
스터디 책: Building Knowledge Graphs
지식그래프의 가장 큰 장점은 다른 시스템과 통합해서 사용할 때 극대화된다. 지식그래프를 data fabric(데이터 통합 관리 아키텍쳐 정도로 이해. 아래 추가 설명 있음)에 통합하는 방법은 여러가지 있으며, 여기에는 클라이언트 측 데이터베이스 드라이버, (사용자 정의) 함수와 프로시저, API, 스트리밍 미들웨어, 그리고 ETL(추출, 변환, 적재) 도구까지 포함된다.
Towards a Data Fabric
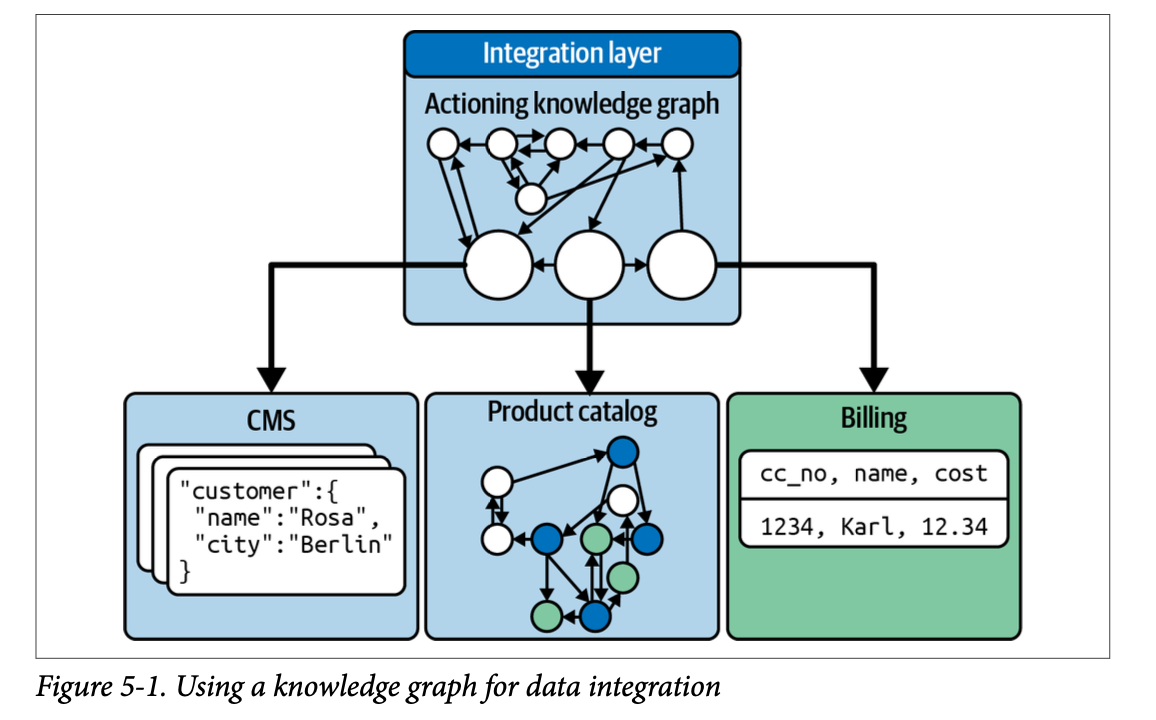
Data fabric은 조직 전체에서 사용할 수 있는 범용적인 데이터 접근 계층으로, 흩어져있는 데이터를 하나로 연결해주는 역할을 한다. data fabric의 중심 모델로 지식그래프를 활용할 수 있는데, 지식그래프를 통해 데이터들을 연결하고 색인화(indexing)할 수 있다. 즉, 클라이언트는 여러 시스템에 접근할 필요 없이 하나의 지식그래프를 통해 통합된 조회를 할 수 있다는 것이다. 위 그림에서도 고객관리, 제품 카탈로그, 가격과 관련된 개별 정보들이 RDB에 저장되어 있던, NoSQL 형식이던 KG라는 접근점으로 통합되는 것을 볼 수 있다.
