
저는 해당 책과 ppt 자료를 바탕으로 포스팅하였습니다. 자세한 내용은 책과 ppt 자료를 참고하시면 감사하겠습니다.

이전 참고 글
모델 선택
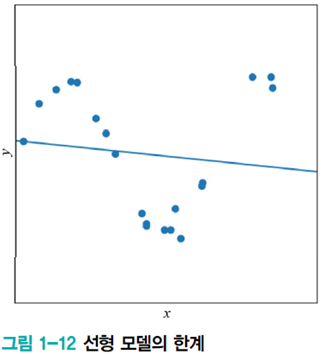
[그림1-12]에서 선형 모델을 선택한 의사결정은 잘못되었다. 모델을 잘못 선택했을 때 나타나는 현상, 적절한 모델 선택 방법, 모델 선택의 한계, 등을 다룰 예정이다.
위 그림이 최적해를 찾더라도 큰 오차가 생기는 이유는 모델의 용량이 적기 때문이다. 직선 모델은 단지 데이터가 직선을 이루는 경우만 수용할 수 있다.
과소적합과 과잉적합
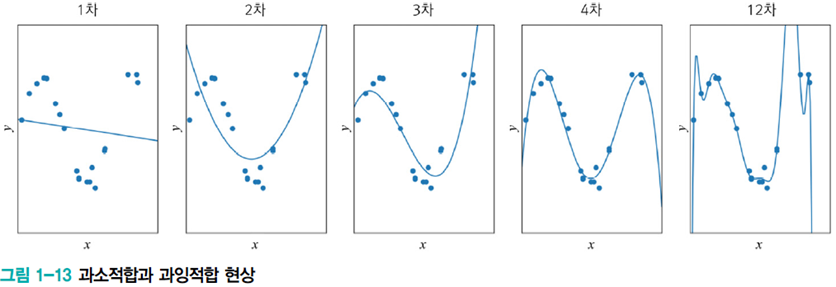
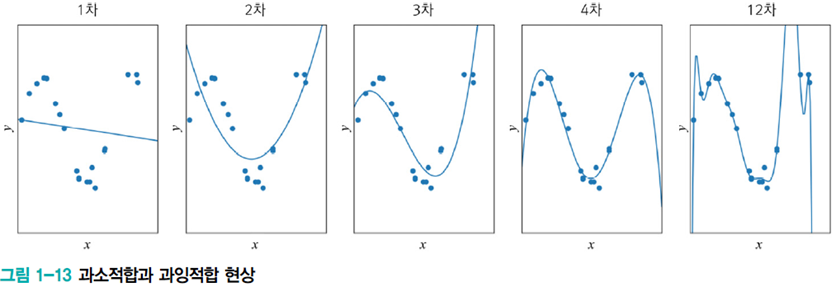
위 [그림1-13]의 1차 모델은 과소적합(underfitting)이다. 쉽게 생각할 수 있는 해결 방법은 더 높은 차원의 다항식, 즉 비선형 모델(nonlinear model)을 사용하는 방식이다.
2차, 3차, 4차, 12차는 다항식 곡선을 선택한 예는 1차(선형)에 비해 오차가 크게 감소하긴 한다.
하지만 12차 다항식을 선택했을 경우, 1차 미분이 0인 극점(extreme point)이 최대 11개인 복잡한, 용량이 큰 모델이 나온다. 용량이 커진다는 것은 추정해야 하는 매개변수가 많아진다는 의미이다. 매개변수는 w1, w2, ..., w12으로 13개나 되어 모델 학습이 어려워진다.
12차 다항식이 train set에 대해 완벽하게 근사화하지만 새로운 데이터를 예측해야 할 때 큰 문제가 발생한다.
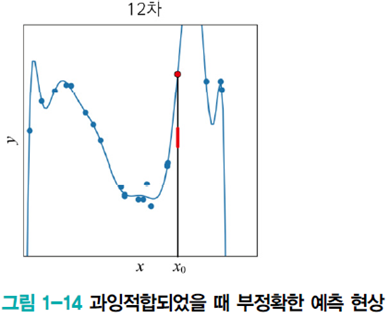
x0에서 빨간 막대 근방을 예측해야 하는 경우지만 빨간점을 예측한다. 잡음을 수용하지 못하는 것이다. 이런 현상을 과잉적합(overfitting)이라고 한다.
여기서 알 수 있는 점은 적절한 용량의 모델을 선택하는 모델 선택 작업이 필요하다는 것이다.
정리
- 1~2차는 훈련집합과 테스트집합 모두 낮은 성능
- 12차는 훈련집합에 높은 성능을 보이나 테스트집합에서는 낮은 성능 → 낮은 일반화 능력
- 3~4차는 훈련집합에 대해 12차보다 낮겠지만 테스트집합에는 높은 성능 → 높은 일반화 능력
바이어스(bias)와 분산(variance)
기계학습의 목표는 train set에 없는 test set에 대해 높은 성능을 보장하는 프로그램을 만드는 것, 일반화 능력을 높이는 것이다.
12차 다항식 모델은 아주 높은 성능을 보이지만 test set에서는 낮은 성능을 보일 것이다. 즉, train과 test set 성능 차이에 큰 차이가 있다. 이를 generalization 능력이라 한다.
