
스터디 책: Building Knowledge Graphs
chapter4에서는 neo4j에 데이터를 업로드하는 세가지 방법을 소개하고 있다. 각 방법마다 장단점이 있으므로 진행하고자 하는 프로젝트, 데이터의 특성에 맞게 선택하면 된다고 한다.
1️⃣ Data Importer 활용
Data Importer는 neo4j에서 제공하는 GUI 기반 데이터 임포트 서비스이다. 시각적으로 도메인 모델을 그리고 CSV 데이터를 매핑할 수 있도록 해서 초보자들에게 적합하고, 이외에도 모델 데이터 흐름을 시각화하고 싶거나 디버깅 용으로 사용할 수 있다. neo4j aura에서는 Import 탭에서 바로 사용할 수 있고, 위에 첨부한 링크로 들어가면 아래와 같은 화면이 나온다.
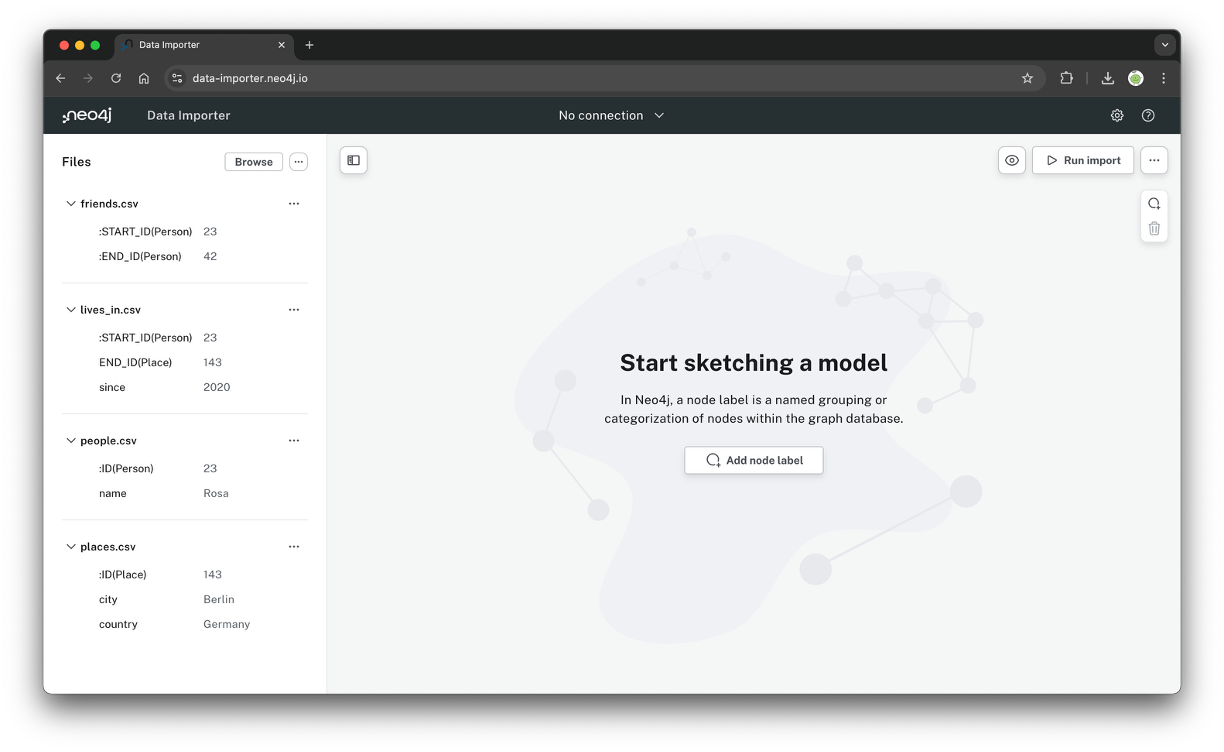
좌측에 csv, tsv를 올릴 수 있는 화면이 나온다. 교안에 나온 것과 동일하게 4개의 데이터를 임포트 해줬다.

