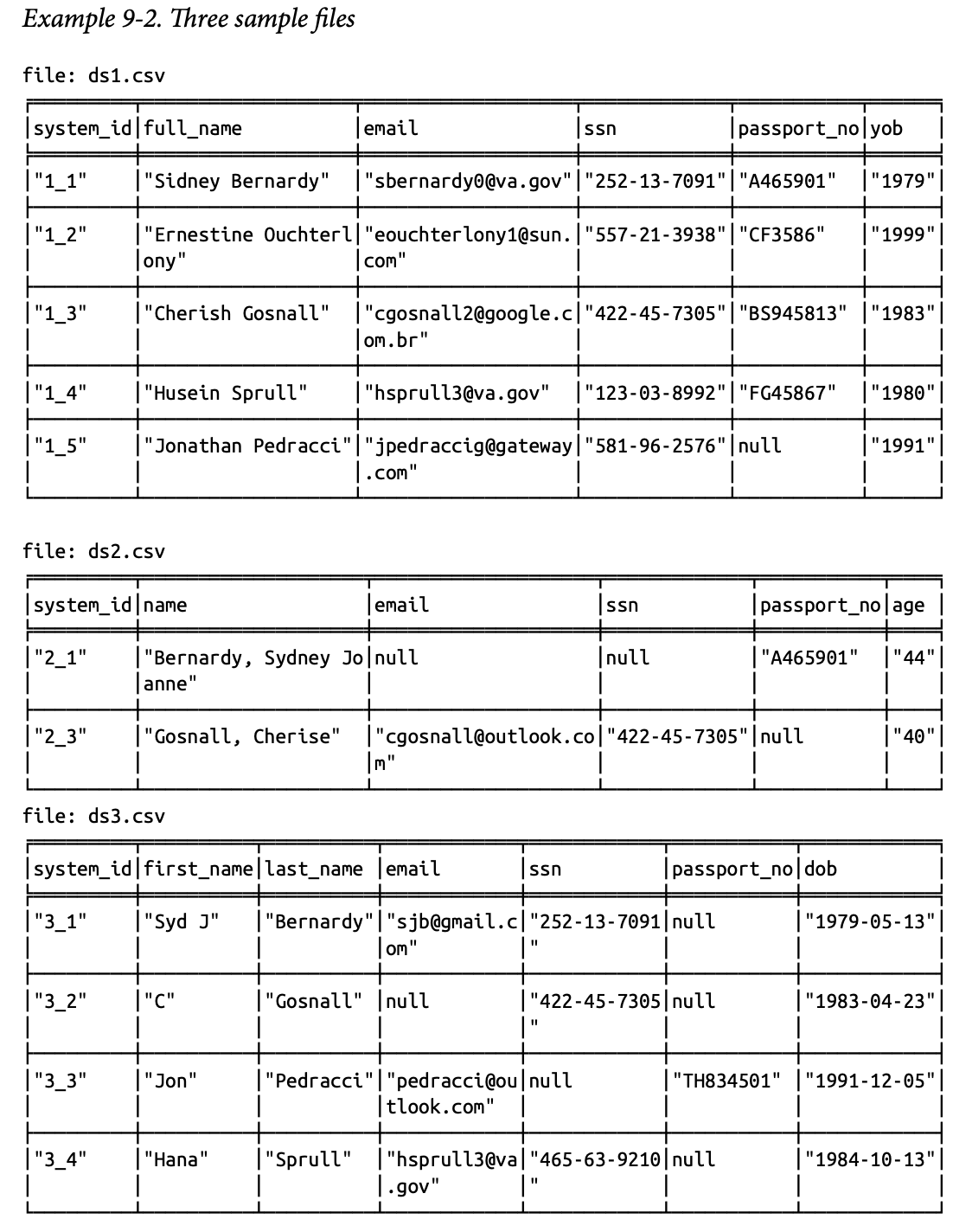
우선, 위 세 개의 데이터를 로드하고, 각 엔티티 노드를 :Person으로 모델링한다.
