stackoverflow와 youtube 영상의 출처는 아래에 있습니다.
Data Normalization은 데이터의 범위를 사용자가 원하는 범위로 제한하는 것을 의미합니다.
Question
Why do we have to normalize the input for an artificial neural network?
I understand that sometimes, when for example the input values are non-numerical a certain transformation must be performed, but when we have a numerical input? Why the numbers must be in a certain interval?
What will happen if the data is not normalized?
위 글은 출처 [1]의 원문입니다.
스택오버플로우는 error명 그대로 검색하면 항상 구글링 상위에 있는 사이트입니다! 프로그래밍 언어 공부하다보면 금방 만나는 사이트일 것 같은데, 개발자들 사이의 지식in 같은 것이 아닐까 생각합니다. 전 아직 직접 질문을 남겨본 적은 없지만요!
원문에 남긴 댓글을 살펴보면 진짜 설명을 잘해주셨습니다.
이해가 잘 되었던 답변 정리
Answer 1
In neural networks, it is good idea not just to normalize data but also to scale them. This is intended for faster approaching to global minima at error surface. See the following pictures:
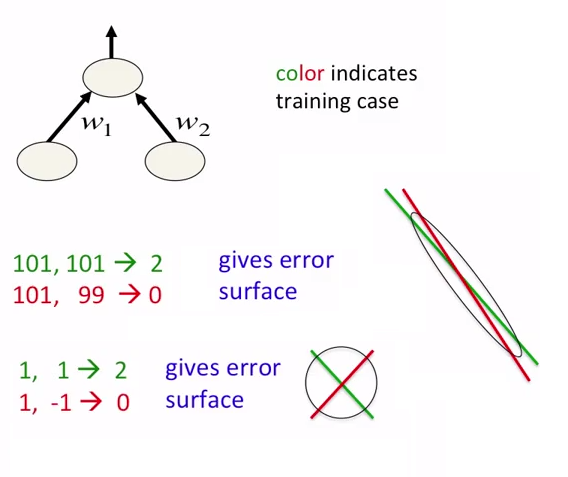
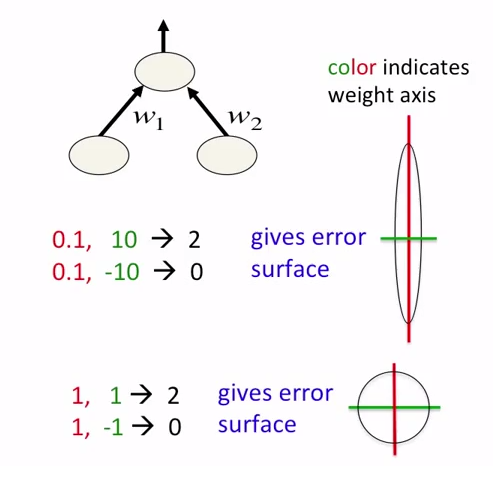
neural network를 학습할 때 데이터를 정규화하는 것 뿐만 아니라 데이터를 늘리는 것도 좋은 방법입니다.
학습이 더 빨라지고 local optimum(minimum)에 빠지는 것을 방지합니다. global minima에 다가가는 것이 목표이기 때문이겠죠. 그림을 통해 더 잘 이해할 수 있습니다!
Answer 2
Some inputs to NN might not have a 'naturally defined' range of values. For example, the average value might be slowly, but continuously increasing over time (for example a number of records in the database).
In such case feeding this raw value into your network will not work very well. You will teach your network on values from lower part of range, while the actual inputs will be from the higher part of this range (and quite possibly above range, that the network has learned to work with).
You should normalize this value. You could for example tell the network by how much the value has changed since the previous input. This increment usually can be defined with high probability in a specific range, which makes it a good input for network.
이 답변은 정규화했을 때, 높은 확률로 값의 변화가 특정 범위에서 네트워크에 좋은 input으로 정의될 수 있다고 설명하고 있습니다.
Answer 3
There are 2 Reasons why we have to Normalize Input Features before Feeding them to Neural Network:
Reason 1: If a Feature in the Dataset is big in scale compared to others then this big scaled feature becomes dominating and as a result of that, Predictions of the Neural Network will not be Accurate.
Example: In case of Employee Data, if we consider Age and Salary, Age will be a Two Digit Number while Salary can be 7 or 8 Digit (1 Million, etc..). In that Case, Salary will Dominate the Prediction of the Neural Network. But if we Normalize those Features, Values of both the Features will lie in the Range from (0 to 1).
Reason 2: Front Propagation of Neural Networks involves the Dot Product of Weights with Input Features. So, if the Values are very high (for Image and Non-Image Data), Calculation of Output takes a lot of Computation Time as well as Memory. Same is the case during Back Propagation. Consequently, Model Converges slowly, if the Inputs are not Normalized.
Example: If we perform Image Classification, Size of Image will be very huge, as the Value of each Pixel ranges from 0 to 255. Normalization in this case is very important.
Mentioned below are the instances where Normalization is very important:
- K-Means
- K-Nearest-Neighbours
- Principal Component Analysis (PCA)
- Gradient Descent
여기서는 두 가지 이유와 각각의 예시를 보여주고 있고, 정규화가 어디서 중요한 지 아래 1~4을 통해 알려주고 있습니다.
첫 번째 이유는 데이터셋의 feature가 엄청 큰 경우에 큰 스케일을 가진 feature가 영향이 커서 예측이 정확하지 않다는 지적입니다.
예로는 직원 데이터가 있고 거기엔 나이, 월급이 있는데 나이는 두 자리 수이지만 월급 같은 경우는 단위가 백만입니다. 그래서 이 두 feature의 값을 0부터 1까지 사이의 수로 정규화를 시켜주는 겁니다.
두 번째 이유는 Front Propagation할 때 가중치의 내적이 포함되고, 계속 곱해지기 때문에 모델이 계산하는데 너무 오래 걸린다는 점입니다. 이건 Back Propagation할 때도 마찬가지입니다.
그 예시로 이미지 분류를 예시로 들었는데, 이미지의 픽셀의 값이 0부터 255까지이기 때문에 이미지 사이즈가 매우 커질 것입니다. 그래서 이미지 분류 같은 경우엔 정규화가 필요합니다.
K-means와 K 근접 알고리즘, PCA, Gradient Descent 같은 경우도 Normalization가 중요합니다!
[1] 🔗Why do we have to normalize the input for an artificial neural network?
[2] 🔗Neural Networks - Normalizing inputs
