Reference
seq2seq with Attention을 이해하기 위해 포스팅합니다. 위 reference를 바탕으로 내용을 이해하고 정리하였습니다.
재생산되는 제 내용 중 오류가 있을 수 있습니다. 그럴 경우 댓글로 알려주시면 감사하겠습니다.
또한, LSTM을 사용한 seq2seq에 대해 먼저 이해를 하고 싶으시다면 Sequence to Sequence model 해당 포스팅을 참고해주세요. 감사드립니다.
Seq2Seq Model
Seq2Seq Model이 무엇인지 먼저 이해하고 가면 좋을 듯 합니다.
단어나 문자, 시계열 등 일련의 항목을 가져와서 다른 sequence를 출력하는 모델입니다.
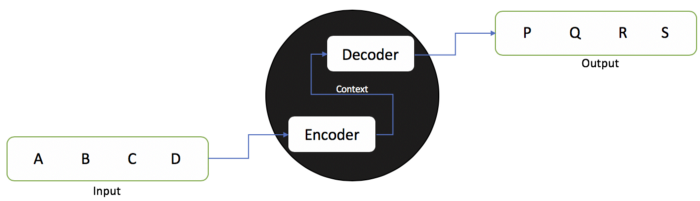
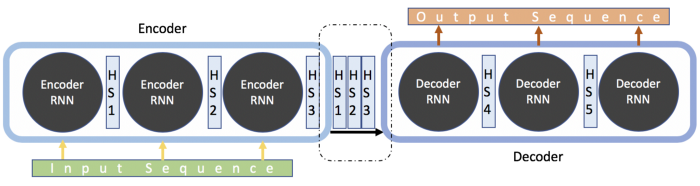
모델은 encoder와 decoder로 구성됩니다.
encoder은 hidden state vector 형태로 input sequence의 context를 포착하고, decoder로 흘려 보내 output sequence를 생성합니다.
이 모든 과정은 sequence를 기반으로 진행합니다.
따라서 RNN, LSTM, GRU 등의 형식을 사용하는 경향이 있습니다.
hidden state vector는 size에 상관없이 사용할 수 있지만, 대부분의 경우 2의 거듭제곱으로 간주됩니다. (256, 512, 1024, ...)
RNN
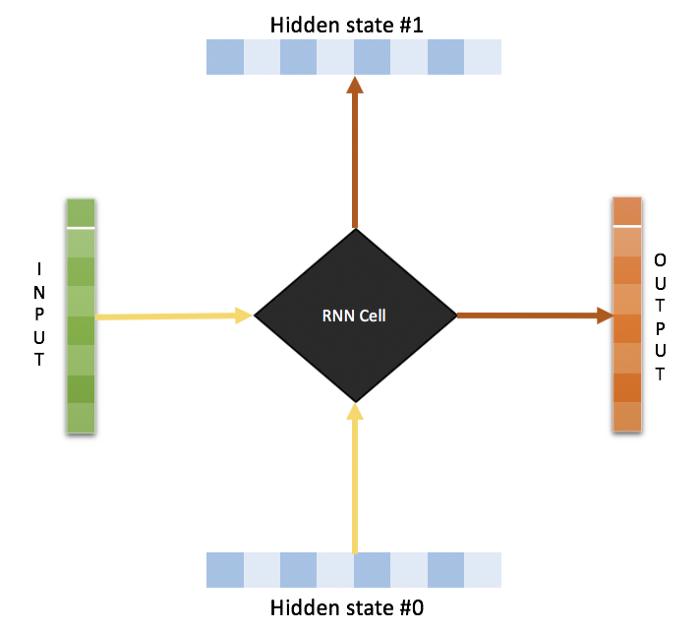
그림으로만 보면 RNN은 2개의 input을 가집니다.
현재 받는 값과 이전 input의 representation을 받는 것이죠.
그럼 time step t에서의 output은 현재 input과 의 입력에 따라 달라집니다.
이런 sequential한 정보는 network의 hidden state로 보존되어서 다음 instance에서 사용됩니다.
RNN으로 구성된 encoder는 sequence를 input으로 사용하고, sequence 끝에 최종 imbedding을 생성합니다.
그런 다음 decoder는 이를 사용하여 sequence를 예측하고 모든 연속을 예측한 다음에 이전 hidden state를 사용하 sequence의 다음 instance를 예측합니다.
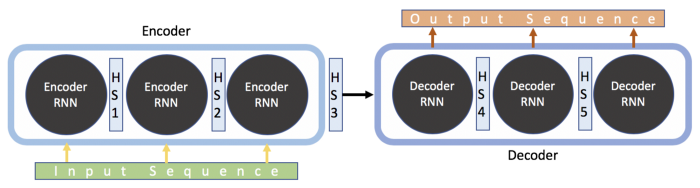
output sequence는 encoder의 최종 출력에서 hidden state에 의해 정의된 context에 크게 의존하기 때문에 model이 긴 문장을 처리하지 못합니다.
sequence가 길어질수록 초기의 context가 손실되기 때문입니다.
