많은 자연어 기반의 문서들은 비구조화 데이터로 존재한다. 이러한 문서를 프로그램적으로 활용하기 위해서는 CSV, JSON, XML과 같은 구조화된 형식으로 변환하는 과정이 필요하다. 이 작업은 주로 자연어 처리(Natural Language Processing, NLP) 기술을 통해 이루어진다.
비구조화 데이터를 활용하는 가장 기본적인 단계는 검색(search) 이다. 초기의 검색 엔진은 단순히 문서 집합에 대한 인덱스를 구축하고, 사용자가 입력한 키워드와 일치하는 항목을 찾아주는 방식이었다. 하지만 이런 방식은 자연어의 특성상 한계가 많았다. 예를 들어, 단어의 복수형(e.g. country, countries), 오탈자, 약어, 동음이의어, 두문자어 등의 다양한 표현 변화를 제대로 처리하지 못해 원하는 결과를 얻기 어려웠다.
이후 발전된 접근은 단순 키워드 매칭을 넘어, 검색 결과 순위화하는 알고리즘이 제안되었는데, 대표적으로 구글의 PageRank가 있다. PageRank는 문서 간의 연결(하이퍼링크)을 활용하여 결과의 중요도를 평가하는 방식이다. 즉, 단순히 키워드 등장 빈도뿐 아니라, 다른 관련 문서들로부터 얼마나 많이 참조되는지에 따라 검색 결과의 가치를 평가하는 것이다.
최근에는 키워드 기반 검색(e.g. wildcard search, fuzzy search, logical expression기반의 키워드 결함 등)과 함께, 지식그래프를 활용하는 방향으로 발전하고 있다. 개념 간의 관계를 구조화하여 표현함으로써, 단순한 키워드 매칭을 넘어 의미 기반의 검색을 수행하는 것이다. 이를 통해 검색 시스템은 동의어나 인접 개념, 도메인 관련 개념까지 이해하고 연결할 수 있으며, 단순 검색을 넘어 질의응답 기능까지 지원할 수 있게 되었다.
From Strings to Things: Annotating Documents with Entities
자연어로 표현된 문서는 엔티티와 관계를 인간의 방식으로 표현하는 방법이다. 그러나 인간의 표현은 굉장히 모호하고 맥락에 기반하기 때문에 이를 구조화하기 위해서는 고차원의 '추상화'가 필요하다.
첫 번째 단계는 NER(Named Entity Recognition)을 통한 'Text annotation'이다. 우선 NER, 즉 개체명인식은 개체의 이름(Class)를 파악하는 것을 의미한다. 예를 들어, 'The New York Times is a daily newspaper and its headquarters is on the west side of Midtown Manhattan in New York City'와 같은 문장이 있을 때, 'The New York Times'와 'New Your City'는 각각 Organization과 Location이라는 다른 타입으로 분류되어야 한다. 이러한 결과를 지식그래프 기반 검색 엔진에 명시적으로 반영하면, 단순히 텍스트 기반 검색을 했을 때와 달리, 정확한 의미를 기반으로 검색할 수 있다.
이제 HuggingFace와 Neo4j를 활용해서 문서에서 엔티티를 추출하고 지식그래프로 변환하는 실습을 파이썬을 활용해서 진행한다.
from transformers import pipeline
ner_pipe = pipeline("ner", aggregation_strategy="simple")
title = "Twitter chair Patrick Pichette joins graph data platform Neo4j board of directors."
fragment = """Pichette is currently a partner at Inovia Capital and is also currently chair of commerce platform Lightspeed. His
30 years of financial and operating expertise includes roles at Google, Sprint Canada and Bell Canada, with a focus on digital
transformation and hyper-growth. According to Pichette, “Neo4j’s graph technology offers a truly unique solution to solve some
of the world’s most complex challenges, with a clear focus on promoting transparency and positive social change.”"""