교안에서는 csv 파일들을 제공하지 않아서 그냥 직접 만들어줬다. :ID 라는 prefix가 붙은 컬럼들은 개별 엔티티들의 ID값이 된다. 현재는 데이터 양이 많지 않아서 name, place값이 유니크하지만, 데이터양이 많은 경우는 유니크한 ID를 기준으로 사용해야 하므로 이런 컬럼을 추가해줬다.
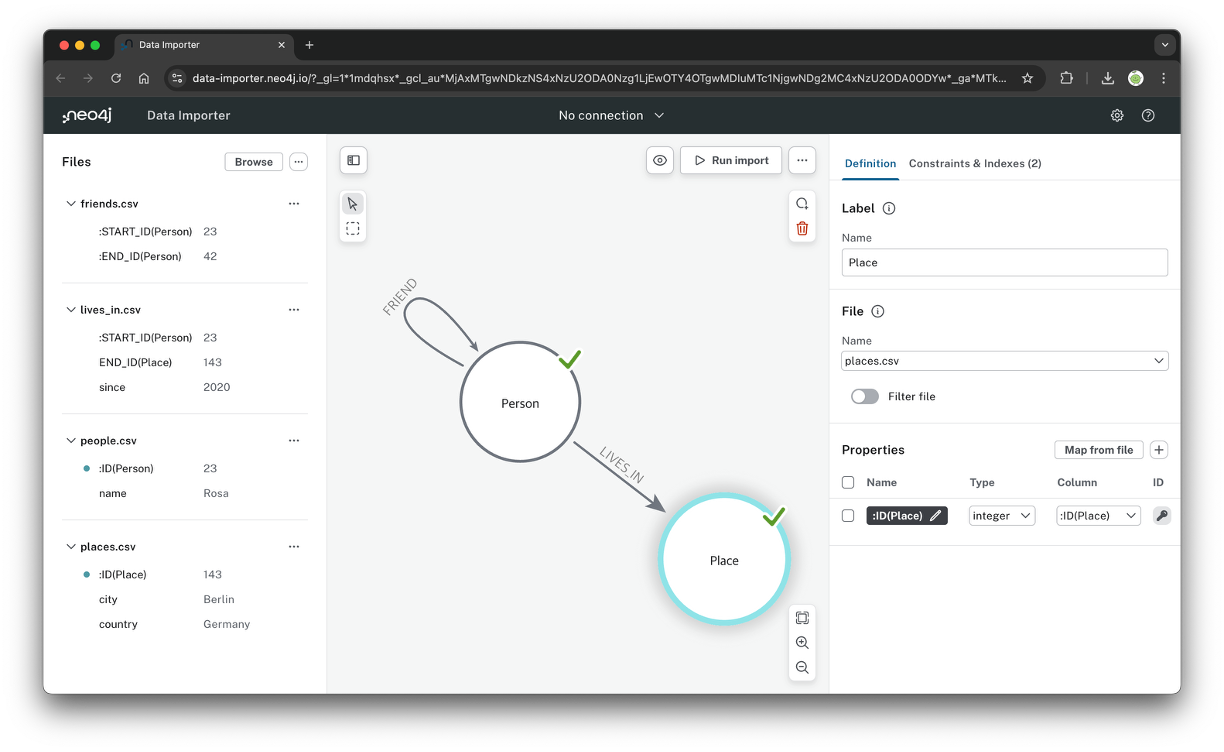
각 노드와 관계를 이렇게 시각적으로 표현해주었다. 사용방법은 마우스로 클릭 몇번만 하면 돼서 쉽게 따라할 수 있고, 해당하는 컬럼 매칭은 우측 패널에서 선택하면 된다.
