참고 자료 출처: 딥러닝을 이용한 자연어 처리 입문
목차
- 트랜스포머 구현하기
- 트랜스포머 하이퍼파라미터 정하기
- 손실 함수 정의하기
- 학습률
트랜스포머 구현하기
이제 지금까지 구현한 인코더와 디코더 함수를 조합하여 트랜스포머를 조립할 차례입니다!
인코더의 출력은 디코더에서 인코더-디코더 어텐션에서 사용되기 위해 디코더로 전달해줍니다.
그리고 디코더의 끝단에는 다중 클래스 분류 문제를 풀 수 있도록, vocab_size 만큼의 뉴런을 가지는 신경망을 추가해줍니다.
def transformer(vocab_size, num_layers, dff, d_model, num_heads, dropout, name='transformer'):
# 인코더의 입력
inputs = tf.keras.Input(shape=(None, ), name='inputs')
# 디코더의 입력
dec_inputs = tf.keras.Input(shape=(None, ), name='dec_inputs')
# 인코더의 패딩 마스크
enc_padding_mask = tf.keras.layers.Lambda(
create_padding_mask, output_shape=(1,1,None),
name='enc_padding_mask')(inputs)
# 디코더의 룩어헤드 마스크(첫 번째 서브층)
look_ahead_mask = tf.keras.layers.Lambda(
create_look_ahead_mask, output_shape=(1,None,None),
name='look_ahead_mask')(dec_inputs)
# 디코더의 패딩 마스크(두 번째 서브층)
dec_padding_mask = tf.keras.layers.Lambda(
creat_padding_mask, output_shape=(1,1,None),
name='dec_padding_mask')(inputs)
# 인코드의 출력은 enc_outputs. 디코더로 전달된다.
enc_outputs = encoder(vocab_size=vocab_size, num_layers=num_layers,
dff=dff, d_model=d_model, num_heads=num_heads, dropout=dropout,
)(inputs=[inputs, enc_padding_mask]) # 인코더의 입력은 입력 문장과 패딩 마스크
# 디코더의 출력은 dec_outputs. 출력층으로 전달된다.
dec_outputs = decoder(vocab_size=vocab_size, num_layers=num_layers,
dff=dff, d_model=d_model, num_heads=num_heads, dropout=dropout,
)(inputs=[dec_inputs, enc_outputs, look_ahead_mask, dec_padding_mask])
# 다음 단어 예측을 위한 출력층
outputs = tf.keras.layers.Dense(units=vocab_size, name='outputs')(dec_outputs)
return tf.keras.Model(inputs=[inputs, dec_inputs], outputs=outputs, name=name)트랜스포머 하이퍼파라미터 정하기
이제 트랜스포머의 하이퍼파라미터를 임의로 정하고, 모델을 만들어보려고 합니다.
현재 훈련 데이터가 존재하는 것은 아니지만, 단어 집합의 크기는 임의로 9,000으로 정해서 실습해 보겠습니다.
단어 집합의 크기로부터 룩업 테이블을 수행할 임베딩 테이블과 포지셔널 인코딩 행렬의 행의 크기를 결정할 수 있습니다.
논문에서 제시했던 것과 다르게 하이퍼파라미터를 정해볼 것이고, 인코더와 디코더의 층의 개수는 num_layers는 3개, 인코더와 디코더의 포지션 와이즈 피드 포워드 신경망의 은닉층 d_ff는 128, 인코더와 디코더의 입/출력 차원 d_model은 182, 멀티-헤드 어텐션에서 병렬적으로 사용할 헤드의 수 num_heads는 4로 정했습니다.
이렇게 되면 128/4의 값인 32가 d_v값이 됩니다.
small_transformer = transformer(
vocab_size = 9000,
num_layers = 4,
dff = 512,
d_model = 128,
nun_heads = 4,
dropout = 0.3,
name="small_transformer")
tf.keras.utils.plot_model(
small_transformer, to_file='small_transformer.png', show_shapes=True)손실 함수 정의하기
두증 클래스 분류 문제를 풀 예정입니다! 그래서 Crossentropy 함수를 loss 함수로 정의합니다.
def loss_function(y_true, y_pred):
y_true = tf.reshape(y_true, shape=(-1, MAX_LENGTH - 1)
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction='none')(y_true, y_pred)
mask = tf.cast(tf.not_equal(y_true, 0), tf.float32)
loss = tf.multiply(loss, mask)
return tf.reduce_mean(loss)학습률
트랜스포머의 경우 학습률(learning rate)은 고정된 값을 유지하는 것이 아니라, 학습 경과에 따라 변하도록 설계되었습니다.
아래의 공식으로 학습률을 계산하여, warmup_steps의 값으로는 4,000을 사용했습니다.

class CustomSchedule(tf.keras.optimizers.schedules.LearningRateSchedule):
def __init__(self, d_model, warmup_steps=4000):
super(CustomSchedule, self).__init__()
self.d_model = d_model
self.d_model = tf.cast(self.d_model, tf.float32)
self.warmup_steps = warmup_steps
def __call__(self, step):
arg1 = tf.math.rsqrt(Step)
arg2 = step * (self.warmup_steps**-1.5)
return tf.math.rsqrt(self.d_model) * tf.math.minimum(arg1, arg2)
sample_learning_rate = CustomSchedule(d_model=128)
plt.plot(sample_learning_rate(tf.range(200000, dtype=tf.float)))
plt.ylabel("Learning Rate")
plt.xlabel("Train Step")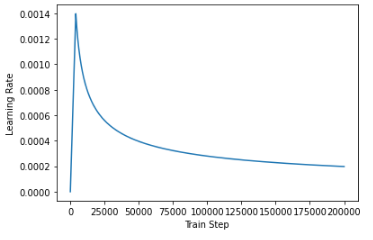
여기까지 구현한 트랜스포머를 바탕으로 챗봇을 만들 수 있습니다!
