
chapter10에서는 지식그래프에서 패턴을 찾는 방법을 두 가지 활용 사례를 통해 소개한다. 지식그래프는 논리적으로 centralized, curated, contextualized 라는 특징을 가지며, 따라서 그래프에서 발견한 패턴은 이상치 혹은 오탐지, 인사이트 발견 등으로 이어질 수 있다.
1️⃣ Fraud Detection
지식그래프는 심각한 사회 문제 중 하나인 온라인 사기 탐지에 활용될 수도 있다. 예를 들어, 신용카드는 거래되는 금액이 크고, 카드와 제공자 전반에 걸쳐 발생하는 거래량이 방대하기 때문에 사기에 노출될 확률이 높다. 이 결제가 정상적인 결제인지 사기인지 구분하기 어렵기 때문이다.
전통적으로 금융 회사들은 특정 단어, 계정, 위치를 탐색해 위험 점수를 부여하는 규칙 기반 전략을 사용했고, 이를 수동으로 검토했다. 그러나 이 방식은 느리고 비용이 많이 든다는 한계가 있다. 반편, 지식그래프는 고객의 넓은 연결성과 맥락을 통해서 더 깊이 있는 통찰을 일괄적으로 얻을 수 있다는 장점이 있다.
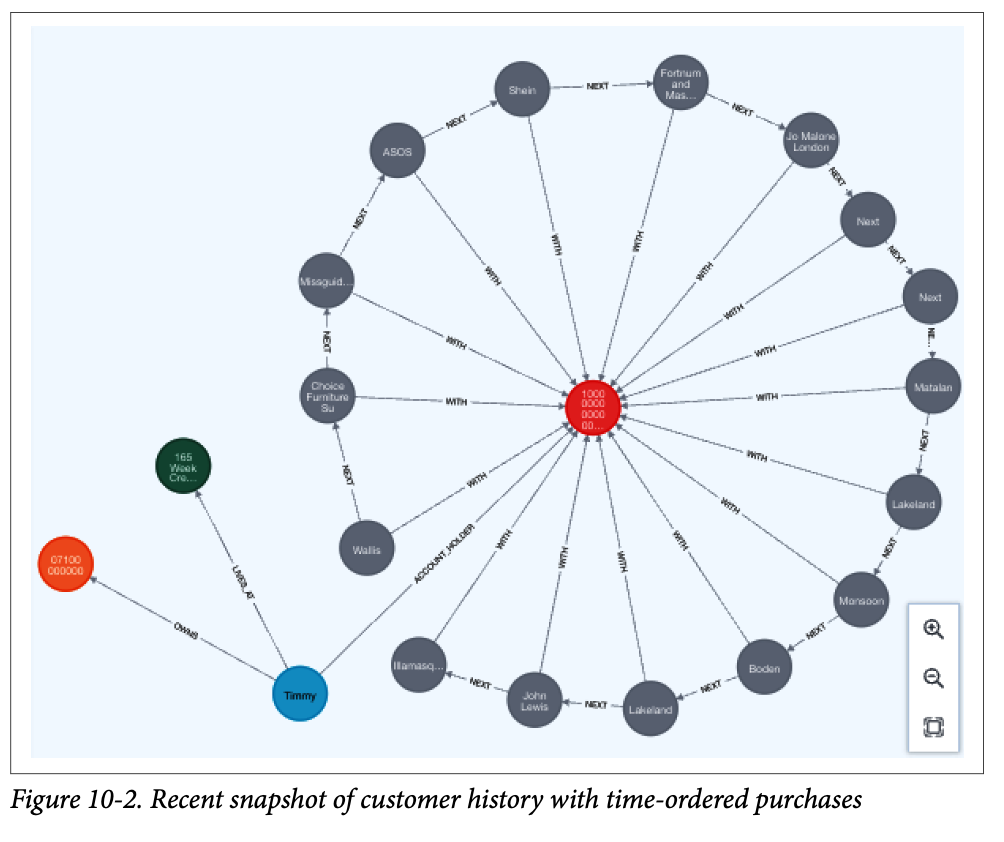
위 그래프는 한 고객의 카드 번호(빨간색 노드)를 중심으로 구매 내역을 연결하고, 시간 순서에 따라서 NEXT로 연결한 것이다. 그러나 모든 고객의 정보를 이렇게 표현하기에는 시간도 자원도 많이 소요된다.
