
- Essential GraphRAG: https://neo4j.com/essential-graphrag/
- GitHub: https://github.com/tomasonjo/kg-rag
새로운 스터디를 시작합니다. 이번 교안은 Neo4j에서 발생한 실습서를 활용하고, LLM, RAG 그리고 GraphRAG(MS의 Graph RAG가 아님)까지의 개념적인 내용과 실제 사용법을 다룹니다. 깃헙에 실습 코드도 전부 제공하고 있어서 보다 practical한 스터디가 될 것 같습니다.
.
.
.
Introduction of LLMs
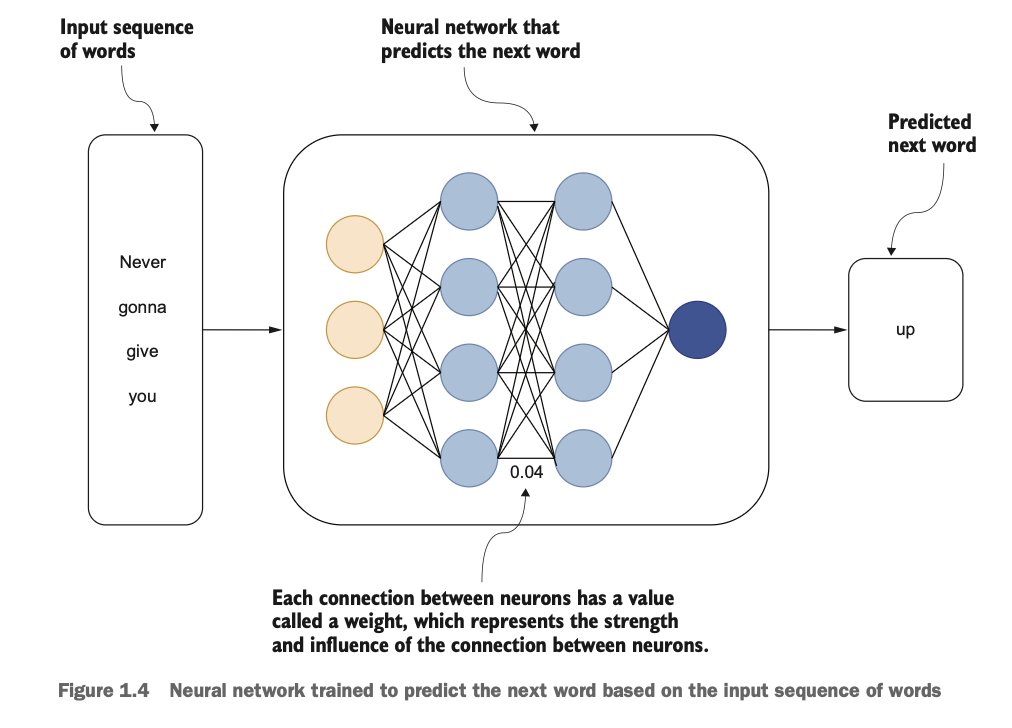
대화 기반(conversational) LLM은 Transformer 구조를 기반으로, 대규모 텍스트 데이터로 다음에 나올 단어를 예측하도록 학습된 모델이다. LLM은 문장을 자동 완성하는 기능 뿐만이라 질의문의 지시사항에 따라 다양하고 복잡한 답변(haiku와 같은 문장까지도)을 생성할 수 있다.
한편, LLM은 특정 정보를 저장하거나 기억한 뒤 답변을 하는 것이 아니라, 학습된 정보를 신경망 기반으로 수학적 확률값을 계산하여 텍스트를 생성하는 방식이다. 따라서 hallucination(환각)이 포함된 답변 생성은 필연적으로 발생할 수 있다.
Limitations of LLMs
1️⃣ Knowledge Cutoff problem
대표적인 LLM의 한계점은 학습 데이터에 포함되지 않은 정보에 대해서 알 수 없다는 것이다. 만약 2023년까지의 정보로 학습된 모델에 2024년에 발생한 이벤트를 묻는다면, 이에 대한 답변은 얻을 수 없다(최근 ChatGPT는 Search 기능을 포함하고 있어서 대응이 가능하지만, 기본적인 LLM의 특성을 말하는 것이다).