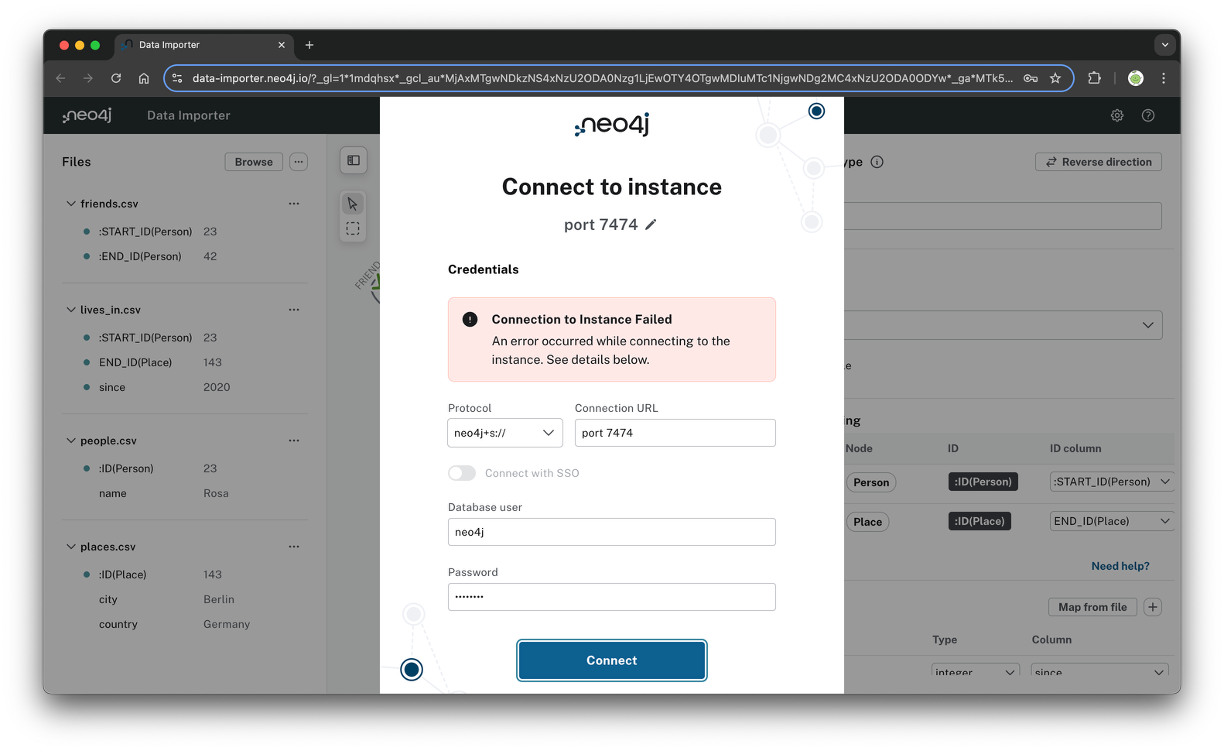
원래 인스턴스에 이렇게 연결하주면 되는것 같은데, 무슨 이유인지 localhost 연결이 잘 안됐다. 이 방법은 많이 안쓸거 같은니 일단 넘어간다.
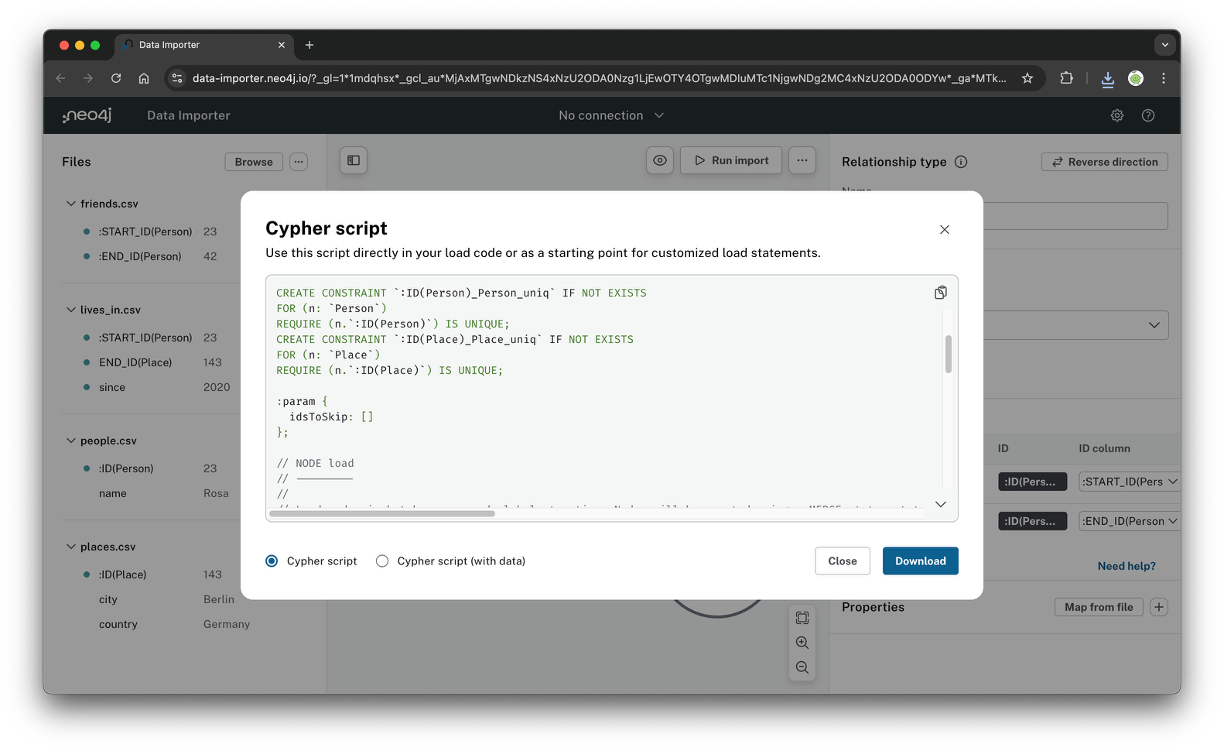
데이터를 임포트 하는 Cypher 코드도 제공하기 때문에 neo4j에서 직접 실행해도 무방하다. 