그래프의 이점 중 하나는 서로 다른 소스에서 다양하게 표현되는 동일 엔티티를 유연하게 수용할 수 있다는 것이다. 데이터 통합 작업은 일회적이지 않고 점진적으로 진행되는데, 예를 들어 node degrees, neighborhood info, centrality 등과 같은 매트릭을 활용하고 텍스트 문자열 유사도, 클러스터링 개수 등을 통해 동일 노드를 파악해낼 수 있다(6장에서 추가 설명).
The Database Driver
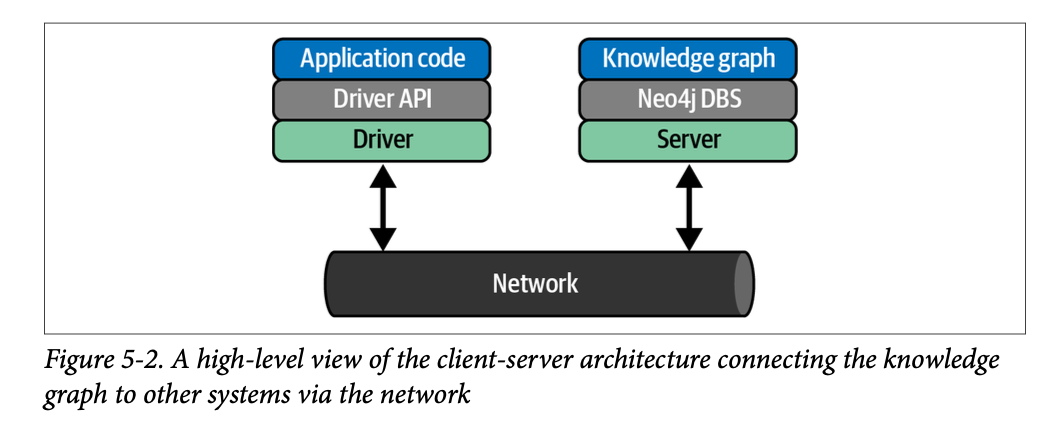
KG로 데이터를 통합하는 가장 일반적인 방법은 'driver'를 사용하는 것이다. 드라이버는 어플리케이션 아래에서 동작하는 클라이언트 측의 미들웨어로, 지식그래프와 네트워크를 통해 연결되며 통합을 이룬다. 쉽게 설명하면, 위 그림과 같이 Neo4j는 브라우저에서(https://localhost:7474 등) 쿼리를 입력하면 드라이버가 네트워크를 통해 서버로 쿼리를 전송하고, 서버의 처리 결과를 다시 브라우저에 전달하는 방식이다. 드라이버는 언어와 플랫폼별로 여러 종류가 존재하며, Neo4j는 JavaScript로 작성되었다고 한다.
Neo4j 드라이버를 사용할 때는 다음 사항들을 주의해야 한다.
- 드라이버 객체는 네트워크 연결과 인증을 설정하기 때문에 어플리케이션 전체에서 한번만 생성하는 것이 좋음. 쿼리마다 새로 생성하면 비용/성능 측면에서 비효율적임
- Session객체는 가볍고 필요할 때 마다 생성 가능하며, 비동기 API와 북마크를 지원함
- 쿼리가 읽기 전용인지 쓰기 전용인지 명시해야 클러스터에서 쿼리를 최적의 노드로 라우팅하는데 도움이 됨
- 쿼리를 파라미터화하면 재해석하지 않아도 되므로 속도가 향상됨(e.g.
MATCH (n:Person {name: $name})에서 name:name 과 같이 명시하라는 의미)
Graph Federation with Composite Databases
Neo4j Composite DB는 여러개의 독립적인 데이터베이스를 하나로 통합해서 단일 접근점을 지원한다. 이는 물리적으로 데이터를 합치는 것이 아니라 가장으로 합치는 federation을 의미한다. 예를 들어, (1) 제품 카탈로그(Product catalog), (2)유럽·중동·아프리카(EMEA) 고객 주문 (3) 아시아·태평양(APAC) 고객 주문 세 개의 DB가 있을 때, (2)와 (3)은 같은 데이터 모델(스키마)를 사용하지만 지역에 따라 분리된 형태이다. 이 경우, 다음과 같은 쿼리를 통해 하나의 DB에서 쿼리한 듯한 결과를 얻을 수 있다.