따라서 실제로 연결된 그룹(커뮤니티)을 찾아내고, 그 특성이 정상적인 것인지 사기 의심 패턴인지 분석하는 방식을 적용할 수 있다. 즉, '개인별 지식그래프'가 아닌 '사람들의 관계망을 통한 커뮤니티 구조(Fraud Rings)'를 활용해서 특이 패턴을 찾는 것이다.
MATCH (:Person) WITH count(*) AS count
MATCH (a:Person)-[*2..4]-(b:Person)
WHERE rand() < 10.0/count
RETURN a이런 패턴을 찾기 위해 위 Cypher를 사용할 수 있다. 모든 Person 노드를 찾아서 전체 개수를 세고, 깊이 2~4 범위에서 노드 사이의 경로를 매칭해서 정상적인 단일 개인 서브그래프(? 한 사람에게 연결된 세부 정보로 구성된 서브그래프를 의미하는 듯)는 제외한다. 이후 현재 매치 결과를 포함할지 말지를 랜덤으로 결정해서 샘플을 얻는다.
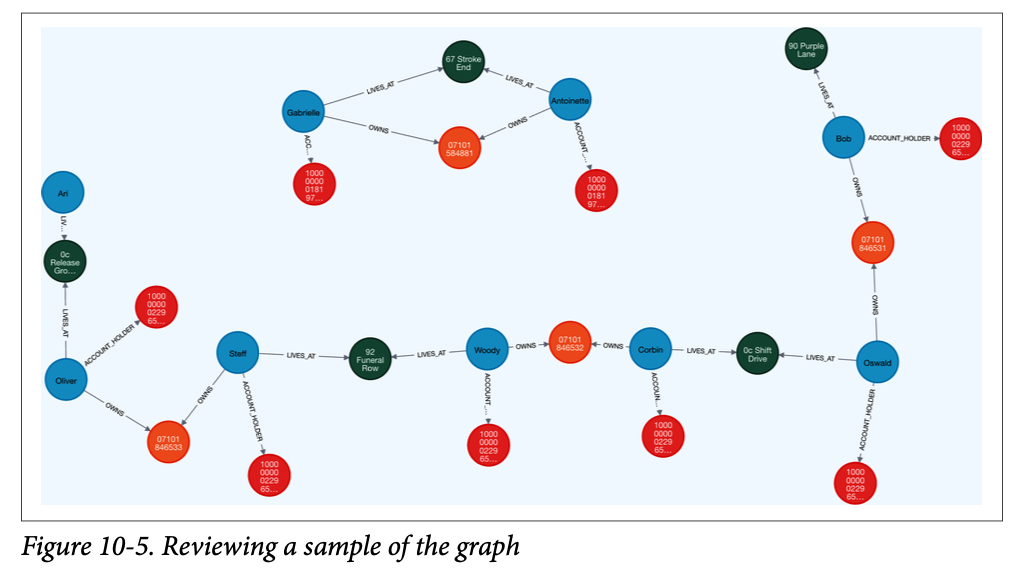
정상적인 서브그래프를 제외하고 남은 그래프는 위와 같은 형태를 띄는데, 두 사람이 하나의 전화번호와 신용카드를 소유하고, 단독 주소에 거주하는 것은 일반적인 패턴과 다르다는 것을 알 수 있다. 그러나 이것만으로는 바로 사기라고 단정하기는 어렵다.
