
The basics of query language generation
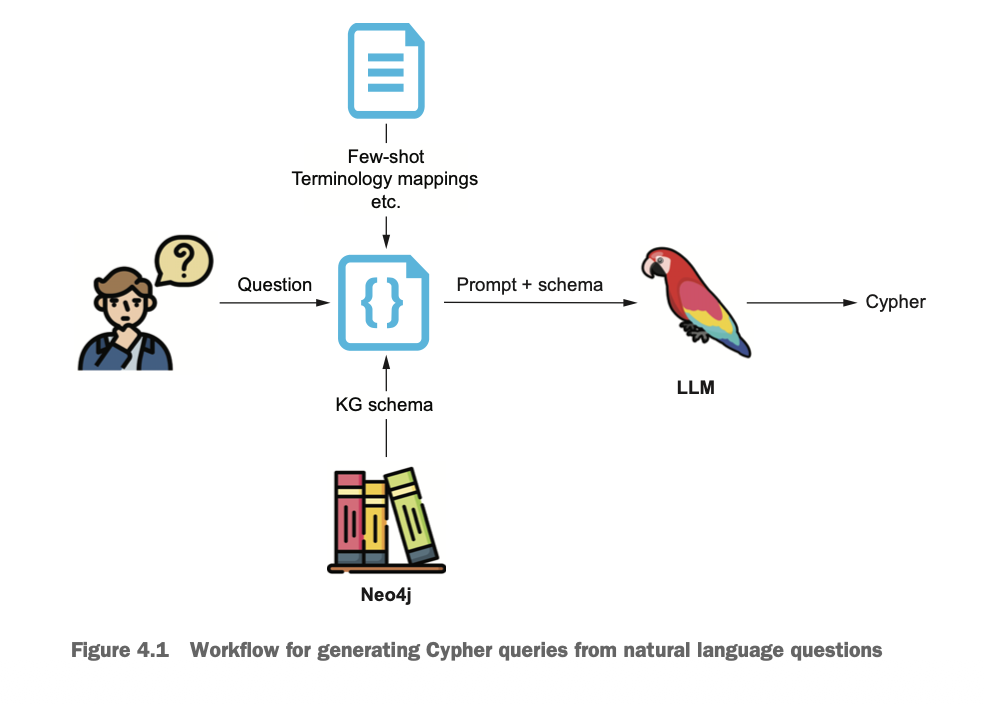
자연어 질의를 Cypher 쿼리로 변환할 때 가장 중요한 점은 질의 문장의 문법적 요소를 파악하는 것과 지식그래프의 구조를 이해하고 있어야 한다는 점이다. 따라서 그래프의 스키마 정보와 용어 매핑정보, 형식 가이드 등과 few-shot 예시 일부가 제공되어야 한다.
Where query language generation fits in the RAG pipeline
'List the top three highest-rated movies directed by Steven Spielberg and their average score'라는 질문이 있을 때, 이는 벡터 유사도를 기반으로는 답변하기 어렵다. 대신, 아래와 같이 데이터베이스에서 직접 쿼리해서 정보를 가져올 필요가 이다.
MATCH (:Reviewer)-[r:REVIEWED]->(m:Movie)<-[:DIRECTED]-(:Director {name:'Steven Spielberg'})
RETURN m.title, AVG(r.score) AS avg_rating
ORDER BY avg_rating DESC
LIMIT 3즉, 유사한 노드를 찾는 것이 아닌 정확한 수치 계산이 필요한 유형의 질문의 경우 Cypher쿼리를 생성할 필요가 있다는 것이며, Text2Cypher가 필요한 이유가 된다.
Useful practices for query language generation
질문이 복잡하거나 모호할 때 생성된 쿼리는 오류가 발생할 수 있다. 다음 네 가지 방법은 정확한 쿼리를 생성하기 위해 시도할 수 있는 몇 가지 기법들을 설명한다.
