📒 [모두의 딥러닝 - 길벗] 교재를 참고하여 정리합니다.
📗 [핸즈온머신러닝 - 한빛미디어] 교재를 참고하여 정리합니다.
🔗 08. 오토인코더 (AutoEncoder)
1. 오토인코더란?
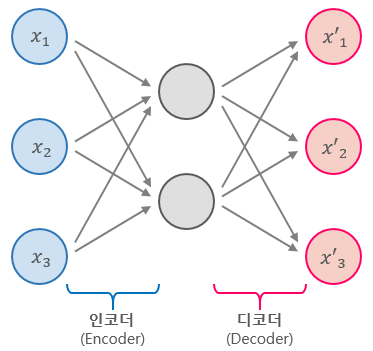
입력층보다 적은 수의 뉴런를 가진 은닉층을 중간에 넣어 줌으로써 차원을 줄입니다. 이때 학습을 통해 소실된 데이터를 복원하고, 이 과정을 통해 입력 데이터의 특징을 효율적으로 응축한 새로운 출력이 나오는 원리입니다.
오토인코더(Autoencoder)는 어떤 지도 없이도(즉, 레이블되어 있지 않은 훈련 데이터를 사용하여) 잠재 표현(latent representation) 또는 코딩(coding)이라 부르는 입력 데이터의 밀집 표현을 학습할 수 있는 인공 신경망입니다.
이런 코딩은 일반적으로 입력보다 훨씬 더 낮은 차원을 가져서 차원 축소와 시각화에 유용하게 사용됩니다.
오토인코더가 강력한 특성 추출기처럼 작동하여서 심층 신경망의 비지도 사전 훈련에 사용될 수 있습니다.
마지막으로 일부 오토인코더는 훈련 데이터와 매우 비슷한 새로운 데이터를 생성할 수 있습니다. 이는 생성 모델(generative model)이라고 합니다.
예를 들어, 얼굴 사진으로 오토인코더를 훈련하면 이 모델은 새로운 얼굴을 생성할 수 있습니다.
책에선 GAN을 설명하며 정리했는데, 아직 잘 모르므로 일단 스킵하겠습니다.
오토인코더는 단순히 입력을 출력으로 복사하는 방법을 배웁니다. 다양한 방법으로 네트워크에 제약을 가해 이 작업을 어렵게 만듭니다.
예를 들어, 잠재 표현의 크기를 제한하거나(은닉층에 있는 뉴런수를 입력층보다 작게 하는 방법) 입력에 잡음을 추가하고 원본 입력을 복원하도록 네트워크를 훈련할 수 있습니다.
이런 제약은 오토인코더가 단순히 입력을 출력으로 바로 복사하지 못하게 막고, 데이터를 효율적으로 표현하는 방법을 배우게 만듭니다.
코딩은 일정 제약 조건하에서 항등 함수(identity function)을 학습하려는 오토인코더의 노력으로 생겨난 부산물입니다.
오토인코더는 차원 축소, 특성 추출, 비지도 사전훈련 방법과 이를 생성 모델로 사용하는 방법 등이 있습니다.
2. 효율적 데이터 표현
- 40, 27, 45, 56, 71, 12, 68, 10, 19
- 50, 48, 46, 44, 42, 40, 38, 36, 34, 32, 30, 28, 26, 24, 22, 20, 18, 16, 14
위와 같은 숫자 시퀀스가 있습니다.
두 시퀀스 중 무엇을 더 기억하기 쉬울까요? 한눈에 봤을 땐 위에 시퀀스가 더 짧아서 쉬워 입니다.
하지만 자세히 보면 두 번째 시퀀스는 50에서 14까지 짝수만 나열했다는 것을 알 수 있습니다. 이런 걸 패턴이라 합니다.
패턴을 찾고나면 두 번째 시퀀스를 찾는 것이 더 쉽습니다. 그래서 패턴을 이용하는 것이 유용합니다. 효율적으로 정보를 저장할 수 있기 때문입니다.
훈련하는 동안 오토인코더에 제약을 가해서 데이터에 있는 패턴을 찾아 활용합니다.
오토인코더가 입력을 받아 효율적인 내부 표현으로 바꾸고, 입력과 가까운 어떤 것을 출력합니다.
오토인코더는 항상 두 부분으로 구성되는데요.
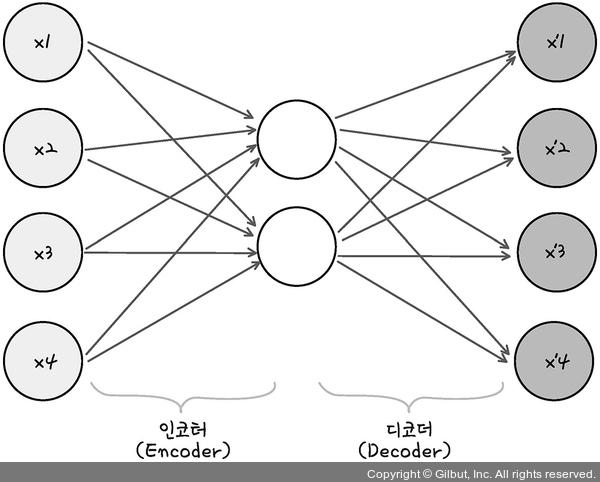
위 그림과 같이 인코더(Encoder), 디코더(Decoder)가 있습니다.
인코더(Encoder): 입력을 내부 표현으로 바꿈(인지 네트워크, recognition network)
디코더(Decoder): 내부 표현을 출력으로 바꿈(생성 네트워크, generative network)
그림을 보면 출력층의 뉴런 수가 입력 개수와 동일하다는 것을 볼 수 있습니다.
그점을 제외하고는 오토인코더는 MLP와 구조가 동일합니다.
이 예에서는 뉴런 2개로 구성된 하나의 은닉층(인코더)이 있고, 뉴런 4개로 구성된 출력층(디코더)이 있습니다.
오토인코더가 입력을 재구성하기 때문에 출력을 재구성(reconstruction)이라고 부릅니다.
비용 함수는 재구성이 입력과 다를 때 모델에 벌점을 부과하는 재구성 손실(reconstruction)을 포함합니다.
내부의 표현이 입력 데이터보다 저차원이기 때문에 이런 오토인코더를 과소완전(undercomplete)라고 합니다.
과소완전 오토인코더는 입력을 코딩으로 복사할 수 없고, 입력과 똑같은 것을 출력하기 위한 다른 방법을 찾아야 합니다.
이는 입력 데이터에서 가장 중요한 특성을 학습하도록 만들고, 중요하지 않은 것은 버리게 합니다.
다음 내용은
- 과소완전 선형 오토인코더로 PCA 수행하기
- 적층 오토인코더
- 합성곱 오토인코더
- 순환 오토인코더
- 잡음 제거 오토인코더
- 희소 오토인코더
- 변이형 오토인코더
이 나옵니다.
천천히 정리하며 공부해보겠습니다.🤦♂️
