
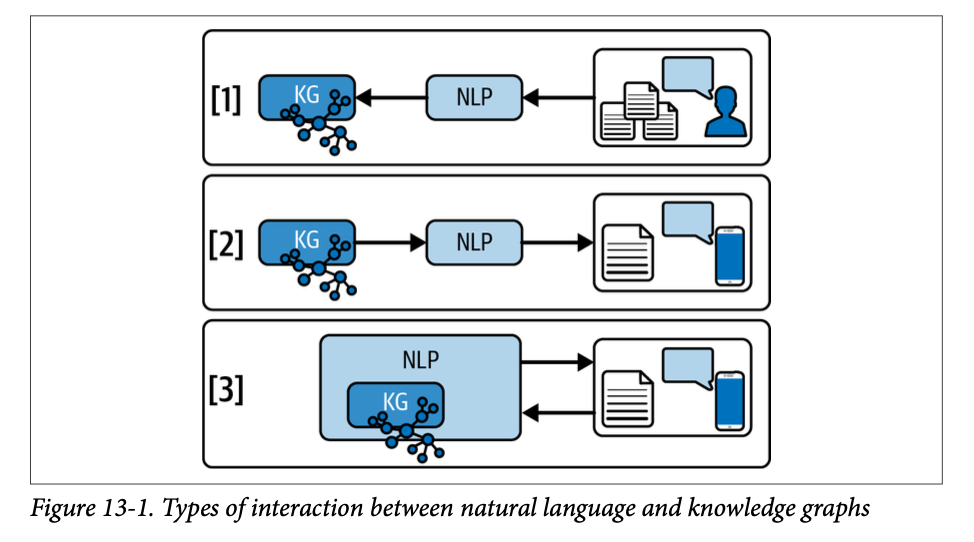
chapter12에서 다뤘던 NER은 NLP와 지식 그래프가 상호작용하는 방법 중 하나일 뿐이고, 크게 보면 세 가지 범주가 있다.
- 자연어 텍스트에서 개체, 사실, 지식을 추출해서 지식그래프에 채워넣는 방식(text -> KG)
- 지식그래프에 담긴 구조적 데이터를 자연어 문장으로 생성하는 방식(KG -> text)
- NLP가 더 잘 작동하도록 지식그래프가 구조화된 맥락을 제공하는 방식: 단어, 구, 문장의 의미를 더 잘 해석하기 위해 동의어, 상위어, 하위어 관계를 그래프에서 찾아서 단어의 중의성을 해소할 수 있음. 문장 속에서 개념 간의 관계와 의미적 구조를 파악할 수 있도록 도울 수 있음
이번 챕터에서는 이렇게 사실을 추출해서 지식그래프를 구축하는 방법과 자연어 질의를 구조화된 쿼리로 변환하고, 그 결과를 다시 자연어 문장으로 생성하는 방법, 그리고 Lexical KGs와 도메인 특화 엔티티 추출기를 통해서 특정 도메인에 특화된 엔티티 추출기를 구축하는 방법을 순서대로 다룬다.
1️⃣ QA: Natural Language as a Source of Facts for a KG
이 방법은 사실정보를 추출하는 원천 정보로 문서를 사용한다. 즉, 문서에서 추출한 사실들을 지식그래프 안에서 연결하여 도메인 질문에 직접 답변할 수 있게 만드는 것이다.
책에서는 Diffbot API를 사용해서 문장에서 엔티티를 추출하고 KG로 만드는 예시를 설명한다. Diffbot은 텍스트에서 entity-property-value의 triple 형태로 결과를 반환하고, 고유 식별자나 wikidata에서 가져온 정보들, salience, condidence, sentiment과 같은 추가 속성들을 제공한다.
