
어떻게 행렬과 매트릭스를 코드로 표현할 것인가?
- List 형태로 표현했었으나 큰 Matrix 등을 사용하기 위해 Numpy 사용!
Numpy
Numpy란?
- Numerical Python
- 파이썬의 고성능 과학 계산용 패키기
- Matrix와 Vector 같은 Array 연산의 사실상의 표준(이걸로 선형대수 대부분을 다룸)
Numpy 특징
- 일반 List에 비해 빠르고, 메모리가 효율적
- 반복문 없이 데이터 배열에 대한 처리를 지원함
- 선형대수와 관련된 다양한 기능을 제공
- C, C++, 포트란 등의 언어와 통합가능
import numpy as np형태로 호출
array creation
test_array = np.array([1,2,3,4], float)형식으로 가능- np.array 함수를 활용해 배열을 생성함 → 생성배열을 'ndarray 객체'라고 부름
- numpy는 하나의 데이터 Type만 배열에 넣을 수 있음
(기존 list엔 다양한 타입이 들어갔음 [1, 0.7, 0.5])
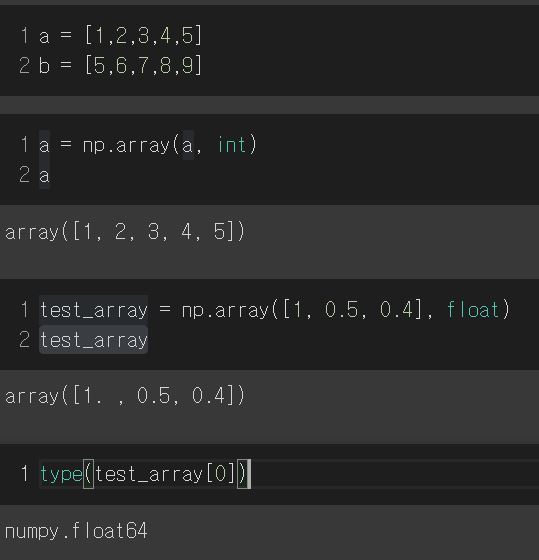
※ 참고) Shift + tab을 누르면 Docstring으로 함수 구성을 보여줌 → 선언해서 확인하는게 좋음 - List와 가장 큰 차이점 → daynamic typing not supported
- C의 Array를 사용해 배열을 생성함
.shape: numpy array의 dimension 구성을 반환 (type:tuple)
- vector([1,2,3,4]는 (4,)로 표현 colunm의 갯수
- matrix([[1,2,3,4][5,6,7,8]])은 (2,4)로 axis가 뒤로 하나씩 밀림
.dtype: numpy array의 data type을 반환
※ 참고) float64에서 64는 64bit를 의미함. 하나의 데이터 공간이 64bit → 8byte (8bit = 1byte).ndim: number of dimensions.size: data의 갯수