UNWIND ['globalsales.apac','globalsales.emea'] AS g
CALL {
USE graph.byName(g)
MATCH (c:Customer)-[:PURCHASED]->()-[o:ORDERS]->(:Product)
WITH c, sum(o.quantity * o.unitPrice) AS totalOrdered
WHERE totalOrdered > 100000
RETURN c.customerID AS name, c.country AS country, totalOrdered
}
RETURN name, country, totalOrderedServer-Side Procedures
일반적으로는 클라이언트-서버 방식으로 Cypher 쿼리와 Neo4j 드라이버를 사용하지만, 경우에 따라서는 서버측에서 접근하는 로직이 필요할 때가 있다. 즉, Neo4j 서버 내부에서 직접 실행되는 추가 기능(=프로시저)을 사용하는 경우를 의미한다.
앞서 APOC 라이브러리를 다룬적이 있는데, 이 라이브러리의 함수들은 neo4j의 엔진 안에서 실행되며, 필요에 따라 외부 DB(SQL, NoSQL 등), API, 파일에 직접접근해서 데이터를 가져올 수 있다. 아래와 같이 Cypher는 코드 내에서 SQL 쿼리를 적용하면 SQL 드라이버를 사용해서 DB에 접근할 수 있다. 이를 통해 사용자는 단일 시스템에서 여러 데이터베이스에 통합적으로 접근할 수 있다는 장점이 있다.
CALL apoc.load.driver("com.mysql.jdbc.Driver");
WITH "select firstname, lastname from employees