LOAD CSV WITH HEADERS FROM "file:///ds1.csv" AS row
CREATE (p:Person) set p.source = "ds1", p += properties(row) ;
LOAD CSV WITH HEADERS FROM "file:///ds2.csv" AS row
CREATE (p:Person) set p.source = "ds2", p += properties(row) ;
LOAD CSV WITH HEADERS FROM "file:///ds3.csv" AS row
CREATE (p:Person) set p.source = "ds3", p += properties(row) ;이 세 데이터의 가장 큰 차이는 객체를 표현하는 정도(level)이 다르다는 건데, ds1의 경우 생년월일을 연도만 표현하고 있지만, ds3는 연-월-일으로 보다 구체적으로 표현하기 때문이다. 이런 경우에, ds3의 값을 각각 분리한 컬럼으로 만들어주면 매칭에 활용할 수 있는 feature가 갖춰진다. 이와 유사하게 이름의 표현방식(성, 이름으로 표현했는지 등)도 데이터 간의 표현방식의 통일이 필요하다.
추가로, 이 단계에서는 매칭 연산을 줄일 수 있는 blocking 작업을 위한 키를 설정할 수도 있다. 즉, 매칭에 활용할 특정 키를 고르거나 생성하는 과정을 의미한다.
2️⃣ Entity Matching
정제한 데이터를 기반으로 본격적으로 동일한 엔티티를 찾아주는 ER을 수행할 수 있다. 어떤 조건이 성립했을 때 두 엔티티가 동일하다고 표현할 건지 규칙을 정해야 하며, 이 규칙은 도메인 지식을 기반으로 휴리스틱하게 수립된다. 이 규칙들은 일반적으로 정확하게 일치하는 것(exact match), 확률적으로 근사한 것(approzimate match; 거리기반 유사도 등), 퍼지요소(fuzziness; 문자열 유사도 혹은 값 근사 등) 등을 기반으로 구성된다.
다음은 매칭 규칙을 적용하는 접근 방식들이다.
- 명확한 식별자가 일치하는 경우
SAME_AS관계를 생성한다. - 임계값(thredhold) 이상으로 일치하지만 동일하지는 않는 경우
SIMILAR관계를 생성한다. - 명확한 식별자가 불일치하는 경우
SIMILAR관계를 삭제하고, similarity score 기반의 가중치를 준다. - 비식별 특성에서 임계값 이상으로 일치하는 경우, 보정계수(correcting factor)를 적용한다.
- 유사도 점수가 최소 임계값 이하인 경우
SIMILAR관계를 삭제한다.
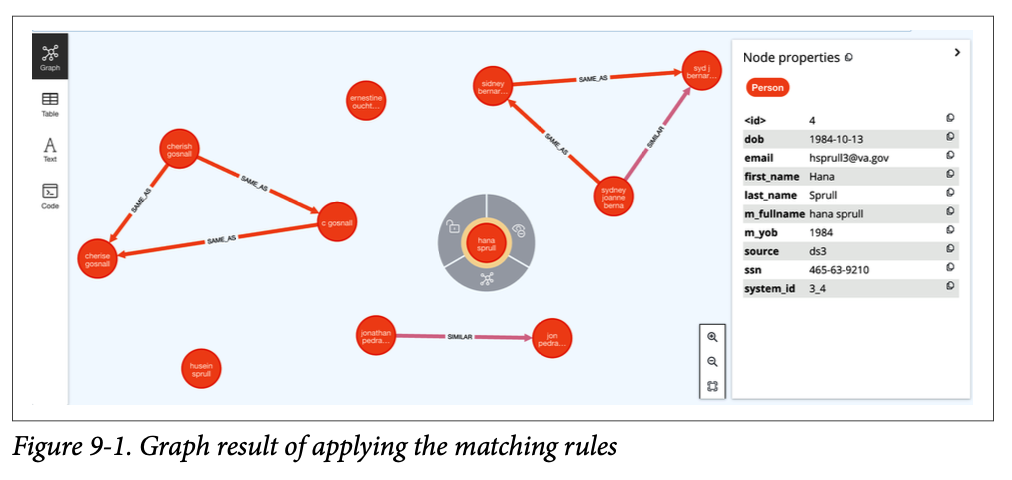
이런 규칙들을 통해 SAME_AS와 SIMLILAR관계로 연결된 그래프를 형성할 수 있다.
책에서는 이 과정들을 Cypher 쿼리를 통해 해결하는 방법을 설명한다. 다만, 본인은 Cypher가 익숙하지 않고, 대규모 데이터인 경우 Python으로 사전에 처리를 하는 것이 더 나을 것 같다는 개인적인 생각을 했다(적절한 임계값을 찾기 위해서 반복적인 작업을 수행해야 할 것 같기도 하고, 최종적인 검토도 필요할 것 같다). 책에서도 하나의 반드시 따라야 하는 방법은 없으니 특성에 따라 선택하면 된다..고 나와있는 만큼, 선택적으로 적절한 방식을 선택하면 될 것 같다.
