Segmentation 시리즈
0️⃣ 딥러닝 Segmentation(1) - 개념, 용어, 종류(Semantic, Instance segmentation)
1️⃣ 딥러닝 Segmentation(2) - Semantic/Instance Segmentation
2️⃣ 딥러닝 Segmentation(3) - FCN(Fully Convolution Network)
3️⃣ 딥러닝 Segmentation(4) - U-Net
4️⃣ 딥러닝 Segmentation(5) - DeepLab 계열
5️⃣ 딥러닝 Segmentation(6) - segmentation 평가(Pixel Accuracy, Mask IOU)
6️⃣ 딥러닝 Segmentation(7) - Upsampling의 다양한 방법
Segmentation을 위한 대표적인 방법이 있다고 합니다.
이렇게 크게 세 가지가 있는 것 같은데 이번 게시글은 FCN의 내용을 다뤄볼 예정이며
주요 참고 자료
0️⃣ 해당 논문📃: Fully Convolutional Networks for Semantic Segmentation
1️⃣ Fully Convolutional Networks for Semantic Segmentation - 허다운
2️⃣ FCN 논문 리뷰 — Fully Convolutional Networks for Semantic Segmentation
을 참고할 예정입니다.
제발 저 위의 논문 리뷰를 읽어보세요. 저렇게 잘 정리된 논문 리뷰는 처음 봐요.😳
FCN
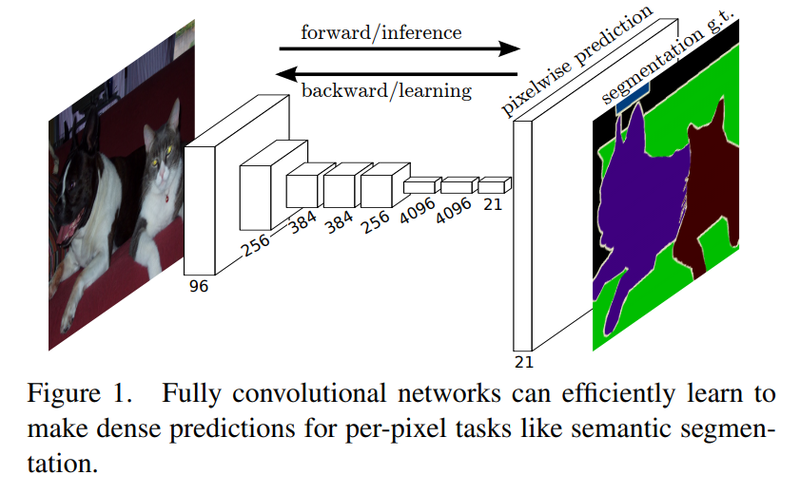
FCN은 Semantic Segmentation 모델을 위해 기존 image classification에서 우수한 성능을 보인 CNN 기반 모델(AlexNet, VGG16, GoogLeNet)을 변형시킨 구조입니다.
기본적인 VGG 모델은 이미지의 feature을 추출하기 위한 네트워크의 뒷단에 fully connected layer를 붙여, 계산한 class 별 확률을 바탕으로 image classification을 수행합니다.
FCN에서는 Segmentation을 하기 위해서 네트워크 뒷단에 fully connected layer 대신 CNN을 붙여줍니다!