# 결과값 예시
{"sentiment": -0.32881057,
"entities": [{"name": "Patrick Pichette", "confidence": 0.81,
"salience": 0.64345313, "sentiment": 0.0, "isCustom": ... }],
"facts": [ {
"humanReadable": "[Patrick Pichette] employee or member of [Innovia Capital]",
"entity": { "name": "Patrick Pichette",
"diffbotUri": "https://diffbot.com/entity/EYwbLa__MNVGtPMryqqCCEA",
"confidence": 0.9999268,
"allUris": ["http://www.wikidata.org/entity/Q3369779"],
"allTypes": [{"name": "person",
"diffbotUri": "https://diffbot.com/entity/E4aFoJie0MN6dcs_yDRFwXQ",
"dbpediaUri": "http://dbpedia.org/ontology/Person"}],
"isCustom": False, "entityIndex": 5},
"property": {"name": "employee or member of",
"diffbotUri": "https://docs.diffbot.com/ontology#Person.memberOf"},
"value": {"name": "Innovia Capital",
"confidence": 0.9989188, "allUris": [],
"allTypes": [{"name": "date",
"diffbotUri": "https://diffbot.com/entity/EGTSOJhZ0NnqIjbjgQ8pyLg"}],
"isCustom": False, "entityIndex": 0},
"confidence": 0.9498123,
"evidence": [{"passage": "Pichette is a partner at Inovia Capital",
"entityMentions": [{
"text": "Pichette", "beginOffset": 111, "endOffset": 113,
"isPronoun": False, "confidence": 0.9985091}],
"valueMentions": [{"text": "Innovia Capital",
"beginOffset": 119, "endOffset": 132,
"confidence": 0.9989188}]}]},
{"humanReadable": ... }] ,
...
}그러나 이 예시는 간단한 문장이나 적은 데이터에서는 잘 작동하지만, 추출관계가 다양해질 경우 불필요하게 많은 관계가 생길 수도 있다고 한다.
도메인에 따라서도 성능이 달라질 것 같고, 대규모 문서의 경우 이 API를 사용해서 하나의 KG를 구축하는 것이 가능할까?라는 의문이 있다.
2️⃣-1) Using Natural Language Query with a KG
풍부한 정보를 담은 지식그래프에서 더 많은 사용자가 가치 있는 정보를 얻으려면 자연어 기반 인터페이스가 필요 한다. 즉, 자연어로 질문해도 구조화된 쿼리(Cypher)로 변환해서 지식그래프의 답변을 얻을 수 있는 것을 의미한다.
예제는 Neo4j의 :play movies를 사용하고, spaCy 라이브러리를 사용해서 규칙 기반의 매칭방법을 사용한다.
# python3.10에서 실행했을 때 성공했고,
# 'en_core_web_sm' 부분에서 에러가 나면 `!python3.10 -m spacy download en_core_web_sm`을 실행해서 해결함
import spacy
from spacy.matcher import Matcher
nlp = spacy.load('en_core_web_sm')
matcher = Matcher(vocab=nlp.vocab)
q1_pattern = [{"LOWER":"who"}, {"LEMMA": {"IN": ["direct", "produce", "write", "review"]}, "POS": "VERB"}, {'IS_ASCII': True, 'OP': '+'}, {'IS_PUNCT': True, 'OP': '?'}]
matcher.add("q_1", patterns=[q1_pattern]) # (1)
doc = nlp("do you know who wrote a few good men?") # (2)
result = matcher(doc, as_spans=True) # (3)
print(result)
이 코드는 spaCy Matcher 패턴을 통해서 자연어 문장을 인식하는 방법을 설명한다. {"LOWER":"who"}는 대소문자 상관없이 'who'를 매칭하고, 동사로는 ["direct", "produce", "write", "review"] 등을 인식한다. {'IS_ASCII': True, 'OP': '+'}를 통해 영화 제목같이 여러 단어도 인식할 수 있도록 하고 {'IS_PUNCT': True, 'OP': '?'}의 의미는 질의어가 ?가 없이 평서문으로 작성되어도 인식할 수 있도록 하는 것이다.