3️⃣ Curation of persisted record of master entities
동일한 엔티티를 식별한 뒤에는 최종적으로 '마스터 엔티티'를 생성해야 한다. 즉, 'Cathy Lee', 'Catherine, Lee', 'Lee, Cathy' 라는 값들이 하나의 엔티티로 묶인 경우, 이를 묶어서 하나의 대표 엔티티로 만드는 작업이다. 이 작업은 WCC(Weakly Connected Component) 알고리즘을 통해 수행할 수 있는데, 그래프 안에서 SAME_AS, SIMILAR로 연결되어 있으면 모두 같은 그룹으로 가정해서 일종의 묶음으로 만들어주는 것이다.
CALL gds.graph.project(
'identity-wcc',
'Person',
['SAME_AS','SIMILAR']
)최종적으로 아래와 같이 동일한 golden_id를 갖는 값들은 동일한 엔티티로 묶여지고 대표값을 지정할 수도 있다.
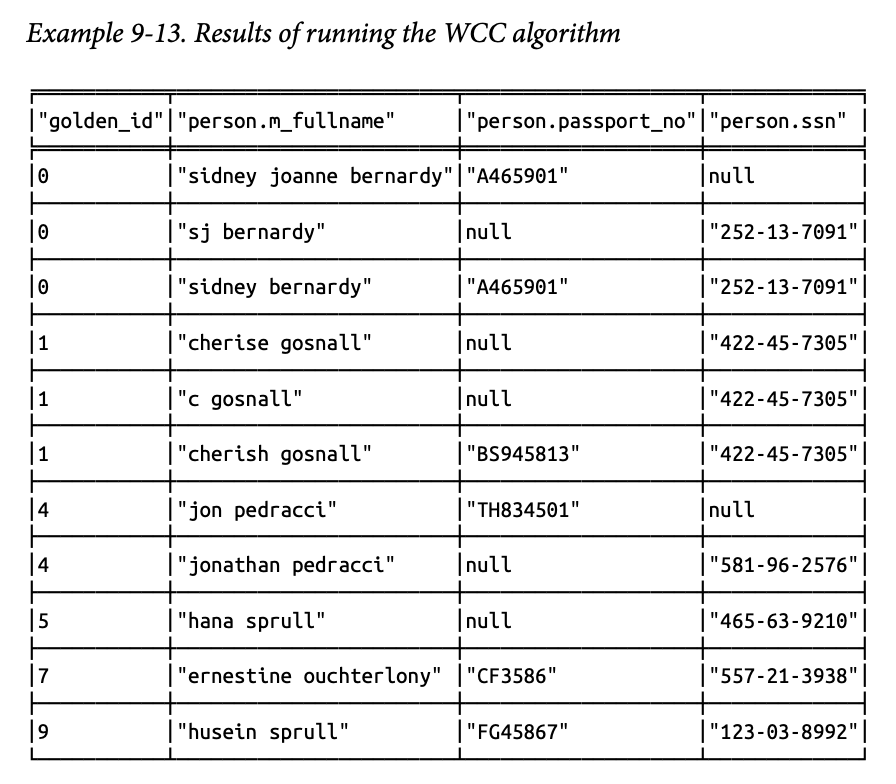
한편, 데이터는 지속적으로 변경되므로 ER작업은 반복적 수행이 필요하다. 새로운 매칭이 생길 수도 있고, 기존의 그룹이 쪼개지거나 바뀔수도 있다. 또한 단순히 노드의 속성만 보지 않고, 관계 정보나 이웃노드 정보를 활용하여 매칭할 수도 있는데, 예를 들어, 관계에 있는 속성값이나 구조조 지표(중심성, 기타 메트릭 등), 주변 노드의 특징을 활용하여 더욱 정교한 결과를 얻을 수 있다.
Working with Unstructured Data
데이터를 통합할 때 사용할 수 있는 명확한 식별자가 없는 경우에는 더욱 정교한 정제가 필요하며, 비정형 데이터에서는 주로 유사도를 기반으로 접근한다. Amazon과 Google의 제품 카탈로그 데이터 세트는 좋은 사례인데, 이 데이터 세트는 Amazon.com에서 1,363개, Google 제품에서 3,226개의 제품 설명을 포함한다. 두 데이터 소스에서 공통으로 사용되는 속성은 제품명, 제품 설명, 제조사, 가격이다.
