저는 참고 자료에 적힌 책을 바탕으로 개념을 정리하고 있습니다. 해당 파트는 5-2에 해당됩니다.
참고 자료
📚 딥러닝 교과서, 출판사: 이지스 퍼블리싱
목차
신경망 학습할 때는 최적화에 좋은 위치에서 출발하도록 추기화를 잘하는 것과 최적해로 가는 길을 잘 찾을 수 있도록 정규화(Regularization) 하는 것이 중요하다.
정규화는 최적화 과정에서 최적해를 잘 찾도록 정보를 추가하는 기법으로 최적화 과정에서 성능을 개선하는 기법을 포함합니다.
일반화 오류
일반화(generalization)란 훈련 데이터가 아닌 새로운 데이터에 대해 모델이 예측을 얼마나 잘 하는지를 의미합니다.
모델의 성능이 좋다는 말은 일반화가 잘 되었다는 것을 의미합니다.
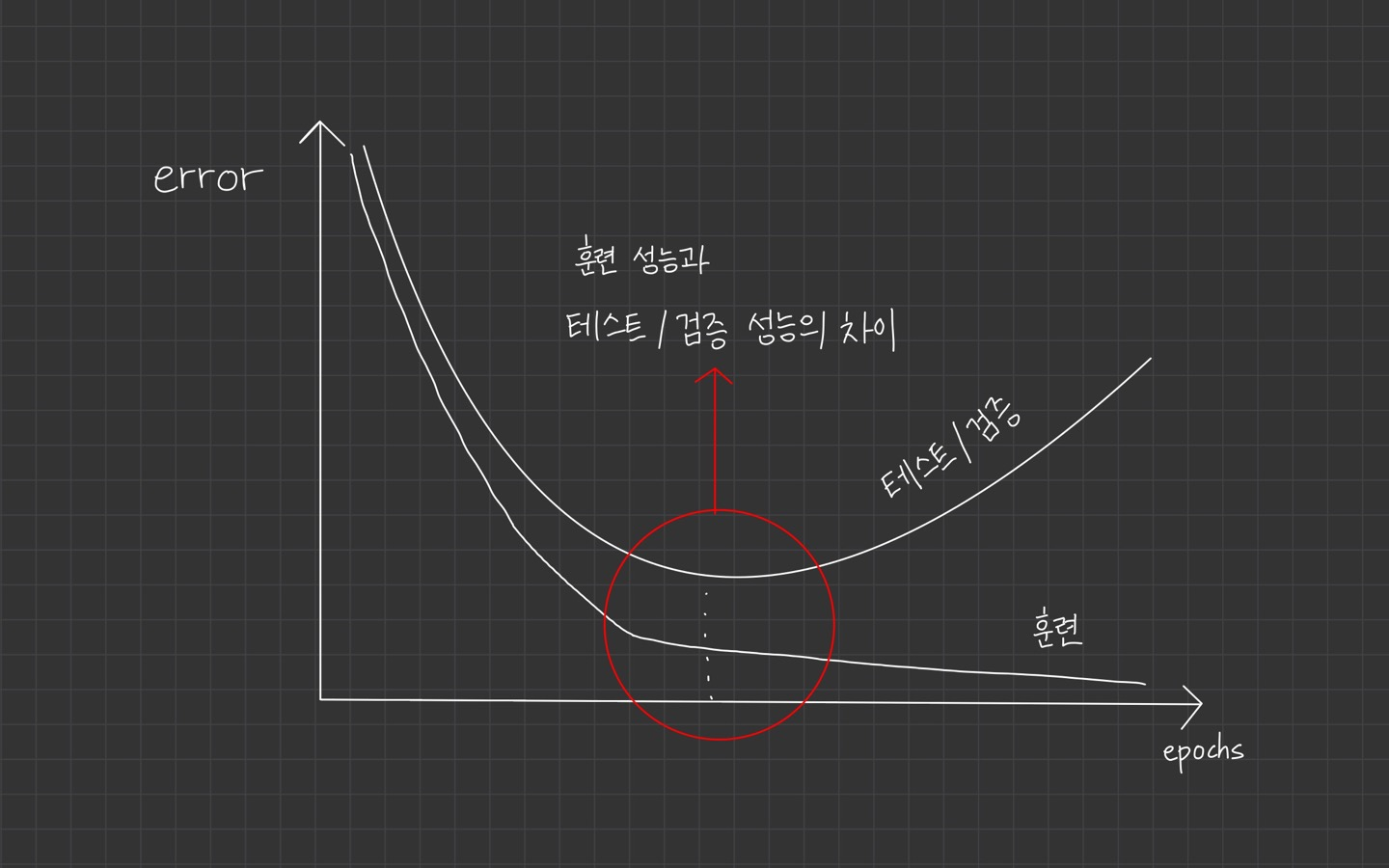
모델의 train 성능과 validation/test 성능의 차이를 일반화 오류(generalization error)라고 합니다.
일반화 오류가 적을 수록 일반화가 잘 된 모델입니다.
두 성능의 차이가 작아야 모델이 훈련 데이터에 과적합되지 않고 새로운 데이터에 대해 일반화를 잘하는 모델이 됩니다.
정규화는 일반화를 잘 하는 모델을 만드는 기법이라고도 합니다.
