
스터디 책: Building Knowledge Graphs
그래프 데이터사이언스의 목적은 KG에서 그래프 알고리즘을 사용해서 인사이트를 얻는데 있다. 그래프 알고리즘은 지식그래프의 구조적 특징을 이해하는 데 도움을 주는데, 예를 들어, 소셜 그래프에서 영향력 있는 사람, 철도 네트워크의 핵심 지점, 사기 집단, 질병 경로의 공통 병원체 등을 발견할 수 있다. 알고리즘 설계와 구현은 전문 영역이지만, 이를 활용하는 것은 어렵지 않으며, 목적과 실행 구문만 이해하면 된다고 한다.
Different Classes of Graph Algorithms
다양한 그래프 알고리즘은 크게 세가지 범주로 나누면 다음과 같ㅌ다.
- Statistical: 그래프의 노드 수, 관계 수, 관계의 분포, 노드 라벨 유형 등과 같은 지표를 제공. 결과를 해석하는 데 필요한 배경 정보를 제공하는 역할을 함
- Analytical: 전체 그래프 또는 주요 하위 구성 요소에서 중요한 패턴이나 잠재 지식을 발견할 수 있음
- Machine Learning: 그래프 알고리즘의 결과를 특징(feature)으로 사용해 머신러닝 모델을 학습시키거나, 머신러닝을 통해 지식 그래프 자체를 진화시키는 데 사용
ML과 관련된 알고리즘은 Chapter7에서 다루고, 이 장에서는 Statistical과 Analytical 분야를 다시 다음 5개의 범주로 구분할 수 있다.
- Network propagation: 어떤 신호가 그래프 안에서 어떻게 전파되는지 분석 (e.g. 전염병 확산 경로 파악, 공급망 취약 지점 확인과 보완)
- Influence: 네트워크 안에서 핵심 노드를 찾아서 영향력, 중심성을 분석(e.g. 소셜 미디어의 인플루언스 탐지, 네트워크의 병목 지점 식별)
