https://www.youtube.com/watch?v=MJW9knnRV5o&t=399s
본 글은 해당 영상을 보고 난 후 NLP로 직무별 역량의 온톨로지를 구축할 수 있지 않을까? 란 생각에서 skill ontology를 구축하는 시도를 정리해보는 글입니다.
Ontology와 Taxonomy
온톨로지(ontology)란 존재하는 사물과 사물 간의 관계 및 여러 개념을 컴퓨터가 처리할 수 있는 형태로 표현하는 것입니다. 특히 HRD의 관점에서 한 사람이 가지고 있는 역량(skill)을 어떻게 정의하고, 조직이 필요로하는 역량이 무엇인지 정의할때 skill ontology를 사용하게 됩니다. 즉 역량이라고하는 추상적인 개념을 컴퓨터가 읽을 수 있게 정의하고, 역량 사이의 관계를 정립하여 관리하는 체계가 온톨로지라고 할 수 있습니다.
위의 그림은 data와 관련되어 있는 영역의 역량을 보여줍니다.

택소노미(Taxonomy)는 그 자체로는 분류체계를 의미합니다. 주로 생물, 유전자의 분류체계를 의미하지만 HRD 관점에서는 한 조직에 필요한 역량의 분류, 관리 체계입니다.
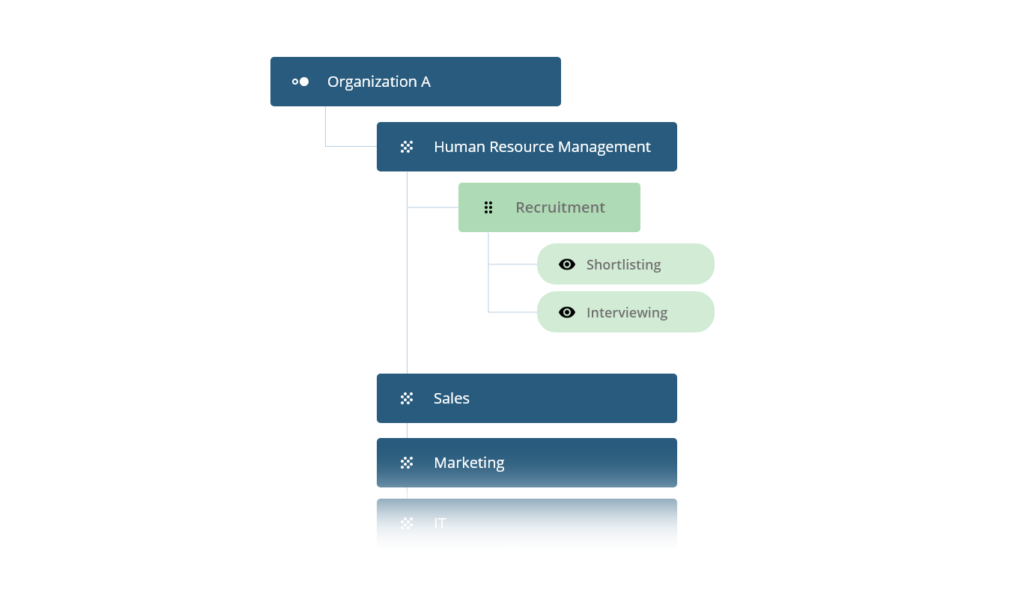
위의 그림을 보면 조직 A에 필요한 하위 부서로 HR, Sales,Marketing, IT등이 존재합니다. 그리고 그 하위에서는 '채용'이라는 역할이 존재하고, '채용'이라는 역할에 필요한 역량으로 최종 후보를 선출하는 능력, 면접을 보는 능력이 필요로 합니다.
이렇게 HRD에서는 택소노미를 활용해 조직에 필요한 역량이 무엇인지 파악하고, 조직원들에게 해당 역량을 개발하는데 필요한 교육을 제공하는 것을 목표로 합니다.
왜 필요한가?
최근 AI와 기술의 발달으로 과거에는 100명이 10일이 걸리는 일을 컴퓨터가 5분만에 해결하게 되면서 자연스럽게 새로운 기술을 배우거나, 새로운 일을 맡게되는 경우가 늘었습니다. 이 때문에 등장한 개념이 upskilling과 reskilling으로 역량의 대한 엄밀한 정의가 되어있다면 조직에 필요한 역량을 진단하고, 그 역량에 필요한 교육을 제공할 수 있기 때문입니다.
어떻게 Ontology를 구축할 수 있을까?
사실 이와 관련된 정보를 찾기는 너무 어려웠습니다. 그렇게 해서 시도해보고자하는 task는 skill별 description을 임베딩하여 클러스터링 해보고자 합니다. 미국의 노동부 직업 정보 네트워크인 o*net에는 skill별 description을 제공하고, lightcast라는 직무분석 기업은 어떤 직무가 어떤 skill을 필요로 하는지, 해당 skill과 유사한 skill이 무엇인지 제공해줍니다.
skill별 description을 임베딩하고, 클러스터링 하였을때 결과가 lightcast에서 제공하는 유사한 skill이라면 ontology 구축에 도움이 되지 않을까란 생각으로 프로젝트를 진행해 보고자 합니다.
project flow
- 직무(occupition)별 description, 채용공고 데이터 수집
- 데이터 전처리
- 문자열 데이터 임베딩
- 클러스터링, 시각화
- 결과 확인(lightcast와 비교)
의 순서로 진행 해 보고자 합니다.
데이터 수집
우선 직무별 역량 데이터를 lightcast의 api를 활용해 수집하겠습니다.
https://docs.lightcast.dev/apis/skills
import requests
url = "https://auth.emsicloud.com/connect/token"
payload = "client_id=CLIENT_ID&client_secret=CLIENT_SECRET&grant_type=client_credentials&scope=emsi_open"
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
response = requests.request("POST", url, data=payload, headers=headers)
skill_response = json.loads(response.text)
access_token = skill_response['access_token']
print(access_token)우선 access_token을 받아오고,
import requests
url = "https://emsiservices.com/skills/versions/latest/skills"
querystring = {"fields":"id,name,type,infoUrl"}
headers = {'Authorization': f'Bearer {access_token}'}
response = requests.request("GET", url, headers=headers, params=querystring)
skill_response = json.loads(response.text)
len(skill_response['data'])데이터를 skill 데이터를 받아옵니다.

받은 데이터에는 skill의 이름, skill의 description, type이 존재합니다.
lightcast는 skill을 크게 3가지로 분류하며
1. Specialized Skills
직업의 하위 집합 내에서 주로 요구되거나 특정 작업을 수행하기 위해 필요한 기술(예: "NumPy" 또는 "호텔 관리"). 기술 또는 하드 스킬이라고도 합니다.
2.Common Skills
개인적 특성과 학습된 기술을 포함하여 다양한 직종과 산업에서 널리 사용되는 기술입니다. (예: '커뮤니케이션' 또는 'Microsoft Excel'). 소프트 스킬, 휴먼 스킬, 역량이라고도 합니다.
3.Certifications
업계 또는 교육 기관에서 지정한 공인 자격 기준(예: "미용사 면허" 또는 "공인 세포 기술자").
입니다.
데이터를 확인해보면 받아오는 json형식이 달라 받아오지 못한 데이터를 마저 받아오면 역량 데이터를 받아올 수 있습니다.