다만 neo4j 버전에 따라서, 데이터 import 폴더의 위치에 따라서 방법은 조금씩 다른 것 같으니 확인해봐야 한다.
2️⃣ LOAD CSV Cypher 쿼리 활용
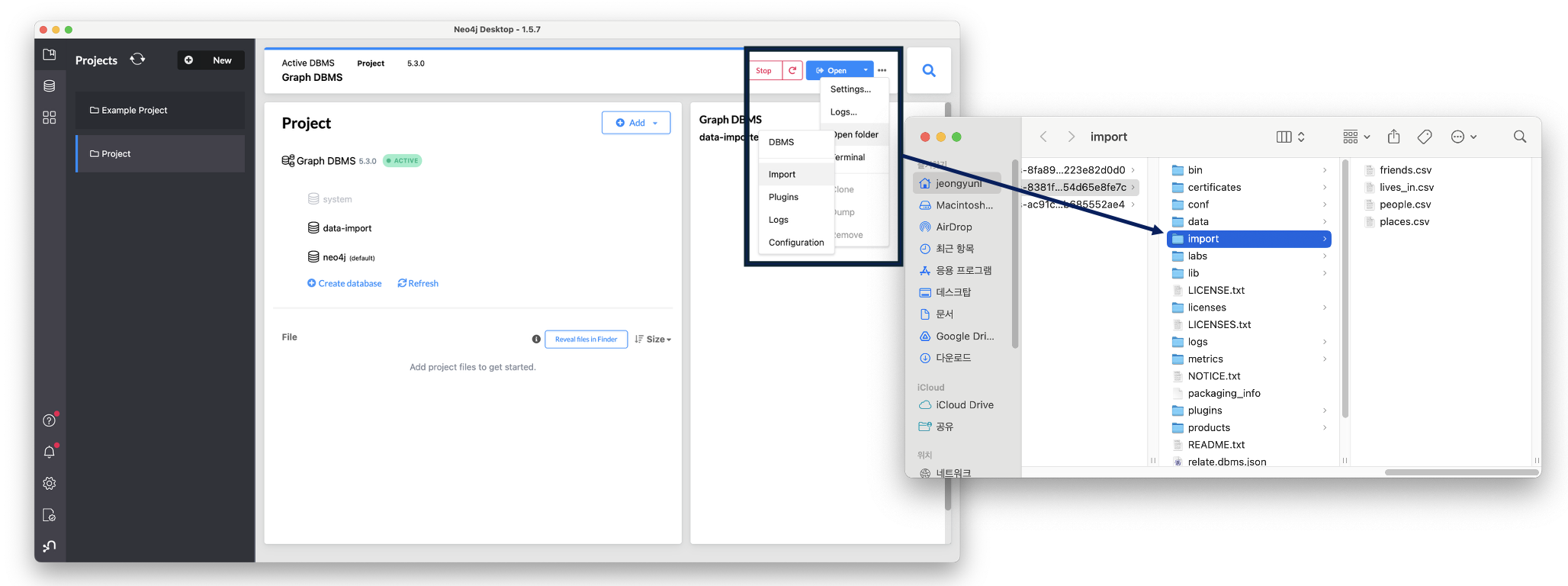
이번에는 neo4j의 인스턴스에서 직접 LOAD CSV 쿼리를 통해 임포트하는 방법이다. 우선 데이터가 DB-해당 인스턴스-import 라는 폴더 안에 위치해야 한다. 