이런 패턴을 기반으로 토큰화된 문장을 넣으면 '[who wrote a, who wrote a few, who wrote a few good, who wrote a few good men, who wrote a few good men?]'와 같은 결과를 얻는 것이다.
# map tokens to graph schema elements
q1_verb_to_rel = {"direct" : "DIRECTED", "produce" : "PRODUCED",
"write" : "WROTE", "review" : "REVIEWED"}
max_match = result[-1]
verb = max_match[1].lemma_ # (1)
title = ' '.join([tk.text for tk in max_match[2:] if tk.pos_ != 'PUNCT']) # (2)
query_as_cypher = "MATCH (p:Person)-[:{rel_type}]->(m:Movie) " \
"WHERE toLower(m.title) CONTAINS '{movie_title}' " \
"WITH collect(p.name) AS answer_as_list " \
"RETURN CASE WHEN size(answer_as_list) > 0 THEN " \
" substring(reduce" \
"(result='', x in answer_as_list | result + ', ' + x),2) " \
" ELSE \"I cannot answer your question about " \
"'{movie_title}' \" end AS answer " \
.format(rel_type=q1_verb_to_rel[verb], movie_title=title.lower()) # (3)
print(query_as_cypher)이후 자연어와 Cypher 쿼리에 매칭되는 관계를 표현한 간단한 dictionary를 사용해서 만들어둔 템플릿에 적용하면 최종적으로 다음과 같은 쿼리를 얻을 수 있다.
MATCH (p:Person)-[:WROTE]->(m:Movie)
WHERE toLower(m.title) CONTAINS 'a few good men'
WITH collect(p.name) AS answer_as_list
RETURN CASE WHEN size(answer_as_list) > 0 THEN
substring(reduce(result='', x in answer_as_list | result + ', ' + x),2)
ELSE "I cannot answer your question about 'a few good men' "
end AS answer이런 규칙 기반 방식은 자유도가 높지 않아서 실제 적용이 어렵지 않을까 생각했는데, 단순 탐색 쿼리나 스키마가 단순한 경우에는 오히려 정확도가 높아서 유용할 것 같다. 최근 LLM을 활용한 Text2Query와 관련된 연구가 많은데 추후 팔로업하려 한다.
2️⃣-2) Natural Language Generation from KGs
이제 쿼리 결과를 다시 사용자에게 자연어로 제공하는 방법에 대해서 다룬다. 이 역시 룰 기반으로 진행하는데 노드는 명사로, 관계는 동사형으로 인식하여 '주어-서술어-목적어'식의 문장으로 변환하는 방법이다.
MATCH (x)-[r]->(y)
RETURN x.name + " " + toLower(replace(type(r),"_"," ")) + " " + y.name AS sentence그러나 이 작업은 항상 관계가 사람이 사용하는 동사형과 유사한 형태로 표현된다는 것을 전제로 두고 이뤄진다. 따라서 관계 혹은 속성을 표현할 때 관계명/속성명 <-> 자연어 표현을 매핑해둘 필요도 있다고 설명한다. 또한 방향성에 따라서 다른 의미로 표현해야 하는 경우도 존재하므로, 각 관계에 대해 양방향 자연어 표현이 제공되어야 한다.