where firstname like ? and lastname like ?" AS sql
CALL apoc.load.jdbcParams("northwind", sql, ['F%', '%w'])
YIELD row
MATCH (row)-[:WORKS_FOR*1..3]->(boss:Person)
RETURN (boss)Data Virtualization with Neo4j APOC
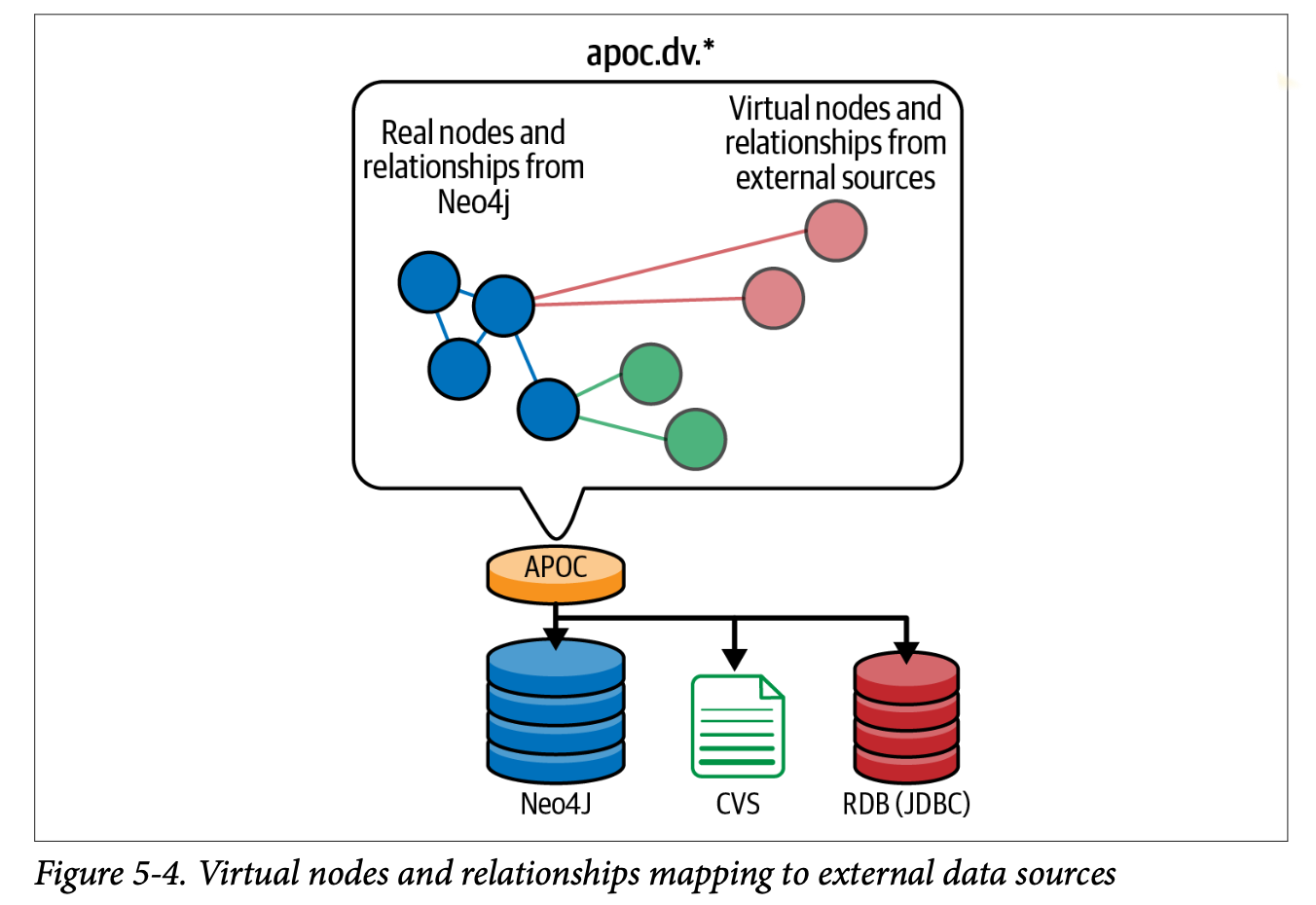
드라이버를 통해 다른 DB, API, 파일에서 가져온 데이터들은 가상의 노드로 그래프에 연결할 수 있고, 시각화도 가능하다.
이 파트의 코드들은 실습을 진행하지 않았다. 추후 진행하고 관련 내용을 추가해보겠다.
Custom Functions and Procedures
Neo4j는 내장된 Cypher 프로시저와 APOC 라이브러리 외에도 사용자가 함수와 프로시저를 정의할 수 있다. 사용자 정의 함수와 프로시저는 Cypher 쿼리와 달리 Neo4j의 Java API를 사용하여 구현된다.
당분간 직접 구현할 일은 없을 것 같아서 넘어가겠다.
Complementary Tools and Techniques
Neo4j 드라이버, 함수, 프로시저 외에도 지식그래프와 시스템을 통합하기 위한 다양한 보조 도구와 기법이 있다. 예를 들어, 지식그래프를 다양한 사용자 애플리케이션에서 활용할 수 있도록 API를 제공하거나, 상위 시스템에서 데이터를 가져와 지식그래프를 확장하기 위한 ETL 작업을 수행하는 것, 지식그래프와 분석 시스템 간의 데이터 이동이나 실시간 데이터 스트리밍을 구현하는 등의 케이스가 있다. 이를 위해 현재 구현된 도구들을 하나씩 소개하고 있다.