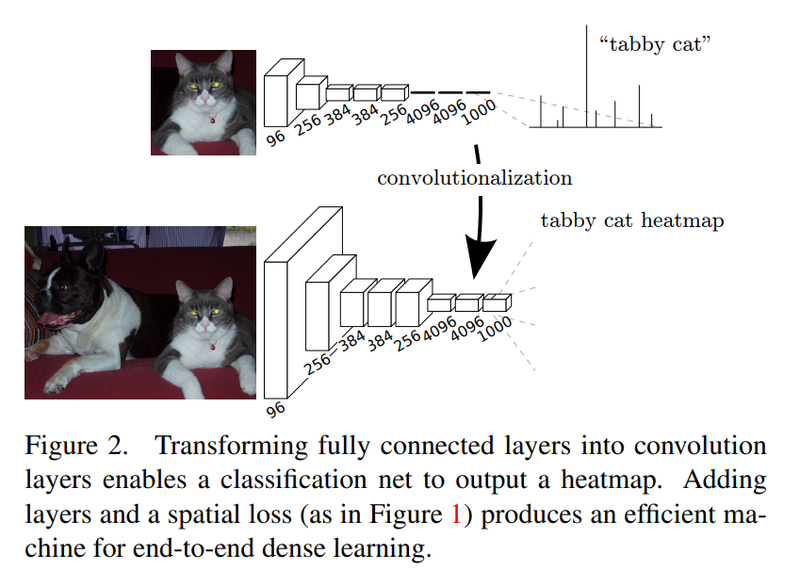
뒤의 3 Dense Layers가 모두 Conv-layer로 변경되었습니다.
이렇게 변경하는 이유는 fc-layer가 Semantic Segmentation의 관점에서 갖는 한계 때문이었는데요.
원래의 CNN 구조는 network의 input layer에서 중간부분까지는 ConvNet을 이용하여 영상의 feature를 추출하고, 해당 feature를 output layer 부분에서 fc-layer를 통해 이미지를 분류했습니다.
fc layer의 한계점은
- 이미지의 위치 정보가 사라짐
- input image의 size가 고정됨
Segmentation의 목적은 원본 이미지의 각 pixel에 대해 class를 구분하고, instance 및 background를 분할하는 것이므로 위치 정보가 매우 중요합니다.
그래서 위치 정보를 유지하면서 class 단위의 Feature map을 얻어 segmentation하기 위해 fc-layer를 CNN으로 대체합니다.
마지막 CNN은 1x1의 kernel size와 class 개수 만큼의 channel을 갖습니다.
하지만 Feature map의 크기는 일반적으로 원본 이미지보다 작습니다. 그래서 feature coarse의 특성을 갖게 됩니다. 이 해결 방법으로 upsampling이 있고, Deconvolution과 Interpolation 방식을 활용합니다.
- Deconvolution은 Conv 연산을 거꾸로 해준 것이라고 볼 수 있습니다.
- Interpolation은 보간법으로 주어진 값들을 통해 추정해야 하는 pixel(여기서는 feature map의 크기가 커지면서 메꾸어야 하는 중간 pixel들을 의미합니다.) 추정하는 방법입니다.
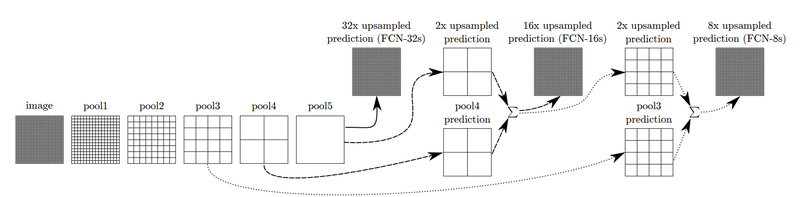
Upsampling만 하면 원하는 segmentation map을 얻을 수 있습니다. 그것이 바로 FCN-32s의 경우입니다.
하지만 논문에서는 더 나은 성능을 위해서 한 가지 기법을 더해줍니다.
위 그림에서 확인할 수 있는 Skip Architecture라는 방법입니다.
논문에서는 FCN-32s, FCN-16s, FCN-8s로 결과를 구분해 설명합니다.