이런 방법을 해결하기 위해 Attention이라는 기술이 도입되어 모델이 output sequence의 모든 step에서 input sequence의 다른 부분에 초점을 맞춰 context를 보존하는 방법을 사용했습니다.
Attention
Now I’m getting your ATTENTION! 이라네요. ㅎㅎ 저도 관심 좀 주세요...
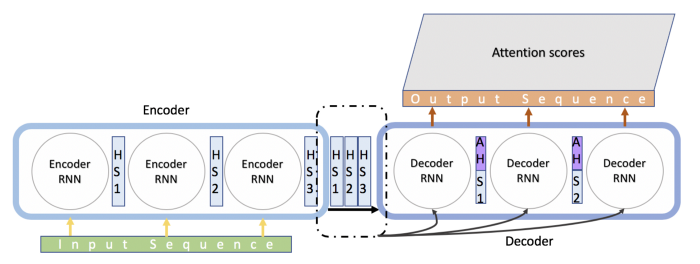
앞의 내용을 간단히 정리하자면, 결론적으로 encoder의 끝에 있는 single hidden state vector가 충분하지 않다는 것이 문제였습니다.
그래서 새로운 방법은 input sequence의 수만큼 많은 hidden state vector를 보내는 것입니다!
decoder는 hidden state vector를 어떻게 사용할까요?
지금까지 두 model의 유일한 차이점은 decoding 단계에서 모든 input instance의 hidden state를 도입했다는 점 뿐인데요.
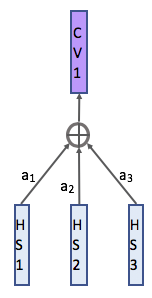
Attention 기반 model을 만드는데 추가된 또 다른 기능은 context vector입니다.
이것은 output sequence의 모든 time instance에 의해 생성되는데요.
모든 step에서 context vecotr는 아래와 같이 hidden state의 weighted sum입니다.
이제 두 가지 질문이 나옵니다.
- context vector는 어떻게 이용하는 것인지?
- weight 1, 2, 3은 어떻게 결정되는 것인지?
context vector는 hidden state vecotr와 결합되고, 새로운 attention hidden vector는 해당 시점의 output을 예측하는데 사용됩니다.
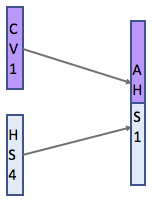
그렇다면 어떻게 score를 예측할까요?
이것은 초기에 seq2seq 모델과 함께 훈련된 다른 neural network model인 alignment model의 출력입니다.
alignment model은 input(represented by its hidden state)이 이전 output (represented by attention hidden state)과 얼마나 잘 일치하는지 점수를 매기고, 모든 input에 대해 이전 output과 일치시킵니다.
그런 다음 softmax가 모든 점수에 적용되고 각 입력에 대한 attention score가 나오게 됩니다.
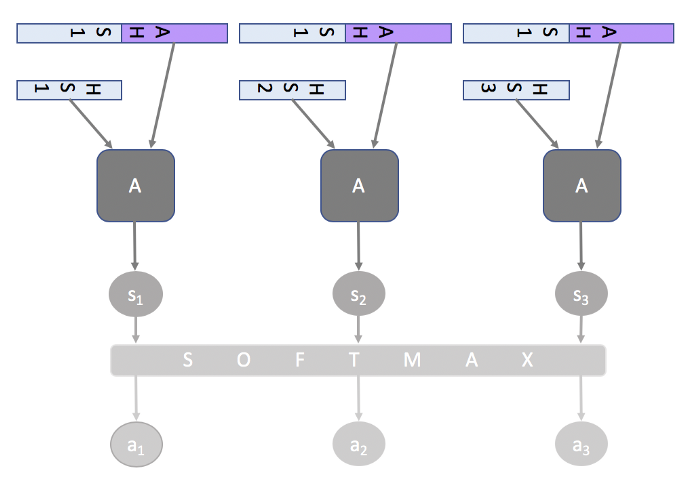
따라서 이제 output sequence의 각 instance를 예측하는데 input의 어느 부분이 가장 중요한지 알 수 있습니다.
training 단계에서 model은 output sequence에서 input sequence로 다양한 instance를 정렬하는데요.
아래 그림은 matrix 형태로 표시된 machine translation의 예시입니다.
각 항목은 input 및 output sequence의 attention score입니다.

이제 최종적으로 완전한 모델이 완성됩니다.
Seq2Seq Attention Based Model
Summary
여기서 새롭게 나온 keyword 등은
context vector, alignment model, attention score
등이 있었습니다.
해당 개념에 대해 이해하려고 노력하다 보면, attention mechanism을 이해하는데 더 도움이 될 것 같습니다.
