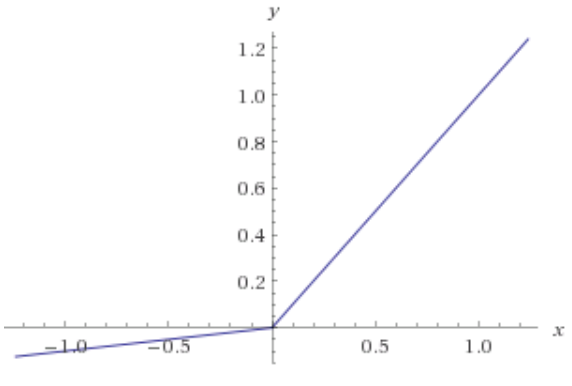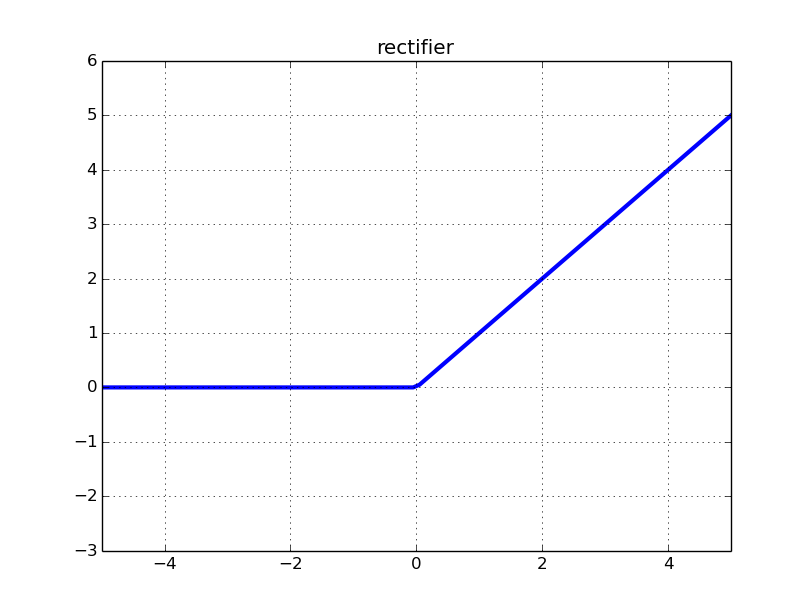
ReLU(Rectified Linear Unit)의 그래프입니다.
일부 input에 대한 rectifier의 입력 가 있습니다.
Weight 을 위해 이전 layer의 특정 입력 입력 를 로부터 활성화합니다.
rectifier neuron function은
입니다.
error을 굉장히 simple하게 추정한다면
로 볼 수 있습니다.
여기서 가 헷갈렸는데, layer의 activation function이 ReLU일 경우에 예측된 y의 값입니다.
rectifier은 backpropagation algorithm의 에 대해 오직 2개의 gradient values 값만 가집니다.
ReLU의 왼쪽 부분은 "기울기 = 0"으로 전혀 작동하지 않음을 알 수 있습니다.
입력 에 대해 현재 가중치가 ReLU를 왼쪽 평평한 면에 배치하고,
이 특정 입력에 대해 최적으로 오른쪽에 있어야 한다면 어떻게 될까요?
gradient가 0이므로 가중치가 업데이트되지 않습니다.
이 경우 "learning"은 어디에 있을까요?
답의 핵심은 Stochastic Gradient Descent가 단일 입력 뿐만 아니라 많은 입력을 고려합니다.
모든 입력이 ReLU의 flat한 쪽에 가지 않기를 바라고, gradient는 몇몇의 inputs에 0이 되지 않도록 합니다.
적어도 하나의 input 가 steep side에 ReLU를 갖고 있다면, 여전히 학습이 진행 중이고 이 뉴런에 대한 가중치가 업데이트되기 때문에 ReLU는 여전히 살아 있습니다.
모든 입력을 ReLU를 flat side에 두면, 가중치가 바뀌지 않고, 모든 뉴런이 죽습니다.
ReLU는 가중치를 더 작은 값으로 만들어 모든 입력에 대해 이 되도록 하는 일부 input batch에 대한 gradient step로 인해 살아 있다가 죽을 수 있습니다.