1️⃣ Using few-shot examples for in-context learning
few-shot 예제는 자연어-Cypher쿼리 쌍으로 구성된 임의의 예시를 제공하는 방법이다. 예를들어, 'In what country was the movie The Matrix produced?'라는 자연어 질의는 MATCH (m:Movie {title: 'The Matrix'}) RETURN m.country 쿼리에 매칭된다. 그러나 실제로 Movie 노드에 country라는 속성이 있지 않고, 관계인 PRODUCED_IN으로 표현되어야 한다면, 아래와 같은 예시를 추가해서 쿼리를 수정할 수 있다.
Question: In what country was the movie Ready Player One produced?
Cypher: MATCH (m:Movie { title: 'Ready Player One' })-[:PRODUCED_IN]->(c:Country)
RETURN c.name이 예시를 참고해서 LLM은 MATCH (m:Movie {title: 'The Matrix'})-[:PRODUCED_IN]->(c:Country) RETURN c.name 이렇게 올바른 쿼리를 생성할 수 있다.
2️⃣ Using database schema in the prompt to show the LLM the structure of the knowledge graph
Cypher쿼리를 생성할 때 지식그래프의 스키마 정보를 프롬프트에 넣어주는 방식으로, Neo4j의 연구에 따르면 형식이 큰 영향을 주진 않는다고 한다. 스키마는 레이블, 관계 정보, 속성 정보들을 다음과 같이 표현한다.
Graph database schema:
Use only the provided relationship types and properties in the schema. Do not use
any other relationship types or properties that are not provided in the schema.
Node labels and properties:
LabelA {property_a: STRING}
Relationship types and properties:
REL_TYPE {rel_prop: STRING}
The relationships:
(:LabelA)-[:REL_TYPE]->(:LabelB)
(:LabelA)-[:REL_TYPE]->(:LabelC)지식그래프 전체를 쿼리용으로 노출할지 여부는 스키마의 크기와 사용목적에 따라서 다른데, Neo4j에서 스키마를 자동으로 추론할 수도 있지만 사이즈가 큰 경우 비용이 많이 든다고 한다. 따라서 일반적으로는 데이터의 일부를 샘플링해서 추론하고 이때 Neo4j의 APOC 라이브러리를 사용할 수 있다. 즉, Cypher를 통해서 일부 노드와 속성, 관계와 속성 등을 추출한 뒤, 파이썬의 함수를 통해서 이 값들을 구조화된 형식으로 바꿔서 프롬프트에 넣어준다는 의미이다.
import neo4j
from neo4j.exceptions import ClientError
from typing import Any, Optional
NODE_PROPERTIES_QUERY = """
CALL apoc.meta.data()
YIELD label, other, elementType, type, property
WHERE NOT type = "RELATIONSHIP" AND elementType = "node"
WITH label AS nodeLabels, collect({property:property, type:type}) AS properties
RETURN {labels: nodeLabels, properties: properties} AS output
"""
REL_PROPERTIES_QUERY = """
CALL apoc.meta.data()
YIELD label, other, elementType, type, property
WHERE NOT type = "RELATIONSHIP" AND elementType = "relationship"
WITH label AS relType, collect({property:property, type:type}) AS properties
RETURN {type: relType, properties: properties} AS output
"""
REL_QUERY = """
CALL apoc.meta.data()
YIELD label, other, elementType, type, property
WHERE type = "RELATIONSHIP" AND elementType = "node"
UNWIND other AS other_node
RETURN {start: label, type: property, end: toString(other_node)} AS output
"""각 정보는 위와 같은 Cypher 쿼리를 통해서 추출하고, 파이썬 함수를 통해 프롬프트에 들어갈 적절한 형식으로 변환하면 된다. Movie 예제를 기반으로 실행하면 아래와 같은 스키마를 추출할 수 있다.
