👩🔬 이번에는 혼공머 책의 챕터 8-1 파트입니다.
참고 자료
📕 혼자공부하는머신러닝+딥러닝, 한빛미디어
합성곱(Convolution)
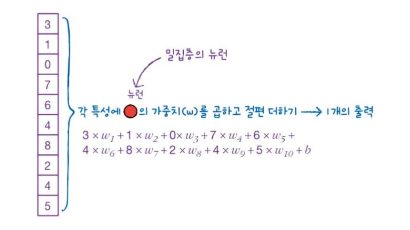
위의 그림을 참고해봅시다.
Dense Layer(밀집층)에는 뉴런마다 입력 개수만큼의 가중치가 있습니다. 모든 입력에 가중치를 곱하는 과정을 그림으로 나타낸 것입니다.
각 특성에 Neuran의 가중치()를 곱하고 절편() 더하기 -> 하나의 출력
인공 신경망의 모델 훈련은 가중치 ~을 찾아 절편 를 랜덤하게 초기화한 다음 epoch를 반복하면서 Gradient Descent Algorithm을 이용하여 loss가 낮아지도록 최적의 weight과 bias를 찾아가는 과정입니다.
예를 들어, Dense Layer에 Neuran이 3개 있다면 입력 개수와 상관없이 출력도 3개가 됩니다.
Fashion MNIST dataset에서도 이미지에 있는 784개 pixel을 입력 받는 hidden layer의 neuran이 100개라면 neuran마다 1개씩 출력을 가져 100개의 출력이 됩니다.
합성곱(convolution)은 Dense Layer와 계산이 조금 다릅니다. 입력 데이터 전체에 가중치를 적용하는 것이 아니라 일부에 가중치를 곱합니다.
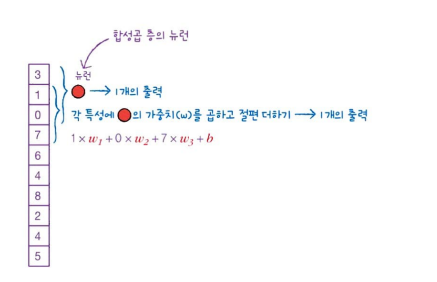
합성곱의 경우 입력의 처음 3개의 값에 가중치 ~이 곱해져서 1개의 출력을 만듭니다.
그리고 한 칸 아래로 이동해서 두 번째부터 네 번째 feature(특성)까지 곱해져 새로운 출력을 만듭니다.
여기서 중요한 점은, 첫 번째 합성곱에 사용된 가중치 ~와 절편 가 두 번째 합성곱에더 동일하게 사용된다는 점입니다.
💡 모두 같은 가중치 ~와 절편 를 사용한다.
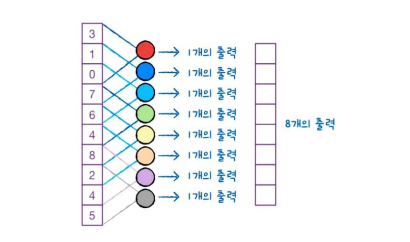
여기서는 뉴런의 가중치가 3개여서 총 8개의 출력이 만들어집니다.
사용될 뉴런의 가중치 개수는 정해야 하는 하이퍼파라미터(hyperparameter)입니다.
이전까지는 neural network 의 그림은 neuran이 길게 늘어서 있고 서로 조밀하게 연결되어 있는 모습이었습니다.

합성곱(convolution)에서는 뉴런이 위를 이동하며 출력을 만듭니다.
그래서 합성곱 신경망(convolution Neural Network, CNN)에서는 Fully-Connected(Dense) Neural Network와 달리 Neuran을 필터(filter) 혹은 커널(kernel)이라 부릅니다.
뉴런(neuran) = 필터(filter) = 커널(kernal)
해당 책에서는 뉴런의 개수를 이야기 할 때는 필터라 부르고, 가중치를 의미할 때는 커널이라 부릅니다.
커널(kernal): 입력에 곱하는 가중치
필터(filter): 뉴런의 개수
CNN의 장점은 1차원이 아니라 2차원에서도 적용이 된다는 점입니다.
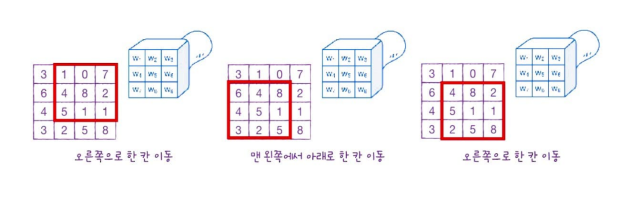
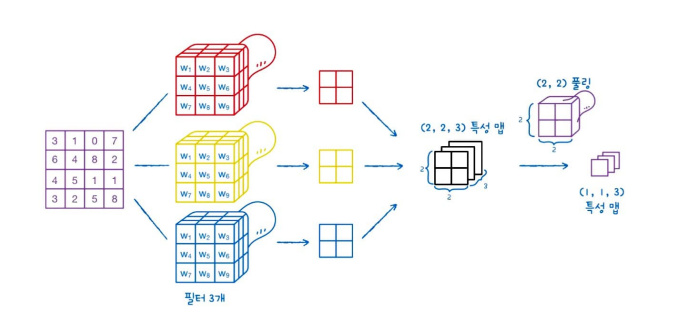
위 그림의 경우는 9개의 입력 원소, 커널 크기가 (3,3)입니다. 필터가 오른쪽으로 한 칸 이동하며 합성곱을 수행합니다.
