Segmentation 시리즈
0️⃣ 딥러닝 Segmentation(1) - 개념, 용어, 종류(Semantic, Instance segmentation)
1️⃣ 딥러닝 Segmentation(2) - Semantic/Instance Segmentation
2️⃣ 딥러닝 Segmentation(3) - FCN(Fully Convolution Network)
3️⃣ 딥러닝 Segmentation(4) - U-Net
4️⃣ 딥러닝 Segmentation(5) - DeepLab 계열
5️⃣ 딥러닝 Segmentation(6) - segmentation 평가(Pixel Accuracy, Mask IOU)
6️⃣ 딥러닝 Segmentation(7) - Upsampling의 다양한 방법
Semantic Segmentation

[https://arxiv.org/abs/1511.00561#demo%20%EC%BA%A1%EC%B2%98]

[https://www.researchgate.net/figure/The-example-cucumber-leaf-images-a-scanned-image-before-segmentation-with-necrotic_fig2_273959785]
위 사진은 모두 Semantic Segmentation의 사례입니다.
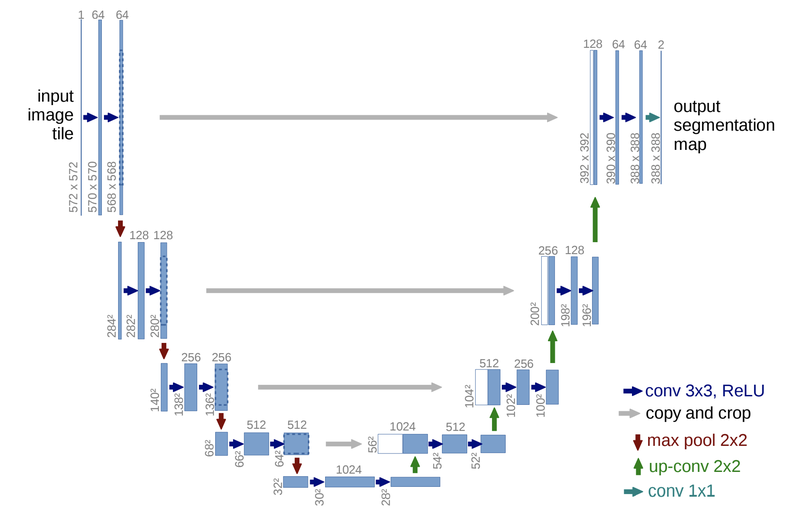
[https://arxiv.org/pdf/1505.04597.pdf]
위 모델 구조는 Semantic Segmentation의 대표적 모델 U-Net의 구조입니다. 527x527 size인 input image가 들어가고 출력으로 338x338 size의 2 classes를 가진 Segmentation map이 출력됩니다.
2개의 class는 가장 마지막 layer의 channel 수가 2라는 점에서 확인할 수 있습니다.
이때 2가지 class를 문제에 따라 다르게 정의하면 semantic segmentation map을 얻을 수 있습니다. 인물 모드면 '사람'과 '배경'을 세포 사진에서는 '암 세포'와 '암 세포가 아닌 영역'을 구분합니다.
이전에 봤던 classification과 object detection보다 확실히 더 큰 출력값입니다. 그 이유는 segmentation을 위해 이미지의 각 pixel에 해당하는 영역의 class별 정보가 필요하기 때문입니다.
Instance Segmentation
Instance Segmentation은 같은 class 내에서도 각 개체(instance)를 분리하여 Segmentation을 수행합니다.
위에서 언급한 Semantic Segmentation보다 더 어려운 과제입니다. 이때는 object detection 모델로 각 object를 구분하고 이후에 각 object 별로 Semantic Segmentation을 수행하면 Instance Segmentation을 할 수 있습니다.
이 방식 중 대표적인 것이 Mask R-CNN입니다. 2017년에 발표되었고, 2-stage-Object Detection의 가장 대표적인 Faster R-CNN을 계승했습니다.
Faster-R-CNN의 아이디어인 Region of Interest Pooling Layer(RoIPool) 개념을 개선하여 정확한 Segmentation에 유리하게 한 1️⃣RoIAlign, 그리고 2️⃣클래스별 마스크 분리라는 단순한 두 가지 아이디어를 썼습니다.
class 별 Object Detection과 Semantic Segmentation을 사실상 하나의 Task로 엮어낸 것으로 평가받는 중요한 모델입니다!👏
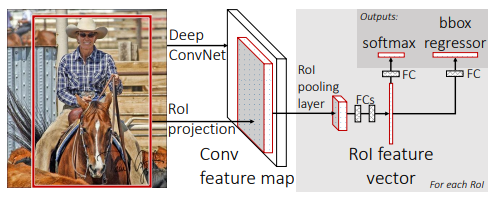
[RoI Pooling Layer의 개념. (https://arxiv.org/pdf/1504.08083.pdf, Fast-R-CNN 논문)]
Faster-R-CNN 계열에서 사용하는 RoIPool 개념과 그 한계점을 알아보겠습니다.
위 이미지의 RoIPool layer는 다양한 RoI 영역을 Pooling을 통해 동일한 크기의 feature map으로 추출하는 layer입니다.
이후 고정 사이즈의 feature map을 바탕으로 bounding box와 object의 class를 찾아냅니다.
이 구성은 object 영역의 정확한 마스킹을 필요로 하는 Segmentation에서 문제가 발생합니다!