author = "Digital Nation Staff"
url = "https://www.itnews.com.au/digitalnation/news/twitter-chair-patrick-pichette-joins-graph-data-platform-neo4j-board-of-directors-572498"
entity_list = []
for entity in ner_pipe(title + fragment):
entity_list.append(entity)default 설정을 사용하면 bert-base-NER 모델을 사용하고, 영어 문장에서 적합한 모델이라고 한다. 만약 한글 텍스트를 사용할 경우 다른 모델을 사용하는게 적합할 것 같다. aggregation_strategy는 엔티티를 묶는 단위를 결정하는데, 'none'의 경우 토큰 간위 그대로 반환하고, 'simple'의 경우 같은 엔티티 타입이 연속되면 하나로 합친다. 예를 들어, 'Harry Potter'가 들어오면 'Harry'도 PER이고 'Potter'도 PER이므로 'Harry Potter'을 하나의 엔티티로 묶는 것이다. 이외에도 first, average, max 등의 파라미터가 있다고 한다.
아래는 entity_list의 출력값이다.
[{'entity_group': 'ORG',
'score': 0.99194723,
'word': 'Twitter',
'start': 0,
'end': 7},
{'entity_group': 'PER',
'score': 0.9966798,
'word': 'Patrick Pichette',
'start': 14,
'end': 30},
{'entity_group': 'ORG',
'score': 0.97817,
'word': 'Neo4j',
'start': 57,
'end': 62},
{'entity_group': 'PER',
'score': 0.9963177,
'word': 'Pichette',
'start': 82,
'end': 90},
{'entity_group': 'ORG',
'score': 0.99511474,
'word': 'Inovia Capital',
'start': 117,
'end': 131},
{'entity_group': 'ORG',
'score': 0.99450964,
'word': 'Lightspeed',
'start': 181,
'end': 191},
{'entity_group': 'ORG',
'score': 0.9993794,
'word': 'Google',
'start': 261,
'end': 267},
{'entity_group': 'ORG',
'score': 0.9991764,
'word': 'Sprint Canada',
'start': 269,
'end': 282},
{'entity_group': 'ORG',
'score': 0.9990806,
'word': 'Bell Canada',
'start': 287,
'end': 298},
{'entity_group': 'PER',
'score': 0.98403025,
'word': 'Pichette',
'start': 370,
'end': 378},
{'entity_group': 'ORG',
'score': 0.943916,
'word': 'Neo4j',
'start': 381,
'end': 386}]bert-base-NER 모델은 'LOC', 'ORG', 'PER', 'MISC'(기타) 네 가지 유형으로 엔티티 타입을 구분한다. score는 모델이 해당 엔터티라고 판단한 확률을 의미한다. 분석된 텍스트 안에서 해당 엔티티가 얼마나 중요한지를 나타낸다. 즉, 엔티티가 텍스트의 중심 주제라면 높은 점수가 부여된고, 단순히 언급ㄷ만 된것이라면 낮은 점수를 갖는다. start와 end는 해당 단어의 인덱스 위치를 의미한다.
# Neo4j DB 연결
from neo4j import GraphDatabase
driver = GraphDatabase.driver("bolt://localhost:7687",
auth=("neo4j", "password"))
# NER을 통해 entity_list 생성
for entity in ner_pipe(title + fragment):
entity_list.append(entity)
cypher_query ='''
MERGE (a:Article { url:$url}) ON CREATE SET a.title= $title, a.text= $frg
MERGE (p:Person { name: $author})
MERGE (a)-[:has_author]->(p)
WITH a UNWIND $entityList AS entity
MERGE (e:Entity { name: entity.word , type: entity.type })
MERGE (a)-[:references { salience: entity.score }]->(e)
'''
# 쿼리
with driver.session(database="neo4j") as session:
session.execute_write(
lambda tx: tx.run(cypher_query, url=url, author=author, title=title,
frg=fragment,
entityList=[
{
"word": x["word"],
"type": x["entity_group"],
"score": x["score"]
}
for x in entity_list
]
)
)
driver.close()추출한 엔티티를 Neo4j에 쿼리를 통해서 삽입해준다. 쿼리를 보면 해당 URL을 가진 Article 모드가 있으면 가져오고 없으면 새로 생성하는데, 새로 생성될 때만 title과 text 속성을 설정한다. 이후 저자 이름($author)을 가진 Person 노드를 생성하고 article 노드와 author 노드를 has_author라는 관계로 연결해준다. 아래 그래프에서 파란색 기사 노드와 보라색 저자 노드가 연결된 것을 볼 수 있다.