2️⃣ Outdated Information
유사하게, LLM은 오래전 정보를 기반으로 답변을 하게 된다. 예를 들어, 회사의 대표나 대통령이 바뀐 정보에 대해서 LLM이 새롭게 학습하지 못한다면, 과거의 outdated 정보를 제공할 수 밖에 없다는 의미이다.
3️⃣ Pure hallucination
hallucination은 그럴듯해보이는 답변이지만 실제로는 잘못된 정보를 내포하고 있는 경우를 의미한다. 특히 URL이나 학술적 참고문헌, 위키데이터 ID와 같은 레퍼런스를 제공할 때 오류가 포함될 가능성이 높다고 한다. hallucination이 발생하는 이유는 위에서도 언급했듯, LLM은 확률적으로 다음 토큰을 예측하는 모델이며, 추론 엔진이 아니기 때문이다.
4️⃣ Lack of Private Information
LLM은 학습데이터에 포함된 범위에 한해서만 답변을 할 수 있다. 따라서 학습 과정에서 포함되지 않았을 가능성이 높은 개인적인 정보(회사 내부의 자료나 일반적인 도메인 데이터가 아닌 경우)는 제대로 답변하지 못할 수 있다.
위 네 가지 이외에도 답변의 편향성, 위험성(악의적인 목적인 사용에 취약함) 맥락이나 뉘앙스를 부정확하게 이해하는 것, 일관되지 않은 답변 생성 등의 한계를 갖는다.
Overcoming the limtations of LLMs
1️⃣ Supervised finetuning
LLM의 한계를 극복할 수 있는 가장 기본적인 방법은 추가 학습을 진행하는 것이다. 우선, LLM의 학습은 다음과 같은 과정으로 진행된다.
- Pretraining: 1조 토큰 이상의 대규모의 텍스트를 기반으로 다음 단어를 예측하도록 하는 기본적인 학습 단계를 의미한다. 이 과정은 수천개의 GPU와 몇 개월의 학습 시간이 필요하다.
- Supervised finetuning: 챗봇과 같이 대화형으로 활용하기 위해 QA 형식의 데이터셋으로 미세조정하는 단계이다. 사전학습 단계보다는 적은 양의 데이터가 요구되며, 작은 LLM의 경우 단일 랩탑으로도 학습이 가능하다.
- Reward modeling: 어떤 답변이 좋고 나쁜지 보상을 통해서 구분할 수 있도록 하는 학습 과정이다. 더 큰 보상을 얻은 답변을 기준으로 답변의 품질을 향상시키게 된다.
- Reinforcement learning: 생성한 답변을 유저 혹은 가상 환경에서 피드백을 받아서 강화하는 학습 방법이다.
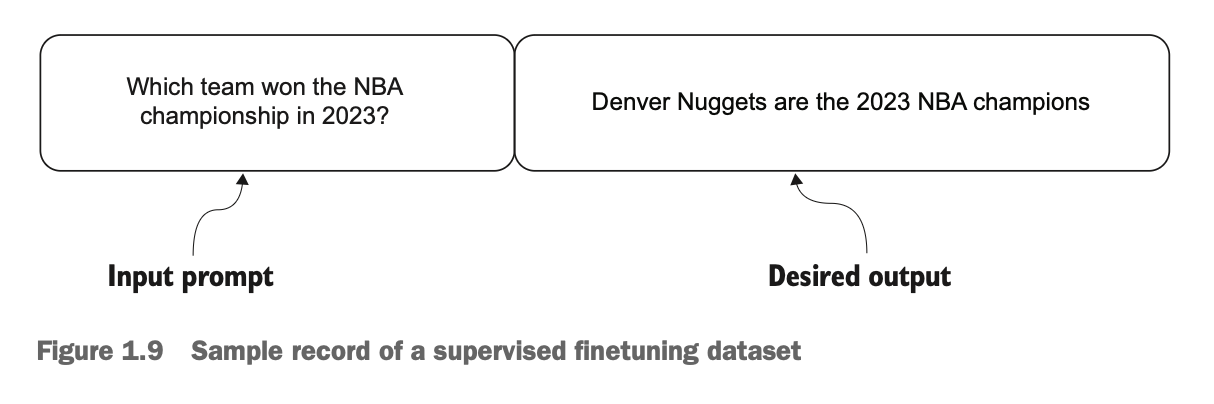
pretraining 방법은 많은 자원이 소요되는 만큼, LLM의 한계점을 극복하는 방법으로 위 예시와 같이 구체적인 질의에 대한 답변을 학습하는 finetuning이 많이 강조되고 있다. 그러나 이 방법은 LLM의 전반적인 지식을 향상시키지만, 현재 기술 발전 단계에서는 finetuning한 실제 운영 환경에 배포하는데는 어려움이 있다고 한다.