따라서 도메인 전문가가 최종 판단을 하거나, 이상치 패턴에 ML과 통계 기법을 보조적으로 사용해서 잠재적 범죄를 발견할 수 있다. 주소지를 공유하거나 전화번호를 공유하는 집단 중 하나는 사기 조직일 가능성이 높다는 것 예측을 할 수 있는 것이다. 이를 통해 빠르게 cash-out(현금화)를 막거나 더 큰 피해에 대응할 수 있게 된다.
한편, 앞서 언급했듯 위와 같이 동일한 주소지를 공유하거나 전화번호를 공유한다고 해서 반드시 사기 집단이라고 단정할 순 없다. 가족이거나 직장 번호일 가능성도 존재하기 때문이다. 따라서 정상적인 공유 패턴을, 예를 들어 가구원(household)인 경우 같은 주소를 공유하는데 전화번호를 갖는 것이 당연하므로 이를 거르는 것이 중요하다. 책에서는 아래와 같은 Cypher 쿼리를 예시로 설명하고 있다.
MATCH households=(p:Person)-[:LIVES_AT]->(:Address)
<-[:LIVES_AT]-(:Person)-[:OWNS]->(:Phone)<-[:OWNS]-(p)
RETURN households결론적으로, 지식그래프 기반의 사기 탐지는 전문가들이 정의한 정상/사기 패턴을 바탕으로 그래프 알고리즘, 머신러닝, 시각화 등을 활용해서 방어 체계를 갖추게 된다. 실제 운영에서는 고객이 거래를 시도할 때 해당 고객을 중심으로 한 작은 서브그래프를 빠르게 조회해 패턴을 매칭한다. 이렇게 하면 거래 승인 과정에서 지연이 거의 발생하지 않으면서도 사기 여부를 즉시 점검할 수 있다. 다만, 거래의 위험도가 높거나 금액이 큰 경우에는 더 넓은 범위의 그래프를 탐색하거나 데이터 사이언스 기법을 추가로 적용할 수 있다. 이 과정은 시간이 더 걸리므로 전체 거래가 아닌 일부 고위험 거래에 한정해 사용하는 것이 바람직하다. 따라서 기본적으로는 저지연의 서브그래프 탐색으로 효율적인 실시간 검증을 수행하고, 필요할 때만 고비용 분석을 병행하는 것이 고객과 회사를 모두 보호하는 효과적인 방법이다.
2️⃣ Skills Matching
지식그래프는 숙련된 사람을 채용할때, 그리고 채용한 사람을 적절한 부서나 프로젝트에 배치하는 과정에서 활용될 수 있다. 보유 기술, 직급, 프로젝트 경험 수준, 언어 능력 등 각각의 요소들을 독립된 레이어로 모델링하고, 쿼리 시점에 통합해서 통합하여 복잡한 질문에 답변하는 예제를 하나씩 살펴보겠다.