1, 2차도 train, test set에서 낮은 성능을 보일 것이다. 그러므로 3, 4차가 train, test set에서 가장 비슷한 성능을 보여주어 적절한 모델로 선택할 수 있다.
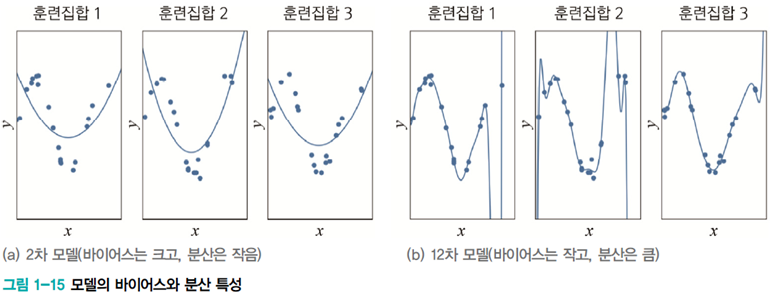
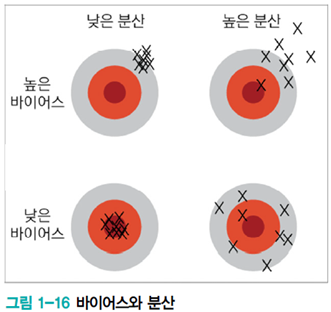
[그림1-15]는 train set을 세 번 수집한 후, 훈련집합 각각에 대해 2차 모델과 12차 모델을 학습 시킨 결과를 보여준다. 데이터 생성 과정과 2차 다항식 모델 사이에 큰 차이가 있음을 알 수 있다. 이런 현상을 bias가 크다고 표현한다. 세 가지 train set 모두 데이터와 학습된 모델 사이 큰 차이가 있어, 2차 모델은 bias가 크다고 말할 수 있다.
반면, train set이 바뀌더라도 훈련 결과로 얻은 곡선은 비슷하다. 이를 variance가 작다고 표현한다.
12차는 반대로 bias가 작고 variance가 크다고 말할 수 있다.
일반적으로 용량이 작은 모델은 bias는 크고, variance는 작다. 복잡한 모델은 bias는 작고, variance는 크다.
bias와 variance는 trade-off 관계임을 알 수 있다.
기계 학습의 목표
- 낮은 bias와 낮은 variance를 가진 predicor를 만드는 것
- 하지만 bias와 variance는 trade-off 관계를 가지므로 결국 bias의 희생을 최소로 유지하며 variance를 최대로 낮추는 전략이 필요하다.
validation set
지금까지는 train set으로 모델을 학습하고, test set으로 학습된 모델의 일반화 능력을 측정하였다. 좋은 모델을 알고 있다면 문제없지만, 그렇지 않다면 모델 집합의 여러 모델을 독립적으로 학습시킨 후 그중 가장 좋은 모델을 선택해야 한다.
이때 모델을 비교하는 데 사용할 별도의 데이터가 필요한데, 이 데이터 집합을 validation set이라고 한다.
validation을 이용한 model selection 과정
- 모델을 train set으로 학습시킨다.
- validation set으로 모델의 성능을 측정한다.
- 가장 높은 성능을 보인 모델을 측정한다.
- test set으로 선택된 모델의 성능을 측정한다.
cross validation
여기서 cross validation 개념이 등장한다. 데이터 수집 비용 문제로 별도의 validaion set이 없는 상황에 유용한 모델을 선택하는 방법이다.
train set을 등분하여 train, test 과정을 여러 번 반복한 다음에 평균을 사용한다.
cross validation을 이용한 model selection 과정
- train set을 k개의 그룹으로 등분한다.
- i번째 그룹을 제외한 k-1개 그룹으로 모델 학습
- 학습된 모델의 성능을 i번째 그룹으로 측정
- k개 성능을 평균하여 해당 모델의 성능으로 취한다.
- 가장 높은 성능을 보인 모델을 선택한다.
- test set으로 선택된 모델의 성능을 측정한다.
모델 선택의 한계와 현실적인 해결책
현실에서는 모델이 아주 다양하다.
- 신경망(3,4,8장), 강화 학습(9장), 확률 그래피컬 모델(10장), SVM(11장), 트리 분류기 (12장) 등이 선택 대상
- 신경망을 채택하더라도 MLP(3장), 깊은 MLP(4장), CNN(4장) 등 아주 많음
실제로는 주로 경험 지식을 통해 큰 틀을 선택하고 그 틀 안에서 세부 모델을 선택하는 전략을 사용한다. 예를 들어, MLP를 사용하기로 한 후 hidden layer의 개수, activation function은 무엇으로 할지 등 결정하는데 알고리즘이 필요하다.
현대 Machine Learning은 용량이 충분히 큰 모델을 선택한 후, 선택한 모델이 정상을 벗어나지 않도록 여러 가지 규제 기법을 적용하는 현실적인 접근방법을 사용 중이다.
특히 딥러닝에서는 규제 기법이 더욱 중요하다. 다음 포스팅은 규제 기법에 대해 포스팅할 예정이다.