2️⃣ Retrieval-Augmented Generation
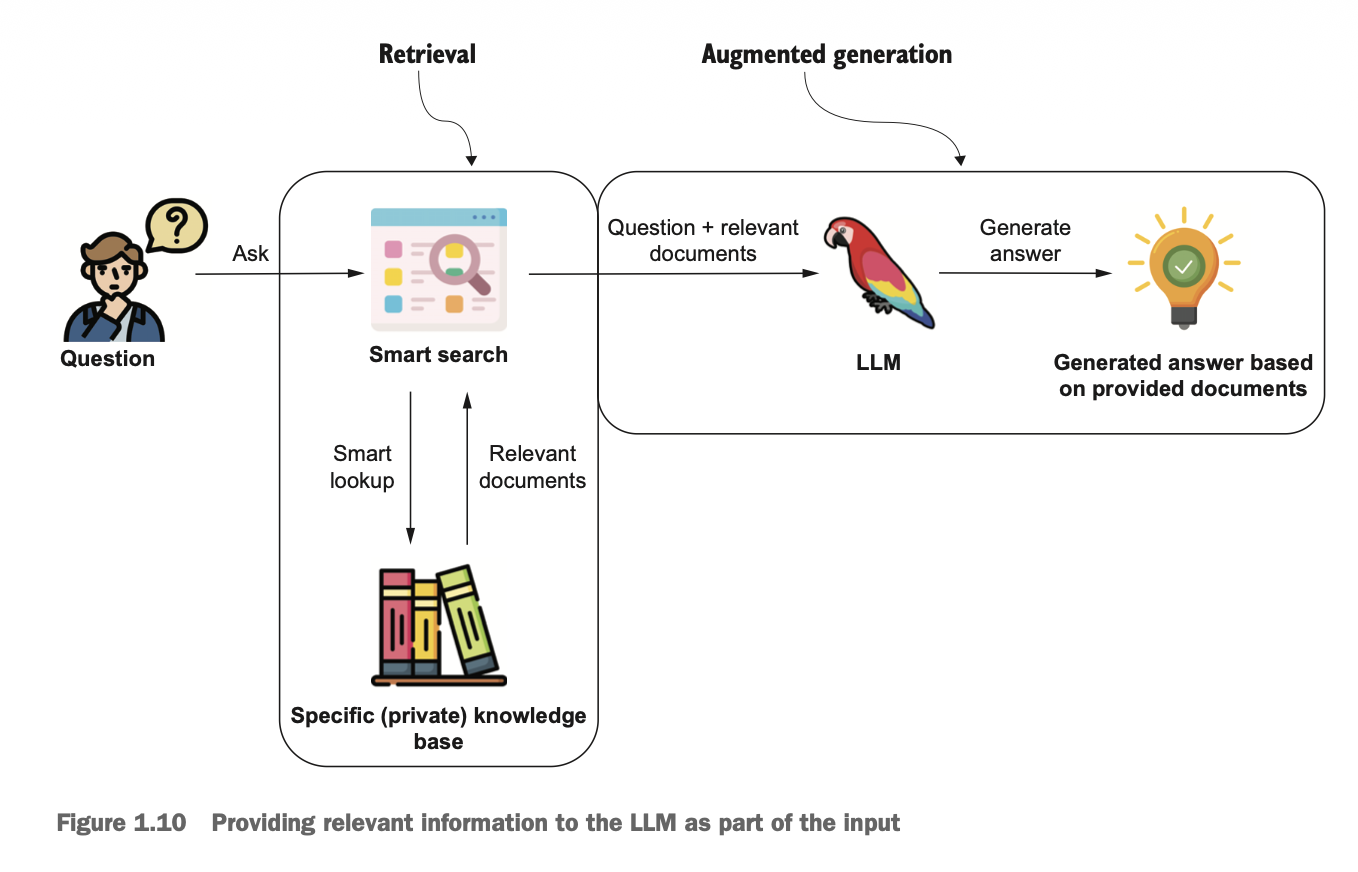
RAG는 LLM과 외부 지식베이스의 정보를 결합해서 더 정확하고 최신 답변을 제공할 수 있도록 하는 방법이다. RAG는 Retrieval(검색)과 Augmented Generation(증강 생성) 단계로 구성된다. 검색 단계는 질의를 기반으로 관련있는 정보는 외부 지식베이스나 데이터베이스에서 검색한다. 증강 생성 단계는 이러한 정보와 사용자의 질문을 다시 LLM에 넣어서 답변을 생성하도록 하는 파트를 의미한다. LLM은 자연어를 이해하고 지시에 따른 답변을 자연어로 생성하는데 강점을 갖고 있기 때문에, 아래와 같이 일정한 템플릿을 기반으로 지시를 하면 환각 현상이 줄어든 정확한 답변을 생성하는데 효과적이다.