- Community detection: 서로 연결된 집단 찾기 (e.g. 금융 사기 집담 탐지, 추천 시스템 등)
- Simlilarity: 유사한 특성이 있는 노드 찾기 (e.g. 고객 추천 시스템, 이상치 탐지)
- Link prediction: 현재 그래프의 구조를 기반으로 존재하지 않지만 생길 가능성이 높은 연결을 예측 (e.g. 소셜미디어에서 알 수도 있는 사람 추천, 지식그래프의 누락된 관계 보완)
어떤 분석 알고리즘을 선택할 지는 데이터의 특성과 분석 목적, 즉 맥락에 따라 다르다. 따라서 여러 방법을 테스트해보고 분석 목적에 가장 잘 맞는 결과를 주는 알고리즘을 선택해야 한다.
Graph Data Science Operations
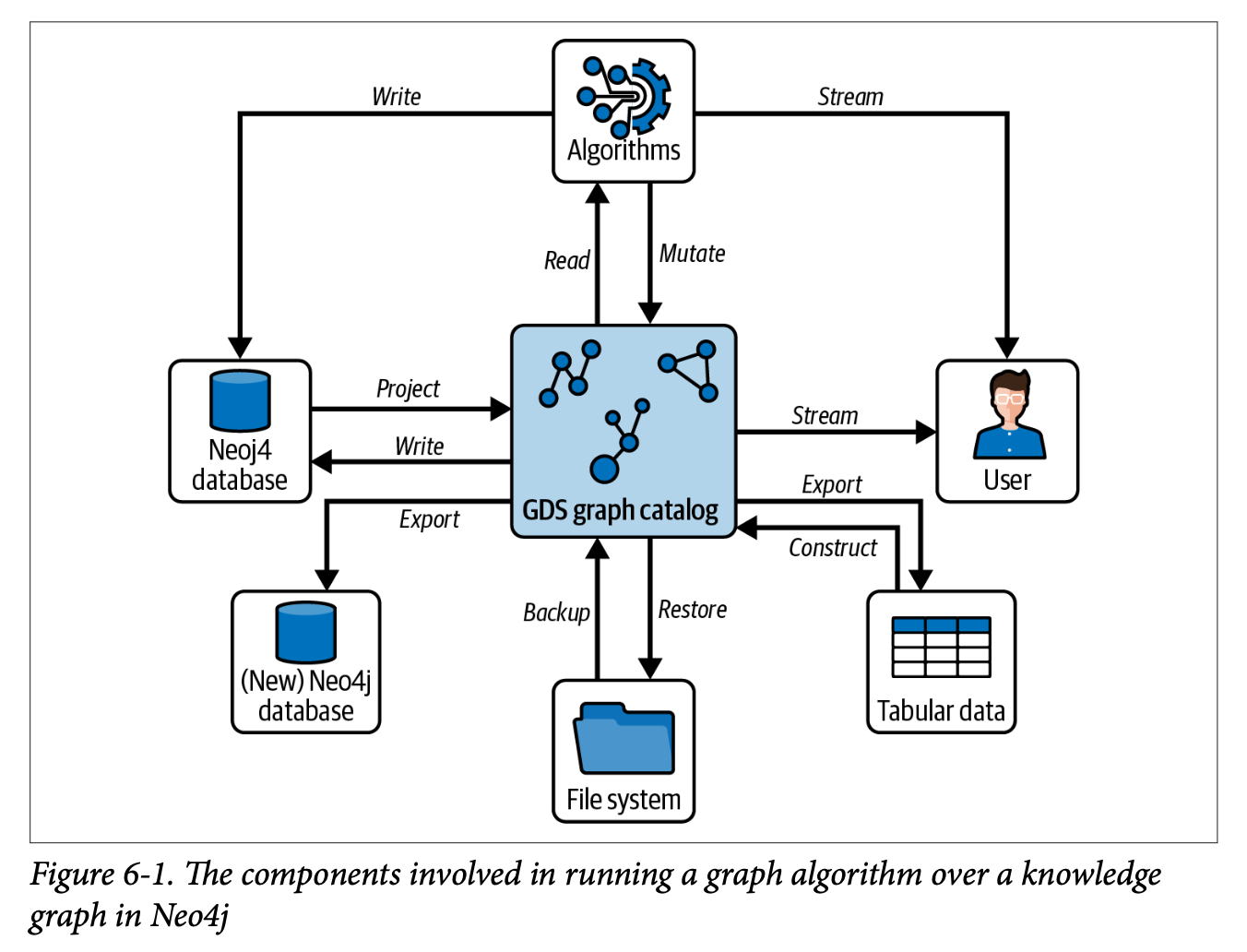
Neo4j는 플러그인으로 GDS(Graph Data Science)를 제공한다. GDS는 Neo4j의 지식그래프를 활용해서 그래프 알고리즘 등을 통해 계산하고 분석할 수 있도록 하는 도구이다. 아래에는 그래프 알고리즘을 실행하는 네 가지 주요 단계를 보여준다.
- Read: 처리하는 그래프 일부를 선택해서 하는 작업
- Load: 선택한 그래프를 인메모리 데이터 구조로 내보내어 병렬 처리 준비
- Execute: 매개변수를 지정해서 알고리즘 실행
- Store results: 결과를 다시 지식그래프에 기록해서 그래프를 풍부하게(enrich)만듦
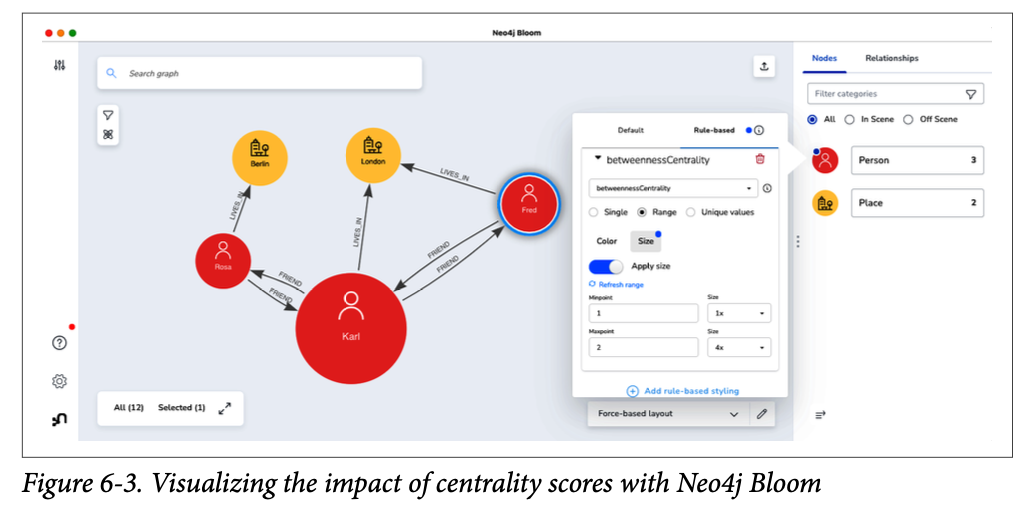
아래 코드는 GDS를 활용하는 Cypher 코드이다. 선택하고 싶은 노드를 지정하고, 관계를 설정한 뒤, 중심성(betweeness) 알고리즘을 기반으로 계산해서 'gds-example-graph'라는 graph projection에 저장한다.