Skills/Expertise KG
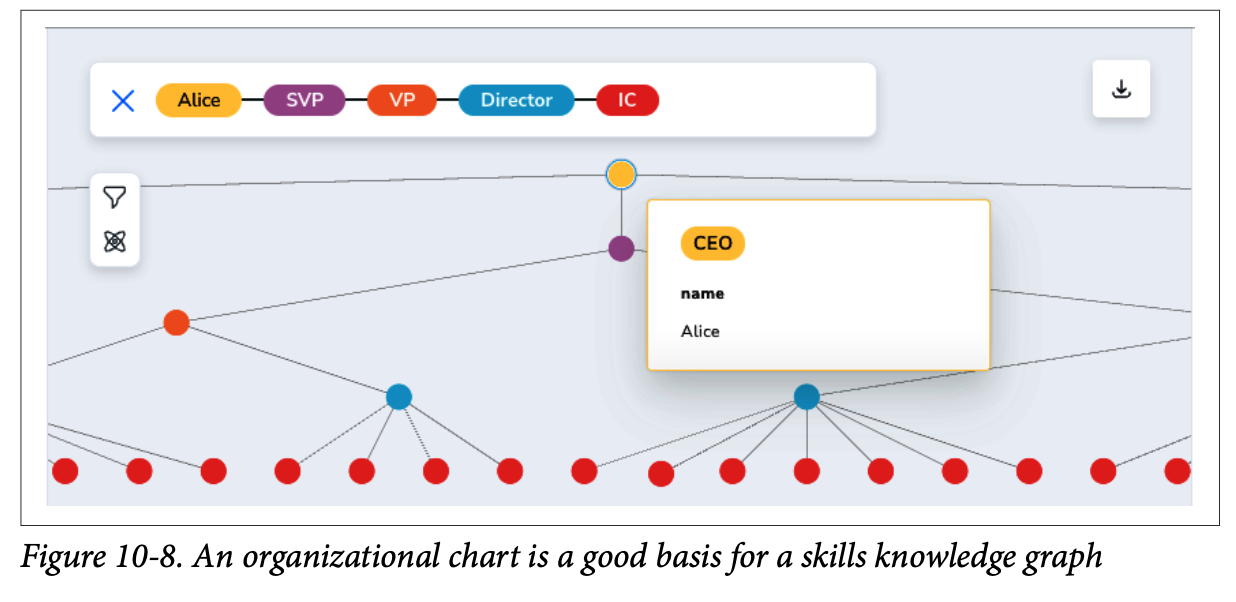
가장 먼저 tree 형태로 표현된 조직도는 계층 구조를 가지며, 지식그래프의 기본 레이어가 될 수 있다. 이를 통해 특정 부서나 프로젝트에 몇 명이 있는 확인할 수 있고, HR팀에서는 조직 계층을 이해하거나 변경할 때 활용할 수 있다. 그러나 조직도에는 실제 업무와 밀접한 내용, 예를 들어 협업방식이나 기술 등과 같은 정보들은 포함되지 않을 가능성이 높다.
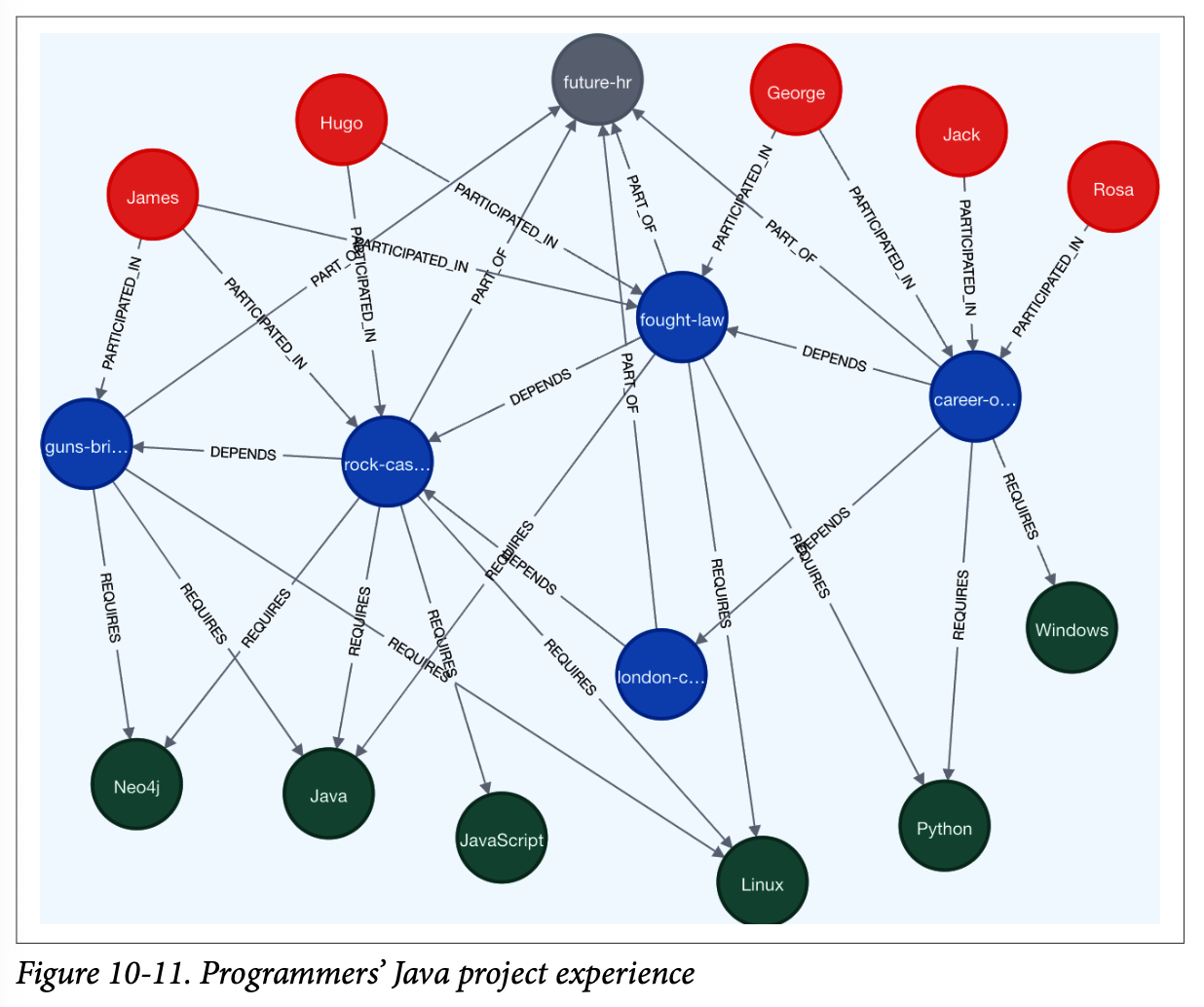
만약 JAVA를 활용한 프로젝트에 참여한 사람들을 찾고 싶다면, 조직도가 아닌 기술 정보가 기록된 KG를 활용해야 한다. 위 그래프처럼 파란색 노드에는 프로젝트를, 해당 프로젝트에서 활용한 기술들은 초록색 노드에, 그리고 이 기술을 활용한 참여자인 빨간색 노드로 표현된다. 즉, 프로젝트와 프로그램을 통해 사람들이 어떤 기술에 관여했는지 파악할 수 있는 것이다.
또한 MATCH (java:Skill {name:'Java'})<-[:REQUIRES]-(:Project)<-[:PARTICIPATED_IN]-(ic:IC) RETURN DISTINCT ic.name 와 같은 쿼리를 활용하면, JAVA 프로젝트에 참여한 사람들을 찾을 수 있고, 프로젝트 참여 횟수를 기반으로 숙련도 혹은 경험치를 계산할 수도 있다.