가장 먼저 해야 하는 일은 토큰화인데, 제품명을 모두 소문자로 바꾸고, 알파벳과 숫자가 아닌 모든 문자를 정규표현식을 통해 제거한다. 이후 split을 통해서 공백 단위로 문자열을 분리한다.
비정형 데이터이고, 토큰화를 하는데 csv 형태라는게 살짝 의문이긴 하지만, 문장형 값이 한 열에 들어 있다고 이해했다.
CREATE INDEX FOR (w:Word) ON w.txt ;
MATCH (p:Product { source : "GGL" })
UNWIND [x in split(apoc.text.replace(tolower(p.name),"[^a-zA-Z0-9]", " ")," ")
WHERE x <> "" ] AS txt
MERGE ( w:Word { txt: txt }) merge (p)-[:includes]->(w) ;
MATCH (p:Product { source : "AMZ" })
UNWIND [x in split(apoc.text.replace(tolower(p.title),"[^a-zA-Z0-9]", " ")," ")
WHERE x <> "" ] AS txt
MERGE ( w:Word { txt: txt }) merge (p)-[:includes]->(w) ;이 과정을 거치면 제품명과 단어들이 연결된 아래와 같은 네트워크를 형성할 수 있다.
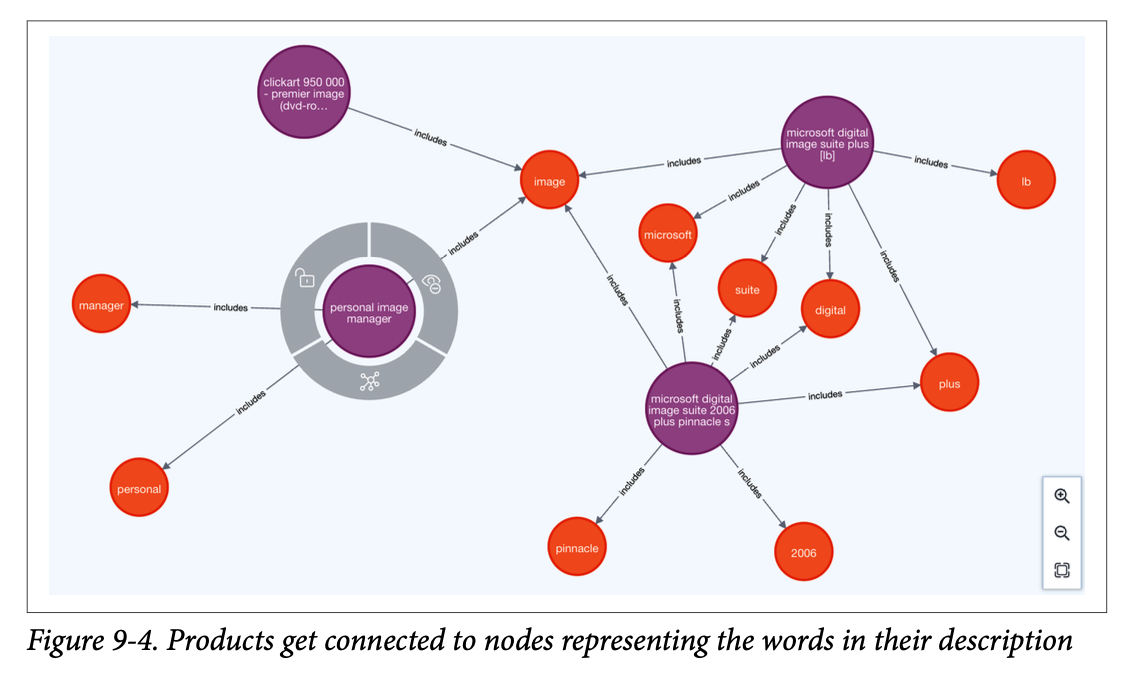
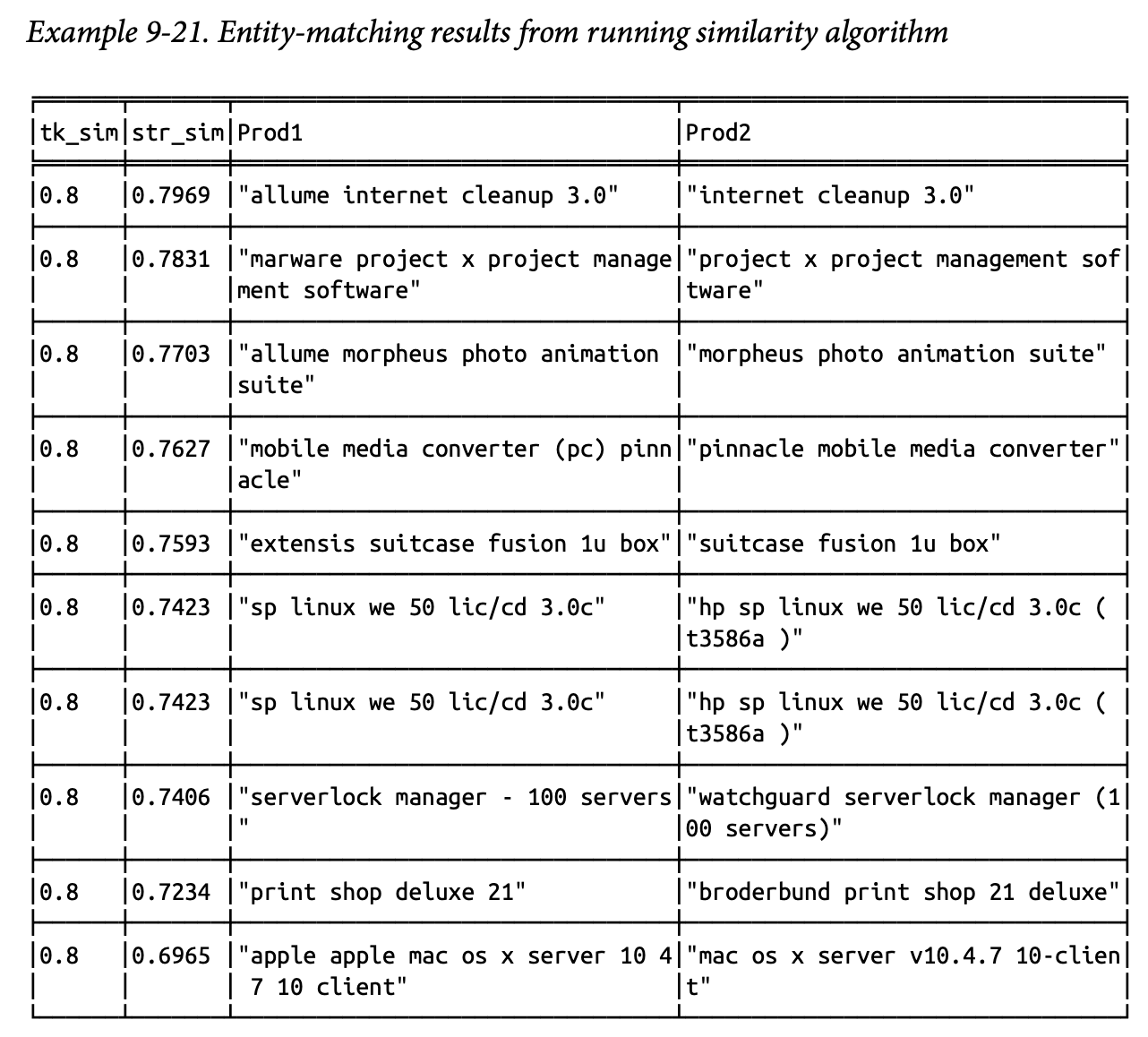
이제 구조적 유사도 알고리즘을 통해서 두 노드가 얼마나 유사한지 확률적으로 계산하는데, 유사도 계산 방식은 자카드 계수 (Jaccard Similarity;두 집합이 얼마나 겹치는지 비율로 측정)와 Overlap 계수 (Szymkiewicz–Simpson; 작은 집합을 기준으로 얼마나 많이 겹치는지 측정) 등을 사용할 수 있다. 즉, 동일한 단어를 많이 가질수록 두 노드의 유사도는 높아지는 것이다. 이때 문자열 유사도(jaro-winkler나 레벤슈타인 등)보다 토큰 기반 유사도의 정확도가 더 높다고 설명하는데, 토큰 단위로 끊어서 보면 공유하고 있는 단어들을 확일할 수 있어서 전체적으로는 유사하게 안보이더라도 실제 같을 확률을 더욱 안정적으로 확인할 수 있기 때문이다.
아래 표는 tk_sim(토큰 기반 유사도)와 str_sim(문자열 기반 유사도) 수치를 포함하고 있다. 이 수치가 임계값이 넘는 경우만 동일한 노드로 묶어주면 된다.