위와 같이 더보기에 Open folder>import로 들어가면 로컬 finder에서 해당 위치가 열릴 것이다. 이 부분에 위와 동일하게 4개의 csv 파일을 위치하면 된다.
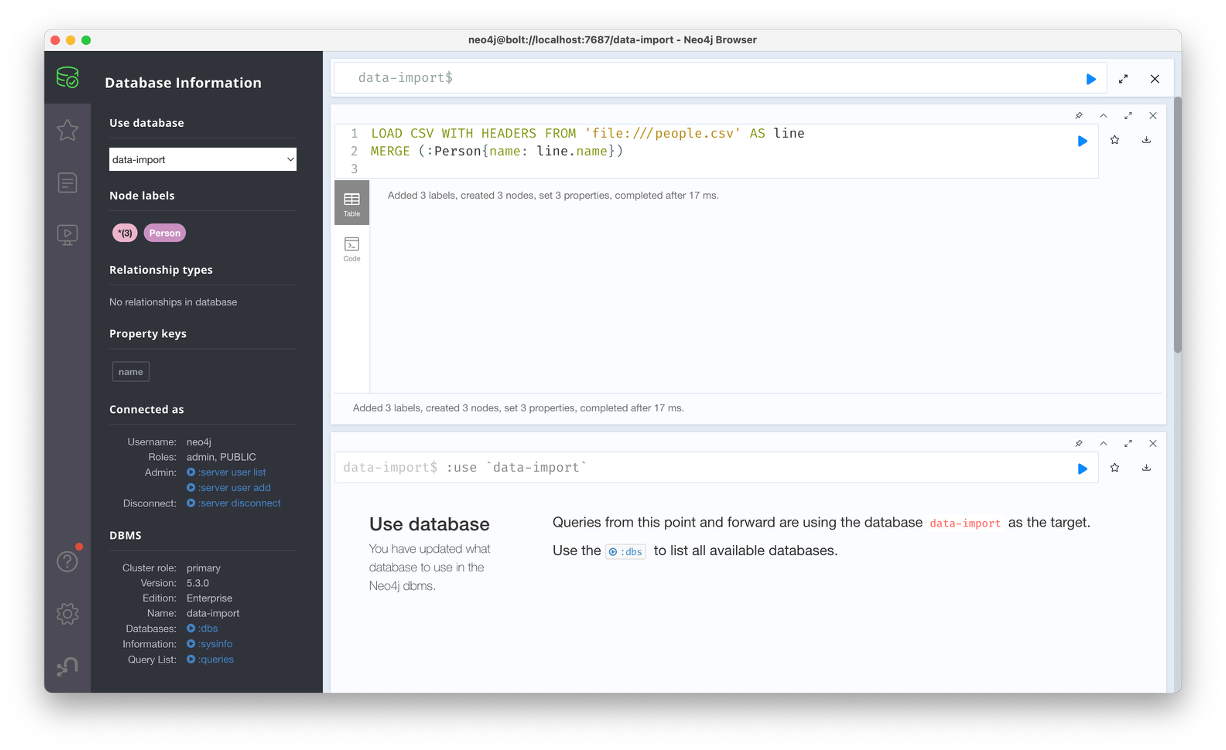
이후 쿼리창에 아래 쿼리 코드를 입력하기만 하면 된다. 노드 파일들은 각 노드컬럼과 지정할 변수명을 적으면 되고, 관계 파일들은 어떤 노드와 연결하면 되는지 관계들을 명시하면 된다.