다음은 파이썬에서 전달한 entityList를 각 엔티티별로 분리하고, 각 엔티티의 name과 type 속성을 부여해준다. 이후 article노드와 엔티티 노드를 references 관계로 연결하고, 계산한 수치를 salience 속성을 통해서 표현해준다.
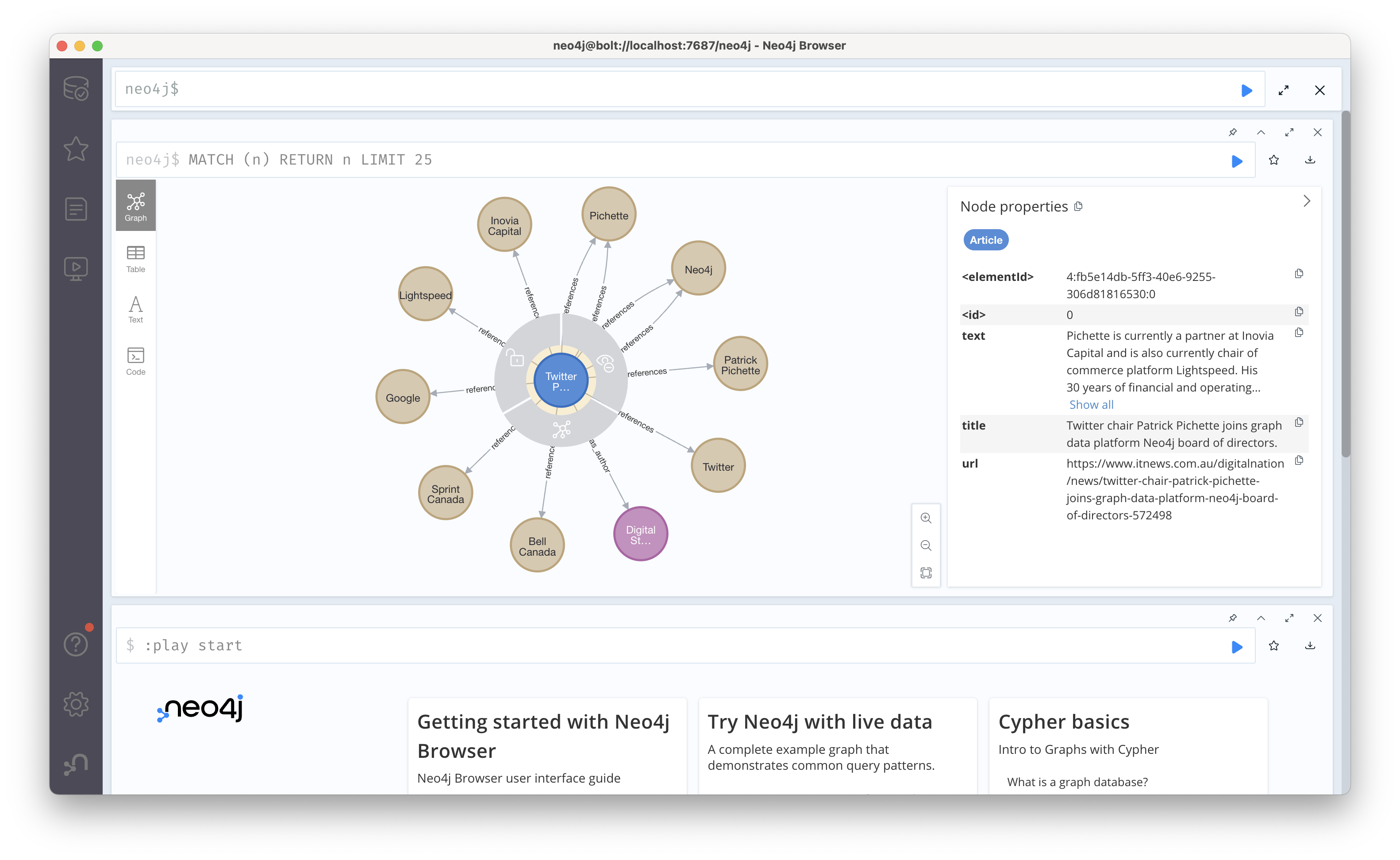
동일한 방법으로 예제의 두번째 article도 그래프에 넣어주면 아래와 같이 Neo4j로 연결된 두 그래프를 확인할 수 있다.