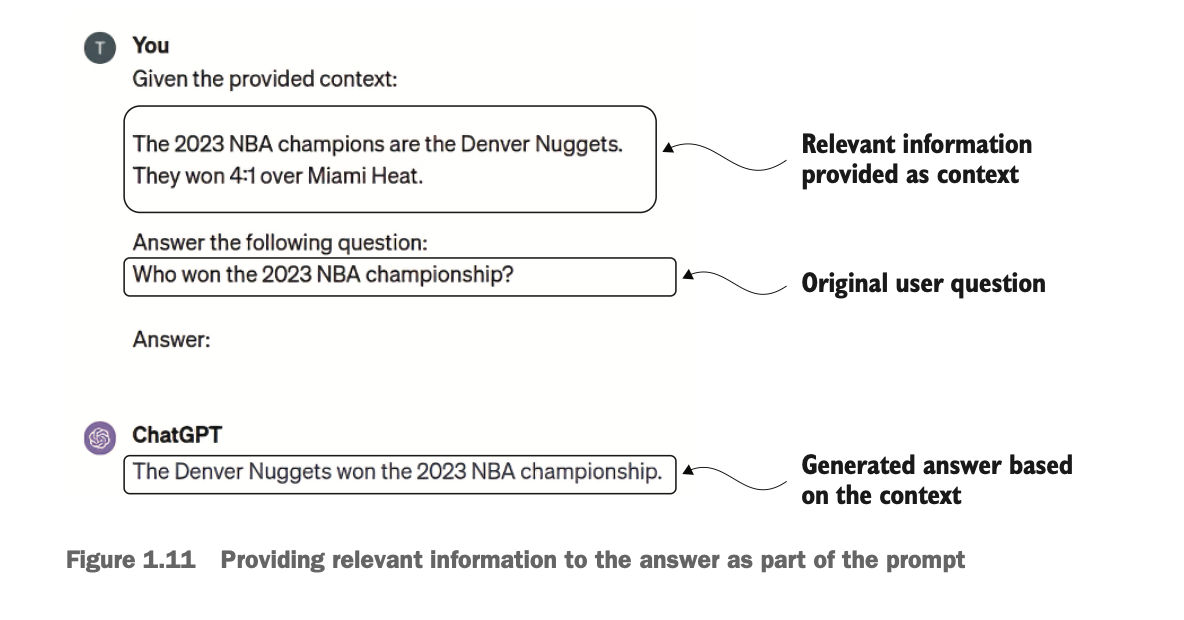
RAG는 간단한 구조로도 LLM 답변 성능을 쉽게 향상시킨다는 점에서 강력한 기법으로 평가되며, 최근에는 ChatGPT와 같은 챗봇 서비스에 기본적으로 Web Search와 같은 RAG 기반 답변 모드를 지원한다.
Knowledge graphs as the data storage for RAG applications
RAG 시스템을 적용할 때에는 어떤 외부 지식베이스나 데이터베이스를 사용할 지 결정해야 하며, 지식그래프와 그래프 데이터베이스도 좋은 선택지가 될 수 있다. 지식그래프는 개념, 엔티티, 관계를 노드와 간선을 통해서 구조적으로 표현하는 방식이며, 아래와 같은 형태를 띈다.