Annotating the KG's Organizing Principle to Drive Natural Language Generation
앞에서 제기된 문제들(노드를 어떻게 지칭할지, 스키마 이름이 자연스럽게 읽히지 않는 경우를 어떻게 해결할지, 관계를 한쪽 방향이 아닌 양쪽 방향으로 어떻게 표현할지)는 온톨로지를 활용하는 방식으로 풀 수 있다. 온톨로지와 자연어 생성기를 결합하면 지식 그래프 데이터를 고품질의 자연어로 자동 변환할 수 있는데, 이때 온톨로지는 단순한 스키마 정의를 넘어서 자연어 생성 엔진이 참고하는 일종의 설정 파일 역할을 한다. 온톨로지는 Neo4j 내부에 인스턴스 데이터와 함께 저장될 수도 있고, 외부 리포지토리에서 불러오거나 Fabric 환경에서 별도 그래프로 관리될 수도 있다. 이를 표현하는 방법으로는 W3C 표준인 RDFS나 OWL을 사용할 수 있으며, Neo4j에서는 neosemantics 플러그인을 이용해 가져오거나 직접 노드와 관계 형태로 정의할 수도 있다. 온톨로지의 핵심 목적은 각 노드 타입을 어떻게 지칭할지와 관계를 어떤 문장 구조로 설명할지를 선언적으로 정의하는 것이다. 예를 들어, 영화 데이터베이스에서는 Person 타입의 노드는 name 속성으로, Movie 타입의 노드는 title 속성으로 지칭하도록 정할 수 있다. 이렇게 정의된 온톨로지를 활용하면 지식 그래프를 일반적인 스키마 요소 이름에 종속되지 않고, 보다 자연스럽고 사람 친화적인 언어로 설명할 수 있게 된다.
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix talk: <http://www.neo4j.org/2022/07/talkable#> .
@prefix mv: <http://www.neo4j.org/sch/movies#> .
mv:ACTED_IN rdf:type owl:ObjectProperty ;
rdfs:domain mv:Person ;
rdfs:range mv:Movie ;
talk:direct "acted in"@default ,
"is in the cast of"@long ,
"worked in"@short ;
talk:inverse "has $o in it"@default ,
"includes"@short ,
"includes $o in its cast"@long ;
rdfs:label "ACTED_IN" .
mv:WROTE rdf:type owl:ObjectProperty ;
rdfs:domain mv:Person ;
rdfs:range mv:Movie ;
talk:direct "is the author of"@default ,
"wrote"@short ,
" wrote the script of"@long ;
talk:inverse "is authored by"@default ,
"is written by"@long ,
"is by"@short ;
rdfs:label "WROTE" .위와 같이 rdfs의 속성들을 사용해서 rdfs:label을 'ACTED_IN'으로 설정하고, 이 값이 domain, range 그리고 발생할 수 있는 다른 표현들(방향성에 따라 수동, 능동형식이나 짧게 표현하는 경우 등)을 정의한다.
그래프 자동 구축 관점에서 property graph가 rdf 그래프보다 강점을 갖는다고 생각했는데, 다시 자연어로 변환하는 과정에서는 결국 표준 어휘를 사용하고 strict한 스키마를 주는 rdf그래프 식으로 가까워진다는 점이 아이러니하면서도 흥미로웠다. 물론 여전히 표준을 따르지 않아도 표현이 가능하며, 노드와 관계가 모두 속성을 갖는다는 차이점이 존재한다.
3️⃣ Working with Lexical Databases
마지막은 WordNet과 같은 어휘 데이터베이스를 사용해서 단어의 표현은 더욱 세부적으로 이해할 수 있도록 하는 방법이다. WordNet은 명사, 동사, 형용사, 부사를 동의어 집합(synset)으로 묶어서 표현하며 개념적, 의미적 관계와 어휘적 관계로 연결되어 있다. 또한 RDF 형식으로 제공되어서 Neo4j에 바로 임포트해서 사용할 수 있다.
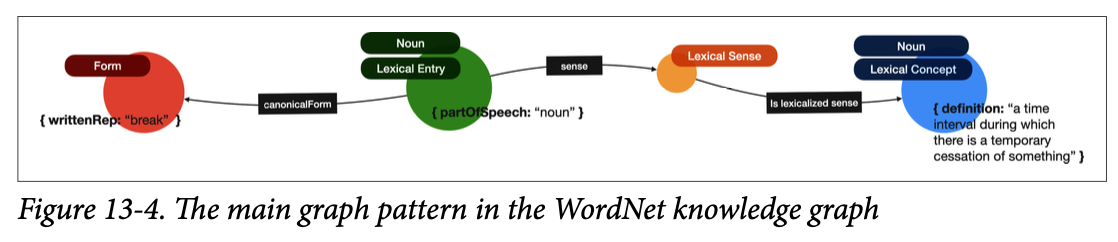
우선 WordNet의 기본 구조는 위와 같이 Form (형태) → Lexical Entry (어휘 항목) → Lexical Sense (어휘 의미) → Lexical Concept (개념)로 구성된다. 예를 들어, 'clear'라는 단어의 모든 의미를 찾는 쿼리를 실행하면, clear는 명사, 동사, 형용사, 부사로 모두 쓰일 수 있기 때문에 여러 결과가 도출된다.
