0. 목차
- Perceptron
- 경사하강법
- 데이터 처리
- Validation
- Stochastic Gradient Descent
- Data Scaling
1. Validation
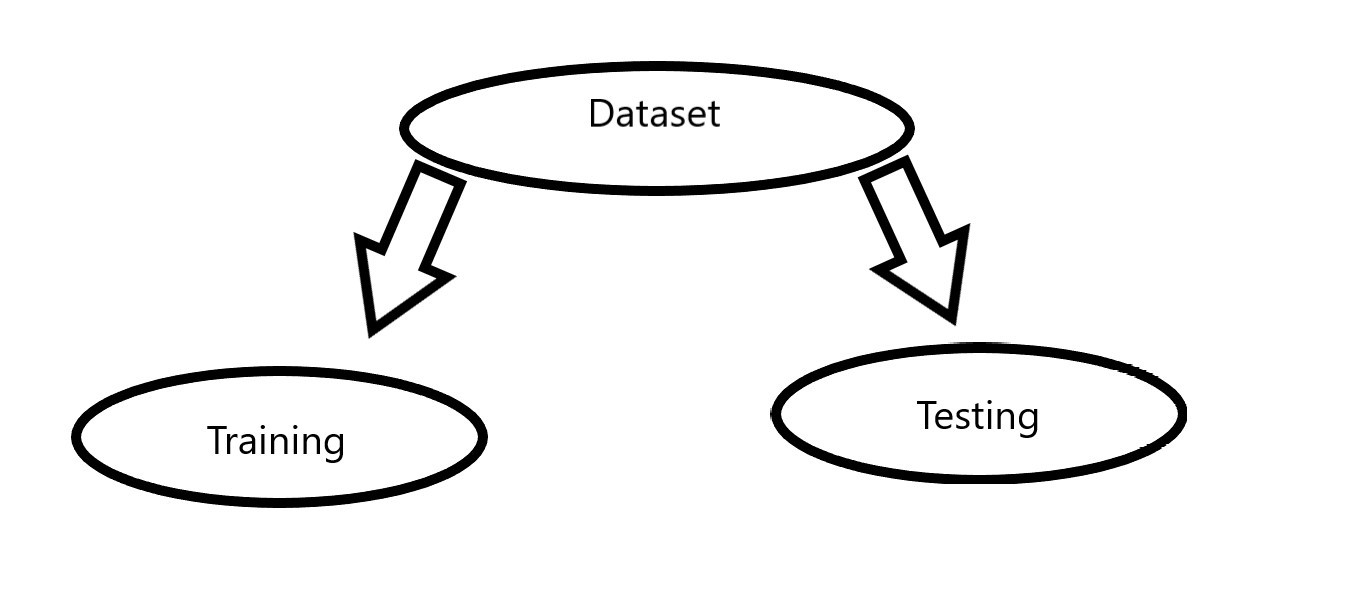
전체 데이터셋이 있다면 학습하기 위한 train set, 성능을 확인하기 위한 test set으로 7:3, 8:2 나눕니다.
근데 test set으로만 성능을 점검하면 성능이 잘 안 나올 수 있습니다.
이걸 방지하기 위해서 random하게 data를 섞지만 그래도 train set에 data가 편향되게 갈 수도 있고, trian set이 학습을 너무 잘해버리는 경우 test set에서는 성능이 잘 안 나올 수 있습니다.
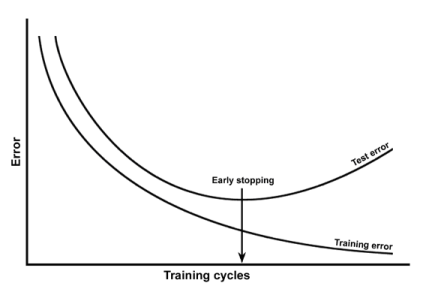
위의 그래프를 보면 y축이 Error로 Loss 값을 의미합니다.
training error는 학습하면서 점점 줄어드는데 Test error는 어느 순간부터는 Loss 값이 증가하기 시작합니다.
왜냐하면 model이 train set에만 맞게 학습을 하기 때문에 어느 순간부터는 너무 train set에만 맞게 되어 버립니다.
그래서 여기서는 Loss 값이 증가해버리는 test set 지점을 찾아서 학습을 시켜야 합니다.