★중요★ Numpy array와 list의 차이점
1. memory 할당 방법
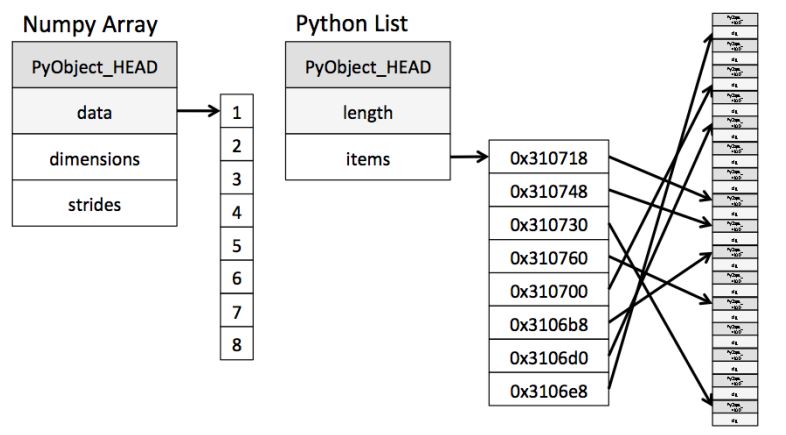
- Numpy Array : 데이터가 memory 임의의 공간에 차례대로 할당됨 → 데이터가 붙어있어서 연산이 좋아짐. 같은 위치끼리만 더하면 되니까 memory 접근성이 좋음
- Lsit : -5 ~ 256의 값이 memory 임의의 static한 공간에 존재함. 따라서 list 값 공간에 해당 주소값을 저장하게 되어 포인터로 한번 더 들어가야함. → 이래서 list는 값을 변환하는 것은 쉬움. 해당 주소값만 바꿔주면 되니까
- 따라서
is로 같은 숫자를 비교하면,
- list는 다른 list끼리의 같은 숫자를is로 비교하면 memory 주소값이 동일하기때문에 True가 나온다.- 하지만 ndarray 에서는 같은 숫자라도 새롭게 값을 할당하기 때문에 memory 값이 달라 False가 나오게 됨
2. memory 계산 용이
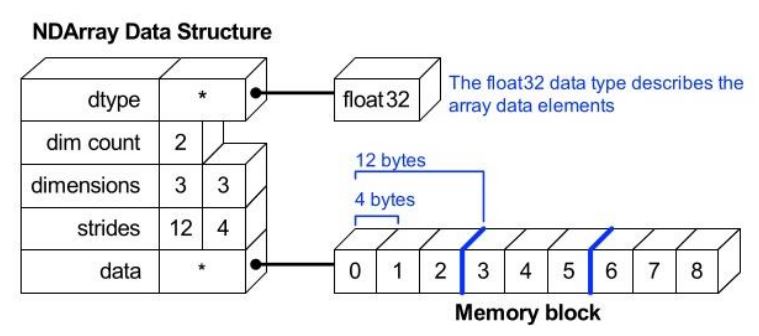
- 연산시 메모리의 크기가 일정하니 데이터 저장공간을 잡는 것도 훨신 효율적임
Array dtype
- daynamic typing not supported!
- ndarray의 single element가 가지는 data type
- 각 element가 차지하는 memory의 크기가 결정됨
- C의 data type과 compatible함
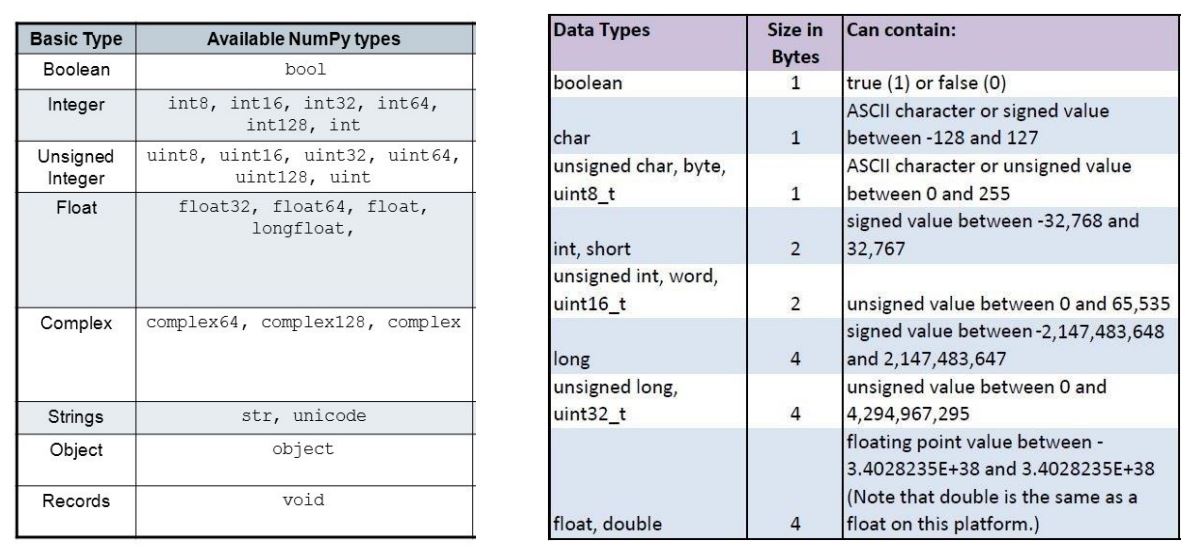
※ 참고) 64bit가 표현할 수 있는 수는? ±2^63개 - .nbytes : ndarray object의 memory 크기를 반환(사실 볼일 거의 없음)
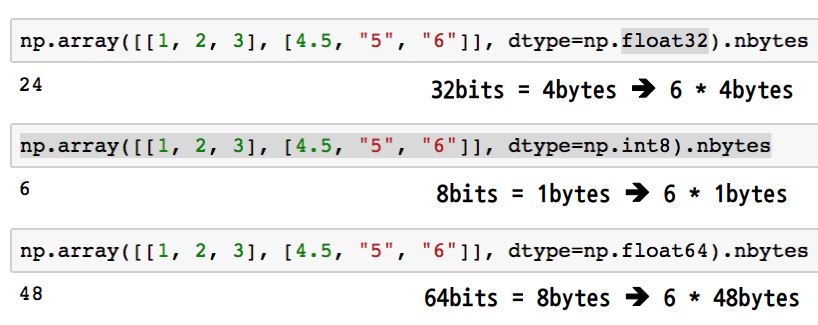
- 딥러닝은 parameter가 억단위가 되니 크기가 어마무시함!