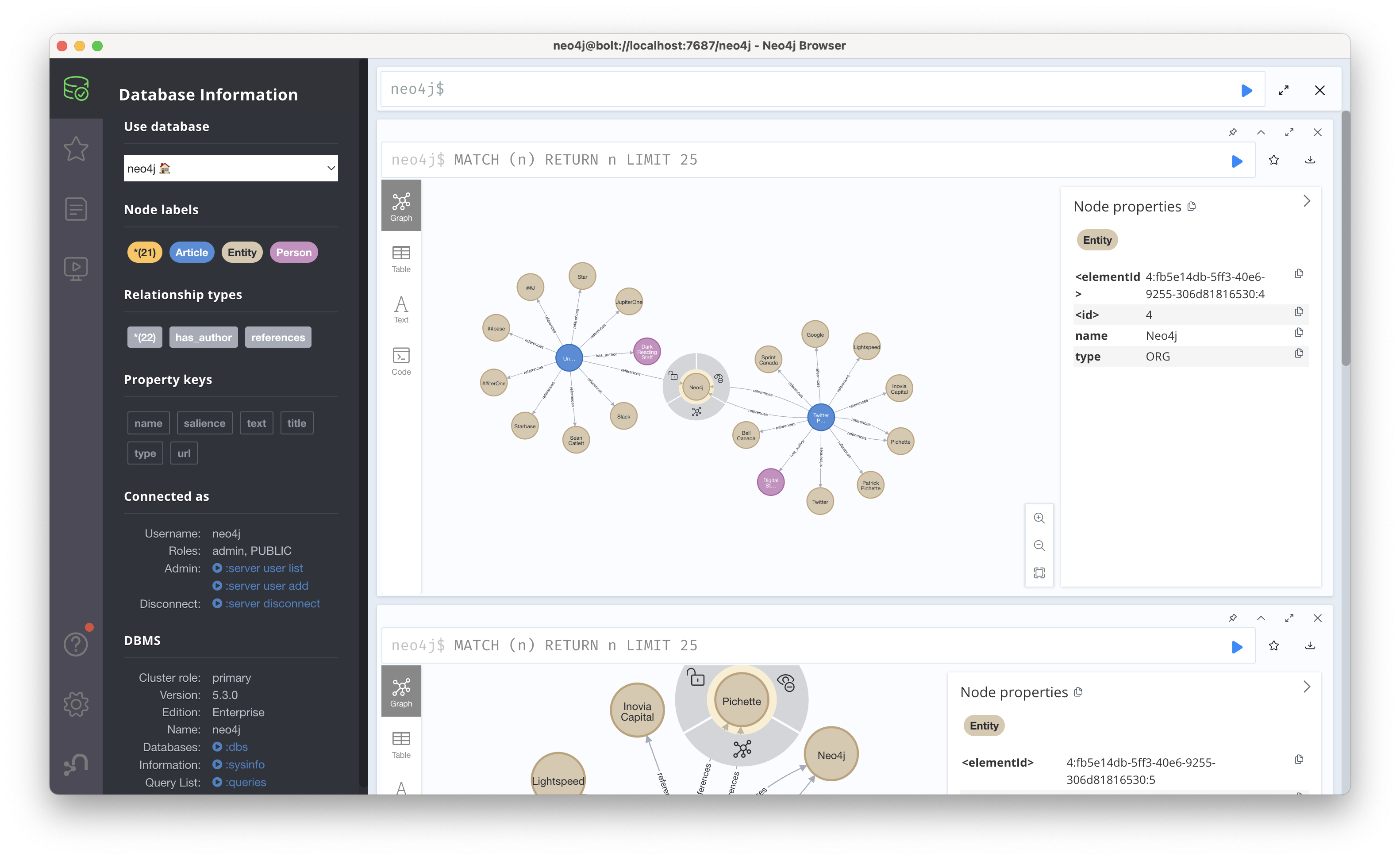
이제 이 문서를 기반으로 다음과 같은 쿼리들을 수행할 수 있다.