CALL gds.graph.project.cypher(
'gds-example-graph'
,
'MATCH (p:Person)
RETURN id(p) AS id'
,
'MATCH (p1:Person)-[:FRIEND]->(p2:Person)
RETURN id(p1) AS source, id(p2) AS target, "FRIEND" AS type');
CALL gds.betweenness.write('gds-example-graph',{
writeProperty:'betweennessCentrality'});쿼리 결과를 Neo4j Bloom을 통해 시각화하면 아래와 같은 결과를 얻을 수 있다. 그래프 사이즈가 큰 경우에는 이 계산이 오래걸릴 수 있는데, 이 경우에는 더 작은 projection 그래프를 선택하거나, CPU와 RAM 성능을 높여야 한다.
Experimenting with Graph Data Science
이 챕터에는 GDS API를 Python에서 실행하는 방법을 설명한다. 우선 pip instal graphdtascience와 pip install notebook을 설치하고, 데이터는 이 깃헙에서 'nr-stations-all.csv'와 'nr-station-links.csv'를 다운 받을 수 있다.
파이썬에서 아래 코드를 실행하면 데이터를 임포트할 수 있다. host, user, password는 각자 설정에 맞게 작성하면 된다. pymysql을 사용하는 것과 유사해서 그렇게 어렵지 않게 사용할 수 있었다.
from graphdatascience import GraphDataScience
# Connect to the database
host = "bolt://localhost:7687"
user = "neo4j"
password= "password"
gds = GraphDataScience(host, auth=(user, password), database="neo4j")
# Load stations as nodes
gds.run_cypher(
"""
LOAD CSV WITH HEADERS FROM "file:///nr-stations-all.csv" AS station
CREATE (:Station {name: station.name, crs: station.crs})
"""
)
# Load tracks bewteen stations as relationships
gds.run_cypher(
"""
LOAD CSV WITH HEADERS FROM "file:///nr-station-links.csv" AS track
MATCH (from:Station {crs: track.from})
MATCH (to:Station {crs: track.to})
MERGE (from)-[:TRACK {distance: round( toFloat(track.distance), 2 )}]->(to)
"""
)
gds.close()이렇게 연결한 뒤, 최단거리 역사를 찾는 쿼리나 기타 다른 분석 쿼리들을 실행할 수 있다. Neo4j bloom에서 시각화 결과를 보면 아래와 같은 그래프를 확인할 수도 있다.
교안에 있는 모든 테스트 코드를 하나씩 실행해보면서 결과를 보진 않았지만, 그래프 알고리즘을 사용하는 경우에 파이썬에서 neo4j와 연결해서 수행할 수 있다는 사실은 이해할 수 있었다. 한편, 단일 그래프 알고리즘 점수로는 현상을 완벽하게 설명하기 어렵다는 것을 언급하며, 경우에 따라 더 정교한 projection을 만들거나 추가적인 알고리즘을 적용할 필요성을 강조했다.