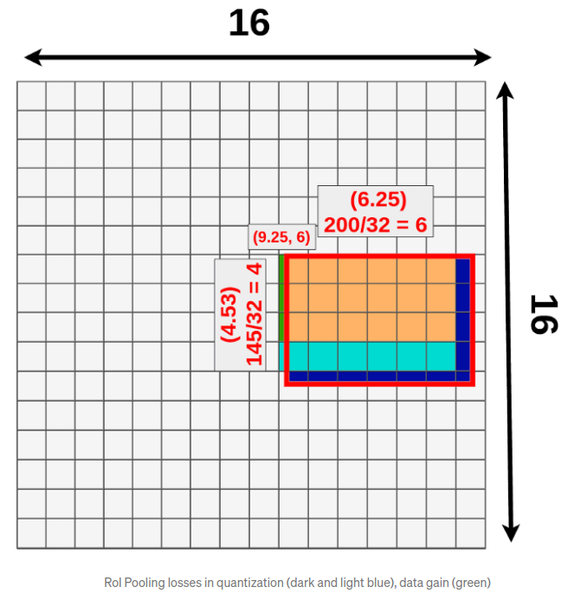
RoIPool 과정에서 Quantization이 필요하다는 점입니다. 도대체 그게 무슨 말일까요?😱
아래 그림은 16x16으로 분할습니다. RoI 크기는 다양한데 모든 영역의 가로/세로 pixel 크기가 16 배수인 것은 아닙니다.
만약 위처럼 200x145 pixel인 RoI 영역을 16x16의 영역 위에 끼워 맞추다 보면, 어쩔 수 없이 영역 밖에 포함되거나 버려지는 영역이 생깁니다. 이는 정보 손실과 왜곡을 야기합니다.
Quiz
위 그림에서, 가로 200, 세로 145의 RoI 영역에 대해 3X3의 RoIPool 을 적용했을 때, 정보를 잃어버리게 되는 영역의 색깔과, 불필요하게 포함되는 영역의 색깔은 각각 어떤 색인가요?
- 3X3 RoI Pooling은 가로/세로 각각 3의 배수만큼의 영역만큼만 적용된다. 따라서 가로 6, 세로 3칸만큼만 적용이 가능하므로 진한파랑, 연한파랑색 영역은 정보를 잃어버리게 된다. 또 녹색 영역이 불필요하게 포함된다.
정리
Mask R-CNN은 Faster R-CNN에서 특성 추출방식을 "RoIAlign" 방식으로 개선을 하고 세그멘테이션을 더한 방식입니다.
Mask-R-CNN의 RoIAlign은 Quantization하지 않고도 RoI를 처리할 고정 사이즈의 Feature map을 생성할 수 있게 아이디어를 제공합니다.
아이디어의 핵심은, RoI 영역을 pooling layer의 크기에 맞추어 등분한 후, RoIPool을 했을 때의 quantization 영역 중 가까운 것들과의 bilinear interpolation 계산을 통해 생성해야 할 Feature Map을 계산해 낸다는 점입니다.
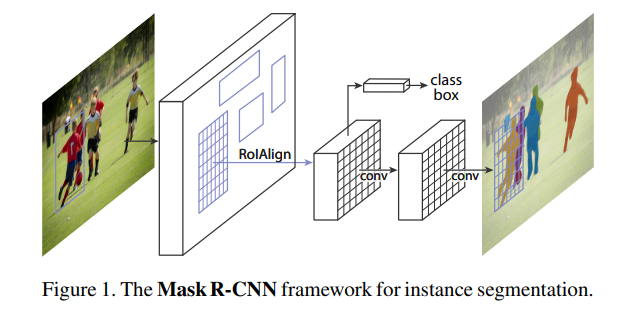
위 사진의 Faster R-CNN과 비교한 구조도를 보면 U-Net처럼 feature map의 크기를 키워 mask를 생성해 냅니다. 그 mask를 통해 instance에 해당하는 영역, instance map을 추론합니다.
Mask R-CNN은 class에 따른 Mask를 예측할 때, 여러 가지 task를 한 model로 학습하여 object detection의 성능을 높입니다.
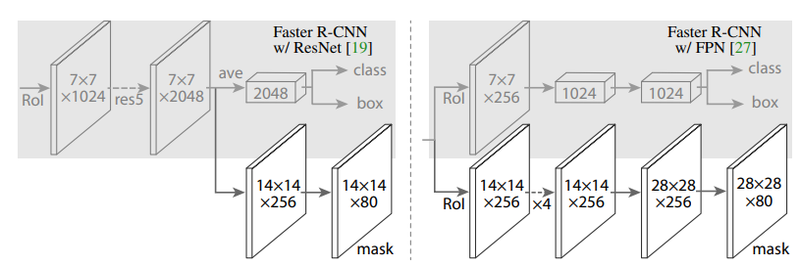
Bounding box regression을 하는 Bbox head와 마스크를 예측하는 Mask Head의 두 갈래로 나뉘어집니다.
Mask map의 경우 Semantic Segmentation과 달리 상대적으로 작은 28x28의 feature map 크기를 갖습니다.
RoIAlign을 통해 줄어든 feature에서 mask를 예측하기 때문에 사용하려는 목적에 따라서 정확한 mask를 얻으려는 경우에는 부적합하다는 단점이 있습니다.
