
Pandas
- 구조화된 데이터의 처리를 지원하는 Python 라이브러리Python계의 엑셀! (몹시 비슷함)
- Panel data → pandas
- 고성능 array 계산 라이브러리인 numpy와 통합하여, 강력한 스프레드시트 처리 기능을 제공
- 인덱싱, 연산용 함수, 전처리 함수 등을 제공함
- 데이터 처리 및 통계 분석을 위해 사용
- table 형태의 데이터는 거의 이런 식으로 변경해서 사용함
데이터 로딩
data_path = ~~
data = pd.read_csv(data_path, sep = '\s+', header = None)
# csv type 로드, sep는 데이터 커팅 기준, header는 Column 포함 유무기본
Pandas의 형태
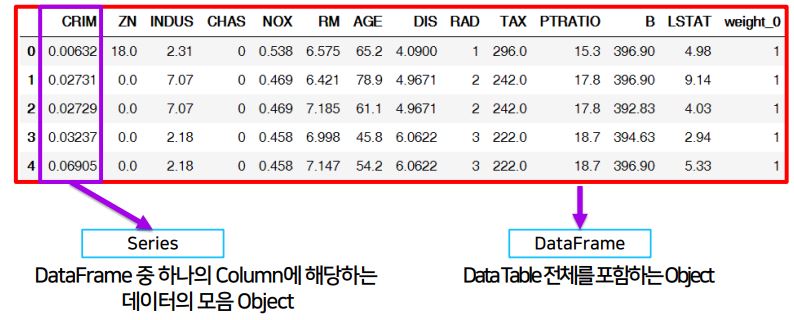
Series
- Series : DataFrame 중 하나의 column에 해당하는 vector를 표현하는 object
- list data를
Series(data = list, index = list_index)로 해서 pandas로 변환할 수 있음. (이는 기본이 numpy, 그걸 series라는 포장지로 싸는 것) data의 index를 숫자 또는 문자로 바꿀 수 있음 - dict type도 바로 padas 변환가능
Series(data = dict, dtype = 설정 가능, name = 설정가능)

data[idx]로 접근 가능.data.value,data.index로 값 list 추출 가능data.name = ~,data.index.name = ~의 형태로 정보 저장 가능(사실 잘 안씀. column 값으로 많이 사용함)
dataFrame
- data table 전체를 포함하는 Object
- dataframe의 memory

- data에 접근하기위해서는 col, idx 둘다 알아야함.
- 각 data의 type은 다를 수 있음.
- series를 모아서 만든 data table → 기본 2차원
- data frame 생성시 dict 형태로 만들면
{column_name : data}로 적용됨 dataframe(data, column = [a,b]로 가능- column 선택 후 series 추출 하는 방법은
df.col1ordf['col1']형태가 있음 (df는 df = dataframe ~ 형태로 저장된 상태)- data frame indexing
- loc : index location(행을 읽음).
df.loc[idx],df.loc[:,['col1', 'col2']]형태도 가능 - iloc : index position(열을 읽음).
`df['col'].iloc[idx]

df.T: data transposedf.to_csv(): csv 변환 (shift + tab으로 더 기능 확인 가능)df.drop('col1' axis = 1)col1 지워진 형태로 보임(df 데이터 삭제 X)df.del['col1']col1 메모리 삭제 (df 데이터 삭제)dict = {'col1' : {idx1 : 1, idx2 : 2}, 'col2' : ~}의 형태로로 dataframe 생성 가능 (실제론 거의 사용 X. 나중에 JSON 파일 이용시 dataframe으로 사용할 수 있겠네~? 정도만 알면 O)
Selection & Drop
selection with Column
df['col1']: 한개의 column 선택 → series data 추출df[['col1']]: 한개의 column을 list로 선택 → dataframe 형태로 추출df.head(3).T: 3개의 데이터만 뽑아서 Transpose로 어떤 형태인지 확인하기도 함df[['col1', 'col2']]: 여러개를 뽑을 땐 list 형태로 씀 → dataframe 형태 추출
selection with index
※ 헷갈리니 column 은 str, index 는 int 값으로 하는게 좋음
df[:3]: index 기준 3개 뽑음 → series data 추출df[[0,1,2,3]]: 1개 이상의 indexdf[list(range(0, 15, 2)]: 형태로도 추출 가능(fancy index)df[조건]: 조건이 True인 값만 추출 (boolen index)- 다양한 data 추출 방법
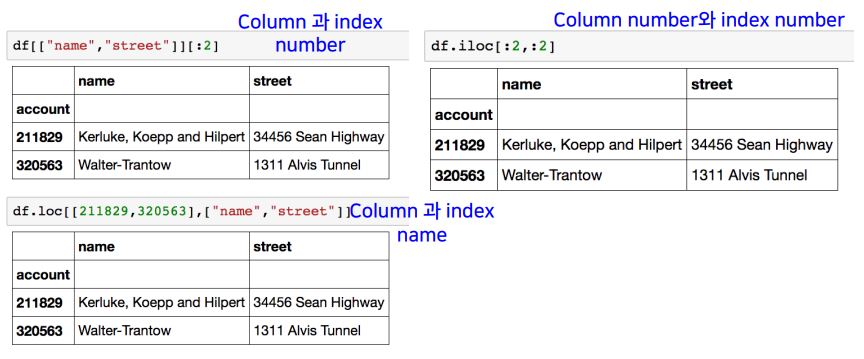
- index를 정확히 안다면 loc(권장), 아니면 iloc,
- 보통 select 시는
df[['col1', 'col2']][:2]형태, 할당은loc형태
df.reset_index(): index 재설정.
(drop = True)시 기존 index는 지워짐(실제 df에서 삭제 X)
(inplace = True)로 하면 실제 df에서 삭제됨df.drop(idx): 해당 index 지움 (실제 df 삭제 X)df.drop('col1', axis = 1): 해당 col axis 기준으로 지움(df 삭제 X).inplace = True써줘야 df에서 삭제
dataframe operations
- series operation

- 이때
df.add(df2, fill_value= 0)으로 하면 NaN값은 0으로 변환해서 operation 진행 - operation types = add, sub, div, mul
- 이때
- series + dataframe

- axis를 기준으로 broad casting 실행하기 때문에 axis 설정 안하면 계산이 안됨
lambda, map, apply (inplace True안하면 변함 X)
- apply는 기본 col단위로 한다는 것
- apply map은 모든 element에 적용
Pandas built-in functions
isnull()df.sort_values(['col1', col2']): value 값으로 sortingpd.options.display.max_rows = 200: display 설정 변경하는것. 가운데 ... 없이 200개의 값 모두 출력됨- corr 처리시 sex같은 데이터는 male, female 대신 0, 1로 변경하는데, 이를 label encoding 이라고함

차보의 Data Engineer 도전기♥ (근데 기록을 곁들인)