// people.csv
LOAD CSV WITH HEADERS FROM 'file:///people.csv' AS line
MERGE (p:Person {id: line.`:ID(Person)`})
SET p.name = line.name
// places.csv
LOAD CSV WITH HEADERS FROM 'file:///places.csv' AS line
MERGE (pl:Place {id: line.`:ID(Place)`})
SET pl.city = line.city
SET pl.country = line.country
// friends.csv
LOAD CSV WITH HEADERS FROM 'file:///friends.csv' AS line
MATCH (p1:Person {id: line.`:START_ID(Person)`})
MATCH (p2:Person {id: line.`:END_ID(Person)`})
MERGE (p1)-[:FRIEND]->(p2)
// lives_in.csv
LOAD CSV WITH HEADERS FROM 'file:///lives_in.csv' AS line
MATCH (person:Person {id: line.`:START_ID(Person)`})
MATCH (place:Place {id: line.`:END_ID(Place)`})
MERGE (person)-[r:LIVES_IN]->(place)
SET r.since = line.since입력 후 확인해보면 이렇게 올바르게 데이터가 임포트 된 걸 볼 수 있다.
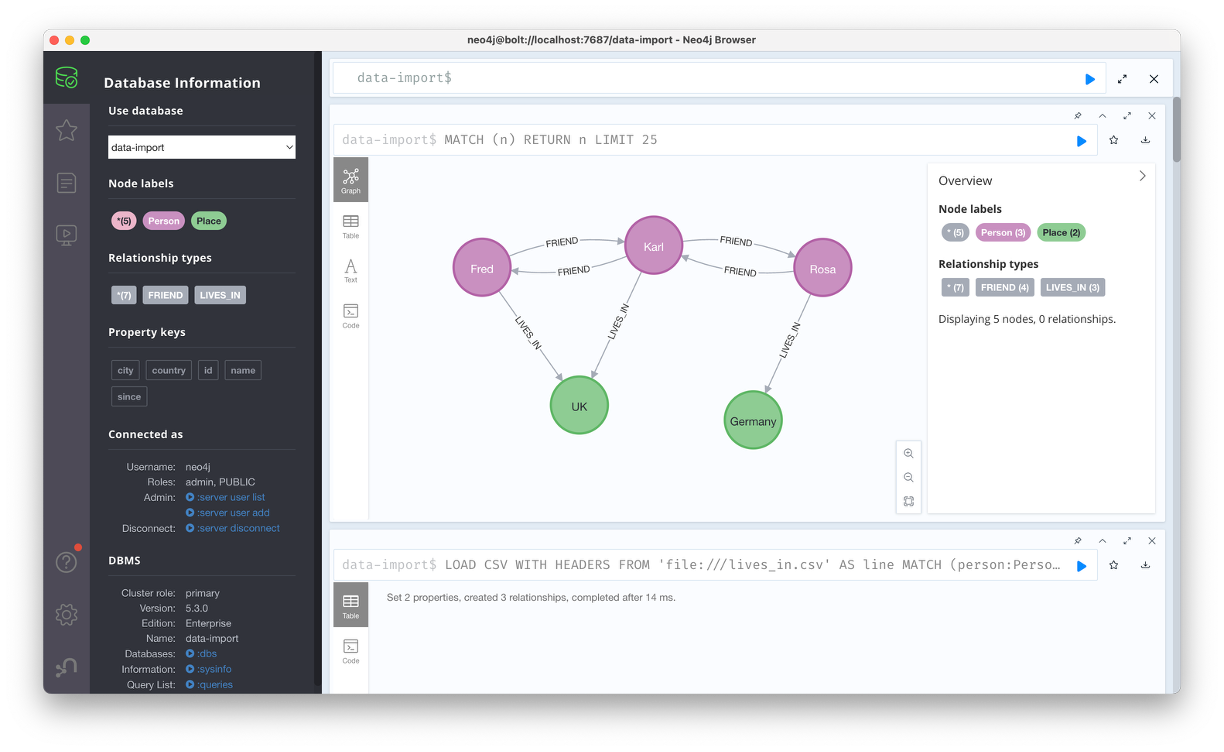
만약 100만건 이상의 데이터를 임포트 하고 싶다면, 행별로 트렌젝션 단위를 분할해서, 즉 배치 단위로 업로드하는 방법도 있다.