지금은 dataset을 train, test set으로 나누었는데 또 하나의 방법은
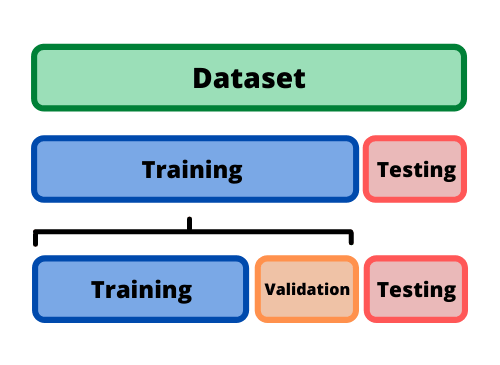
training, validation, testing set으로 나누는 방법이 있습니다.
- train set으로 학습을 시킴
- validation을 통해 test set 성능이 잘 나오는 구간을 찾음
- 마지막으로 성능을 점검할 때 test set 사용
모델 검증(validation)과 오버피팅(Overfitting)
- Train, Test dataset 둘로 나누어 학습된 모델을 평가한다.
- Train, Validation, Test set으로 나누고 Validation dataset으로 모델을 선택하고, Test dataset으로 모델의 성능을 평가한다.
그러면 training error와 validation error의 차이가 가장 적은 부분의 모델을 체크해두고 test set으로 성능을 평가하는 방식을 이용하면 된다.
2. Stochastic Gradient Descent
Stochastic Gradient Descent은 확률적 경사하강법이라고도 한다.
이 방법은
- 전체 데이터셋을 Mini batch size로 나누어 단계별로 가중치를 업데이트 하는 학습 방식
이다.
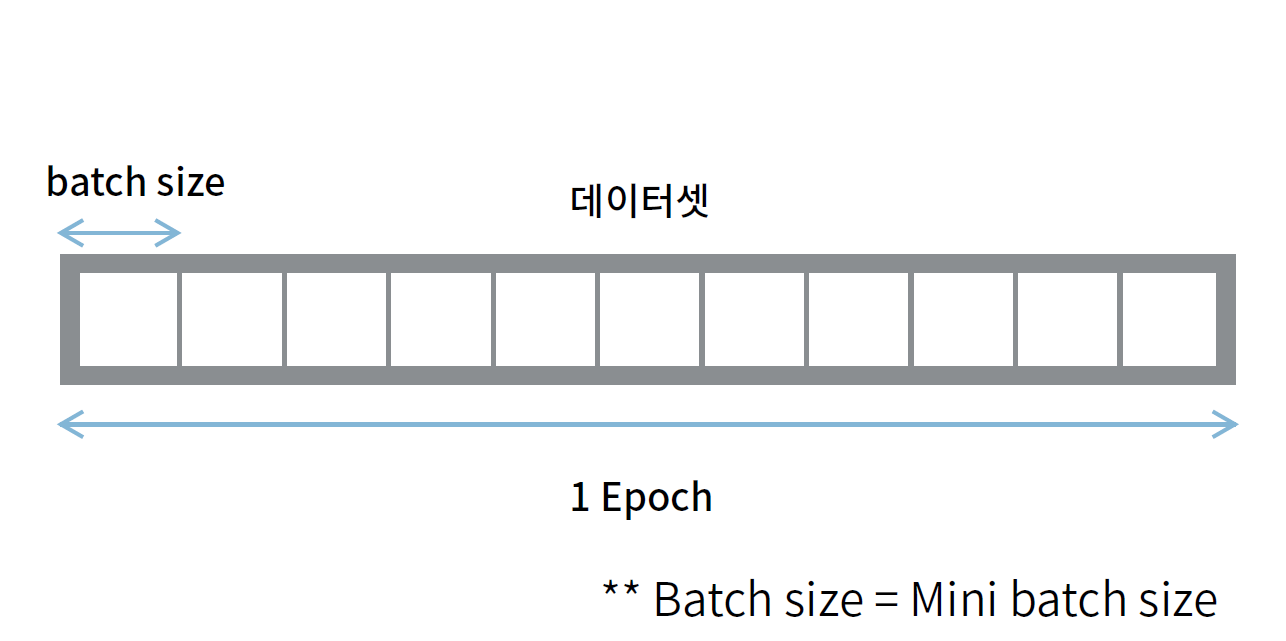
위의 그림을 보자.
전체 dataset을 정해둔 batch size만큼 나눈다.
그리고 단계별로 가중치를 업데이트하면서 학습 시킨다.
그러면 1부터 11까지 가중치를 업데이트 한다.
dataset이 110개라면 10개씩 나누어진 data이고, 이 10개를 batch size or mini batch size라고 한다.
여기서 11은 iteration이라고 반복 횟수라고 한다.
그리고 11번 학습시키면 1 Epoch 학습했다라고 얘기한다.