참고 이미지
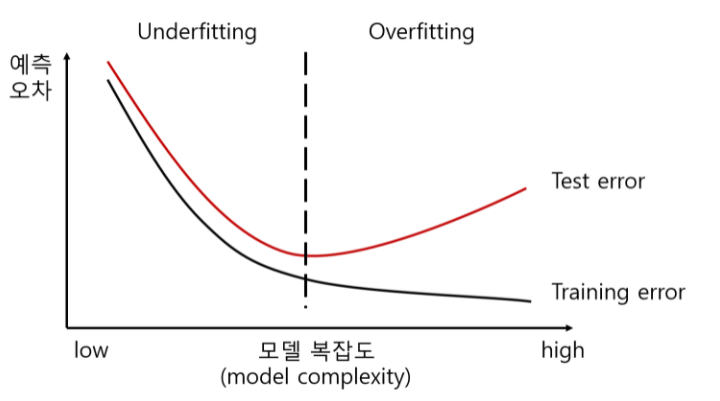
신경망은 모델이 크고 복잡해서 parameter 공간이 크고 학습 데이터가 많이 필요합니다.
과적합 되는 경우를 막기 위해 반드시 정규화가 필요합니다.
정규화 접근 방식
책에선 총 4가지를 설명하고 있습니다.
1. 모델을 최대한 단순하게 만든다.
단순한 모델은 복잡한 모델보다 파라미터 수가 적어서 과적합이 덜 생깁니다.
학습 과정에서 필요한 가중치만 남기고, 필요하지 않은 가중치는 0이 되도록 만들면 과적합을 막을 수 있습니다.
정규화 기법이 여기에 해당됩니다.
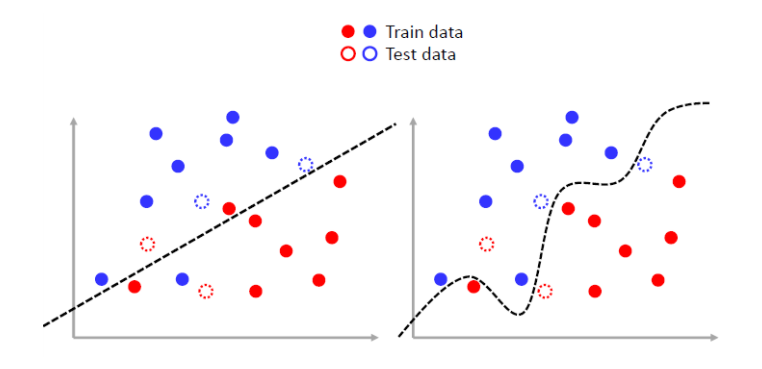
2. 사전 지식을 표현해서 최적해를 빠르게 찾도록 한다.
데이터나 모델에 대한 사전 분포를 이용해 빠르게 해를 찾는 방법입니다.
가중치 감소는 가중치의 사전 분포를 손실 함수의 일부 항으로 표현해서 가중치의 크기를 조절하는 정규화 기법입니다.
*전이 학습이나 메터 학습과 같이 미리 학습한 모델의 파라미터로 초기화해서 세부 튜닝하는 학습 방법도 사전 지식을 표현한 방법입니다.
3. 확률적 성질을 추가한다.
데이터 또는 모델, 훈련 기법 등에 확률 성질을 부여하여 조금씩 변화된 형태로 데이터를 처리함으로써 다양한 상황에서 학습하는 효과를 줍니다.
정확한 해를 찾을 수 있고 모델이 잡음에 대해 민감하게 반응하지 않습니다.
*데이터 증강, 잡음 주입, 드롭아웃 등이 해당됩니다.
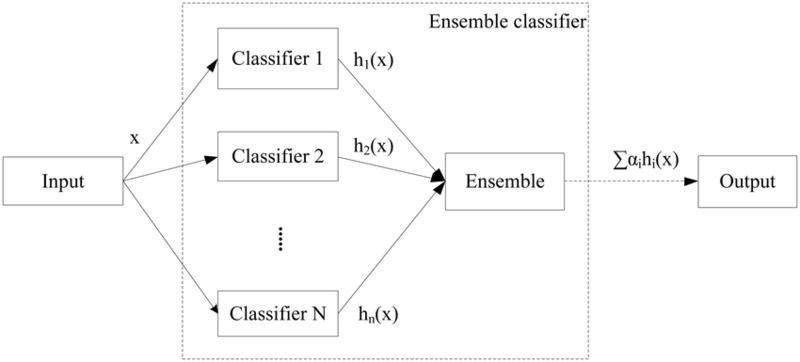
4. 여러 가설을 고려하여 예측한다.
하나의 모델로 예측하지 않고 여러 모델로 동시에 예측해서 그 결과에 따라 최종 예측하는 방식입니다.
모델이 가지는 편향을 제거하여 오차를 최소화합니다.
*앙상블 기법 중 하나인 배깅이 해당됩니다.
이렇게 정규화에 대해 간단히 소개를 하고 뒤에 배치 정규화, 가중치 감소, 학습 조기 종료, 데이터 증강, 배깅, 드롭아웃, 잡음 주입 등에 살펴보는 것 같습니다.