LOAD CSV WITH HEADERS FROM ‘file:///people.csv' AS line
CALL {
WITH line
MERGE (p:Person {id: line.`:ID(Person)`})
SET p.name = line.name
} IN TRANSACTIONS OF 1 ROWS이 과정을 EXPLAIN을 통해 확인하면 아래와 같은 결과를 확인할 수 있다.

- csv line 단위로 데이터 LOAD
- 각 csv 행을 1개의 행 transaction 단위로 실행. 한 행이라도
실행하면 ERROR FAIL - p:Person 라벨 가진 노드 스캔, p.id = line.
:ID(Person)
조건에 맞는 경우만 filter - 조건에 맞는 노드가 없으면 CREATE (MERGE 기능 수행)
- 매칭되었거나 새로 생성된 p 노드에 p.name = line.name 속성 부여
- RETURN이 없으므로 최종 결과는 EMPTY RESULT
3️⃣ neo4j-admin 활용
neo4j-admin은 초기 데이터베이스를 구축할 때(DB가 꺼져있는 오프라인 상태) 대규모 데이터를 로딩하는 툴이다. 수천만~수억 건 단위의 데이터 로드에 최적화되어 있고, S3나 Azure같은 클라우드에 있는 데이터가 아닌 로컬 파일만 업로드 가능하다는 특징이 있다. (공식 가이드 문서 참고)
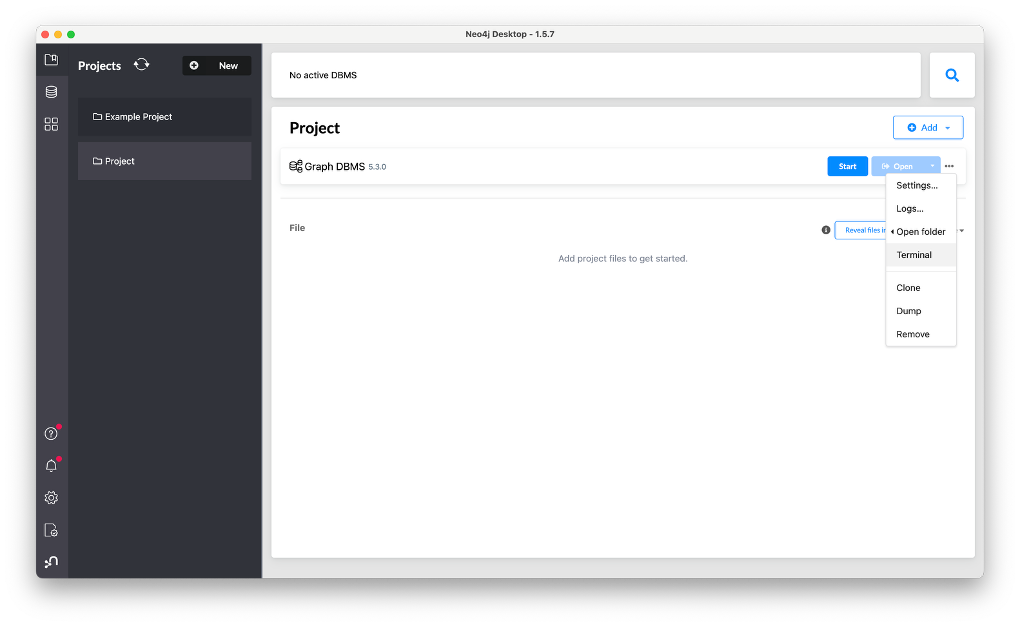
우선 빈 인스턴스를 생성해야 한다. 처음에 인스턴스를 생성하지 않고 진행했는데, 이렇게 하면 로컬에 임포트가 되지만 neo4j desktop에 업데이트가 되지 않는 문제가 발생했다. 공식 문서를 확인해보니 반드시 인스턴스를 생성하고 진행해야 한다는 설명이 있었다.