Epoch의 경우 1번만 학습하는 것이 아니라 100번, 128번 등까지 학습이 가능하다.
1번만으로 weight 값을 global minima로 한 번에 도달하는 것이 아니기 때문에 반복적으로 학습한다.
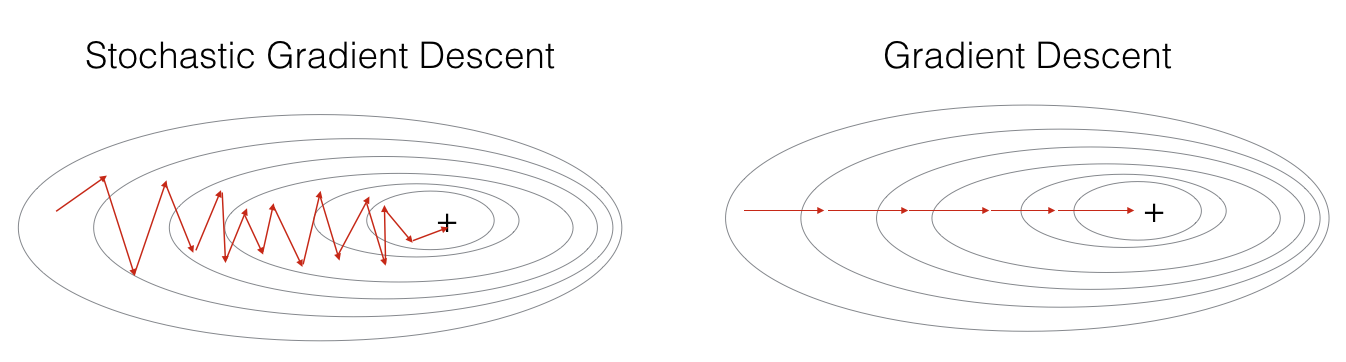
그래서 해당 그림을 보면 Stochastic Gradient Descent는 원하는 지점에 더 빠르게 도착한다고 한다.
3. Data Scaling
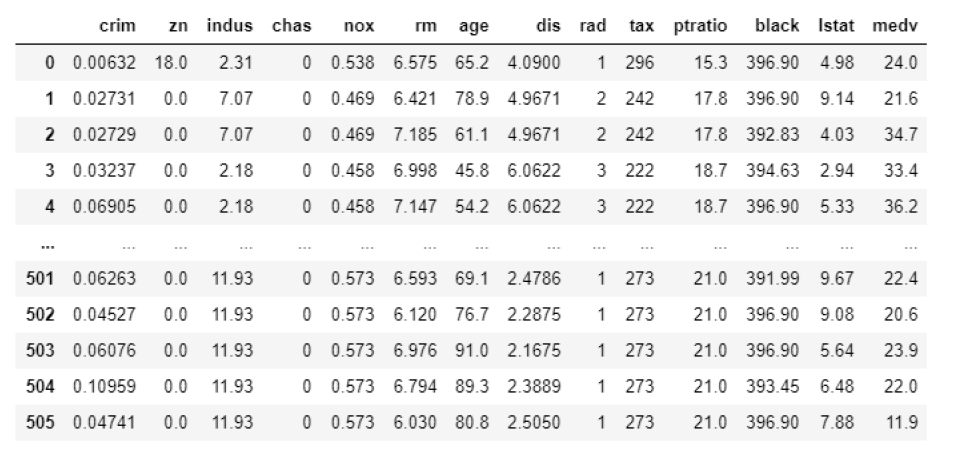
위의 표를 보면 nox column의 경우 0.xx 값을 갖고 있고,
black column을 보면 390대의 값을 갖고 있다.
데이터 스케일링이란 위처럼 데이터 자체의 크기가 매우 다른 경우에 이를 방지하기 위해 조절해주는 방법을 말한다.
- 절댓값이 큰 변수가 학습에 영향을 크게 미치는 것을 방지
- 각 변수들이 동일한 조건을 갖게 한 뒤 학습에 사용
- column별로 변환해 사용
- Scikit-learn 라이브러리 사용
스케일링 방식
스케일링은 Scikit-learn 라이브러리 사용할 예정이다.
Scikit-learn 머신러닝 모델이 많이 들어 있는 라이브러리이다.
1. StandardScaler
- 데이터의 평균을 0, 분산을 1로 변환
- μ: 평균
- σ: 표준편차
2. MinManScaler
- 데이터의 값을 모두 0과 1 사이의 값으로 변환
이렇게 스케일링하는 방법까지 알아보았다.