MATCH (lemma:Form)<-[:canonicalForm]-(le:LexicalEntry)
-[:sense]->()-[:isLexicalizedSenseOf]->(concept)
WHERE lemma.writtenRep = "clear"
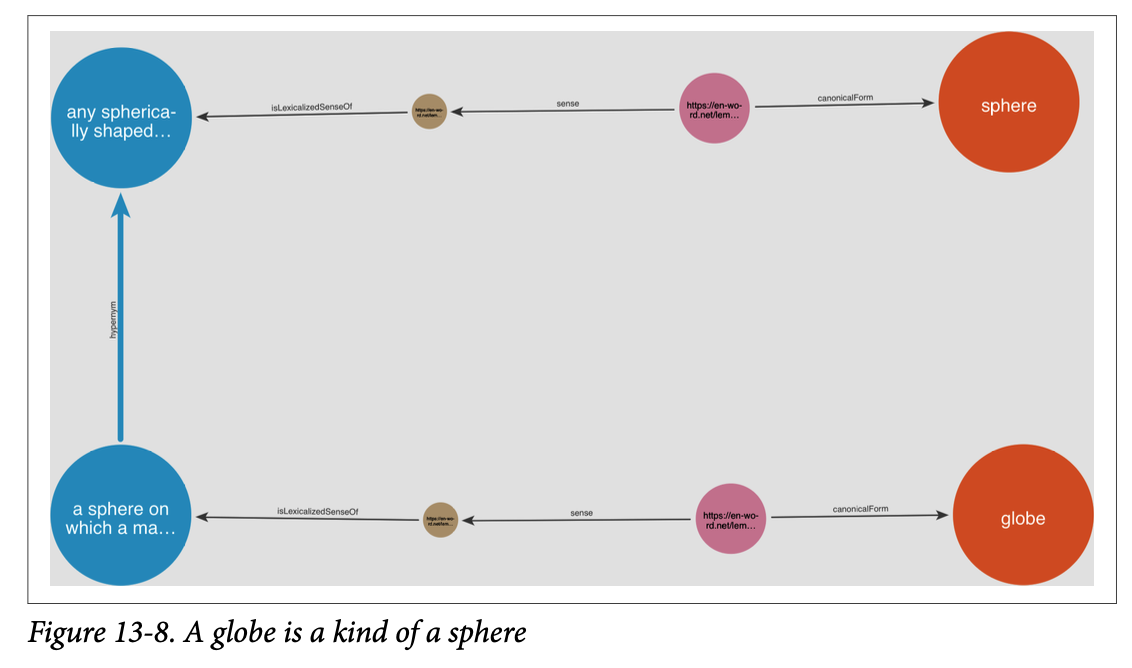
RETURN le.partOfSpeech AS PoS, concept.definition AS definition또한 개념간의 다양한 관계 표현을 통해 상/하위어, 부분-전체 관계를 파악할 수 있는데, 아래와 같이 globe는 sphere의 하위 개념(더 구체적인 위미)를 갖는 것을 파악하여 의미 유사도를 정의할 수도 있다.
Graph-Based Semantic Similarity
그래프에서 의미적 유사도를 계산할 때 가장 많이 사용하는 세 가지 기법에 대해서 소개한다.