1️⃣ GraphQL
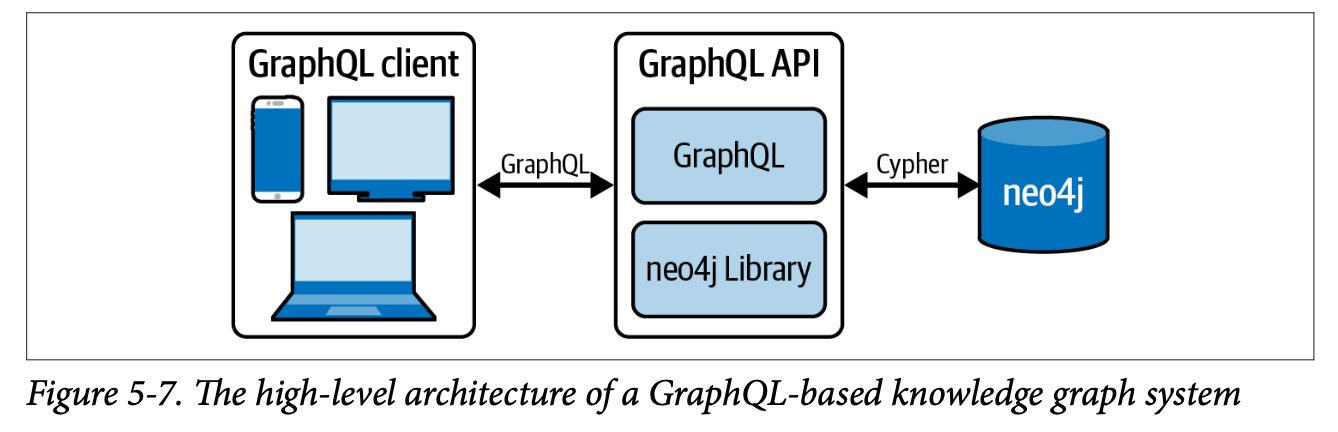
GraphQL은 Facebook에서 만든 API 툴킷으로, 초기에는 TAO(페이스북의 소셜 그래프 서비스)에 저장된 소셜 그래프에 접근하기 위한 API 제공을 목적으로 했지만, 현재는 API 구축을 위한 프레임워크(타입, 스키마, 메시지 등을 정의)이자 API 호출을 실행하는 런타임 환경(GraphQL 서버)을 제공하는 도구로 발전했다고 한다. 그래프 환경 뿐만 아니라 일반적인 시스템에서도 활용할 수 있는 범용 API 툴킷으로 REST API를 대체할 수 있는 도구로도 평가된다고 한다.
2️⃣ Kafka Connect Plug-In
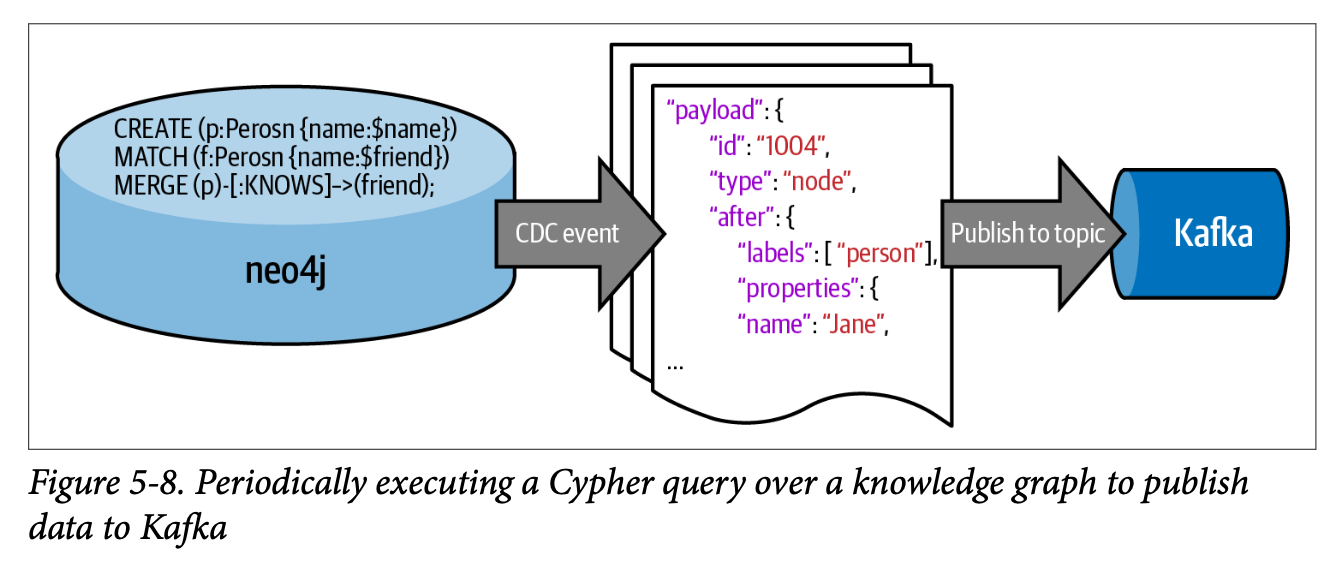
Apache Kafka는 시스템 간 데이터를 빠르고 안정적으로 주고받는 미들웨어이다. 대량의 데이터를 실시간으로 처리할 수 있고, 데이터베이스처럼 기록을 저장하고 처리하는 기능을 수행할 수도 있다.
