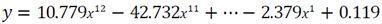저는 해당 책과 ppt 자료를 바탕으로 포스팅하였습니다. 자세한 내용은 책과 ppt 자료를 참고하시면 감사하겠습니다.

이전 참고 글
규제
규제 기법은 다양하다. 이 책에서는 chapter5의 3장, 5장에서 이를 다루고 있다. 그중 가중치 규제, earlystopping, data augmentation, dropout, ensemble을 소개 중이다.
하지만 이번 포스팅에서 다루는 규제 내용은 chapter1의 6장이며 규제의 필요성과 규제 기법 전략, 효과를 간단하게 정리할 예정이다.
1. 데이터 확대
일반화 능력을 향상 시키는 가장 좋은 방법은 데이터를 더 많이 수집하는 것이다.
[그림1-17]을 보면 (a)의 경우 overfitting이 심하지만 train set의 크기가 점점 커질 수록 일반화 능력이 향상되고 있다.
하지만 문제점은 데이터 수집은 비용이 가장 많이 드는 일이다. 사람이 일일이 어떤 부류인지 레이블(label)을 붙여야 할 수도 있다.
데이터를 추가로 수집하기 어려운 상황에서 사용하는 방법은 train set에 있는 sample을 변형시켜 인위적으로 데이터를 augmentation(확대)하는 방법이 있다.

위 그림을 통해 예를 들면, 데이터를 살짝씩 회전 시켜서 변형 sample을 늘리고 있다. 물론 이 데이터의 경우 아예 상하 반전할 경우 다른 데이터가 되므로 주의하여야 한다. (6과 9)
Data augmentation이라 하며, 이동, 회전, 크기, wrapping, noise 추가 등의 방법이 있다.
Data augmentation에 대해 정리한 포스팅이 있습니다!
2. 가중치 감쇠
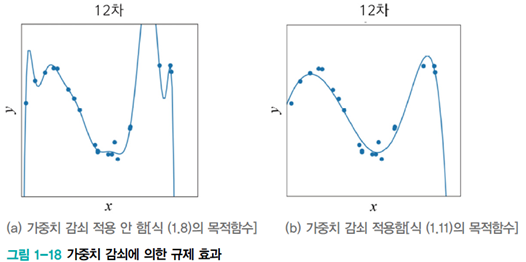
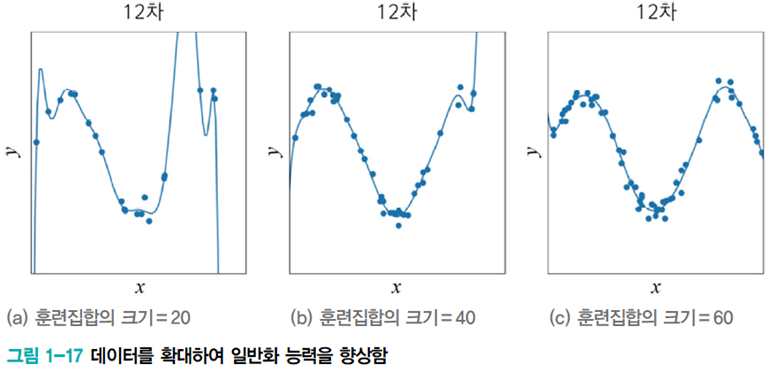
해당 그림에서 [그림(a)]는 곡선이 매우 굴곡이 심하다. 다시 말해 극점에서 curvature이 매우 크다. 아래는 기계 학습이 찾은 이 곡선의 방정식이다.
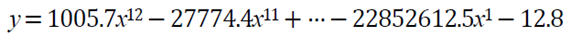
잘 살펴보면 매개변수가 무척 크다는 사실을 알 수 있다. 이는 weight가 크다고 말할 수 있다.
여기서 가중치 감쇠(weight decay) 규제 기법은 wieght를 작게 유지함으로써 일반화 능력을 향상시킨다.

weight decay 방법은 [식1.11]을 cost function으로 사용한다. 첫 번째 항은 이전과 마찬가지로 오류를 줄이는 역할을 한다. 두 번째 항은 weight의 크기를 나타내는데 weight가 클수록 큰 값을 가진다.
최적화 알고리즘은 두 항을 더한 값을 최소화하는 방법으로 학습을 진행하므로 결국 오류가 적으면서 계수가 작은 해를 찾아 준다. [그림 1-18(b)]의 매끈한 곡선으로 확인할 수 있다.
[그림 1-18(b)]의 weight는 아래의 식처럼 줄어든 것을 확인할 수 있다.