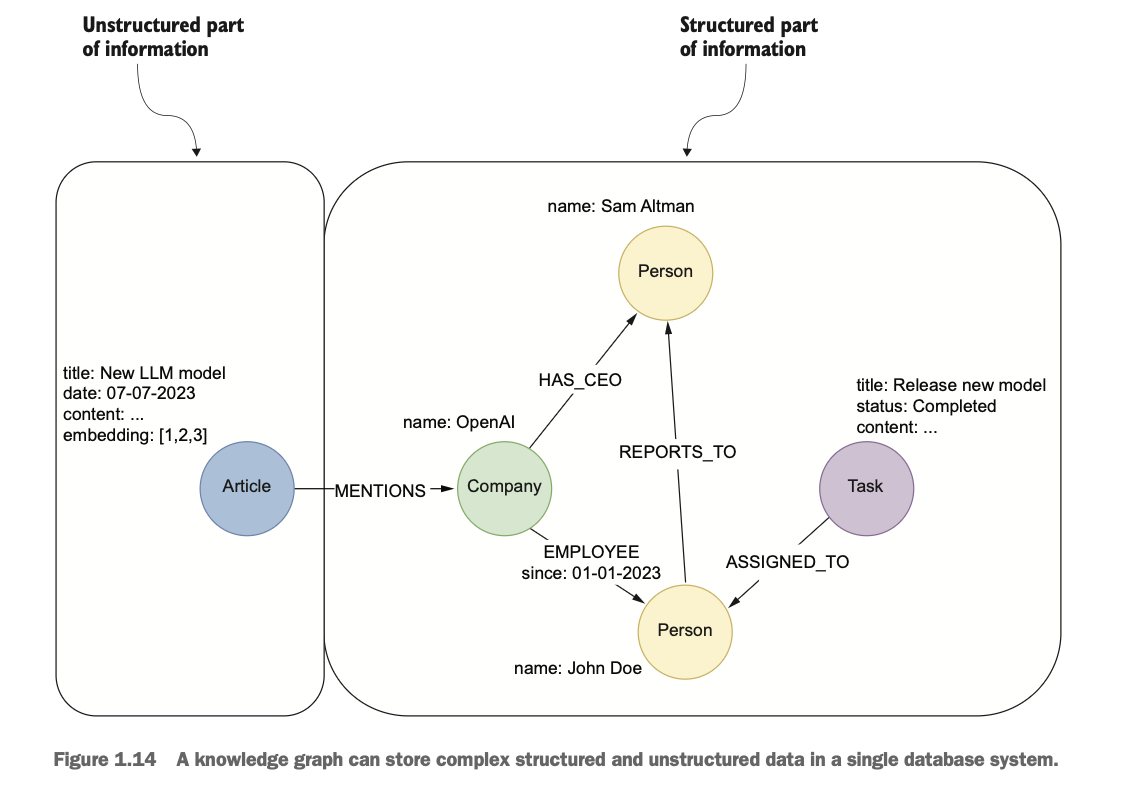
우측 부분처럼, 정보를 구조적으로 표현한 경우 'Who is the CEO of OpenAI?'와 같은 질문에 대해서 정확한 쿼리 결과를 기반으로 답변을 생성할 수 있다. 반면, 좌측 부분처럼 비구조적인 정보들은 'How is this article related to OpenAI employees?'와 같은 질의에 대해 더욱 풍부한 맥락적 정보를 통해 데이터의 깊이와 뉘앙스를 더해주지만, 'How many tasks are completed within a company?'와 같이 수치적 답변을 할 때는 벡터 기반의 확률적 답변보다 쿼리를 통한 답변이 계산 비용이나 정확성 측면에서 더욱 이점을 갖는다는 특징이 있다.
결론적으로, 지식그래프는 정형데이터와 비정형 데이터를 동일한 프레임워크 내에서 통합함으로 광범위한 질문에 효율적이고 정확하게 답변할 수 있다. 또한 두 관계를 명시적으로 연결해서 정형화된 결과를 글의 단락과 연결하는 등의 고급 검색 전략도 가능하게 한다.