메모리가 적게 차지하는 것이 무조건 좋은 것은 아님. 보통float64를 사용함
Handling Shape
reshape
.reshape(): Array의 shape 크기를 변경함. element 갯수는 동일.reshape(-1, 2): reshape에서 고정하고 싶은 값이 있을 때(이경우 2) 나머지를 -1로 설정하면 size를 기반으로 -1 값을 새로 설정함
.flatten(): 다차원 array를 1차원 array로 변환
Indexing & slicing
-
index for numpy array
- list와 달리 2차원 배열에서 [0,0] 표기법 제공
array[0,0]==array[0][0] - matrix의 경우 앞은 row, 뒤는 column을 의미
- list와 달리 2차원 배열에서 [0,0] 표기법 제공
-
slicing for numpy array
-
list와 달리 행과 열 부분을 나눠서 slicing이 가능함 (= 중간값 slice가능)
-
matrix의 부분 집합을 추출할 때 용이
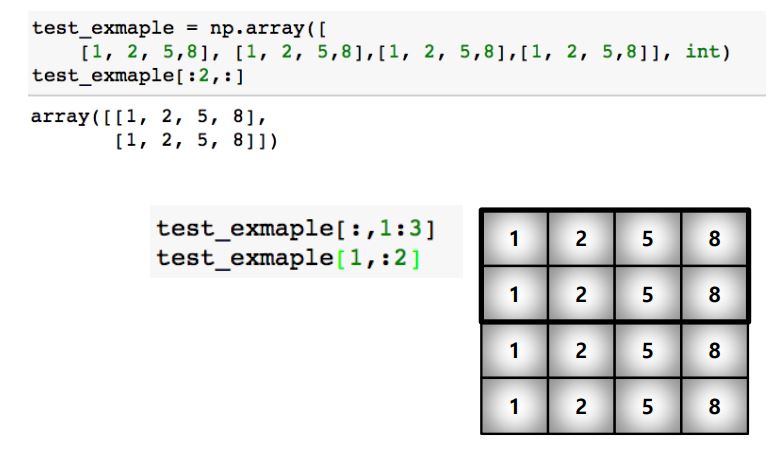
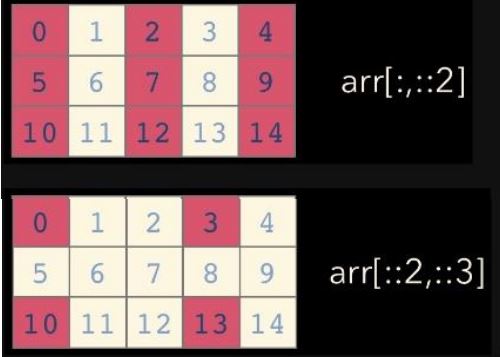
이런식으로 step을 가지고 추출하는 것도 가능함
Creation function
.arange(시작, 끝, step): array 범위를 지정하여 값의 list를 생성.zeros(shape): 0으로 가득찬 ndarray 생성.ones(shape): 1로 가득찬 ndarray 생성empty: shape만 주어지고 비어있는 ndarray 생성
(memory initialization이 되지 않음 = 자리만 주고 값은 할당하지 않음)
그래서 그 memory에 전에 썻던 값이 있으면 그게 그대로 출력됨 신기방기
-something_like(기존 ndarray) : 기존 ndarray 크기만큼 1(something -> ones), 0(something -> zeros), empty(something -> empty) arry 반환
.identity(shape): 단위행렬 생성- `.eye(행렬사이즈, k = 시작값) : 대각선이 1인 행렬, k값의 시작index 변경가능
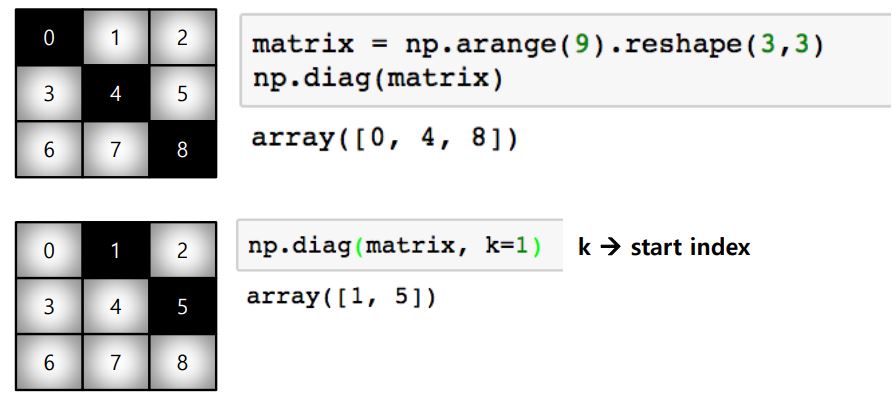
.diag(matrix): 대각 행렬의 값을 추출함
.random.분포(시작, 끝, 갯수).reshape: 데이터 분포에 따른 sampling으로 array 생성 (균등 분포 - uniform, 정규분포 - normal)
Operation functions
.sum(): ndarray element간의 합을 구함. list의sum(list)와 동일
-.mean(): 평균np.std(array): 표준편차np.sqrt(array): 루트!