Deep & Coarse(추상적인) 레이어의 의미적(Semantic) 정보와 Shallow & fine 층의 외관적(appearance) 정보를 결합한 Skip architecture를 정의한다.[2️⃣]
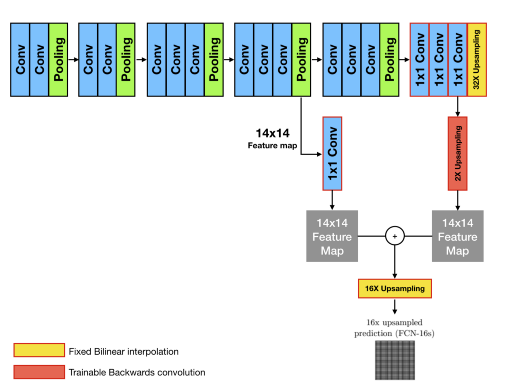
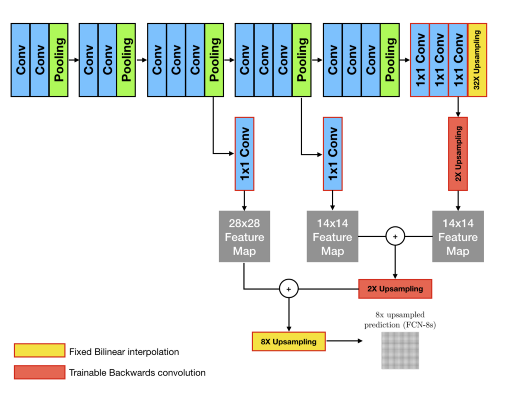
FCN-16s는 앞쪽 블록에서 얻은 예측 결과 맵과, 2배로 upsampling한 맵을 더한 후, 한 번에 16배로 upsampling을 해주어 얻습니다.
여기서 한 번 더 앞쪽 블록을 사용하면 FCN-8s를 얻을 수 있습니다. 이 기법으로 나아지는 결과는 논문 원문에 소개된 아래 그림에서 확인할 수 있습니다.
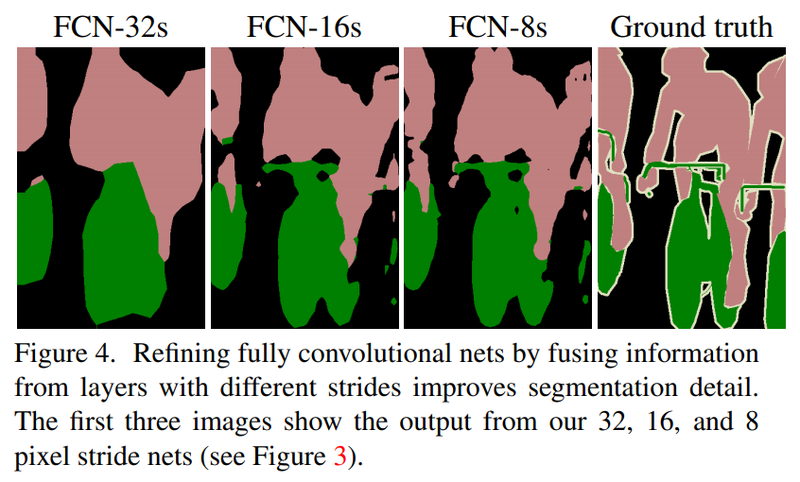
성능 지표를 살펴 보아도
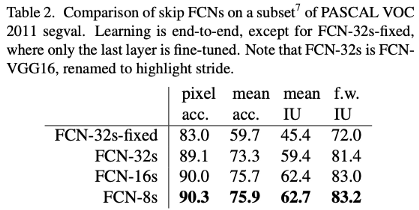
FCN-32s > FCN-16s > FCN-8s 순으로 결과가 좋아지고 있습니다.
정리
- FCNs은 기존의 Deep learning 기반 이미지 분류를 위해 학습이 완료된 모델의 구조를 Semantic Segmentation 목적에 맞게 수정하여 Transfer learning 하였습니다.
- Dense layer 👉 Conv layer 변경 - Convn layer로 변경한 모델을 통해 예측된 Coarse map을 input image size와 같이 Dense하게 만들기 위해 Upsampling하였습니다.
- Skip architecture(Deep Neural Network에서 shallow layer의 Local 정보와 Deep layer의 Semantic 정보를 결함)을 통해 보다 정교한 Segmantation 결과를 얻을 수 있었습니다.
- End-to-End 방식의 Fully-Convolution Model을 통한 Dense Prediction 혹은 Semantic Segmentation의 초석을 닦은 연구로써 이후 많은 관련 연구들에 영향을 주었습니다.
참고: [2️⃣]
