이제 SR Resolution 문제를 접근하는 방식 중 Deep Learning-based method를 살펴보겠습니다.
논문 "Image Super-Resolution Using Deep Convolutional Networks"에서 SRCNN을 발표했습니다.
위는 논문 제목처럼 Super Resolution Convolutional Neural Networks의 앞글자를 따서 SRCNN이라고 불립니다.
이는 3개의 layer만 사용하는 매~우 간단한 모델 구조임이었음에도 불구하고, 아주 좋은 성능 향상을 이뤄냈습니다! 그 이후엔 어떻게 되었을까요? layer를 겁나 쌓았겠죠?
아무튼 SRCNN을 봅시다!
SRCNN
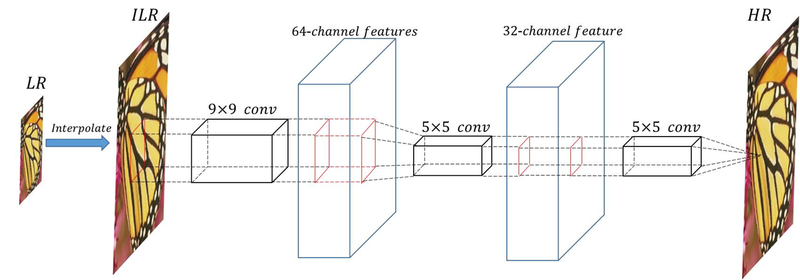
가장 먼저 저해상도 이미지(LR)을 bicubic interpolation하여 원하는 크기로 이미지를 늘립니다.
SRCNN은 이미지를 input으로 사용합니다. 이후 3개의 Conv layer를 거쳐 고해상도 이미지를 output합니다!
생성된 고해상도 이미지와 실제 고해상도 이미지 사이의 차이를 역전파하여 신경망의 가중치를 학습합니다.
최근 발표되는 수 백 개 이상의 Conv layer를 갖는 CNN과 비교한다면 SRCNN은 매우 간단합니다.
위에 소개했던 SRCNN 논문을 잘 리뷰해둔 블로그를 공유합니다. (당장 보러가기👉클릭)
SRCNN의 연산 방법
- Patch extraction and representation
저해상도 이미지에서 patch를 추출한다. 이 patch들은 특징을 갖습니다.
- Non-linear mapping
Patch를 다른 차원의 patch로 비선형 매핑한다.
- Reconstruction
Patch로부터 고해상도 이미지를 생성한다.
SRCNN의 Loss function
학습 시킬 때 사용하는 loss function은 MSE입니다.
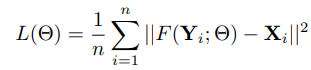
y_i는 예측값이며, X_i는 실제값 똔느 라벨을 의미합니다. n은 훈련 샘플의 개수를 의미합니다.
MSE는 딥러닝 모델에 많이 쓰이는 function으로 평균 제곱 오차값이라고도 합니다. 전체적인 학습 효과에는 좋지만 이후 high frequency의 특징들을 잘 못잡아내서 다른 loss function을 사용하는 SR 딥러닝 모델이 나오게 되었습니다.