Neo4j 지식 그래프와 Kafka를 연결하면, 두 가지 방식으로 활용할 수 있습니다. 우선, 지식그래프에서 특정 데이터를 주기적으로 조회(Cypher 쿼리)하고, Kafka로 발행해서 다른 시스템이 사용할 수 있도록 하는 방식이다. 예를 들어, '베를린에 새로 이사 온 사람' 정보를 5초마다 조회해서 Kafka 토픽(new-arrivals-in-Berlin)으로 보내는데, 이때 LIVES_IN 관계의 timestamp 속성을 이용해 최근 변경된 데이터만 가져오도록 할 수 있다. 다른 방식은 Kafka에서 발행된 메시지를 받아서 지식 그래프에 저장하는 것이다. 예를 들어, Kafka의 new-arrivals-in-Berlin 토픽에서 데이터를 받아, Cypher의 MERGE 구문을 이용해 사람 노드, 장소 노드, 관계를 자동으로 생성하고 연결할 수 있다. 이렇게 하면 실시간 이벤트를 지식 그래프에 바로 반영할 수 있다.
3️⃣ Neo4j Spark Connector
Apache Spark는 대규모 데이터를 분산 처리할 수 있는 프레임워크이다. 여러 서버(클러스터)에 데이터를 나누어 처리할 수 있고, 복잡한 연산도 간단한 코드로 순차적으로 표현할 수 있다.
Neo4j Spark Connector를 사용하면 서로 구조가 다른 Spark와 Neo4j 지식그래프를 적절히 변환해서 연결할 수 있다. 활용 방법은 두 가지인데, 첫 번째는 Spark가 지식 그래프에서 데이터를 읽어와서 처리하는 방식이다. 이때 레이블을 기반으로 읽으면 Person 노드 중 특정 조건(나이, 이름 등)에 맞는 데이터만 가져오는 방식에 해당한다. 반면, Cypher 쿼리를 기반으로 읽으면 지식그래프에서 원하는 패턴을 쿼리로 지정하고, 결과값만 가져올 수 있다. 이렇게 읽어온 데이터는 Spark의 데이터프레임(DataFrame)에서 분석, 가공, 통계 등 다양한 연산에 활용할 수 있다. 두 번째 방식은 Spark에서 처리한 데이터를 다시 Neo4j 지식 그래프에 넣는 방법이다. 이때도 레이블 기반으로 쓰면 노드의 타입을 지정해 데이터프레임의 내용을 Neo4j에 추가할 수 있고, Cypher 쿼리 기반으로 쓰면 Spark에서 가져온 데이터를 Cypher 패턴으로 변환해 노드와 관계를 생성하거나 갱신할 수 있다.
