SRCNN 이후 정말 많은 Super Resolution 연구가 이뤄졌습니다. CNN 발전 과정과 크게 다르지 않다고 합니다. SR뿐만 아니라 많은 cv 분야에서 사용되는 방법과 유사합니다.
VDSR (Very Deep Super Resolution)
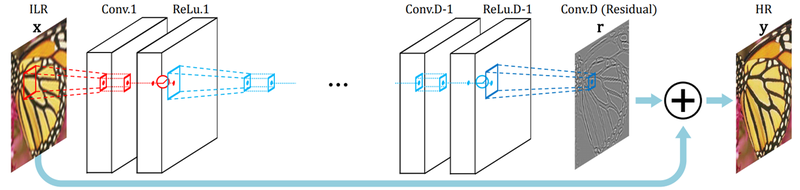
SRCNN과 동일하게 interpolation을 통해 저해상도의 이미지의 크기를 늘려 input으로 사용합니다.
3개보다 더 많은 20개의 Conv layer를 사용했고, 최종 고해상도 이미지 생성 직전에 처음 입력 이미지를 더하는 residual learning을 이용했습니다.
SRCNN보다 더 깊은 구조를 이용해 더 큰 성능 향상을 이끌어 냈다고 합니다!
RDN (Residual Dense Network)
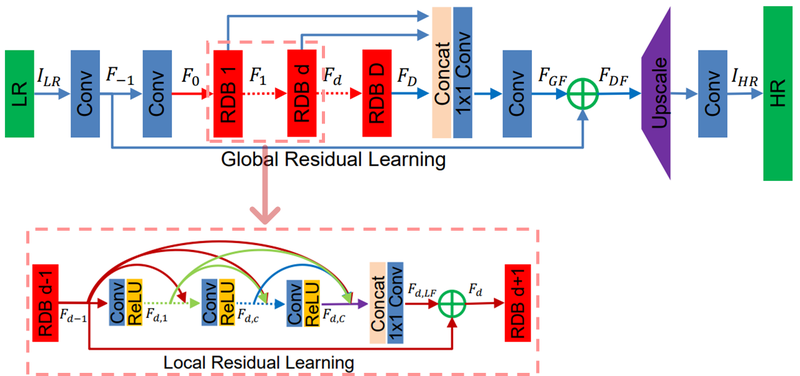
RDN은 저해상도 이미지가 입력되면 여러 단계의 Conv layer를 거치고 layer에서 나오는 출력 결과로 생성된 특징들이 화살표를 따라 이후 연산에서 다시 활용됩니다.
한 곳에서 나온 화살표가 여러 곳을 향하고 있는 것을 볼 수 있습니다.
RCAN (Residual Channel Attention Networks)
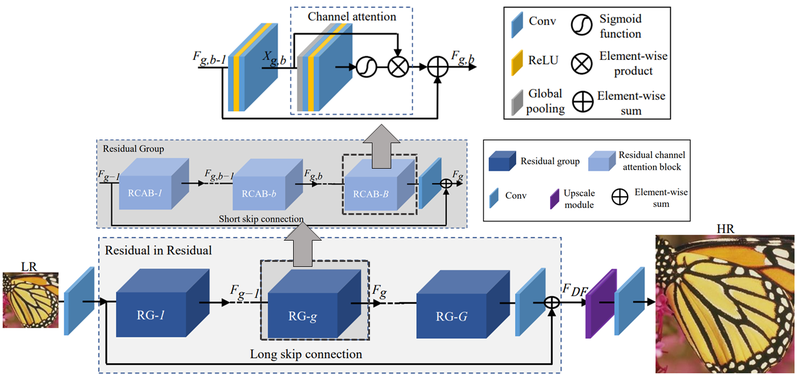
RCAN 구조 또한 많은 convolutional layer를 거치며 학습합니다. 위 구조와 다른 점은 Conv layer의 결과인 각각의 feature map을 channel 간의 모든 정보가 균일한 중요도를 갖는 것이 아니라 일부 중요한 채널에만 선택적으로 집중하도록 유도하였습니다.
이런 방법을 Channel attention이라 하며, CNN Attention을 검색해보면 RCAN과 비슷한 구조의 attention 기술을 찾아볼 수 있습니다.

AI/ML Engineer