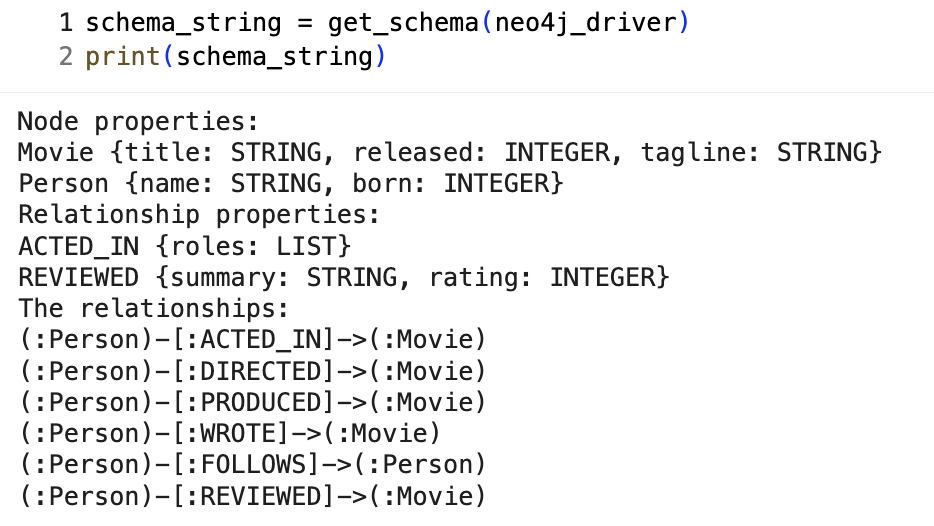
3️⃣ Adding terminology mapping to semantically map the user question to the schema
지식그래프에서 사용한 용어에 대한 정보를 프롬프트에 넣어주는 방법을 의미한다. 일반적으로 명사형이나 동사형을 레이블과 관계에 사용하고, 부사나 명사형을 속성에 사용하는데, 그럼에도 여러 변칙들이 있을 수 있으므로 완벽하게 그래프에서 사용한 단어를 LLM이 활용하지 않을 가능성이 있다. 따라서 아래와 같이 용어 매핑에 대한 정보를 프롬프트에 넣어주는 것이다.
TERMINOLOGY MAPPING:
Persons: When a user asks about a person by trade, they are referring to a node with
the label Person. Movies: When a user asks about a film or movie, they are referring
to a node with the label Movie.4️⃣ Format instructions
Cypher 쿼리를 출력할 때, LLM에 따라 코드 블럭 형태로 출력할 수도 있고, 벡틱 등을 포함할 수도 있다. 따라서 특정 형식을 반드시 지정해서 출력하도록 하는 프롬프트를 추가하는 것이다. (LangChain과 같은 라이브러리를 사용하면 형식을 지정을 위한 프롬프트 템플릿들을 제공하기도 한다)
FORMAT INSTRUCTIONS:
Do not include any explanations or apologies in your responses. Do not respond to
any questions that might ask anything else than for you to construct a Cypher state-
ment. Do not include any text except the generated Cypher statement. ONLY
RESPOND WITH CYPHER, NO CODE BLOCKS.위 내용을 Neo4j Python Driver와 OpenAI API를 사용해서 테스트 할 수 있도록 하는 코드를 이 깃헙에서 제공한다.
이 코드를 코랩에서 바로 실습할 수 있도록 재구성했는데, Neo4j Aura 인스턴스 정보와 OpenAI API 키만 따로 설명하면 된다.
https://colab.research.google.com/drive/11o5FMpBpVVemq1h2rBFK0e6mI_X-xIFU?usp=sharing
Specialized (finetuned) LLMs for text2cypher
Neo4j에서는 finetuning을 통해서 text2Cypher를 구현하는 방법에 대해서도 학습데이터와 오픈소스 모델을 제공한다고 한다. 즉, 대형 모델과 같이 모든 기능을 다 수행할 수 있는게 아니라, 텍스트를 Cypher 쿼리로 옮기는데 특화된 소형 모델을 의미한다.