MATCH (:Skill {name:'Java'})<-[:REQUIRES]-(:Project)<-[:PARTICIPATED]-(e:Employee)
CALL {
WITH e
MATCH (e)-[:PARTICIPATED]->(p:Project)
RETURN collect(duration.inMonths(p.start, p.end).months) AS duration
}
RETURN DISTINCT e.name,
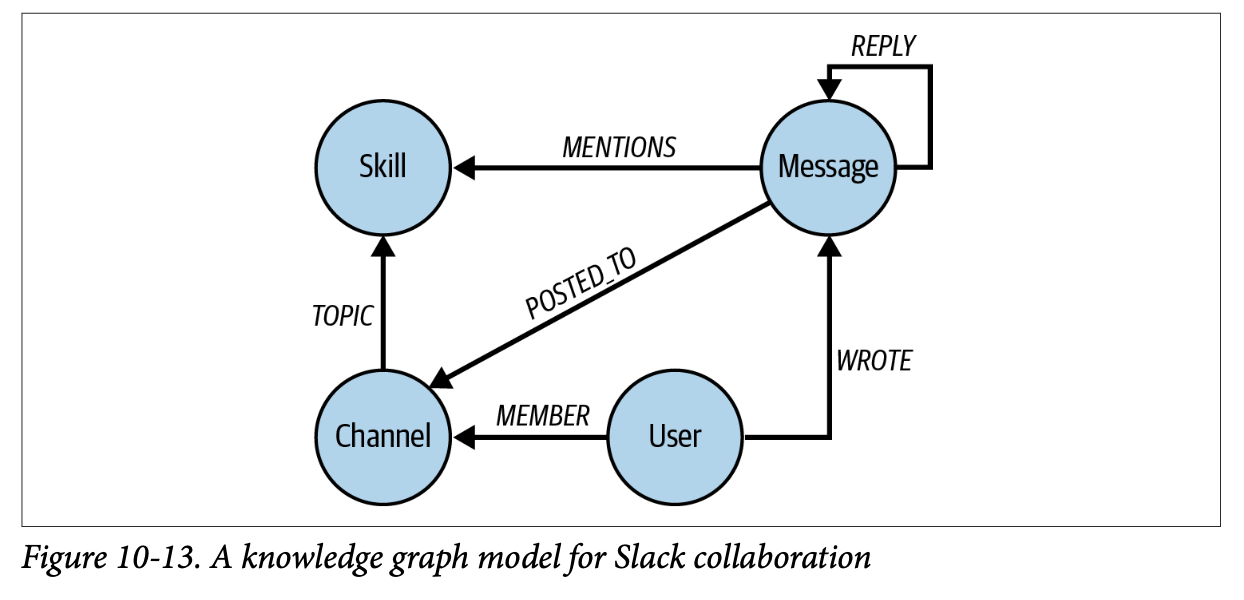
reduce(total=0, number in duration | total + number) AS monthsOfExperience한편, 이렇게 프로젝트 단위의 기술 숙련도도 중요하지만, 실제 업무 환경에서 역할을 파악하는 것은 실질적인 조직의 구조를 반영할 수 있다. 예를 들어 Slack, MS Teams 등과 같은 업무용 소통 시스템에서 서로 언급하고, 연락을 한 내용을 기반으로 구성한 그래프를 레이어에 추가할 수 있다. 이를 통해 특정 업무에 실제로 조언을 해줄 수 있는 적합한 사람을 더 쉽게 찾을 수 있다.
Individual Career Growth, Organizational Planning and Predicting
이런식의 HR관리를 위한 그래프는 개인의 프로젝트 이력관리 역할을 해서 이직 등과 같은 상황에서 이전 career path를 기반으로 적절한 방향을 찾을 수 있다(Linked In 같은 취업정보 공유 플랫폼에서도 활용할 수 있을 것 같다). 또한 조직의 팀 구성 과정에서도 도움이 될 수 있는데, 단순히 업무적 경험이나 기술 뿐만 아니라 동료 평가 점수 기반의 social layer를 추가하면 더욱 세부적인 정보를 얻을 수 있다.
지식그래프는 과거 프로젝트의 성과를 바탕으로 미래 프로젝트의 성공 가능성을 예측하는데도 활용할 수 있다. 예를 들어, 관리자의 능력이 부족하거나 구성원의 기술 수준이 낮으면 프로젝트의 실패 확률이 높아지고, 반대로 강한 리더쉽과 숙력된 팀원들이 모이면 성공 가능성이 높아진다. 패턴을 통해서 실패한 프로젝트를 찾을 수도 있고, GDP를 통해서 실패/성공을 예측하는 모델을 만들 수도 있다. 예시에서는 그래프 수치를 벡터로 변환한 뒤, Random Forest 회귀 모델을 사용해서 새로운 feature값을 예측하도록 하는 모델을 학습한다. 이를 통해 성과를 추적하거나 문제가 있는 구성원들을 파악해서 개선할 수 있으며, 장기적으로 조직 재설계에도 활용할 수 있다고 한다.