4️⃣ Apache Hop for ETL
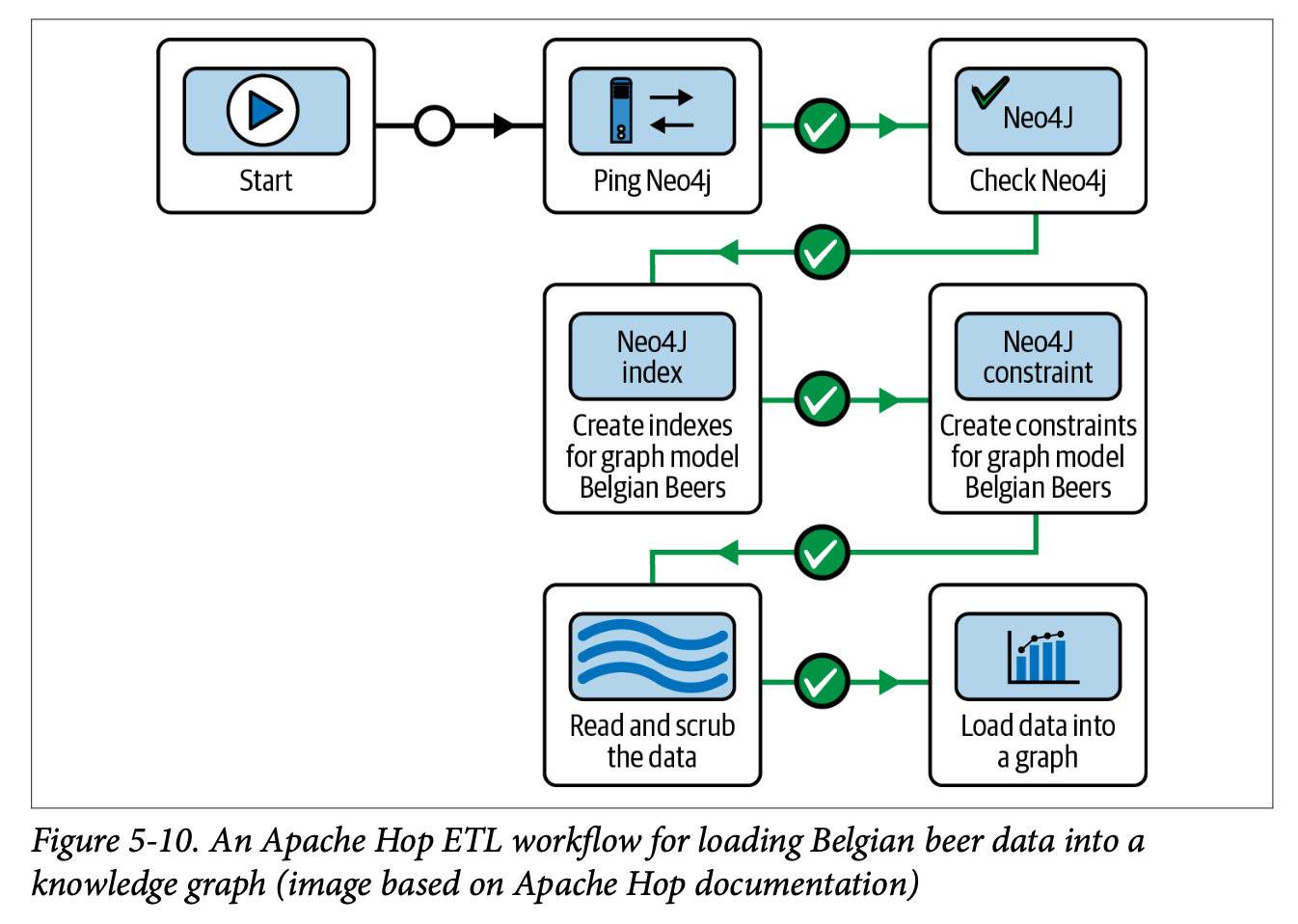
Apache Hop은 지식 그래프를 포함한 여러 시스템 간 데이터를 이동하고 변환하는 ETL 도구이다. Spark Connector가 특정 목적에 맞춘 ETL 도구라면, Hop은 좀 더 범용적이고 직관적인 ETL 플랫폼이라고 볼 수 있다. Hop은 여러가지 기능을 지원하는데, 우선 데이터베이스, 파일 시스템, 클라우드 서비스 등 Neo4j를 포함한 다양한 시스템과 연결할 수 있다. 이때 각 데이터 간의 매핑을 통해 연결할 수 있고, Cypher를 통해 여러 형태를 통합해서 쿼리할 수 있다. 또한 웹 인터페이스를 제공하여 노코드로 진행할 수 있다는 점도 큰 장점이다.