Production Considerations
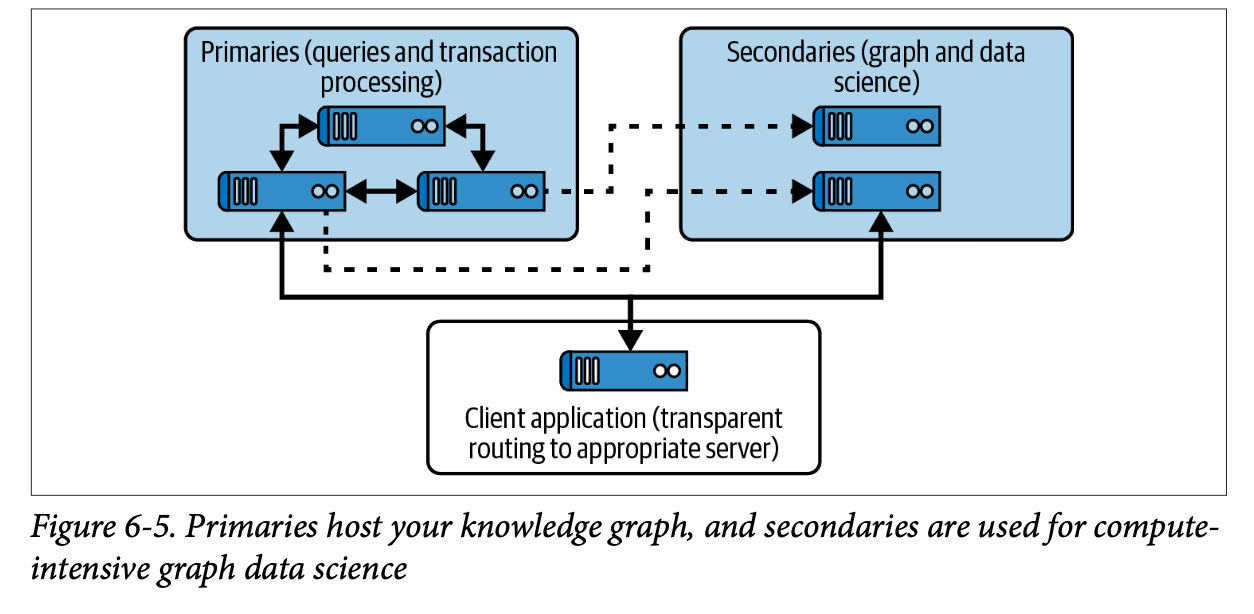
실제 운영 환경에서는 물리적 서버를 역할별로 나누는 것이 일반적이며, Neo4j에서는 이를 위해 Primary 서버와 Secondary 서버를 지원한다.
- Primary 서버: 트랜잭션 처리를 담당하며, 클러스터를 구성하여 확장성과 가능한 장애에 대응한다. Cypher 쿼리를 담당하고 원칙적으로 그래프 알고리즘을 실행할 수 있지만, 트랜잭션 처리 계산과 충돌할 가능성이 있다.
- Secondary 서버: GDS 등 그래프 알고리즘을 계산하는 용도로 사용한다. 업데이트를 비동기적으로 받아서 primary와 달리 트랜잭션에 영향을 주지 않는다. CPU, RAM 등 하드웨어 구성을 다르게 해서 알고리즘 계산을 최적화해서 수행할 수 있다.
간단하게 정리하면, primary 서버는 데이터를 직접 기록하는 곳이고 sencondary 서버는 데이터를 복제해서 조회, 분석에 활용한다. 이때 데이터를 업데이트 하자마자 쿼리를 하면 secondary에 반영되지 않았을 가능성이 있으므로 Neo4j는 데이터가 반영된 시점을 표시하는 '북마크'라는 기능을 제공한다. 이를 통해 언제 쿼리를 실행해도 데이터가 일관되게 보장될 수 있다.
또한 production 단계에서는 알고리즘을 적용해서 도출된 결과를 단순히 확인만 하는 것이 아닌, 그래프에 정보를 추가해서 시스템 개선에 활용할 수 있다.