- 해당 url에 참조된 엔티티를 조회하는 쿼리
MATCH (a1:Article)-[:references]->(e:Entity) WHERE a1.url = 'https://www.itnews.com.au/digitalnation/news/twitter-chair-patrick-pichette-joins-graph-data-platform-neo4j-board-of-directors-572498' RETURN e.name AS entityName, e.type AS entityType - 특정 엔티티(Twitter)를 참조하는 기사를 조회하는 쿼리
MATCH (a:Article)-[:references]->(e:Entity) WHERE e.name = 'Twitter' AND e.type = 'ORG' RETURN a.url AS articleLink, a.title AS articleTitle - 엔티티의 월별 등장 빈도로 시계열 데이터를 생성하는 쿼리
지난 12개월 동안 특정 엔티티인 'Twitter'가 언급된 기사수를 월별로 집계하는 쿼리인데, 현재 데이터에는 published date 노드가 없으므로 쿼리된 값이 없는게 정상이다.MATCH (c:Entity { name: 'Twitter', type: 'ORG' }) WITH c, date() - duration("P1Y") AS startdate UNWIND range(0,11) AS increment MATCH (c)<-[:references]-(a:Article) WHERE startdate + duration("P"+ (increment - 1) +"M") < a.published < startdate + duration("P"+ increment +"M") RETURN startdate + duration("P"+ increment +"M") AS date, count(a)
UNWIND는 리스트의 값을 하나씩 가져와서 처리하는 기능을 하고 파이썬의for x in list와 유사함
Navigating the Connections: Document Similarity for Recommendations
위 예시를 통해 단순 단어 수준이 아닌 엔티티 수준에서 검색할 수 있는 그래프를 만들었다. 이제 이 그래프의 구조를 분석해서 문서 간의 유사성을 파악하는 방법을 알아보겠다.
콘텐츠 기반 추천 시스템은 아이템의 특성(feature)을 중심으로 추천을 진행한다. 이 접근 방식을 확장하면, 아이템은 문서가 되고, 특성은 문서에서 추출한 엔티티들이 되며, salience(여기서는 score)는 어느 특성이 더 중요하게 작용하는지 판단하는 요소가 된다.
예를 들어, '해리포터1권'과 '해리포터2권'이 있을 때 이 두 아이템은 유사한 특성을 가지고 있으므로 공유하는 엔티티가 노드가 많을 것이다. 따라서 1권을 구매한 소비자에게 자연스럽게 2권을 추천해줄 수 있는 것이다.