책에서 제시하는 Cypher 쿼리와 NLTK 코드의 실습은 다루지 않았다. 버전 문제 등으로 그대로 실행하면 에러가 있었고 살짝씩 수정이 필요한 것 같긴 하다.
Path Similarity
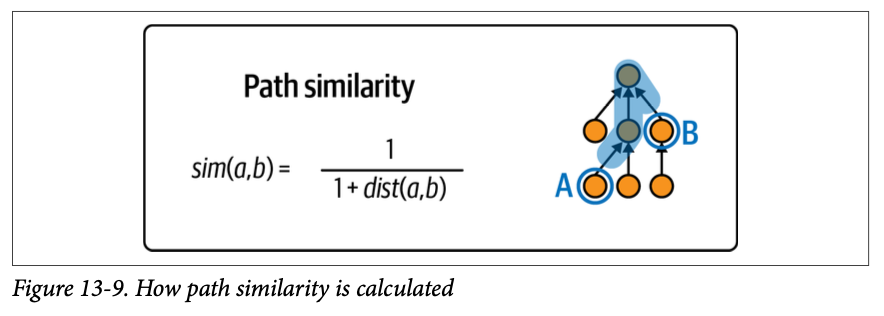
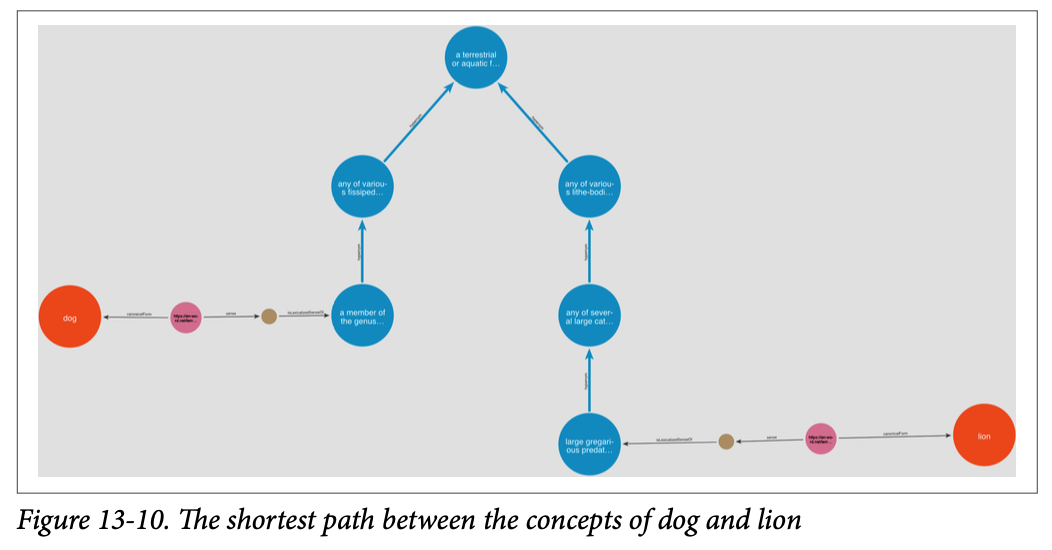
거리 기반 유사도는 두 어휘의 개념이 텍소노미에서 얼마나 가까이 연결되어 있는지를 기반으로 유사도를 계산한다. 예를 들어, dog과 lion은 아래와 같이 개념적으로 표현되며, 최단 거리가 5로 계산된다. 이와 같은 계산은 Cypher를 통해서도 할 수 있고, NLTK 라이브러리도 사용할 수 있다.