등등 다양함np.concatenate((ar1, ar2), axis): ndarray를 axis에 맞춰 붙히는 함수
(axis는 붙혔을 때 생성되는 결과값의 axis라고 생각하면 편함). 두 ndarray의 shape이 동일해야함!array[np.newaxis, :]: 값은 그대로에 축을 하나 늘릴 때 사용.- `np.vstack(ar1, ar2) : 수직으로 붙힘
- `np.hstack(ar1, ar2) : 수평으로 붙힘
★중요★ axis
- 모든 operation function을 실행할 때 기준이 되는 dimension 축
- 새로 생기는 축은 항상 axis = 0이 되고 나머지는 뒤로 하나씩 밀림

해당 축 방향으로 계산한다는 것!!!!!!!!!!!
Array operation
- numpy array간의 기본적인 사칙 연산 지원!
- Element-wise operation임! Array간 shape이 같을 때 일어나는 연산 기법
ar1.dot(ar2): matrix의 기본 연산, Dot productar1.transpose()orar1.T: transpose 전치함수 → 행렬 계산시 많이 사용함- broadcasting : shape이 다른 배열간 연산을 지원하는 기능.
Scalar - Vector 외에도 Vector - Matrix간의 연산도 지원

참고) Numpy performance
%timeit: jupyter환경에서 코드의 퍼포먼스를 체크하는 함수
def sclar_vector_product(scalar, vector):
result = []
for value in vector:
result.append(scalar * value)
return result
iternation_max = 100000000
vector = list(range(iternation_max))
scalar = 2
%timeit sclar_vector_product(scalar, vector) # for loop을 이용한 성능
%timeit [scalar * value for value in range(iternation_max)]
# list comprehension을 이용한 성능
%timeit np.arange(iternation_max) * scalar # numpy를 이용한 성능- 일반적으로 속도는 for loop < list comprehension < numpy
- 100,000,000번의 loop가 돌 때, 약 4배 이상의 차이를 보임
- Numpy는 C로 구현되어 있어, 성능을 확보하는 대신 파이썬의 가장 큰 특징인 dynamic typing을 포기
- 대용량 계산에서 가장 많이 사용됨
- Concatenate 처럼 계산이 아닌, 할당에서는 연산 속도의 이점이 없음

- 실제 계산시 Numpy의 위력을 확인할 수 있었다.