url1 = "https://www.itnews.com.au/digitalnation/news/twitter-chair-patrick-pichette-joins-graph-data-platform-neo4j-board-of-directors-572498"
url2 = "https://www.darkreading.com/dr-tech/jupiterone-unveils-starbase-for-graph-based-security"
cypher_query ='''
MATCH (a1:Article)-[:references]->(e:Entity)<-[:references]-(a2:Article)
WHERE a1.url = $url1 AND a2.url = $url2
RETURN e.name AS entityName, e.type AS entityType
'''
with driver.session(database="neo4j") as session:
results = session.execute_read(
lambda tx: tx.run(cypher_query, url1=url1, url2=url2).data()
)
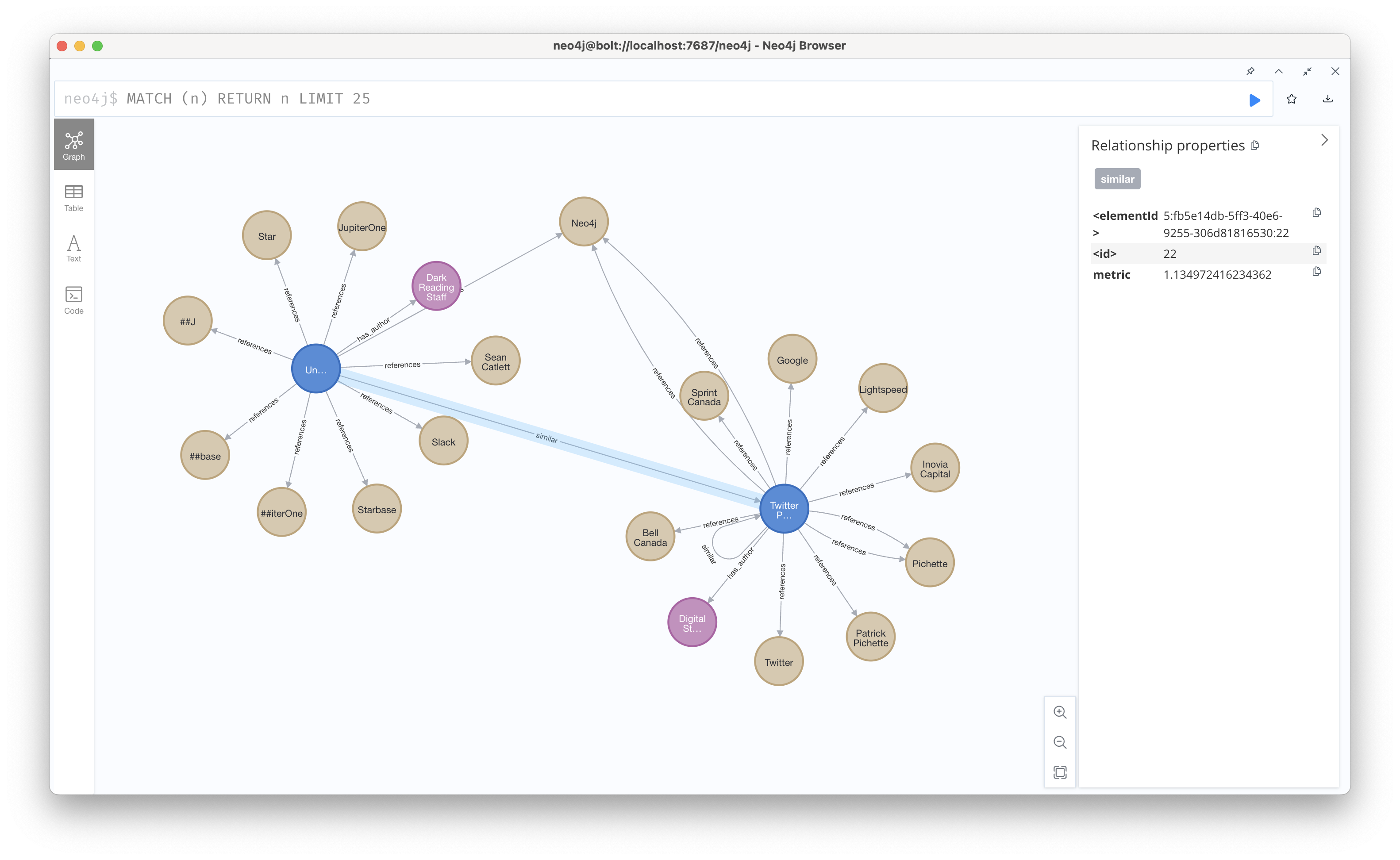
print(results)위 코드를 사용하면 해당 url을 갖는 두 article의 공통 엔티티를 찾을 수 있다. 출력값은 위 시각화에서 확인했듯 [{'entityName': 'Neo4j', 'entityType': 'ORG'}, {'entityName': 'Neo4j', 'entityType': 'ORG'}] 즉, Neo4j 노드가 된다.
이 특성들을 활용하면 '유사도 지표(similarity metric)'를 계산할 수 있다. 유사도 지표는 각 엔티티의 가중치의 합(weighted sum)으로 계산되는데, 예를 들어, 개별 문서가 5개의 feature들과 연결되어 있는데, 이때 관계에는 각각 가중치가 부여되어 더 중요한 특성과 그렇지 않은 특성이 구분되고 있다. 따라서 중복되는 엔티티를 통해 문서의 유사도를 파악할 때도 가중치를 활용하면 더욱 정교한 유사성을 확인할 수 있는 것이다.
cypher_query ='''
MATCH (a1:Article)-[r1:references]->(e:Entity)<-[r2:references]-(a2:Article)
WHERE a1.url = $url1 AND a2.url = $url2
RETURN sum(r1.salience * r2.salience) AS similarity_metric
'''
The Cold Start Problem
문서의 유사도는 '추천을 위한 기준점'이 존재한다는 전제를 갖고 있다. 위에서 진행한 예시에서 기준점은 이전에 읽은 기사가 되고, 이를 기반으로 그 다음에 읽을 기사를 추천해준 것이다. 그러나 현실에서는 기준점이 없는 cold start 상황이 존재한다. 예를 들어, 홈페이지를 처음 개설해서 보여주는 콘텐츠를 선정할 때가 해당한다.