한 칸씩 이동하여 계산하면 총 4개의 출력을 만듭니다.
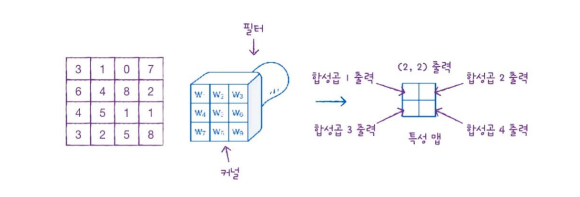
4개의 출력을 2차원으로 배치하면 (2,2) 크기의 출력값이 나옵니다. 이를 특성 맵(feature map)이라 부릅니다.
합성곱 계산을 통해 얻은 출력을 특성 맵(feature map)이라고 한다.
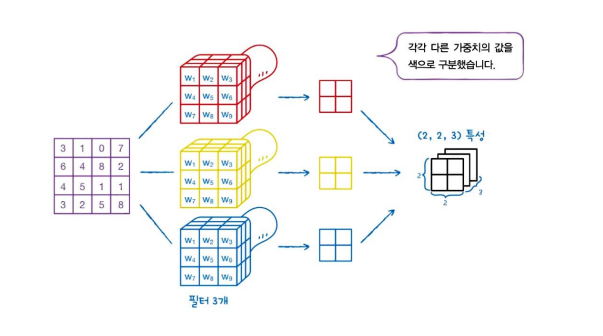
Dense Layer에서 여러 개의 Neuran을 사용하듯이, Convolution에서도 여러 개의 필터를 사용합니다.
*필터(filter)는 뉴런의 개수를 의미
여러 개의 필터를 사용하면 feature map도 차곡차곡 쌓이게 됩니다.
(2,2) 크기의 feature map을 쌓으면 3차원 배열이 되고, 3개의 필터를 사용해서 (2,2,3) 크기의 3차원 배열로 바뀝니다.
Dense Layer와 Convolution의 차이점은 2차원 형태를 유지하는 점입니다. 실제 계산은 단순히 input과 weight를 곱하는 방식으로 같습니다.
Convolution이 2차원 구조를 사용하기 때문에 이미지 처리 분야에서 더 좋은 성능을 발휘합니다.
패딩(padding)
아까 앞의 예시는 (4,4) 크기의 입력에 (3,3) 크기의 kernal을 적용하여 (2,2) 크기의 faeture map을 마늗ㄹ었습니다.
그렇다면 kernal 크기는 (3,3) 그대로 두고 출력의 크기를 입력과 동일하게 (4,4)로 만들려면 어떻게 해야 할까요?
그런 경우에는 더 큰 입력에 합성곱을 하는 방법을 선택해야 합니다.
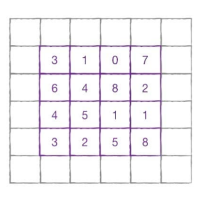
해당 이미지처럼 입력 (4,4)를 (6,6)으로 바꾸고 (3,3) kernal을 사용하면 (4,4)의 출력이 됩니다.

이런식으로 입력 배열의 주위를 가상 원소로 채우는 것을 패딩(padding)이라고 합니다.
패딩(padding): 데이터 주변에 특정 값(0혹은 다른 값)을 줘서 Convolution Layer를 통과하더라도 데이터의 크기가 동일하게 유지하게 도와주는 것
패딩과 관련하여 두 가지 개념이 더 나옵니다.
밸리드 패딩(valid padding)과 세임 패딩(same padding)인데요!
valid padding은 패딩 없이 순수하게 입력 배열로만 합성곱을 하여 feature map을 만드는 경우를 말합니다.
valid padding 같은 경우는 feature map의 크기가 줄어들 수밖에 없습니다.
세임 패딩(same padding)은 입력과 feature map의 크기를 동이랗게 만들기 위해 입력 주위에 0으로 패딩하는 것을 의미합니다.
그렇다면 convolution에서 padding을 많이 사용하는 이유는 무엇일까요?
(4,4) 크기의 입려에서 convolution을 수행한다면 왼쪽 모서리의 3은 kernal로 딱 한 번만 사용됩니다.
왼쪽 위의 3 뿐만 아니라 각 모서리에 있는 값들은 아무래도 kernal이 지나가는데 찍히는 횟수가 훨씬 더 적겠죠.
중간의 4,8,5,1 같은 경우는 모두 찍힙니다.
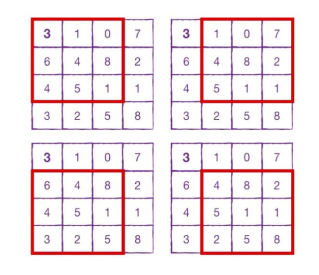
만약에 kernal이 덜 지나가는 모서리에 중요한 feature가 있다면, 잘 전달되지 않을 가능성이 높습니다.