Comparisons
- numpy array끼리 비교하는 것
array < n처럼 표기하고, array 값 각각을< n을 비교하며 array 갯수만큼 True of False 출력 (broadcasting 처리됨)np.any(조건): 하나라도 조건에 만족하면 True (or 개념)np.all(조건): 모두가 조건에 만족한다면 True (and 개념)- numpy는 배열의 크기가 동일할 때 element간 비교의 결과를 Boolen type으로 반환
ex) ar1, ar2 가 동일 shape이면,ar1 > ar2&(ar1 > ar2).any()가능 np.logical_and(조건1, 조건2): 두개의 조건의 and 비교로 Boolen 출력 (and 대신 or, not도 가능함)np.where(조건, true시 출력값, false시 출력값): 조건에 맞는 값 반환np.where(조건): 조건에 맞는 값의 index 반환np.isnan(array): Not a Number(NaN)값 있는지 확인np.isfinite(array): 발산하는 값(memory를 넘어가는 값)을 찾음np.argmax(arr)&np.argmin(arr): array내 최대값, 최소값의 index를 반환함
Boolen & Fancy Index
- boolean index
- 특정 조건에 따른 값을 배열 형태로 추출
- Comparison operation 함수들도 모두 사용가능
array[array 조건]으로하면 조건이 True인 index의 element만 추출- 원래 array와 boolen array의 크기가 같아야함
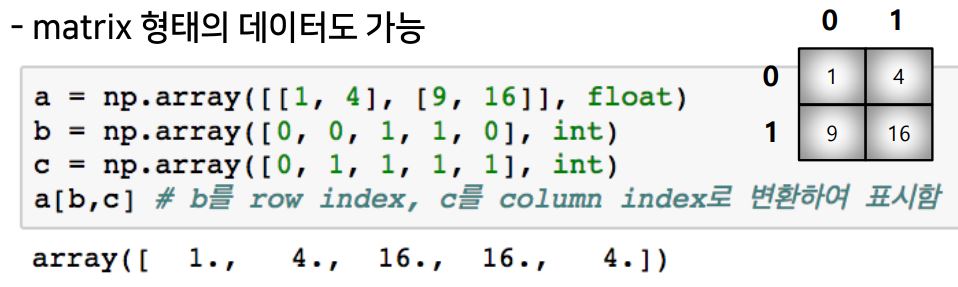
- Fancy Index
- numpy는 array를 index value로 사용해서 값을 추출함
- 반드시 integer list 사용함!
- 두 array의 크기가 동일하지 않아도 되지만, index로 사용되는 array의 값은 상대 array의 range를 벗어나면 안됨

Numpy data in/out
- loadtxt & savetxt : text type의 데이터를 읽고 저장하는 기능
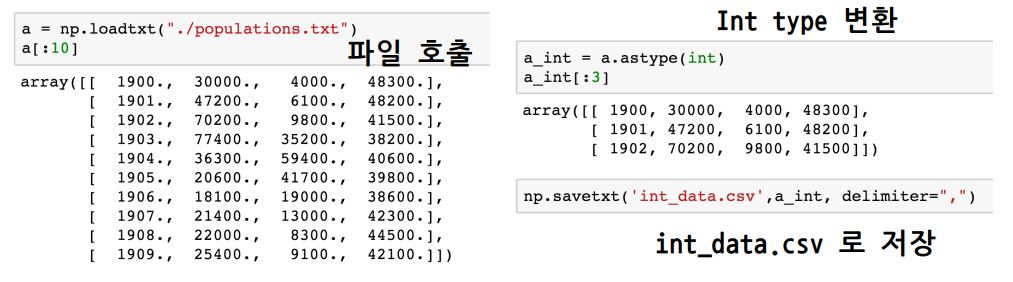
delimiter: 데이터를 자르는 기준fmt = %.2e: 소숫점 2째자리까지 저장- numpy object의 형태인
.npy로 저장 가능. pickle type

차보의 Data Engineer 도전기♥ (근데 기록을 곁들인)