이런 상황에서는 인기 있는 주제, 즉 트렌드는 보여주는게 합리적인 방법이 된다. 아래 쿼리는 최근 6개월 동안 가장 많이 언급된 개념을 찾는 것이다.
MATCH (c:Concept)<-[:refers_to]-(a:Article)
WHERE date() - duration("P6M") < a.datetime < date()
RETURN c.label, count(a) AS freq LIMIT 10또 다른 방법으로는 미리 그래츠 전체에 유사도 알고리즘에 기반한 유사도를 계산해둔 뒤, 사용자가 특정 주제나 기사를 클릭하는 순간 즉시 비슷한 것들을 추천해주는 방법도 있다.
Making the Annotation Semantic with an Organizing Principle
NER기반의 Text Annotation는 다음 두가지 한계를 갖는다.
- 개체 구분의 어려움: ‘United Kingdom’과 ‘UK’를 모두 LOC로 인식하지만 동일한 개체라는 건 확인 할 수 없음
- 개체 간 관계 표현의 어려움: ‘Wales’를 LOC로 인식하지만 ‘UK’의 PART_OF 라는 관계를 도메인 지식 기반으로 반영할 수 없음
이런 한계를 극복하기 위해 도메인별로 수립한 조직 원리(organizing principle)를 활용하여 Semantic KG를 구성할 수 있다. 이때 조직 원리는 도메인에 맞는 온톨로지, 개념 체계(concept scheme), 어휘 등을 채택한다는 의미이다. 예를 들어, n개의 문서에서 'United Kingdom', 'England', 'Wales', 'London' 등이 인식되고, 모두 LOC로 분류하는건 Text annotation까지의 단계라면, 조직원리를 활용해서는 아래와 같이 'England'와 'Wales'는 'United Kingdom'의 PART_OF이고, 'London'은 'England'에 LOCATED_IN되어 있으며, CAPITAL_OF로 연결된다는 추가 관계를 부여할 수 있다.

이와 같이 공유된 개념 스키마를 기반으로 개체를 매칭하는 걸 named-entity linking(= entity disambiguation)이라고 하고, 일반적으로 NER 작업과 함께 수행된다고 한다. NER을 사용하는 예제로 GCP(Google Cloud Platform)를 소개하는데, 앞서 다뤘던 HuggingFace보다 상세한 정보와 개체의 Wipedia URL을 메타데이터에 추가한다는 차이가 있다.
사용 방법은 우선 GCP에 접속해서 프로젝트를 생성하고, IAM 및 관리자> 서비스 계정> 서비스 계정 만들기 를 순서대로 실행하면 services.json 파일을 다운할 수 있다.
이후 라이브러리를 설치한 뒤, 아래 코드를 실행하면 NER이 수행된 결과를 얻을 수 있다.
from google.cloud import language_v1
client = language_v1.LanguageServiceClient.from_service_account_json
('services.json')
text = u"Twitter chair Patrick Pichette joins
graph data platform Neo4j board of directors"
document = language_v1.Document(
content=text, type_=language_v1.Document.Type.PLAIN_TEXT
)
response = client.analyze_entities(request={"document": document})
for entity in response.entities:
print(entity)결과를 보면, 세 개의 엔티티를 추출하고 각각 기본적인 type과 함께 상세한 메타데이터를 제공하는 것을 확인할 수 있다.

GCP API로 진행할 수도 있지만, Neo4J의 APOC에는 GCP Natural Language API를 호출할 수 있는 매서드가 포함되어 있고, neosemantics 라이브러르로 온톨로지(SKOS, OWL, RDFS 등) 기반 조직 원칙 부여할 수 있다.
LOAD CSV WITH HEADERS FROM 'file:///articles.csv' AS row
CREATE (a:Article { uri: row.uri})
SET a.title = row.title, a.body = row.body, a.datetime = datetime(row.date)우선 articles.csv 데이터를 임포트해야 하는데, 해당 데이터는 이 깃헙에서 다운받을 수 있다. 데이터는 url, body, title, date 컬럼과 32행으로 구성된다.