Leacock-Chodorow Similarity
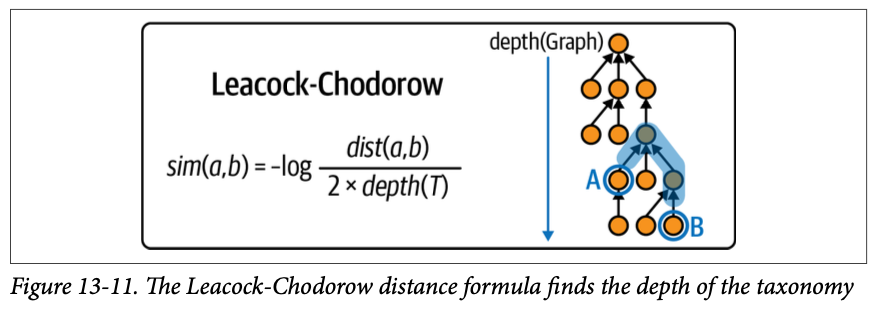
Leacock-Chodorow 유사도는 단순히 최단 경로 길이만 보지 않고 taxonomy의 깊이를 고려한다. 즉, 루트에서 특정 개념까지 가장 긴 경로의 길이인 깊이를 통해 깊은 계층에서 일치하는 단어일수록 유사도를 더 높게 평가한다.
Wu and Palmer Similarity
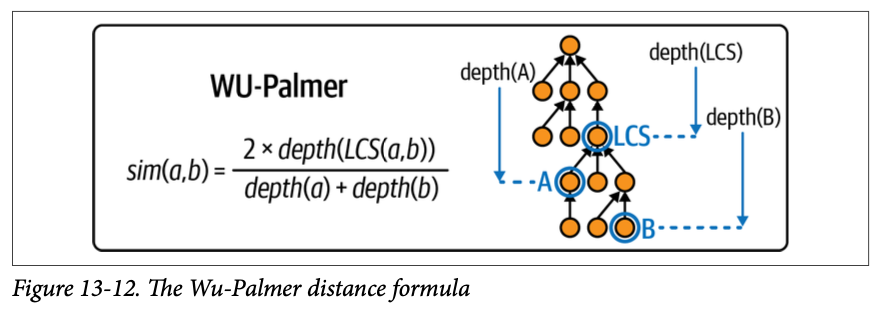
Wu and Palmer 유사도는 Least Common Subsumer(최소 공통 조상)와 깊이를 활용해 계산한다.
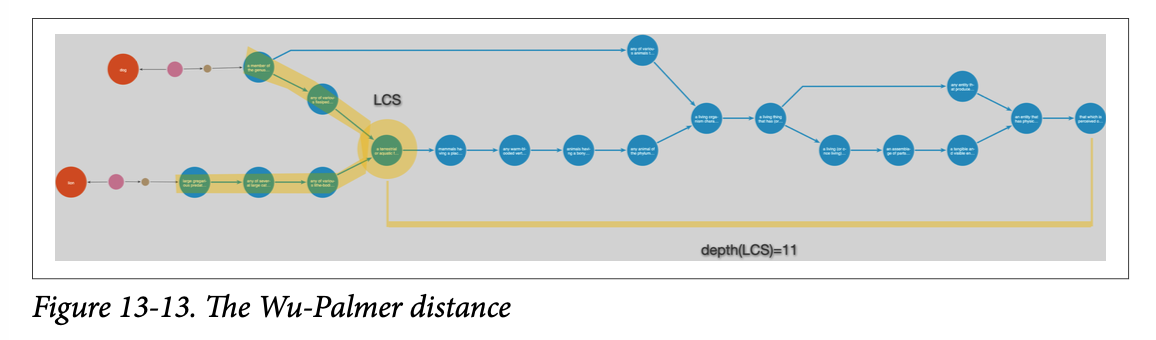
예를 들어, dog와 lion은 mammal이자 animal이므로, 최소 공통 조상은 mammal이라고 볼 수 있다. 이때 mammal이 루트에서부터 깊이가 깊은 경우 보다 세부 범주에서 유사도를 고려했으므로 유사도가 높게 측정된다.
반면, dog와 car는 최소 공통 조상이 entity(개체)로 정의될 경우 일반적 유사성에 의해 유사도 수치는 낮게 계산된다.
