저는 해당 책과 ppt 자료를 바탕으로 포스팅하였습니다. 자세한 내용은 책과 ppt 자료를 참고하시면 감사하겠습니다.

Machine Learning 개념
Machine Learning(기계학습)의 개념을 간단한 예로 알아보겠다.
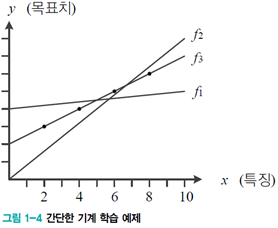
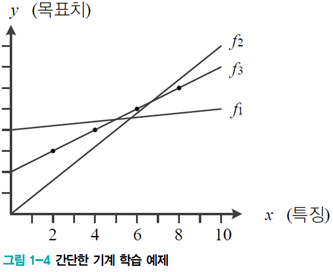
[그림1-4]에서 가로축은 시간, 세로축은 이동체의 위치라 가정한다. 시간을 나타내는 가로축에서 2.0, 4.0, 6.0, 8.0인 점을 샘플링하여 이동체의 위치를 측정한 결과, 3.0, 4.0, 5.0, 6.0인 값 4개를 얻었다. 이때 임의의 시간에 대한 이동체의 위치를 예측하는 문제가 있다.
prediction(예측) 문제
- 임의의 시간이 주어지면 이때 이동체의 위치는?
- 회귀(regression) 문제와 분류(classification) 문제로 나뉨
- [그림1-4]처럼 실숫값을 예측하는 것이 regression, 아래 그림처럼 숫자 필기 인식 문제는 10가지 부류 중 하나를 예측하는 것으로 classification이라고 한다.
train set(훈련 집합)
- 가로축은 특징, 세로축은 목표치로 볼 수 있다.
- 여기서 특징은 feature, 목표치는 target value라고 한다.
- feature를 x, value를 y로 표현한다.
[그림1-4]는 feature가 하나 뿐이지만 대부분 2개 이상의 특징으로 구성되는 feature vector 형태를 가진다. 그래서 x는 단순히 scala 값이 아닌 벡터 𝕏로 생각하면 된다.
여기서는 𝕏={𝐱_1=(2.0),𝐱_2=(4.0), 𝐱_3=(6.0), 𝐱_4=(8.0)}, 𝕐={𝑦_1=3.0, 𝑦_2=4.0, 𝑦_3=5.0, 𝑦_4=6.0}로 training set을 구성할 수 있다. training set은 아래와 같이 표기한다.
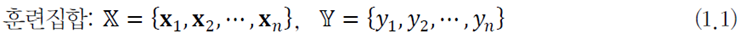
modeling
- 눈대중으로 보면 직선을 이루므로 직선을 선택하자 → 모델로 직선을 선택했다.
- 직선 모델의 수식은 2개의 매개변수 w, b로 표현될 수있다.

Machine Learning은 가장 정확하게 예측할 수 있는, 즉 최적의 매개변수를 찾는 작업이다.
처음에는 최적값을 모르므로 임의의 값에서 시작해, 점점 성능을 개선해서 최적에 도달한다.
이렇게 최적에 도달하는 작업을 learing(학습) 또는 train(훈련)이라 한다.
[그림 1-4]의 예에서는 f1에서 시작하여 f1→f2→f3, 최적인 f3은 w=0.5와 b=2.0이다.
train이 끝나면
- 학습된 모델을 이용해 예측할 수 있다.
- 예) 10.0이라는 시간에서 이동체의 위치를 알고 싶으면 f3(10.0)=0.5*10.0+2를 계산하여 7.0을 출력할 수 있다.
이처럼 train set에 없는 new sample에 대한 value를 예측하는 과정을 test라고 한다.
최종 목표는 train set에 없는 new sample에 대한 error를 최소화하는 것이다. 여기서 new sample을 가진 데이터를 test set이라고 하는데, test set에 대해 높은 성능을 가진 성질을 일반화(generalization) 능력이라 부른다.
그리고 train set과 test set을 합쳐 database라 한다.