이후 neo4j에서 neosemantics 플러그인을 설치 후, SKOS/OWL/RDFS 파일을 기반으로 변환한다. 아래 코드를 실행하면, SKOS ttl 파일을 바로 가져와서 이를 기반으로 관계를 정의하는데handleVocabUris: ”IGNORE”는 URI를 노드 이름으로 두지 않고 내부로 처리한다는 의미이고, 모든 classLabel에 기본으로 skos:Concept 지정, 상-하위 관계를 broader라는 관계로 매핑한다고 한다.
CALL n10s.graphconfig.init({
handleVocabUris: "IGNORE",
classLabel: "Concept",
subClassOfRel: "broader"})
CALL n10s.skos.import.fetch(
"path-to-file-containing-organizing-principle",
"RDF/XML"
)이후 Cypher에서 APOC라이브러리를 활용해서 GCP Natural Language API를 호출하여 개체 추출 후 조직 원리와 연결한다. 이를 통해 (1) 개체를 모호성 없이 고유하게 식별할 수 있고 (2) 의미 기반으로 상호연결된 표현을 구축할 수 있으며 (3) 시멘틱 검색이 가능해진다. 예를 들어, ‘NoSQL dbms’를 검색하면 문서에 해당 단어가 없어도 Neo4j와 DB라는 동일 범주(혹은 skos:broader 관계) 에 있으므로 검색 가능해진다.
CALL apoc.periodic.iterate(
"MATCH (a:Article)
WHERE a.processed IS NULL
RETURN a",
"CALL apoc.nlp.gcp.entities.stream([item in $_batch | item.a], {
nodeProperty: 'body',
key: $key})
YIELD node, value
SET node.processed = true
WITH node, value
UNWIND value.entities AS entity
WITH entity, node
WHERE NOT (entity.metadata.wikipedia_url is null)
MATCH (c:Concept {altLabel: entity.metadata.wikipedia_url})
MERGE (node)-[rt:refers_to]->(c)
SET rt.salience = entity.salience",
{batchMode: "BATCH_SINGLE", batchSize: 10, params: {key: $key}})
YIELD batches, total, timeTaken, committedOperations
RETURN batches, total, timeTaken, committedOperations;이런 방식을 확장하면, 제품 카탈로그처럼 여러 차원에서 분류가 가능해서 하나의 문서나 엔티티가 여러 경로로 탐색될 수 있고 결과적으로 검색 결과의 품질이 향상된다. 즉, 단순 텍스트 검색이 아니라 의미 기반 검색을 통해 ‘things, not string’를 실현할 수 있다는 것이다.
활용할 수 있는 분야의 예시는 다음과 같다.
- 헬스 케어 분야: 퇴원요약서, 임상기록, 논문 등 비정형 텍스트 데이터 비중이 굉장히 높은데, semantic KG를 통해 환자 데이터를 고급검색(환자 정보를 통합적으로 볼 수 있도록)과 분석이 가능
- 뉴스 미디어 분야: 기사, 오디오/비디오 미디어의 스크립트를 활용해서 ‘다음에 볼 콘텐츠 추천’과 같은 개인화 서비스 구현이 가능하고, 비선형적(nonlinear; 원하는 부분만 검색해서 zoom-in 접근)방식으로 미디어를 소비할 수 있음
- NASA의 ‘lessons learn’시스템은 아폴로 달탐사때부터 수백만개의 문서, 보고서, 연구결과를 저장
- 2000년대 초반: 키워드 검색 시 2천만 문서 전체에서 검색하고 수천건의 결과가 나와서 사용성이 떨어짐
- 풍부한 메타데이터를 기반으로 주제를 중심으로 엔티티를 추출해서 연결함. 이를 통해 주제 간 상관관계, 잠재적 위험 예방 등 파악 가능
- 현재는 빠른 검색 속도, 관련성 높은 결과 제공을 통해 연구 개발 시간을 절약했고, 실제로 ‘Mission to Mars’계획에서 최소 1년, 200만 달러를 절약했다고 함