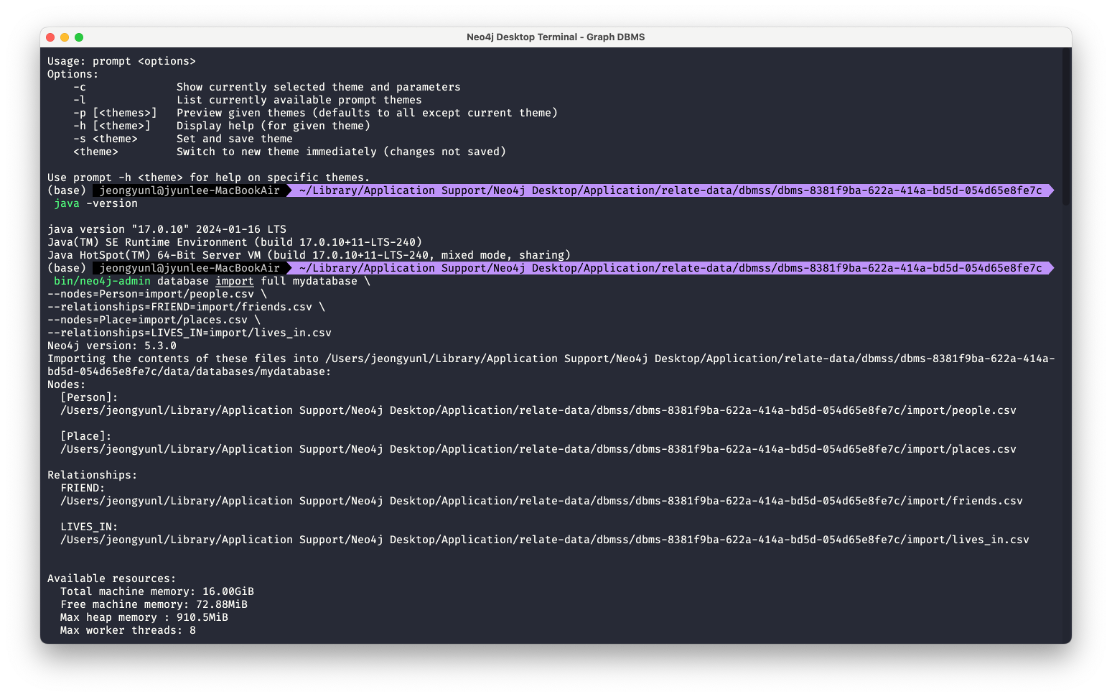
더보기 창에서 Terminal을 열면 위와 같이 인스턴스 경로에서 터미널이 열린다. 만약 docker를 사용하고 있다면 해당 neo4j 컨테이너 내부에서 진행하면 될 것 같다. Terminal에 아래 명령어를 입력하기만 하면 쭉 진행상황이 뜨고 제대로 임포트 되었다. 데이터 사이즈가 작아서 체감 속도는 LOAD CSV와 크게 다르지 않았는데, 추후 데이터 사이즈가 큰 경우에는 활용할 수 있을 것 같다.
bin/neo4j-admin database import full neo4j \
nodes=Person=import/people.csv \
relationships=FRIEND=import/friends.csv \
nodes=Place=import/places.csv \
relationships=LIVES_IN=import/lives_in.csv