가운데에 있는 입력 정보에서만 feature가 더 두드러지게 나타날 것입니다.
그래서 1 pixel을 padding하면 ((4,4)->(6,6)) 모서리에 있는 pixel이 convolution에 더 많이 참여하게 되어, 참여 비율 차이가 줄어들게 됩니다.
keras의 경우 기본 padding이 valid이기 때문에 same padding을 사용하고 싶은 경우, padding='same'을 꼭 적어줘야 합니다.
keras.layer.Conv2D(10, kernel_size(3,3), activation='relu', padding='same', strides=1)여기서 strides=1이라는 새로운 개념이 나옵니다. stride는 무엇일까요?
스트라이드(stride)
이때까지 좌우, 위아래로 한 칸씩 이동을 하였습니다. 그 의미가 strides=1 코드 부분입니다.
두 칸씩 이동할 수도 있는데요. 두 칸씩 이동하면 이동 거리가 넓어지니까 feature map의 크기는 더 작아집니다.
더 크게 이동하며 주요하게 뽑는 feature가 줄기 때문이빈다.
이런 이동의 크기를 stride(스트라이드)라고 합니다.
keras에서 기본 스트라이드는 1이라고 합니다.
keras.layer.Conv2D(10, kernel_size(3,3), activation='relu', padding='same', strides=2)만약 2칸씩 가고 싶다면 위처럼 바꿔주면 됩니다.
하지만 1보다 더 큰 stride는 잘 사용하지 않는다고 합니다.
풀링(pooling)
풀링(pooling)은 convolution에서 만든 feature map의 가로세로 크기를 줄이는 역할을 수행합니다.
하지만 feature map의 크기는 줄어들지 않습니다.
아까 위의 예로 (2,2,3) 크기의 feature map에 pooling을 적용하면 마지막 차원의 개수는 유지하고, 너비와 높이만 줄어들어서 (1,1,3) 크기의 feature map이 된다고 합니다.
그림으로 살펴보면 이렇습니다.
위 그림에서는 (2,2) 크기로 풀링하였습니다. 풀링의 방법은 크게 두 가지가 있습니다.
- 최대 풀링(max pooling)
- 평균 풀링(average pooling)
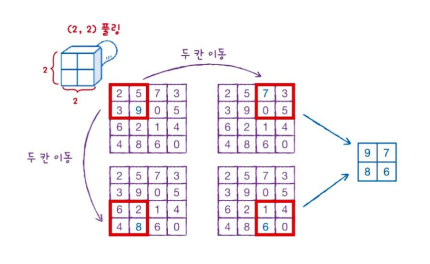
이 경우는 max pooling을 하는 경우입니다. 가장 큰 값을 찾아 (4,4) 크기를 (2,2) 크기로 줄어드는 모습을 볼 수 있습니다.
대신 pooling은 가중치와 패딩이 없고 커널이 두 칸씩 이동하며 겹치지 않게 이동합니다.
keras.layers.MaxPooling2D(2)의 형식으로 풀링의 크기를 지정할 수 있습니다.
풀링을 사용하는 이유는 합성곱에서 stride를 크게 하여 feature map을 줄이는 것보다 pooling layer에서 크기를 줄이는 것이 더 좋은 성능을 내기 때문입니다.
Summary
여기까지 합성곱 층(convolutional layer), 필터(filter), 패딩(paddig), 스트라이드(stride), 풀링(pooling) 등 신경망 개념을 살펴보았습니다.
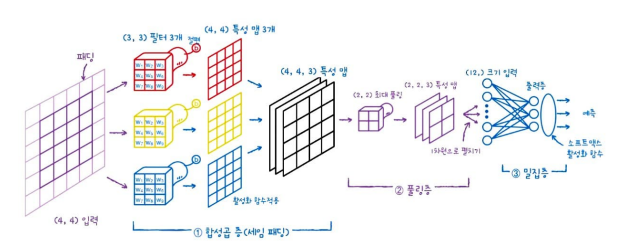
해당 그림을 통해 한 번 더 이해에 도움이 되셨으면 좋겠습니다.
- 입력 (4,4) 사이즈가 입력됩니다.
- convolution filter는 (3,3) 사이즈로 3개입니다.
- 절편(, Bias)도 하나씩 더해집니다.
- (4,4) 사이즈의 feature map이 만들어집니다.
- 3개의 filter가 합쳐져서 (4,4,3)이 됩니다.
- activation function으로 ReLU를 사용합니다.
- max pooling을 이용해서 크기가 (2,2) 반으로 줄어들고 차원은 유지하기 때문에 (2,2,3)로 feature map 개수는 유지합니다.
- Dense Layer에서 3차원 배열을 1차원 배열로 펼칩니다.
- 1차원 배열의 입력으로 바뀌고, 3개의 뉴런을 두어 3개의 클래스를 분류하는 다중 분류 문제로 바꿉니다.
- softmax activation function을 통해 최종 예측 활률로 바꾸어 줍니다.
